क्या कारण है कि क्रॉस लागू क्वेरी इस सरल XML दस्तावेज़ पर इतना खराब प्रदर्शन करती है, और जैसे-जैसे डेटासेट बढ़ता है, यह तेजी से धीमा प्रदर्शन करता है?
यह आइटम नोड से विशेषता आईडी प्राप्त करने के लिए पैरेंट अक्ष का उपयोग है।
यह क्वेरी प्लान का यह हिस्सा है जो समस्याग्रस्त है।

निम्न तालिका-मूल्यवान फ़ंक्शन से निकलने वाली 423 पंक्तियों पर ध्यान दें।
तीन फ़ील्ड नोड्स के साथ केवल एक और आइटम नोड जोड़ने से आपको यह मिलता है।
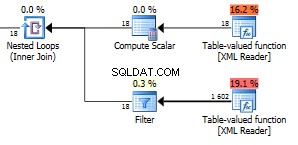
732 पंक्तियाँ लौटीं।
क्या होगा यदि हम पहली क्वेरी से नोड्स को कुल 6 आइटम नोड्स में दोगुना कर दें?
हम एक बड़ी 1602 पंक्ति तक वापस आ गए हैं।
शीर्ष फ़ंक्शन में चित्र 18 आपके XML के सभी फ़ील्ड नोड हैं। हमारे यहां 6 आइटम हैं जिनमें प्रत्येक आइटम में तीन फ़ील्ड हैं। उन 18 नोड्स का उपयोग नेस्टेड लूप में किया जाता है जो दूसरे फ़ंक्शन के विरुद्ध जुड़ते हैं, इसलिए 1602 पंक्तियों को वापस करने वाले 18 निष्पादन देता है कि यह प्रति पुनरावृत्ति 89 पंक्तियों को वापस कर रहा है। यह पूरे एक्सएमएल में नोड्स की सटीक संख्या होती है। वैसे यह वास्तव में सभी दृश्यमान नोड्स से एक अधिक है। मुझे नहीं पता क्यों। आप अपने एक्सएमएल में नोड्स की कुल संख्या की जांच के लिए इस क्वेरी का उपयोग कर सकते हैं।
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
तो जब आप पैरेंट अक्ष .. . का उपयोग करते हैं तो मान प्राप्त करने के लिए SQL सर्वर द्वारा उपयोग किया जाने वाला एल्गोरिदम एक मान फ़ंक्शन में यह है कि यह सबसे पहले उन सभी नोड्स को ढूंढता है जिन पर आप कतरन कर रहे हैं, अंतिम मामले में 18। उन नोड्स में से प्रत्येक के लिए यह पूरे XML दस्तावेज़ को काटता है और लौटाता है और फ़िल्टर ऑपरेटर में उस नोड के लिए जाँच करता है जिसे आप वास्तव में चाहते हैं। वहां आपकी घातीय वृद्धि है। मूल अक्ष का उपयोग करने के बजाय आपको एक अतिरिक्त क्रॉस लागू करना चाहिए। पहले आइटम पर और फिर मैदान पर।
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
मैंने यह भी बदल दिया है कि आप फ़ील्ड के टेक्स्ट वैल्यू तक कैसे पहुंचते हैं। . SQL सर्वर को चाइल्ड नोड्स के लिए field पर जाने देगा और परिणाम में उन मानों को संयोजित करें। आपके पास कोई चाइल्ड वैल्यू नहीं है इसलिए परिणाम समान है लेकिन क्वेरी प्लान (यूडीएक्स ऑपरेटर) में उस हिस्से को रखने से बचना एक अच्छी बात है।
यदि आप XML अनुक्रमणिका का उपयोग कर रहे हैं, तो क्वेरी योजना में पैरेंट अक्ष के साथ कोई समस्या नहीं है, लेकिन फिर भी आप फ़ील्ड मान प्राप्त करने के तरीके को बदलने से लाभान्वित होंगे।