हमने पहले से ही Linux-आधारित SQL सर्वर के लिए उपलब्धता समूहों पर हमेशा कॉन्फ़िगर करने के बारे में कुछ सिद्धांत को कवर किया है। वर्तमान लेख अभ्यास पर केंद्रित होगा।
हम दो सिंक्रोनस प्रतिकृतियों के बीच हमेशा उपलब्धता समूहों पर SQL सर्वर को कॉन्फ़िगर करने की चरण-दर-चरण प्रक्रिया प्रस्तुत करने जा रहे हैं। साथ ही, हम स्वचालित फ़ेलओवर करने के लिए केवल-कॉन्फ़िगरेशन प्रतिकृति के उपयोग पर प्रकाश डालेंगे।
शुरू करने से पहले, मैं आपको उस पिछले लेख को देखने और अपने ज्ञान को ताज़ा करने की सलाह दूंगा।
नीचे दिया गया डिज़ाइन आरेख दो-नोड सिंक्रोनस प्रतिकृति और एक कॉन्फ़िगरेशन-केवल प्रतिकृति प्रदर्शित करता है जो स्वचालित विफलता और डेटा सुरक्षा सुनिश्चित करने में हमारी सहायता करता है।
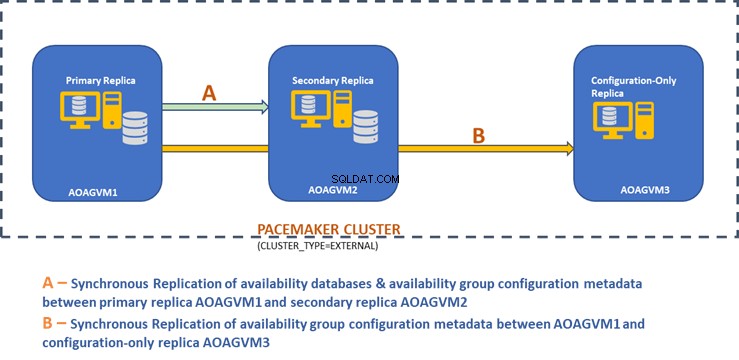
हमने पहले बताए गए लेख में इस डिज़ाइन की खोज की थी, इसलिए व्यावहारिक कार्यों पर आगे बढ़ने से पहले कृपया जानकारी के लिए इसे देखें।
उबंटू सिस्टम पर SQL सर्वर स्थापित करें
ऊपर दिए गए डिज़ाइन आरेख में 3 उबंटु प्रणालियों का उल्लेख है - aoagvm1 , aoagvm2 , और aoagvm3 SQL सर्वर इंस्टेंस के साथ स्थापित। उबंटू पर SQL सर्वर स्थापित करने के निर्देश का संदर्भ लें - उदाहरण Ubuntu 18.04 सिस्टम पर SQL सर्वर 2019 से संबंधित है। आप आगे बढ़ सकते हैं और SQL सर्वर 2019 को सभी 3 नोड्स पर स्थापित कर सकते हैं (सुनिश्चित करें कि एक ही बिल्ड संस्करण स्थापित करें)।
लाइसेंस लागत बचाने के लिए, आप तीसरे नोड प्रतिकृति के लिए SQL सर्वर एक्सप्रेस संस्करण स्थापित कर सकते हैं। यह किसी भी उपलब्धता डेटाबेस को होस्ट किए बिना कॉन्फ़िगरेशन-केवल प्रतिकृति के रूप में काम करेगा।
एक बार SQL सर्वर सभी 3 नोड्स पर स्थापित हो जाने पर, हम उनके बीच उपलब्धता समूह को कॉन्फ़िगर कर सकते हैं।
उपलब्धता समूहों को तीन नोड्स के बीच कॉन्फ़िगर करें
आगे बढ़ने से पहले, अपने परिवेश की पुष्टि करें:
- सुनिश्चित करें कि सभी 3 नोड्स के बीच संचार है।
- sudo vi /etc/hostname कमांड चलाकर प्रत्येक होस्ट के लिए कंप्यूटर का नाम जांचें और अपडेट करें
- होस्ट फ़ाइल को आईपी पते और प्रत्येक नोड के लिए नोड नामों के साथ अपडेट करें। आप कमांड का उपयोग कर सकते हैं sudo vi /etc/hosts ऐसा करने के लिए
- सुनिश्चित करें कि यदि आप SQL सर्वर 2019 का उपयोग नहीं कर रहे हैं तो आपके पास SQL Server 2017 CU1 से आगे चल रहे सभी उदाहरण हैं
अब, 3-नोड्स के बीच SQL सर्वर ऑलवेज ऑन अवेलेबिलिटी ग्रुप को कॉन्फ़िगर करना शुरू करते हैं। हमें सभी 3 नोड्स पर उपलब्धता समूह सुविधा को सक्षम करने की आवश्यकता है।
नीचे दी गई कमांड चलाएँ (ध्यान दें कि आपको उस क्रिया के बाद SQL सर्वर सेवा को पुनरारंभ करने की आवश्यकता है):
--Enable Availability Group feature
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
--Restart SQL Server service
sudo systemctl restart mssql-server
मैंने उपरोक्त आदेश को प्राथमिक नोड पर निष्पादित किया है। इसे शेष दो नोड्स के लिए दोहराया जाना चाहिए।
आउटपुट नीचे है - जब भी संकेत दिया जाए तो उपयोगकर्ता नाम और पासवर्ड दर्ज करें।
example@sqldat.com:~$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
SQL Server needs to be restarted to apply this setting. Please run
'systemctl restart mssql-server.service'.
example@sqldat.com:~$ systemctl restart mssql-server
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to restart 'mssql-server.service'.
Authenticating as: Ubuntu (aoagvm1)
Password:
अगला चरण हमेशा विस्तारित ईवेंट पर . को सक्षम करना है प्रत्येक SQL सर्वर आवृत्ति के लिए। हालांकि यह एक वैकल्पिक कदम है, आपको इसे बाद में आने वाली किसी भी समस्या के निवारण के लिए सक्षम करना होगा। SQLCMD . का उपयोग करके SQL सर्वर इंस्टेंस से कनेक्ट करें और निम्न कमांड चलाएँ:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
Go
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
Go
आउटपुट नीचे है:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
2>GO
1>
एक बार जब आप प्राथमिक प्रतिकृति नोड पर इस विकल्प को सक्षम कर लेते हैं, तो शेष aoagvm2 और aoagvm3 नोड्स के लिए भी ऐसा ही करें।
मिररिंग एंडपॉइंट्स के बीच संचार को प्रमाणित करने के लिए लिनक्स पर चलने वाले SQL सर्वर इंस्टेंस सर्टिफिकेट का उपयोग करते हैं। तो, अगला विकल्प प्राथमिक प्रतिकृति पर प्रमाणपत्र बनाना है aoagvm1 ।
सबसे पहले, हम एक मास्टर कुंजी और एक प्रमाणपत्र बनाते हैं। फिर हम एक फ़ाइल में इस प्रमाणपत्र का बैकअप लेते हैं और फ़ाइल को एक निजी कुंजी से सुरक्षित करते हैं। प्राथमिक प्रतिकृति नोड पर निम्न T-SQL स्क्रिप्ट चलाएँ:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Configure Certificates
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
आउटपुट:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
3>GO
1>BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
2>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
3>GO
1>
प्राथमिक प्रतिकृति नोड में अब दो नई फ़ाइलें हैं। एक है प्रमाण पत्र फ़ाइल dbm_certificate.cer और निजी कुंजी फ़ाइल dbm_certificate.pvk /var/opt/mssql/data/ . पर स्थान।
उपरोक्त दो फाइलों को शेष दो नोड्स (AOAGVM2 और AOAGVM3) पर उसी स्थान पर कॉपी करें जो उपलब्धता समूह कॉन्फ़िगरेशन में भाग लेंगे। इन दो फाइलों को लक्ष्य सर्वर पर कॉपी करने के लिए आप एससीपी कमांड या किसी तीसरे पक्ष की उपयोगिता का उपयोग कर सकते हैं।
एक बार जब फ़ाइलें शेष दो नोड्स में कॉपी हो जाती हैं, तो हम mssql को अनुमतियां प्रदान करेंगे उपयोगकर्ता इन फ़ाइलों को सभी 3 नोड्स पर एक्सेस कर सकता है। उसके लिए, नीचे दिए गए कमांड को चलाएँ और फिर इसे तीसरे नोड aoagvm3 के लिए निष्पादित करें। साथ ही:
--Copy files to aoagvm2 node
cd /var/opt/mssql/data
scp dbm_certificate.* example@sqldat.com:var/opt/mssql/data/
--Grant permission to user mssql to access both newly created files
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
हम शेष दो नोड्स aoagvm2 पर उपरोक्त दो कॉपी की गई फ़ाइलों की सहायता से मास्टर कुंजी और प्रमाणपत्र फ़ाइलें बनाएंगे और aoagvm3 . मास्टर कुंजी . बनाने के लिए उन दो नोड्स पर निम्न कमांड चलाएँ :
--Create master key and certificate on remaining two nodes
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
मैंने उपरोक्त कमांड को दूसरे नोड aoagvm2 . पर निष्पादित किया है मास्टर कुंजी . बनाने के लिए और प्रमाणपत्र . निष्पादन आउटपुट पर एक नज़र डालें। प्रमाणपत्र और मास्टर कुंजी बनाते और उसका बैकअप लेते समय उसी पासवर्ड का उपयोग करना सुनिश्चित करें।
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate
3>FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
4>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
5>GO
1>
उपरोक्त कमांड को AOAGVM3 . पर चलाएँ नोड भी।
अब, हम डेटाबेस मिररिंग एंडपॉइंट्स को कॉन्फ़िगर करते हैं - पहले हमने उनके लिए प्रमाण पत्र बनाए हैं। मिररिंग एंडपॉइंट का नाम hadr_endpoint . है सभी 3 नोड्स पर उनकी संबंधित भूमिका प्रकार के अनुसार होना चाहिए।
चूंकि उपलब्धता डेटाबेस केवल 2 नोड्स पर होस्ट किए जाते हैं aoagvm1 और aoagvm2, हम नीचे दिए गए स्टेटमेंट को केवल उन नोड्स पर चलाएंगे। तीसरा नोड एक गवाह की तरह काम करेगा - इसलिए हम बस बदलेंगे भूमिका साक्षी . के लिए नीचे दी गई स्क्रिप्ट में, और फिर टी-एसक्यूएल को तीसरे नोड aoagvm3 . पर चलाएं . स्क्रिप्ट है:
--Configure database mirroring endpoint Hadr_endpoint on nodes aoagvm1 and aoagvm2
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
प्राथमिक प्रतिकृति नोड पर उपरोक्त आदेश का आउटपुट यहां दिया गया है। मैंने sqlcmd . से कनेक्ट किया है और इसे अंजाम दिया। दूसरे रेप्लिका नोड पर भी ऐसा ही करना सुनिश्चित करें aoagvm2 साथ ही।
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE ENDPOINT [Hadr_endpoint]
2>AS TCP (LISTENER_PORT = 5022)
3>FOR DATABASE_MIRRORING (ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
4>Go
1>ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
2>Go
1>
एक बार जब आप उपरोक्त T-SQL स्क्रिप्ट को पहले 2 नोड्स पर निष्पादित कर लेते हैं, तो हमें इसे तीसरे नोड के लिए संशोधित करने की आवश्यकता होती है - ROLE को WITNESS में बदलें।
विटनेस नोड AOAGVM3 . पर डेटाबेस मिररिंग एंडपॉइंट बनाने के लिए नीचे दी गई स्क्रिप्ट चलाएँ . यदि आप वहां उपलब्धता डेटाबेस को होस्ट करना चाहते हैं, तो उपरोक्त कमांड को 3 रेप्लिका नोड पर भी चलाएँ। लेकिन सुनिश्चित करें कि आपने इस क्षमता को प्राप्त करने के लिए SQL सर्वर का सही संस्करण स्थापित किया है।
यदि आपने केवल-कॉन्फ़िगरेशन implement को लागू करने के लिए 3 नोड पर SQL सर्वर एक्सप्रेस संस्करण स्थापित किया है प्रतिकृति , आप केवल भूमिका . को कॉन्फ़िगर कर सकते हैं एक गवाह . के रूप में इस नोड के लिए:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
----Configure database mirroring endpoint Hadr_endpoint on 3rd node aoagvm3
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = WITNESS, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint on aoagvm3
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
अब हमें ag1 . नाम का उपलब्धता समूह बनाना होगा ।
sqlcmd . का उपयोग करके SQL सर्वर इंस्टेंस से कनेक्ट करें उपयोगिता और प्राथमिक प्रतिकृति नोड पर निम्न आदेश चलाएँ aoagvm1 :
--Connect to the local SQL Server instance using sqlcmd hosted on primary replica node aoagvm1
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Create availability group ag1
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'aoagvm1’ WITH (ENDPOINT_URL = N'tcp://aoagvm1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm2' WITH (ENDPOINT_URL = N'tcp://aoagvm2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm3' WITH (ENDPOINT_URL = N'tcp://aoagvm3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY);
--Assign required permission
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
उपरोक्त स्क्रिप्ट उपलब्धता समूह प्रतिकृतियों को नीचे दिए गए कॉन्फ़िगरेशन पैरामीटर के साथ कॉन्फ़िगर करती है (हमने अभी उन्हें टी-एसक्यूएल स्क्रिप्ट में उपयोग किया है):
- CLUSTER_TYPE =EXTERNAL क्योंकि हम उपलब्धता समूह को Linux आधारित SQL सर्वर इंस्टॉलेशन पर कॉन्फ़िगर कर रहे हैं
- SEEDING_MODE =स्वचालित SQL सर्वर को प्रत्येक द्वितीयक प्रतिकृति पर स्वचालित रूप से डेटाबेस बनाने का कारण बनता है। उपलब्धता डेटाबेस केवल-कॉन्फ़िगरेशन प्रतिकृति पर नहीं बनाए जाएंगे
- FAILOVER_MODE =EXTERNAL प्राथमिक और माध्यमिक प्रतिकृतियों दोनों के लिए। इसका मतलब है कि प्रतिकृति बाहरी क्लस्टर संसाधन प्रबंधक, जैसे पेसमेकर के साथ इंटरैक्ट करती है
- AVAILABILITY_MODE =SYNCHRONOUS_COMMIT स्वचालित विफलता के लिए प्राथमिक और द्वितीयक प्रतिकृतियों के लिए
- AVAILABILITY_MODE =CONFIGURATION_ONLY तीसरी प्रतिकृति के लिए जो केवल विन्यास प्रतिकृति के रूप में काम करती है
हमें सभी SQL सर्वर इंस्टेंस पर पेसमेकर लॉगिन बनाने की भी आवश्यकता है। इस उपयोगकर्ता को ALTER . असाइन किया जाना चाहिए , नियंत्रण , और देखें परिभाषा उपलब्धता समूह पर सभी प्रतिकृतियों पर अनुमतियाँ। अनुमतियाँ देने के लिए, नीचे दी गई T-SQL स्क्रिप्ट को सभी 3 प्रतिकृति नोड्स पर तुरंत चलाएँ। सबसे पहले, हम एक पेसमेकर लॉगिन बनाएंगे। फिर, हम उस लॉगिन को उपरोक्त अनुमतियां प्रदान करेंगे।
--Create pacemaker login on each SQL Server instance. Run below commands on all 3 SQL Server instances
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
--Grant permission to pacemaker login on newly created availability group. Run it on all 3 SQL Server instances
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemaker
GRANT VIEW SERVER STATE TO pacemaker
सभी 3 प्रतिकृतियों पर पेसमेकर लॉगिन के लिए उपयुक्त अनुमति प्रदान करने के बाद, हम द्वितीयक प्रतिकृतियों में शामिल होने के लिए नीचे दी गई टी-एसक्यूएल स्क्रिप्ट को निष्पादित करते हैं aoagvm2 और aoagvm3 नए बनाए गए उपलब्धता समूह ag1 . को . द्वितीयक प्रतिरूपों पर निम्न आदेश चलाएँ aoagvm2 और aoagvm3 ।
--Execute below commands on aoagvm2 and aoagvm3 to join availability group ag1
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
नीचे नोड पर उपरोक्त निष्पादन का आउटपुट है aoagvm2 . इसे aoagvm3 . पर चलाना सुनिश्चित करें नोड भी।
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
2>Go
1>ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
2>Go
1>
इस प्रकार, हमने उपलब्धता समूह को कॉन्फ़िगर किया है। अब, हमें इस उपलब्धता समूह में एक उपयोगकर्ता या एक परीक्षण डेटाबेस जोड़ने की आवश्यकता है। यदि आपने पहले ही प्राथमिक नोड प्रतिकृति पर एक उपयोगकर्ता डेटाबेस बना लिया है, तो बस एक पूर्ण बैकअप चलाएँ और फिर स्वचालित सीडिंग को इसे द्वितीयक नोड पर पुनर्स्थापित करने दें।
इस प्रकार, निम्न आदेश चलाएँ:
--Run a full backup of test database or user database hosted on primary replica aoagvm1
BACKUP DATABASE [Test] TO DISK = N'/var/opt/mssql/data/Test_15June.bak';
आइए इस डेटाबेस को जोड़ें परीक्षण उपलब्धता समूह के लिए ag1 . प्राथमिक नोड aoagvm1 पर नीचे दिए गए T-SQL कथन को चलाएँ . आप sqlcmd . का उपयोग कर सकते हैं टी-एसक्यूएल स्टेटमेंट चलाने के लिए उपयोगिता।
--Add user database or test database to the availability group ag1
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [Test];
आप उपयोक्ता डेटाबेस या एक परीक्षण डेटाबेस को सत्यापित कर सकते हैं जिसे आपने उपलब्धता समूह में द्वितीयक SQL सर्वर आवृत्ति को देखकर सत्यापित किया है, चाहे वह द्वितीयक प्रतिकृतियों पर बनाया गया हो या नहीं। आप या तो SQL सर्वर प्रबंधन स्टूडियो का उपयोग कर सकते हैं या इस डेटाबेस के बारे में विवरण प्राप्त करने के लिए एक साधारण T-SQL कथन चला सकते हैं।
--Verify test database is created on a secondary replica or not. Run it on secondary replica aoagvm2.
SELECT * FROM sys.databases WHERE name = 'Test';
GO
आपको परीक्षा मिलेगी द्वितीयक प्रतिकृति पर बनाया गया डेटाबेस।
उपरोक्त चरण के साथ, ऑलवेजऑन उपलब्धता समूह को तीनों नोड्स के बीच कॉन्फ़िगर किया गया है। हालाँकि, इन नोड्स को अभी तक क्लस्टर नहीं किया गया है। हमारा अगला कदम पेसमेकर . को स्थापित करना है उन पर क्लस्टर। फिर हम उपलब्धता समूह को जोड़ेंगे ag1 उस क्लस्टर के संसाधन के रूप में।
तीन नोड्स के बीच पेसमेकर क्लस्टर कॉन्फ़िगरेशन
इसलिए, हम एक बाहरी क्लस्टर संसाधन प्रबंधक का उपयोग करेंगे पेसमेकर क्लस्टर समर्थन के लिए सभी 3 नोड्स के बीच। आइए सभी 3 नोड्स के बीच फ़ायरवॉल पोर्ट को सक्षम करके शुरू करें।
निम्न आदेश का उपयोग करके फ़ायरवॉल पोर्ट खोलें:
--Run the below commands on all 3 nodes to open Firewall Ports
sudo ufw allow 2224/tcp
sudo ufw allow 3121/tcp
sudo ufw allow 21064/tcp
sudo ufw allow 5405/udp
sudo ufw allow 1433/tcp
sudo ufw allow 5022/tcp
sudo ufw reload
--If you don't want to open specific firewall ports then alternatively you can disable the firewall on all 3 nodes by running the below command (THIS IS ALTERNATE & OPTIONAL APPROACH)
sudo ufw disable
आउटपुट देखें - यह प्राथमिक प्रतिकृति से है AOAGVM1 . आपको उपरोक्त आदेशों को एक-एक करके तीनों नोड्स पर निष्पादित करने की आवश्यकता है। आउटपुट समान होना चाहिए।
example@sqldat.com:~$ sudo ufw allow 2224/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 3121/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 21064/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5405/udp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 1433/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5022/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw reload
Firewall not enabled (skipping reload)
पेसमेकर स्थापित करें और corosync सभी 3 नोड्स पर पैकेज। प्रत्येक नोड पर निम्न कमांड चलाएँ - यह पेसमेकर को कॉन्फ़िगर करेगा , corosync , और बाड़ लगाने वाला एजेंट ।
--Install Pacemaker packages on all 3 nodes aoagvm1, aoagvm2 and aoagvm3 by running the below command
sudo apt-get install pacemaker pcs fence-agents resource-agents
आउटपुट विशाल – . है लगभग 20 पृष्ठ। मैंने इसे स्पष्ट करने के लिए पहली और आखिरी कुछ पंक्तियों को कॉपी किया है (आप सभी पैकेज स्थापित देख सकते हैं):
example@sqldat.com:~$ sudo apt-get install pacemaker pcs fence-agents resource-agents
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
cluster-glue corosync fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4 libcpg4
libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker-cli-utils pacemaker-common pacemaker-resource-agents python-pexpect python-ptyprocess python-pycurl python3-bs4 python3-html5lib
python3-lxml python3-pycurl python3-webencodings rake ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean ruby-ethon ruby-ffi ruby-highline
ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4 ruby-power-assert ruby-rack
ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt ruby-tzinfo ruby2.5
rubygems-integration sg3-utils snmp unzip xsltproc zip
Suggested packages:
ipmitool python-requests python-suds apache2 | lighttpd | httpd lm-sensors snmp-mibs-downloader python-pexpect-doc libcurl4-gnutls-dev python-pycurl-dbg
python-pycurl-doc python3-genshi python3-lxml-dbg python-lxml-doc python3-pycurl-dbg ri ruby-dev bundler
The following NEW packages will be installed:
cluster-glue corosync fence-agents fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4
libcpg4 libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker pacemaker-cli-utils pacemaker-common pacemaker-resource-agents pcs python-pexpect python-ptyprocess python-pycurl python3-bs4
python3-html5lib python3-lxml python3-pycurl python3-webencodings rake resource-agents ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean
ruby-ethon ruby-ffi ruby-highline ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4
ruby-power-assert ruby-rack ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt
ruby-tzinfo ruby2.5 rubygems-integration sg3-utils snmp unzip xsltproc zip
0 upgraded, 103 newly installed, 0 to remove and 2 not upgraded.
Need to get 19.6 MB of archives.
After this operation, 86.0 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 fonts-lato all 2.0-2 [2698 kB]
Get:2 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 libdbus-glib-1-2 amd64 0.110-2 [58.3 kB]
…………
--------
एक बार पेसमेकर क्लस्टर स्थापना समाप्त हो गई है, हक्लस्टर नीचे दिए गए आदेश को चलाने के दौरान उपयोगकर्ता स्वचालित रूप से पॉप्युलेट हो जाएगा:
example@sqldat.com:~$ cat /etc/passwd|grep hacluster
hacluster:x:111:115::/var/lib/pacemaker:/usr/sbin/nologin
अब, हम पेसमेकर . स्थापित करते समय बनाए गए डिफ़ॉल्ट उपयोगकर्ता के लिए पासवर्ड सेट कर सकते हैं और Corosync पैकेज। सभी 3 नोड्स पर एक ही पासवर्ड का उपयोग करना सुनिश्चित करें। नीचे दिए गए आदेश का प्रयोग करें:
--Set default user password on all 3 nodes
sudo passwd hacluster
संकेत मिलने पर पासवर्ड दर्ज करें:
example@sqldat.com:~$ sudo passwd hacluster
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
अगला चरण पीसीडी . को सक्षम और प्रारंभ करना है सेवा और पेसमेकर सभी 3 नोड्स पर। यह रिबूट के बाद सभी 3 नोड्स को क्लस्टर में शामिल होने की अनुमति देता है। इस चरण को पूरा करने के लिए सभी 3 नोड्स पर निम्न कमांड चलाएँ:
--Enable and start pcsd service and pacemaker
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker
प्राथमिक प्रतिकृति पर निष्पादन देखें aoagvm1 . इसे बाकी दो नोड्स पर भी चलाना सुनिश्चित करें।
--Enable pcsd service
example@sqldat.com:~$ sudo systemctl enable pcsd
Synchronizing state of pcsd.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pcsd
--Start pcsd service
example@sqldat.com:~$ sudo systemctl start pcsd
--Enable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
हमने पेसमेकर . को कॉन्फ़िगर किया है पैकेज। अब हम एक क्लस्टर बनाते हैं।
सबसे पहले, सुनिश्चित करें कि आपके पास उन सिस्टमों पर पहले से कॉन्फ़िगर किया गया कोई क्लस्टर नहीं है। आप नीचे दिए गए आदेशों को चलाकर सभी नोड्स से किसी भी मौजूदा क्लस्टर कॉन्फ़िगरेशन को नष्ट कर सकते हैं। ध्यान दें कि किसी भी क्लस्टर कॉन्फ़िगरेशन को हटाने से सभी क्लस्टर सेवाएं बंद हो जाएंगी और पेसमेकर . को अक्षम कर दिया जाएगा सेवा - इसे फिर से सक्षम करने की आवश्यकता है।
--Destroy previously configured clusters to clean the systems
sudo pcs cluster destroy
--Reenable Pacemaker
sudo systemctl enable pacemaker
नीचे प्राथमिक प्रतिकृति नोड से आउटपुट है aoagvm1 ।
--Destroy previously configured clusters to clean the systems
example@sqldat.com:~$ sudo pcs cluster destroy
Shutting down pacemaker/corosync services...
Killing any remaining services...
Removing all cluster configuration files...
--Reenable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
इसके बाद, हम प्राथमिक प्रतिकृति aoagvm1 . से सभी 3 नोड्स के बीच 3-नोड क्लस्टर बनाते हैं . महत्वपूर्ण :नीचे दिए गए आदेशों को केवल अपने प्राथमिक नोड से निष्पादित करें !
--Create cluster. Modify below command with your node names, hacluster password and clustername
sudo pcs cluster auth <node1> <node2> <node3> -u hacluster -p <password for hacluster>
sudo pcs cluster setup --name <clusterName> <node1> <node2...> <node3>
sudo pcs cluster start --all
sudo pcs cluster enable --all
प्राथमिक प्रतिकृति नोड पर आउटपुट देखें:
example@sqldat.com:~$ sudo pcs cluster auth aoagvm1 aoagvm2 aoagvm3 -u hacluster -p hacluster
aoagvm1: Authorized
aoagvm2: Authorized
aoagvm3: Authorized
example@sqldat.com:~$ sudo pcs cluster setup --name aoagvmcluster aoagvm1 aoagvm2 aoagvm3
Destroying cluster on nodes: aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Stopping Cluster (pacemaker)...
aoagvm2: Stopping Cluster (pacemaker)...
aoagvm3: Stopping Cluster (pacemaker)...
aoagvm1: Successfully destroyed cluster
aoagvm2: Successfully destroyed cluster
aoagvm3: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'aoagvm1', 'aoagvm2', 'aoagvm3'
aoagvm1: successful distribution of the file 'pacemaker_remote authkey'
aoagvm2: successful distribution of the file 'pacemaker_remote authkey'
aoagvm3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
aoagvm1: Succeeded
aoagvm2: Succeeded
aoagvm3: Succeeded
Synchronizing pcsd certificates on nodes aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
Restarting pcsd on the nodes to reload the certificates...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
example@sqldat.com:~$ sudo pcs cluster start --all
aoagvm1: Starting Cluster...
aoagvm2: Starting Cluster...
aoagvm3: Starting Cluster...
example@sqldat.com:~$ sudo pcs cluster enable --all
aoagvm1: Cluster Enabled
aoagvm2: Cluster Enabled
aoagvm3: Cluster Enabled
बाड़ लगाना उत्पादन में पेसमेकर क्लस्टर का उपयोग करते समय आवश्यक विन्यासों में से एक है। आपको अपने क्लस्टर के लिए फेंसिंग कॉन्फ़िगर करनी चाहिए ताकि यह सुनिश्चित किया जा सके कि किसी भी तरह के व्यवधान के मामले में कोई डेटा भ्रष्टाचार नहीं होगा ।
बाड़ लगाने के दो प्रकार हैं:
- संसाधन-स्तर - सुनिश्चित करता है कि एक नोड एक या अधिक संसाधनों का उपयोग नहीं कर सकता है।
- नोड-स्तर - सुनिश्चित करता है कि नोड किसी भी संसाधन को बिल्कुल भी नहीं चलाता है।
हम आम तौर पर STONITH . का उपयोग करते हैं बाड़ लगाने के विन्यास के रूप में - पेसमेकर . के लिए नोड-स्तरीय बाड़ लगाना ।
जब पेसमेकर एक नोड पर एक नोड या संसाधन की स्थिति निर्धारित नहीं कर सकता है, बाड़ लगाना क्लस्टर को फिर से एक ज्ञात स्थिति में लाता है। इसे प्राप्त करने के लिए, पेसमेकर के लिए हमें STONITH . को सक्षम करने की आवश्यकता है , जिसका अर्थ है शूट द अदर नोड इन द हेड ।
हम इस लेख में फेंसिंग कॉन्फ़िगरेशन पर ध्यान केंद्रित नहीं करेंगे क्योंकि नोड-स्तरीय फ़ेंसिंग कॉन्फ़िगरेशन व्यक्तिगत वातावरण पर बहुत अधिक निर्भर करता है। हमारे परिदृश्य के लिए, हम नीचे दिए गए आदेश को चलाकर इसे अक्षम कर देंगे:
--Disable fencing (STONITH)
sudo pcs property set stonith-enabled=false
हालांकि, यदि आप पेसमेकर . का उपयोग करने की योजना बना रहे हैं उत्पादन के माहौल में, आपको अपने पर्यावरण के आधार पर STONITH कार्यान्वयन की योजना बनानी चाहिए और इसे सक्षम रखना चाहिए।
इसके बाद, हम कुछ आवश्यक क्लस्टर गुण सेट करेंगे:क्लस्टर-रीचेक-अंतराल, प्रारंभ-विफलता-घातक, और विफलता-समयबाह्य ।
MSDN के अनुसार, यदि विफलता-समयबाह्य 60 सेकंड पर सेट है, और क्लस्टर-रीचेक-अंतराल 120 सेकंड के लिए सेट किया गया है, पुनरारंभ करने की कोशिश एक अंतराल पर की जाती है जो 60 सेकंड से अधिक लेकिन 120 सेकंड से कम हो। Microsoft क्लस्टर-रीचेक-अंतराल के लिए मान सेट करने की अनुशंसा करता है विफलता-समयबाह्य . के मान से अधिक . एक और सेटिंग प्रारंभ-विफलता-घातक सत्य . के रूप में सेट करने की आवश्यकता है . अन्यथा, क्लस्टर प्राथमिक प्रतिकृति की विफलता को उनके संबंधित द्वितीयक प्रतिकृति में आरंभ नहीं करेगा, यदि कोई स्थायी रुकावट होती है।
सभी 3 महत्वपूर्ण क्लस्टर गुणों को कॉन्फ़िगर करने के लिए निम्न कमांड चलाएँ:
--Set cluster property cluster-recheck-interval to 2 minutes
sudo pcs property set cluster-recheck-interval=2min
--Set start-failure-is-fatal to True
sudo pcs property set start-failure-is-fatal=true
--Set failure-timeout to 60 seconds. Ag1 is the name of the availability group. Change this name with your availability group name.
pcs resource update ag1 meta failure-timeout=60s
उपलब्धता समूह को पेसमेकर क्लस्टर समूह में एकीकृत करें
यहां, हमारा लक्ष्य नव निर्मित उपलब्धता समूह ag1 को एकीकृत करने की प्रक्रिया का वर्णन करना है नव निर्मित पेसमेकर . को क्लस्टर समूह।
सबसे पहले, हम पेसमेकर . के साथ एकीकरण के लिए SQL सर्वर संसाधन एजेंट स्थापित करेंगे सभी 3 नोड्स पर:
--Install SQL Server Resource Agent on all 3 nodes
sudo apt-get install mssql-server-ha
मैंने उपरोक्त आदेश को सभी 3 नोड्स पर निष्पादित किया है। नीचे दिए गए आउटपुट को देखें (aoagvm1 . से लिया गया) ):
--Install SQL Server resource agent for integration with Pacemaker
example@sqldat.com:~$ sudo apt-get install mssql-server-ha
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
mssql-server-ha
0 upgraded, 1 newly installed, 0 to remove, and 2 not upgraded.
Need to get 1486 kB of archives.
After this operation, 9151 kB of additional disk space will be used.
Get:1 https://packages.microsoft.com/ubuntu/16.04/mssql-server-preview xenial/main amd64 mssql-server-ha amd64 15.0.1600.8-1 [1486 kB]
Fetched 1486 kB in 0s (4187 kB/s)
Selecting previously unselected package mssql-server-ha.
(Reading database ... 90430 files and directories currently installed.)
Preparing to unpack .../mssql-server-ha_15.0.1600.8-1_amd64.deb ...
Unpacking mssql-server-ha (15.0.1600.8-1) ...
Setting up mssql-server-ha (15.0.1600.8-1) ...
शेष 2 नोड्स पर उपरोक्त चरणों को दोहराएं।
हमने पहले ही पेसमेकर बना लिया है 3 नोड्स पर होस्ट किए गए सभी SQL सर्वर इंस्टेंस पर लॉगिन करें जब हमने उपलब्धता समूह को कॉन्फ़िगर किया हो ag1 . अब, हम सभी 3 SQL सर्वर इंस्टेंस पर sysadmin भूमिका असाइन करते हैं। आप sqlcmd . का उपयोग करके कनेक्ट कर सकते हैं इस टी-एसक्यूएल कमांड को चलाने के लिए। If you have not created the Pacemaker login, you can run the below command to do it.
--Create a pacemaker login if you missed creating it in the above section.
USE master
Go
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
Go
--Assign sysadmin role to pacemaker login on all 3 nodes. Run this T-SQL on all 3 SQL Server instances.
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemaker]
We must save the above SQL Server Pacemaker login and its credentials on all 3 nodes. Run the below command there:
--Save pacemaker login credentials on all 3 nodes by executing below commands on each node
echo 'pacemaker' >> ~/pacemaker-passwd
echo 'example@sqldat.com@12' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd
We will create the Availability Group Resource as master/subordinate .
We are using the pcs resource create command to create the Availability Group resource and set its properties. The following command will create the ocf:mssql:ag resource for the Availability Group ag1 ।
The Pacemaker resource agent automatically sets the value of REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT on the Availability Group based on the Availability Group’s configuration during the creation of the Availability Group resource.
Execute the below command:
--Create availability group resource ocf:mssql:ag
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s --master meta notify=true
Next, we create a virtual IP resource in Pacemaker . Ensure you have the unused private IP address from your network . Replace the IP value with your virtual IP address. This IP will point to the primary replica and you can use it to make databases connections with active nodes.
The command is below:
--Configure virtual IP resource
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=10.50.0.7
We are adding the colocation constraint and ordering constraint to the Pacemaker cluster configuration . These constraints help the virtual IP resource to make decisions on resources, e.g., where they should run.
Constraints have some scores, and Pacemaker uses these scores to make decisions. Scores are calculated per resource. The cluster resource manager chooses the node with the highest score for a particular resource.
The colocation constraint has an implicit ordering constraint . We need to add an ordering constraint to prevent the IP address from temporarily pointing to the node with the pre-failover secondary . Ordering constraint ensures the cluster comes online in a particular sequential manner.
Run the below commands to add colocation constraint and ordering constraint to the cluster.
--Add colocation constraint
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
--Add ordering constraint
sudo pcs constraint order promote ag_cluster-master then start virtualip
Hence, Two-Node Synchronous Replicas (aoagvm1 &aoagvm2) and a Configuration-Only Replica (aoagvm3) on PACEMAKER Cluster between 3-Node Ubuntu Systems has been completed.
We can test the configuration to validate the automatic failover. Run the below command to check the status of the Pacemaker cluster. The command also initiates the Availability Group failover.
Remember, once you couple your Availability Group with the PACEMAKER cluster, you cannot use T-SQL statements to initiate the Availability Group failovers. You can also shut down the primary replica to initiate the automatic failover.
The command is the following:
--Validate the PACEMAKER cluster configuration
sudo pcs status
--Initiate availability group failover to verify AOAG configuration
sudo pcs resource move ag_cluster-master aoagvm2 –master
निष्कर्ष
This article was meant to help you understand the configuration of the Two-Node Synchronous Replicas and a Configuration-Only Replica on PACEMAKER Cluster. We hope that you got useful information that will help you in your workflow.
Always plan all steps carefully and do proper testing in a lower life cycle before deploying to your production environment.
We’ll be glad to hear your thoughts about this topic. Feel free to leave your feedback in a comment section.