हम किन समस्याओं पर विचार करेंगे?
यदि सर्वर "ई ड्राइव पर अधिक स्थान नहीं है" को सूचित करता है - किसी गहन विश्लेषण की आवश्यकता नहीं है। हम उन त्रुटियों पर विचार नहीं करेंगे, जिनका समाधान संदेश के पाठ से स्पष्ट है और जिसके लिए Google तुरंत समाधान के साथ MSDN का लिंक देता है।
आइए उन समस्याओं की जांच करें जो Google के लिए स्पष्ट नहीं हैं, जैसे, उदाहरण के लिए, प्रदर्शन में अचानक गिरावट या कनेक्शन की अनुपस्थिति। अनुकूलन और विश्लेषण के लिए मुख्य उपकरणों पर विचार करें। आइए देखें कि लॉग और अन्य उपयोगी जानकारी कहाँ स्थित है। वास्तव में, मैं एक लेख में एक त्वरित शुरुआत के लिए सभी आवश्यक जानकारी एकत्र करने का प्रयास करूंगा।
सबसे पहले
हम सबसे अधिक पूछे जाने वाले प्रश्नों के साथ शुरुआत करने जा रहे हैं और उन पर अलग से विचार करेंगे।
यदि आपका डेटाबेस अचानक, बिना किसी स्पष्ट कारण के, धीरे-धीरे काम करना शुरू कर देता है, लेकिन आपने कुछ भी नहीं बदला है - सबसे पहले, आंकड़ों को अपडेट करें और इंडेक्स को फिर से बनाएं।
इंटरनेट पर इस तरह के बहुत सारे तरीके हैं, स्क्रिप्ट के उदाहरण दिए गए हैं। मैं मान लूंगा कि वे सभी तरीके पेशेवरों के लिए हैं। खैर, मैं सबसे आसान तरीका बताऊंगा:इसे लागू करने के लिए आपको केवल एक माउस की आवश्यकता है।
संक्षिप्त रूप
- SSMS Microsoft SQL सर्वर प्रबंधन स्टूडियो का एक अनुप्रयोग है। 2016 के संस्करण से शुरू होकर, यह एमएस वेबसाइट पर स्टैंडअलोन एप्लिकेशन के रूप में निःशुल्क उपलब्ध है। docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- प्रोफाइलर एसएसएमएस के साथ स्थापित "एसक्यूएल सर्वर प्रोफाइलर" का एक अनुप्रयोग है।
- प्रदर्शन मॉनिटर नियंत्रण कक्ष का एक स्नैप-इन है जो आपको प्रदर्शन काउंटरों की निगरानी करने, लॉग करने और माप के इतिहास को देखने की अनुमति देता है।
"सेवा योजना" का उपयोग करके आंकड़े अपडेट:
- एसएसएमएस चलाएं;
- आवश्यक सर्वर से कनेक्ट करें;
- ऑब्जेक्ट इंस्पेक्टर में ट्री का विस्तार करें:प्रबंधन\रखरखाव योजनाएं (सेवा योजनाएं);
- नोड पर राइट-क्लिक करें और "रखरखाव योजना विज़ार्ड" चुनें;
- विज़ार्ड में, आवश्यक कार्यों को चिह्नित करें:अनुक्रमणिका का पुनर्निर्माण करें और आंकड़े अपडेट करें
- आप दोनों कार्यों को एक साथ चिह्नित कर सकते हैं या प्रत्येक में एक कार्य के साथ दो रखरखाव योजनाएं बना सकते हैं (नीचे "महत्वपूर्ण नोट" देखें);
- आगे, हम एक आवश्यक डीबी (या कई डेटाबेस) की जांच करते हैं। हम इसे प्रत्येक कार्य के लिए करते हैं (यदि दो कार्यों को चुना जाता है, तो डेटाबेस की पसंद के साथ दो संवाद होंगे);
- अगला, अगला, समाप्त करें।
इन कार्यों के बाद, एक "रखरखाव योजना" बनाई जाएगी (निष्पादित नहीं)। आप इसे राइट-क्लिक करके और "निष्पादित करें" का चयन करके इसे मैन्युअल रूप से चला सकते हैं। वैकल्पिक रूप से, आप लॉन्च को SQL एजेंट के माध्यम से कॉन्फ़िगर करते हैं।
महत्वपूर्ण नोट:
- आंकड़ों को अपडेट करना एक नॉन-ब्लॉकिंग ऑपरेशन है। आप इसे एक कार्यशील मोड में निष्पादित कर सकते हैं।
- सूचकांक पुनर्निर्माण एक अवरोधन कार्य है। आप इसे काम के घंटों के बाहर ही चला सकते हैं। एक अपवाद है - सर्वर का एंटरप्राइज़ संस्करण "ऑनलाइन पुनर्निर्माण" के निष्पादन की अनुमति देता है। यह विकल्प कार्य सेटिंग्स में सक्षम किया जा सकता है। कृपया ध्यान दें कि सभी संस्करणों में एक चेकमार्क है, लेकिन यह केवल एंटरप्राइज़ में काम करता है।
- बेशक, इन कार्यों को नियमित रूप से किया जाना चाहिए। मैं यह निर्धारित करने का एक आसान तरीका सुझाता हूं कि आप इसे कितनी बार करते हैं:
- पहली समस्याओं के साथ, रखरखाव योजना निष्पादित करें;
- अगर यह मदद करता है, तब तक प्रतीक्षा करें जब तक कि समस्याएं फिर से न हों (आमतौर पर अगले मासिक समापन / वेतन गणना / थोक लेनदेन के आदि तक);
- एक सामान्य ऑपरेशन की परिणामी अवधि आपका संदर्भ बिंदु होगी;
- उदाहरण के लिए, रखरखाव योजना के निष्पादन को दो बार बार-बार कॉन्फ़िगर करें।
सर्वर धीमा है - आपको क्या करना चाहिए?
सर्वर द्वारा उपयोग किए जाने वाले संसाधन
किसी भी अन्य प्रोग्राम की तरह, सर्वर को प्रोसेसर समय, डिस्क पर डेटा, रैम की मात्रा और नेटवर्क बैंडविड्थ की आवश्यकता होती है।
टास्क मैनेजर आपको पहले सन्निकटन में किसी दिए गए संसाधन की कमी का आकलन करने में मदद करेगा, चाहे वह कितना भी भयानक क्यों न लगे।
सीपीयू लोड करें
यहां तक कि एक स्कूली छात्र भी प्रबंधक में उपयोग की जांच कर सकता है। हमें केवल यह सुनिश्चित करने की आवश्यकता है कि यदि प्रोसेसर लोड किया गया है, तो यह sqlserver.exe प्रक्रिया है।
यदि यह आपका मामला है, तो आपको यह समझने के लिए उपयोगकर्ता गतिविधि के विश्लेषण पर जाना होगा कि वास्तव में लोड का कारण क्या है (नीचे देखें)।
डिस्क लोआ डी
बहुत से लोग केवल CPU लोड को देखते हैं लेकिन भूल जाते हैं कि DBMS एक डेटा स्टोर है। डेटा की मात्रा बढ़ रही है, प्रोसेसर का प्रदर्शन बढ़ रहा है जबकि एचडीडी की गति काफी समान है। SSDs के साथ स्थिति बेहतर होती है, लेकिन उन पर टेराबाइट्स को स्टोर करना महंगा होता है।
यह पता चला है कि मैं अक्सर ऐसी स्थितियों का सामना करता हूं जहां सीपीयू के बजाय डिस्क सिस्टम अड़चन बन जाता है।
डिस्क के लिए, निम्नलिखित मीट्रिक महत्वपूर्ण हैं:
- औसत कतार लंबाई (बकाया I/O संचालन, संख्या);
- पढ़ने-लिखने की गति (एमबी/सेकेंड में)।
टास्क मैनेजर का सर्वर संस्करण, एक नियम के रूप में (सिस्टम संस्करण के आधार पर), दोनों को दिखाता है। यदि नहीं, तो प्रदर्शन मॉनीटर स्नैप-इन (सिस्टम मॉनीटर) चलाएँ। हम निम्नलिखित काउंटरों में रुचि रखते हैं:
- भौतिक (तार्किक) डिस्क/औसत पढ़ने (लिखने) समय
- भौतिक (तार्किक) डिस्क/औसत डिस्क कतार लंबाई
- भौतिक (तार्किक) डिस्क/डिस्क गति
अधिक विवरण के लिए, आप निर्माता के मैनुअल पढ़ सकते हैं, उदाहरण के लिए, यहां:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx।
संक्षेप में:
- कतार 1 से अधिक नहीं होनी चाहिए। शॉर्ट बर्स्ट की अनुमति है यदि वे जल्दी से कम हो जाते हैं। आपके सिस्टम के आधार पर बर्स्ट भिन्न हो सकते हैं। दो HDD के एक साधारण RAID दर्पण के लिए - 10-20 से अधिक की कतार एक समस्या है। सुपर कैशिंग के साथ एक शानदार लाइब्रेरी के लिए, मैंने 600-800 तक के विस्फोट देखे जिन्हें बिना किसी देरी के तुरंत हल किया गया था।
- सामान्य विनिमय दर डिस्क सिस्टम के प्रकार पर भी निर्भर करती है। सामान्य (डेस्कटॉप) एचडीडी 50-100 एमबी/एस पर प्रसारित होता है। एक अच्छी डिस्क लाइब्रेरी - 500 एमबी/एस और अधिक पर। छोटे यादृच्छिक संचालन के लिए, गति कम होती है। यह आपका संदर्भ बिंदु हो सकता है।
- इन मापदंडों को समग्र रूप से माना जाना चाहिए। यदि आपकी लाइब्रेरी 50MB/s और 50 ऑपरेशन लाइनों की एक कतार प्रसारित करती है - जाहिर है, हार्डवेयर में कुछ गड़बड़ है। यदि ट्रांसमिशन अधिकतम के करीब होने पर कतार लाइन हो जाती है - सबसे अधिक संभावना है, डिस्क को दोष नहीं दिया जाना चाहिए - वे और अधिक नहीं कर सकते हैं - हमें लोड को कम करने के लिए एक रास्ता तलाशने की जरूरत है।
- लोड को डिस्क पर अलग से जांचा जाना चाहिए (यदि उनमें से कई हैं) और सर्वर फ़ाइलों के स्थान के साथ तुलना की जानी चाहिए। कार्य प्रबंधक सबसे सक्रिय रूप से उपयोग की जाने वाली फ़ाइलें दिखा सकता है। इसका उपयोग यह सुनिश्चित करने के लिए किया जा सकता है कि लोड DBMS के कारण होता है।
डिस्क सिस्टम समस्याओं का कारण क्या हो सकता है:
- हार्डवेयर में समस्याएं
- कैश खत्म हो गया, प्रदर्शन में भारी गिरावट आई;
- डिस्क सिस्टम का उपयोग कुछ और करता है;
- रैम की कमी। अदला-बदली। aching क्षय हो गया, प्रदर्शन गिर गया (नीचे RAM के बारे में अनुभाग देखें)।
- उपयोगकर्ता लोड बढ़ गया। उपयोगकर्ताओं के काम का मूल्यांकन करना आवश्यक है (समस्याग्रस्त क्वेरी/नई कार्यक्षमता/उपयोगकर्ताओं की संख्या में वृद्धि/डेटा की मात्रा में वृद्धि/आदि)।
- डेटाबेस डेटा विखंडन (ऊपर अनुक्रमणिका पुनर्निर्माण देखें), सिस्टम फ़ाइलें विखंडन।
- डिस्क सिस्टम अपनी अधिकतम क्षमताओं तक पहुंच गया है।
अंतिम विकल्प के मामले में - हार्डवेयर को एक बार में बाहर न फेंके। कभी-कभी, यदि आप समस्या को समझदारी से हल करते हैं, तो आप सिस्टम से थोड़ा अधिक प्राप्त कर सकते हैं। अनुशंसित आवश्यकताओं के अनुपालन के लिए सिस्टम फ़ाइलों के स्थान की जाँच करें:
- OS फ़ाइलों को डेटाबेस डेटा फ़ाइलों के साथ न मिलाएं। उन्हें विभिन्न भौतिक मीडिया पर संग्रहीत करें ताकि सिस्टम I/O के लिए DBMS के साथ प्रतिस्पर्धा न करे।
- डेटाबेस में दो फ़ाइल प्रकार होते हैं:डेटा (*.mdf, *.ndf) और लॉग (*.ldf)।
डेटा फ़ाइलें, एक नियम के रूप में, ज्यादातर पढ़ने के लिए उपयोग की जाती हैं। लॉग लेखन के लिए काम करते हैं (जिसमें लेखन लगातार होता है)। इसलिए, विभिन्न भौतिक मीडिया पर लॉग और डेटा संग्रहीत करने की अनुशंसा की जाती है ताकि लॉगिंग डेटा रीडिंग को बाधित न करे (एक नियम के रूप में, लिखने के संचालन को पढ़ने पर प्राथमिकता होती है)। - MS SQL क्वेरी प्रोसेसिंग के लिए "अस्थायी तालिकाओं" का उपयोग कर सकता है। वे tempdb सिस्टम डेटाबेस में संग्रहीत हैं। यदि आपके पास इस डेटाबेस की फ़ाइलों पर बहुत अधिक भार है, तो आप इसे भौतिक रूप से अलग मीडिया पर प्रस्तुत करने का प्रयास कर सकते हैं।
फ़ाइल स्थान के साथ समस्या को सारांशित करते हुए, "फूट डालो और जीतो" के सिद्धांत का उपयोग करें। मूल्यांकन करें कि कौन सी फाइलें एक्सेस की गई हैं और उन्हें विभिन्न मीडिया में वितरित करने का प्रयास करें। साथ ही, RAID सिस्टम की विशेषताओं का उपयोग करें। उदाहरण के लिए, RAID-5 रीड लिखने की तुलना में तेज़ होते हैं - जो डेटा फ़ाइलों के लिए अच्छा है।
आइए जानें कि उपयोगकर्ता के प्रदर्शन के बारे में जानकारी कैसे प्राप्त करें:कौन क्या बनाता है, और कितने संसाधनों की खपत होती है
मैंने उपयोगकर्ता गतिविधि के ऑडिट के कार्यों को निम्नलिखित समूहों में विभाजित किया है:
- विशेष अनुरोध का विश्लेषण करने के कार्य।
- विशिष्ट परिस्थितियों में एप्लिकेशन से लोड का विश्लेषण करने के कार्य (उदाहरण के लिए, जब कोई उपयोगकर्ता डेटाबेस के साथ संगत तृतीय-पक्ष एप्लिकेशन में एक बटन पर क्लिक करता है)।
- वर्तमान स्थिति का विश्लेषण करने के कार्य।
आइए उनमें से प्रत्येक पर विस्तार से विचार करें।
चेतावनी
प्रदर्शन विश्लेषण के लिए डेटाबेस सर्वर और ऑपरेटिंग सिस्टम की संरचना और संचालन के सिद्धांतों की गहरी समझ की आवश्यकता होती है। इसलिए केवल इन लेखों को पढ़ने से आप पेशेवर नहीं बन जाएंगे।
वास्तविक प्रणालियों में माने गए मानदंड और काउंटर एक दूसरे पर बहुत अधिक निर्भर करते हैं। उदाहरण के लिए, उच्च HDD लोड अक्सर RAM की कमी के कारण होता है। यहां तक कि अगर आप कुछ माप करते हैं, तो यह समस्याओं का उचित आकलन करने के लिए पर्याप्त नहीं है।
लेखों का उद्देश्य सरल उदाहरणों पर अनिवार्यताओं का परिचय देना है। आपको मेरी सिफारिशों को एक मार्गदर्शक के रूप में नहीं मानना चाहिए। मेरा सुझाव है कि आप उन्हें प्रशिक्षण कार्यों के रूप में उपयोग करें जो विचारों के प्रवाह की व्याख्या कर सकते हैं।
मुझे आशा है कि आप सीखेंगे कि आंकड़ों में सर्वर के प्रदर्शन के बारे में अपने निष्कर्षों को कैसे युक्तिसंगत बनाया जाए।
"सर्वर धीमा हो जाता है" कहने के बजाय, आप विशिष्ट संकेतकों के विशिष्ट मान प्रदान करेंगे।
एक P का विश्लेषण करें कलात्मक R इक्वेस्ट
पहला बिंदु काफी सरल है, आइए इस पर संक्षेप में ध्यान दें। हम कुछ कम स्पष्ट मुद्दों पर विचार करेंगे।
क्वेरी परिणामों के अलावा, SSMS क्वेरी निष्पादन के बारे में अतिरिक्त जानकारी प्राप्त करने की अनुमति देता है:
- आप "अनुमानित निष्पादन योजना प्रदर्शित करें" और "वास्तविक निष्पादन योजना शामिल करें" बटन पर क्लिक करके क्वेरी योजना प्राप्त कर सकते हैं। उनके बीच अंतर यह है कि अनुमान योजना एक क्वेरी निष्पादन के बिना बनाई गई है। इस प्रकार, संसाधित पंक्तियों की संख्या के बारे में जानकारी का अनुमान लगाया जाएगा। वास्तविक योजना में, अनुमानित और वास्तविक डेटा दोनों होंगे। इन मूल्यों की मजबूत विसंगतियां दर्शाती हैं कि आंकड़े प्रासंगिक नहीं हैं। हालांकि, योजना का विश्लेषण एक अन्य लेख का विषय है - अब तक, हम गहराई में नहीं जाएंगे।
- हम सर्वर की प्रोसेसर लागत और डिस्क संचालन का माप प्राप्त कर सकते हैं। ऐसा करने के लिए, SET विकल्प को सक्षम करना आवश्यक है। आप इसे या तो 'क्वेरी विकल्प' डायलॉग बॉक्स में इस तरह कर सकते हैं:
या क्वेरी में सीधे SET कमांड के साथ:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDनतीजतन, हमें संकलन और निष्पादन पर खर्च किए गए समय के साथ-साथ डिस्क संचालन की संख्या पर डेटा मिलेगा।
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.मैं आपका ध्यान संकलन समय, तार्किक पठन 96 और भौतिक पठन 5 की ओर आकर्षित करना चाहूंगा। दूसरी बार और बाद में उसी क्वेरी को निष्पादित करते समय, भौतिक पठन कम हो सकता है, और पुनर्संकलन की आवश्यकता नहीं हो सकती है। इस तथ्य के कारण, अक्सर ऐसा होता है कि पहली बार की तुलना में दूसरे और बाद के समय में क्वेरी को तेजी से निष्पादित किया जाता है। कारण, जैसा कि आप समझते हैं, डेटा और संकलित क्वेरी योजनाओं को कैशिंग करना है।
- "क्लाइंट स्टैटिस्टिक्स शामिल करें" बटन नेटवर्क एक्सचेंज के बारे में जानकारी, निष्पादित संचालन की मात्रा और कुल निष्पादन समय को प्रदर्शित करता है, जिसमें क्लाइंट द्वारा नेटवर्क एक्सचेंज और प्रोसेसिंग की लागत शामिल है। उदाहरण से पता चलता है कि पहली बार क्वेरी को निष्पादित करने में अधिक समय लगता है:
- SSMS 2016 में, «लाइव क्वेरी सांख्यिकी शामिल करें» बटन है। यह छवि को क्वेरी योजना के मामले में प्रदर्शित करता है लेकिन इसमें संसाधित पंक्तियों के गैर-यादृच्छिक अंक होते हैं, जो क्वेरी को निष्पादित करते समय स्क्रीन पर बदलते हैं। तस्वीर बहुत स्पष्ट है - चमकते तीर और चल रहे नंबर, आप तुरंत देख सकते हैं कि समय कहाँ बर्बाद होता है। बटन SQL सर्वर 2014 और बाद के संस्करण के लिए भी काम करता है।
संक्षेप में:
- सेट स्टैटिस्टिक्स टाइम ऑन का उपयोग करके CPU लागतों की जांच करें।
- डिस्क संचालन:सांख्यिकी IO चालू करें। यह मत भूलो कि लॉजिक रीड डिस्क सिस्टम को भौतिक रूप से एक्सेस किए बिना डिस्क कैश में पूरा किया गया रीड ऑपरेशन है। "भौतिक पढ़ने" में अधिक समय लगता है।
- «ग्राहक सांख्यिकी शामिल करें» का उपयोग करके नेटवर्क ट्रैफ़िक की मात्रा का मूल्यांकन करें।
- "वास्तविक निष्पादन योजना शामिल करें" और "लाइव क्वेरी सांख्यिकी शामिल करें" का उपयोग करके निष्पादन योजना द्वारा क्वेरी निष्पादित करने के एल्गोरिदम का विश्लेषण करें।
एप्लिकेशन लोड का विश्लेषण करें
यहां हम SQL सर्वर प्रोफाइलर का उपयोग करेंगे। सर्वर से लॉन्च और कनेक्ट होने के बाद, लॉग इवेंट्स का चयन करना आवश्यक है। ऐसा करने के लिए, एक मानक ट्रेसिंग टेम्पलेट के साथ प्रोफाइलिंग चलाएँ। सामान्य . पर टेम्पलेट का उपयोग करें . में टैब पर जाएं फ़ील्ड, चुनें मानक (डिफ़ॉल्ट) और चलाएं . क्लिक करें ।
अधिक जटिल तरीका चयनित टेम्पलेट में/से फ़िल्टर या ईवेंट जोड़ना/छोड़ना है। ये विकल्प डायलॉग मेनू के दूसरे टैब पर मिल सकते हैं। संभावित ईवेंट और कॉलम की पूरी श्रृंखला देखने के लिए, सभी ईवेंट दिखाएं चुनें और सभी कॉलम दिखाएं चेकबॉक्स।

हमें निम्नलिखित घटनाओं की आवश्यकता होगी:
- संग्रहीत प्रक्रियाएं \ RPC:पूर्ण
- टीएसक्यूएल \ एसक्यूएल:बैचपूर्ण
ये ईवेंट सर्वर पर सभी बाहरी SQL कॉल की निगरानी करते हैं। वे क्वेरी प्रोसेसिंग के पूरा होने के बाद दिखाई देते हैं। ऐसी ही कुछ घटनाएँ हैं जो SQL सर्वर के प्रारंभ होने का ट्रैक रखती हैं:
- संग्रहीत प्रक्रियाएं \ RPC:प्रारंभ
- टीएसक्यूएल \ एसक्यूएल:बैचस्टार्टिंग
हालाँकि, हमें इन प्रक्रियाओं की आवश्यकता नहीं है क्योंकि उनमें क्वेरी निष्पादन पर खर्च किए गए सर्वर संसाधनों के बारे में जानकारी नहीं है। जाहिर सी बात है कि ऐसी जानकारी निष्पादन प्रक्रिया पूरी होने के बाद ही उपलब्ध होती है। इस प्रकार, *प्रारंभिक घटनाओं में सीपीयू, रीड्स, राइट्स पर डेटा वाले कॉलम खाली रहेंगे।
निम्नलिखित घटनाएं हमें भी रूचि दे सकती हैं, हालांकि, हम उन्हें अभी तक सक्षम नहीं करेंगे:
- संग्रहीत कार्यविधियाँ \ SP:प्रारंभ (*पूर्ण) ग्राहक से नहीं, बल्कि वर्तमान अनुरोध या अन्य प्रक्रिया के भीतर संग्रहीत कार्यविधि के लिए आंतरिक कॉल की निगरानी करता है।
- संग्रहीत कार्यविधियाँ \ SP:StmtStarting (*पूर्ण) संग्रहीत कार्यविधि के भीतर प्रत्येक कथन की शुरुआत को ट्रैक करता है। यदि प्रक्रिया में कोई चक्र है, तो चक्र में आदेशों के लिए घटनाओं की संख्या चक्र में पुनरावृत्तियों की संख्या के बराबर होगी।
- TSQL \ SQL:StmtStarting (*Completed) SQL-बैच के भीतर प्रत्येक स्टेटमेंट की शुरुआत की निगरानी करता है। यदि आपकी क्वेरी में कई आदेश हैं, तो उनमें से प्रत्येक में एक ईवेंट होगा। इस प्रकार, यह क्वेरी में स्थित कमांड के लिए काम करता है।
निष्पादन प्रक्रिया की निगरानी के लिए ये घटनाएँ सुविधाजनक हैं।
सी . द्वारा स्तम्भ
कौन सा कॉलम चुनना है यह बटन के नाम से स्पष्ट है। हमें निम्नलिखित की आवश्यकता होगी:
- TextData, BinaryData में क्वेरी टेक्स्ट होता है।
- सीपीयू, पढ़ता है, लिखता है, अवधि प्रदर्शन संसाधन खपत डेटा।
- स्टार्टटाइम, एंडटाइम निष्पादन प्रक्रिया शुरू करने और समाप्त करने का समय है। वे छँटाई के लिए सुविधाजनक हैं।
अपनी प्राथमिकताओं के आधार पर अन्य कॉलम जोड़ें।
कॉलम फ़िल्टर... बटन ईवेंट फ़िल्टर कॉन्फ़िगर करने के लिए संवाद बॉक्स खोलता है। यदि आप विशेष उपयोगकर्ता की गतिविधि में रुचि रखते हैं, तो आप SID नंबर या उपयोगकर्ता नाम द्वारा फ़िल्टर सेट कर सकते हैं। दुर्भाग्य से, ऐप-सर्वर के माध्यम से ऐप को कनेक्शन के पुल के साथ जोड़ने के मामले में, विशेष उपयोगकर्ता की निगरानी अधिक जटिल हो जाती है।
आप केवल जटिल प्रश्नों (अवधि>X) के चयन के लिए फ़िल्टर का उपयोग कर सकते हैं, वे प्रश्न जो गहन लेखन (लिखते> Y), साथ ही साथ क्वेरी सामग्री चयन आदि का कारण बनते हैं।
प्रोफाइलर से हमें और क्या चाहिए? बेशक, निष्पादन योजना!
ट्रेसिंग में «परफॉर्मेंस \ शोप्लान एक्सएमएल स्टैटिस्टिक्स प्रोफाइल» इवेंट को जोड़ना जरूरी है। हमारी क्वेरी निष्पादित करते समय, हमें निम्न छवि प्राप्त होगी:
क्वेरी टेक्स्ट:
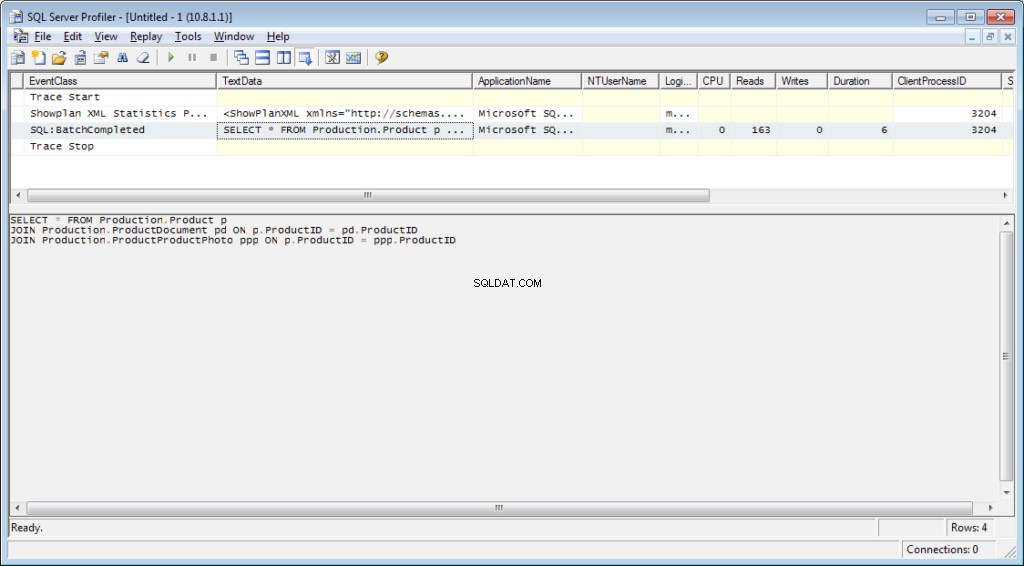
निष्पादन योजना:
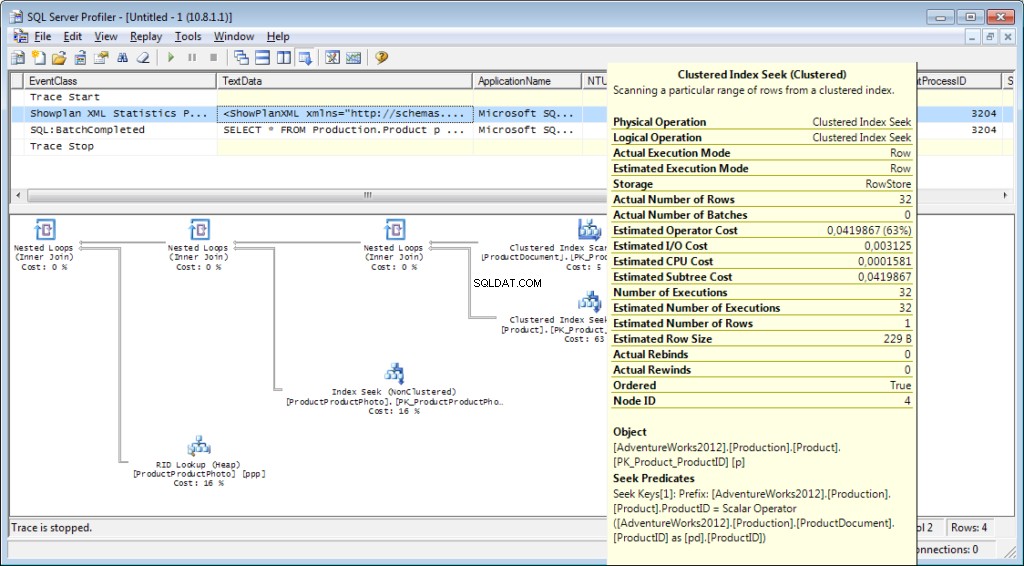
और यही सब कुछ नहीं है
किसी फ़ाइल या डेटाबेस तालिका में ट्रेस सहेजना संभव है। ट्रेसिंग सेटिंग्स को त्वरित रन के लिए व्यक्तिगत टेम्पलेट के रूप में संग्रहीत किया जा सकता है। आप केवल टी-एसक्यूएल कोड, और sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata प्रक्रियाओं का उपयोग करके, एक प्रोफाइलर के बिना ट्रेस चला सकते हैं। आप यहां एक उदाहरण पा सकते हैं। यह दृष्टिकोण उपयोगी हो सकता है, उदाहरण के लिए, किसी शेड्यूल पर किसी फ़ाइल में ट्रेस को स्वचालित रूप से संग्रहीत करना प्रारंभ करने के लिए। इन आदेशों का उपयोग कैसे करें, यह देखने के लिए आपके पास प्रोफाइलर पर एक डरपोक चोटी हो सकती है। आप दो निशान चला सकते हैं और उनमें से एक में ट्रैक कर सकते हैं कि दूसरा शुरू होने पर क्या होता है। जांचें कि प्रोफाइलर पर "एप्लिकेशननाम" कॉलम द्वारा कोई फ़िल्टर नहीं है।
प्रोफाइलर द्वारा निगरानी की जाने वाली घटनाओं की सूची बहुत बड़ी है और यह क्वेरी टेक्स्ट प्राप्त करने तक ही सीमित नहीं है। ऐसी घटनाएं हैं जो पूर्ण स्कैन, पुन:संकलन, ऑटोग्रो, डेडलॉक, और बहुत कुछ ट्रैक करती हैं।
सर्वर पर उपयोगकर्ता गतिविधि का विश्लेषण करना
अलग-अलग स्थितियां हैं। एक प्रश्न 'निष्पादन' पर लंबे समय तक लटका रह सकता है और यह स्पष्ट नहीं है कि यह पूरा होगा या नहीं। मैं समस्याग्रस्त क्वेरी का अलग से विश्लेषण करना चाहूंगा; हालांकि, हमें पहले यह निर्धारित करना होगा कि क्वेरी क्या है। इसे एक प्रोफाइलर के साथ पकड़ना बेकार है - हम पहले ही शुरुआती घटना को याद कर चुके हैं, और यह स्पष्ट नहीं है कि प्रक्रिया पूरी होने के लिए कितना इंतजार करना है।
आइए इसे समझें
आपने 'एक्टिविटी मॉनिटर' के बारे में तो सुना ही होगा। इसके उच्च संस्करणों में वास्तव में समृद्ध कार्यक्षमता है। यह हमारी कैसे मदद कर सकता है? एक्टिविटी मॉनिटर में कई उपयोगी और दिलचस्प विशेषताएं शामिल हैं। सिस्टम व्यू और फंक्शन से हमें वह सब कुछ मिलेगा जिसकी हमें जरूरत है। मॉनिटर स्वयं उपयोगी है क्योंकि आप उस पर प्रोफाइलर सेट कर सकते हैं और देख सकते हैं कि यह कौन सी क्वेरी करता है।
हमें आवश्यकता होगी:
- dm_exec_sessions कनेक्टेड उपयोगकर्ताओं के सत्रों के बारे में जानकारी प्रदान करता है। हमारे लेख के भीतर, उपयोगी क्षेत्र वे हैं जो एक उपयोगकर्ता (लॉगिन_नाम, लॉगिन_टाइम, होस्ट_नाम, प्रोग्राम_नाम, ...) की पहचान करते हैं और खर्च किए गए संसाधनों की जानकारी वाले फ़ील्ड (cpu_time, पढ़ता है, लिखता है, मेमोरी_यूसेज, …)
- dm_exec_requests इस समय निष्पादित प्रश्नों के बारे में जानकारी प्रदान करता है।
- session_id पिछले दृश्य से लिंक करने के लिए सत्र की पहचानकर्ता है।
- स्टार्ट_टाइम, व्यू रन का समय है।
- कमांड एक फ़ील्ड है जिसमें एक प्रकार का निष्पादित कमांड होता है। उपयोगकर्ता प्रश्नों के लिए, यह चयन/अद्यतन/हटाएं/ . है
- sql_handle, Statement_start_offset, Statement_end_offset क्वेरी टेक्स्ट को पुनः प्राप्त करने के लिए जानकारी प्रदान करते हैं:हैंडल, साथ ही क्वेरी के टेक्स्ट में प्रारंभ और समाप्ति स्थिति, जिसका अर्थ है कि वह भाग जो वर्तमान में निष्पादित किया जा रहा है (उस स्थिति के लिए जब आपकी क्वेरी में कई शामिल हैं आदेश)।
- plan_handle जनरेटेड प्लान का एक हैंडल है।
- blocking_session_id, उस सत्र की संख्या को इंगित करता है, जो क्वेरी के निष्पादन को रोकने वाले ब्लॉक होने पर अवरोध उत्पन्न करता है
- wait_type, Wait_time, Wait_resource वे क्षेत्र हैं जिनमें प्रतीक्षा के कारण और अवधि के बारे में जानकारी होती है। कुछ प्रकार की प्रतीक्षाओं के लिए, उदाहरण के लिए, डेटा लॉक, अवरुद्ध संसाधन के लिए अतिरिक्त रूप से एक कोड इंगित करना आवश्यक है।
- प्रतिशत_पूर्ण पूर्णता का प्रतिशत है। दुर्भाग्य से, यह केवल स्पष्ट रूप से पूर्वानुमेय प्रगति वाले आदेशों के लिए उपलब्ध है (उदाहरण के लिए, बैकअप या पुनर्स्थापना)।
- cpu_time, पढ़ता है, लिखता है, तार्किक_पढ़ता है, दी गई_क्वेरी_मेमोरी संसाधन लागत है।
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) टेक्स्ट और निष्पादन योजना प्राप्त करने के कार्य हैं। नीचे, हम इसके उपयोग के एक उदाहरण पर विचार करेंगे।
- dm_exec_query_stats क्वेरी निष्पादित करने के सारांश आँकड़े हैं। यह क्वेरी, इसके निष्पादन की संख्या और खर्च किए गए संसाधनों की मात्रा प्रदर्शित करता है।
महत्वपूर्ण नोट्स
उपरोक्त सूची सिर्फ एक छोटा सा हिस्सा है। दस्तावेज़ीकरण में सभी सिस्टम दृश्यों और कार्यों की पूरी सूची का वर्णन किया गया है। साथ ही, मुख्य वस्तुओं के बीच लिंक का आरेख दिखाते हुए एक सुंदर छवि है।
क्वेरी टेक्स्ट, इसकी योजना और निष्पादन आँकड़े प्रक्रिया कैश में संग्रहीत डेटा हैं। वे निष्पादन के दौरान उपलब्ध हैं। फिर, उपलब्धता की गारंटी नहीं है और कैश लोड पर निर्भर करता है। हां, कैश को मैन्युअल रूप से साफ किया जा सकता है। कभी-कभी, इसकी अनुशंसा तब की जाती है जब निष्पादन योजनाएँ 'फ़्लिप आउट' हो जाती हैं। फिर भी, बहुत सारी बारीकियाँ हैं।
उपयोगकर्ता अनुरोधों के लिए "कमांड" फ़ील्ड अर्थहीन है, क्योंकि हम पूरा टेक्स्ट प्राप्त कर सकते हैं। हालाँकि, सिस्टम प्रक्रियाओं के बारे में जानकारी प्राप्त करना बहुत महत्वपूर्ण है। एक नियम के रूप में, वे कुछ आंतरिक कार्य करते हैं और उनके पास SQL पाठ नहीं होता है। ऐसी प्रक्रियाओं के लिए, कमांड के बारे में जानकारी ही गतिविधि प्रकार का एकमात्र संकेत है।
पिछले लेख की टिप्पणियों में, एक सवाल था कि सर्वर को काम नहीं करना चाहिए, इसमें क्या शामिल है। इसका उत्तर शायद इस क्षेत्र के अर्थ में होगा। मेरे अभ्यास में, "कमांड" फ़ील्ड ने हमेशा सक्रिय सिस्टम प्रक्रियाओं के लिए काफी समझने योग्य कुछ प्रदान किया:ऑटोश्रिंक / ऑटोग्रो / चेकपॉइंट / लॉगराइटर / आदि।
इसका उपयोग कैसे करें
हम व्यावहारिक भाग में जाएंगे। मैं इसके उपयोग के कई उदाहरण दूंगा। सर्वर संभावनाएं सीमित नहीं हैं - आप अपने स्वयं के उदाहरणों के बारे में सोच सकते हैं।
उदाहरण 1. कौन सी प्रक्रिया CPU/रीड/राइट/मेमोरी की खपत करती है
सबसे पहले, उन सत्रों पर एक नज़र डालें जो अधिक संसाधनों का उपभोग करते हैं, उदाहरण के लिए, सीपीयू। आपको यह जानकारी sys.dm_exec_sessions में मिल सकती है। हालाँकि, सीपीयू पर डेटा, जिसमें पढ़ना और लिखना शामिल है, संचयी है। इसका मतलब है कि संख्या में कनेक्शन के सभी समय के लिए कुल शामिल है। यह स्पष्ट है कि जो उपयोगकर्ता एक महीने पहले जुड़ा था और डिस्कनेक्ट नहीं हुआ था, उसका मूल्य अधिक होगा। इसका मतलब यह नहीं है कि वे सिस्टम को ओवरलोड कर देते हैं।
निम्नलिखित एल्गोरिथम वाला एक कोड इस समस्या को हल कर सकता है:
- चुनें और उसे एक अस्थायी तालिका में संग्रहित करें
- थोड़ी देर प्रतीक्षा करें
- दूसरी बार चयन करें
- इन परिणामों की तुलना करें। उनका अंतर चरण 2 पर खर्च की गई लागतों को इंगित करेगा।
- सुविधा के लिए, औसत "लागत प्रति सेकंड" प्राप्त करने के लिए अंतर को चरण 2 की अवधि से विभाजित किया जा सकता है।
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 मैं कोड में दो तालिकाओं का उपयोग करता हूं:#tmp - पहले चयन के लिए, और # tmp1 - दूसरे के लिए। पहले रन के दौरान, स्क्रिप्ट एक सेकंड के अंतराल पर #tmp और #tmp1 बनाती और भरती है, और फिर अन्य कार्य करती है। अगले रन के साथ, स्क्रिप्ट तुलना के लिए आधार के रूप में पिछले निष्पादन के परिणामों का उपयोग करती है। इस प्रकार, चरण 2 की अवधि स्क्रिप्ट के चलने के बीच आपकी प्रतीक्षा की अवधि के बराबर होगी।
इसे उत्पादन सर्वर पर भी निष्पादित करने का प्रयास करें। स्क्रिप्ट केवल 'अस्थायी तालिकाएँ' बनाएगी (वर्तमान सत्र के भीतर उपलब्ध है और अक्षम होने पर हटा दी गई है) और इसमें कोई धागा नहीं है।
जो लोग MS SSMS में किसी क्वेरी को निष्पादित करना पसंद नहीं करते हैं, वे इसे अपनी पसंदीदा प्रोग्रामिंग भाषा में लिखे गए एप्लिकेशन में लपेट सकते हैं। मैं आपको दिखाता हूँ कि एमएस एक्सेल में कोड की एक पंक्ति के बिना यह कैसे करना है।
डेटा मेनू में, सर्वर से कनेक्ट करें। यदि आपको किसी तालिका का चयन करने के लिए कहा जाए, तो एक यादृच्छिक तालिका का चयन करें। अगला क्लिक करें और तब तक समाप्त करें जब तक आपको डेटा आयात संवाद दिखाई न दे. उस विंडो में, आपको Properties पर क्लिक करना होगा। गुणों में, कमांड प्रकार को SQL मान से बदलना और हमारी संशोधित क्वेरी को कमांड टेक्स्ट फ़ील्ड में सम्मिलित करना आवश्यक है।
आपको क्वेरी को थोड़ा संशोधित करना होगा:
- «सेट NOCOUNT ON» जोड़ें
- अस्थायी तालिकाओं को परिवर्तनीय तालिकाओं से बदलें
- विलंब 1 सेकंड के भीतर रहेगा। औसत मान वाले फ़ील्ड आवश्यक नहीं हैं
एक्सेल के लिए संशोधित क्वेरी
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id पर @tmp t से जुड़ें परिणाम:
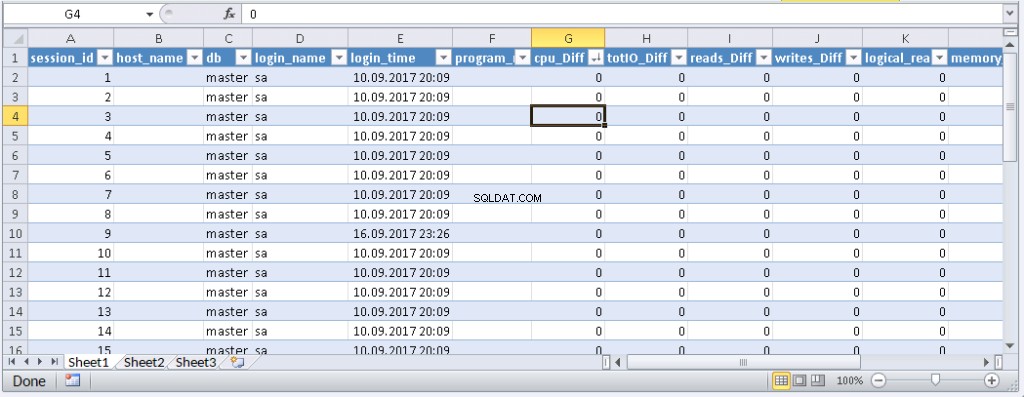
जब एक्सेल में डेटा दिखाई देता है, तो आप इसे आवश्यकतानुसार सॉर्ट कर सकते हैं। जानकारी को अद्यतन करने के लिए, 'ताज़ा करें' पर क्लिक करें। कार्यपुस्तिका सेटिंग्स में, आप एक निर्दिष्ट अवधि में "ऑटो-अपडेट" और "शुरुआत में अपडेट" डाल सकते हैं। आप फ़ाइल को सहेज सकते हैं और इसे अपने सहयोगियों को दे सकते हैं। इस प्रकार, हमने एक सुविधाजनक और सरल टूल बनाया है।
उदाहरण 2. सत्र किस पर संसाधन खर्च करता है?
अब, हम यह निर्धारित करने जा रहे हैं कि समस्या सत्र वास्तव में क्या करते हैं। ऐसा करने के लिए, क्वेरी टेक्स्ट और क्वेरी प्लान प्राप्त करने के लिए sys.dm_exec_requests और फ़ंक्शन का उपयोग करें।
सत्र संख्या द्वारा क्वेरी और निष्पादन योजना
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
क्वेरी में सत्र संख्या डालें और इसे चलाएँ। After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
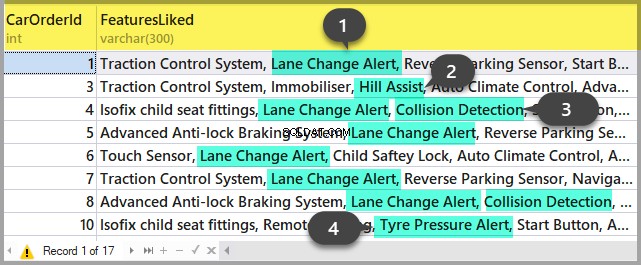
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
निष्कर्ष
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.