हाइब्रिड क्लाउड एक हालिया अवधारणा है जिसे कुछ वर्षों के लिए बढ़ा दिया गया है, और अब किसी भी कंपनी में डिजास्टर रिकवरी प्लान (डीआरपी) के लिए, या यहां तक कि आपके सिस्टम पर अतिरेक होने के लिए एक सामान्य टोपोलॉजी है।
एक बार जब आप अपना हाइब्रिड क्लाउड वातावरण तैयार कर लेते हैं, तो आपको यह जानना होगा कि हर समय क्या हो रहा है। यदि आप यह सुनिश्चित करना चाहते हैं कि सब कुछ ठीक चल रहा है या यदि आपको कुछ बदलने की आवश्यकता हो तो निगरानी आवश्यक है। प्रत्येक डेटाबेस तकनीक के लिए, निगरानी करने के लिए कई चीजें हैं। इनमें से कुछ डेटाबेस इंजन, विक्रेता, या यहां तक कि आपके द्वारा उपयोग किए जा रहे विशिष्ट संस्करण के लिए विशिष्ट हैं।
इस ब्लॉग में, हम देखेंगे कि हाइब्रिड क्लाउड वातावरण पर चलने वाले PostgreSQL डेटाबेस में आपको क्या मॉनिटर करने की आवश्यकता है और इस कार्य में ClusterControl आपकी कैसे मदद कर सकता है।
PostgreSQL में क्या मॉनिटर करना है
डेटाबेस क्लस्टर या नोड की निगरानी करते समय, दो मुख्य बातों को ध्यान में रखना चाहिए:ऑपरेटिंग सिस्टम और डेटाबेस स्वयं। आपको यह परिभाषित करने की आवश्यकता होगी कि आप दोनों पक्षों से किन मीट्रिक्स की निगरानी करने जा रहे हैं और आप इसे कैसे करने जा रहे हैं।
ध्यान रखें कि जब आपकी कोई एक मेट्रिक प्रभावित होती है, तो यह अन्य को भी प्रभावित कर सकती है, जिससे समस्या का निवारण अधिक जटिल हो जाता है। इस कार्य को यथासंभव सरल बनाने के लिए एक अच्छी निगरानी और चेतावनी प्रणाली का होना महत्वपूर्ण है।
ऑपरेटिंग सिस्टम मॉनिटरिंग
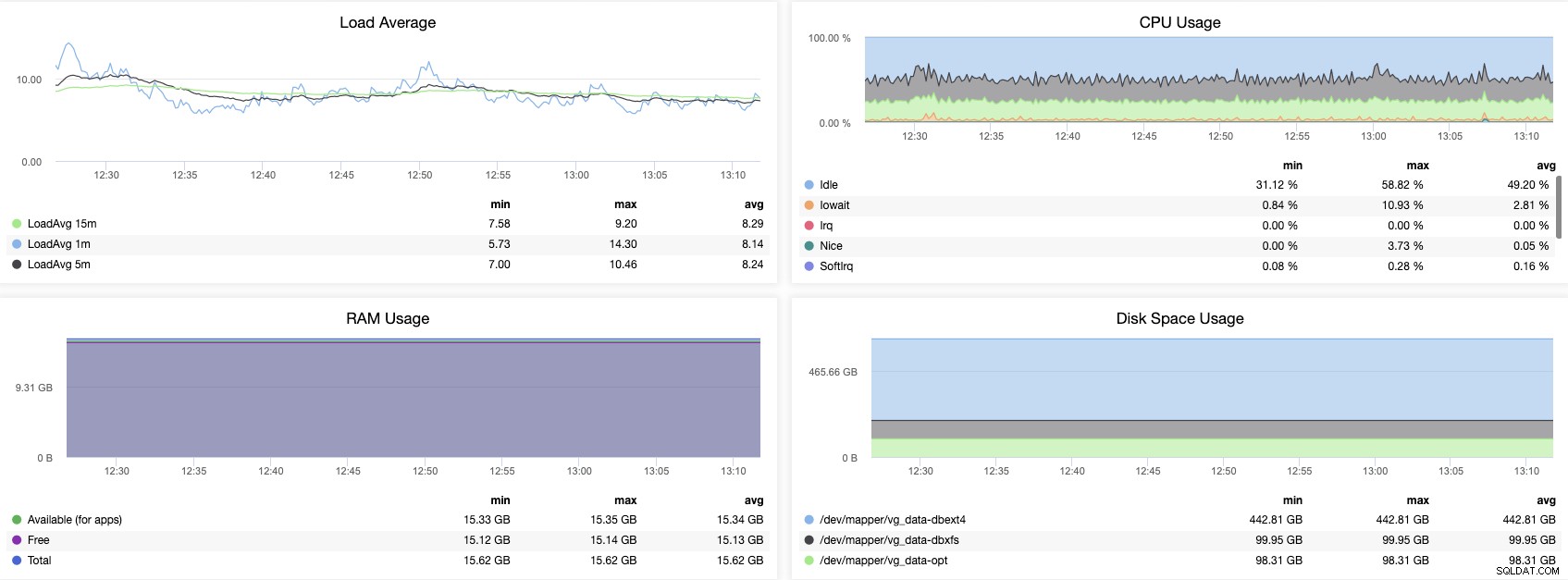
एक महत्वपूर्ण बात (जो सभी डेटाबेस इंजनों और यहां तक कि सभी प्रणालियों के लिए समान है) ऑपरेटिंग सिस्टम व्यवहार की निगरानी करना है। आइए यहां जांच करने के लिए कुछ बिंदु देखें।
CPU उपयोग
यदि सामान्य व्यवहार नहीं है तो CPU उपयोग का अत्यधिक प्रतिशत एक समस्या हो सकती है। इस मामले में, इस मुद्दे को उत्पन्न करने वाली प्रक्रिया/प्रक्रियाओं की पहचान करना महत्वपूर्ण है। यदि समस्या डेटाबेस प्रक्रिया है, तो आपको यह जांचना होगा कि डेटाबेस के अंदर क्या हो रहा है।
RAM मेमोरी या स्वैप उपयोग
यदि आप इस मीट्रिक के लिए एक उच्च मान देख रहे हैं और आपके सिस्टम में कुछ भी नहीं बदला है, तो संभवतः आपको अपने डेटाबेस कॉन्फ़िगरेशन की जांच करने की आवश्यकता है। Shared_buffers और work_mem जैसे पैरामीटर इसे सीधे प्रभावित कर सकते हैं क्योंकि वे PostgreSQL डेटाबेस के लिए उपयोग की जाने वाली मेमोरी की मात्रा को परिभाषित करते हैं।
डिस्क उपयोग
डिस्क स्थान के उपयोग में असामान्य वृद्धि या अत्यधिक डिस्क एक्सेस खपत पर नजर रखने के लिए महत्वपूर्ण चीजें हैं क्योंकि पोस्टग्रेएसक्यूएल लॉग फ़ाइल में बड़ी संख्या में त्रुटियां लॉग हो सकती हैं या खराब कैश कॉन्फ़िगरेशन हो सकता है प्रश्नों को संसाधित करने के लिए मेमोरी का उपयोग करने के बजाय एक महत्वपूर्ण डिस्क एक्सेस खपत उत्पन्न करें।
लोड औसत
यह ऊपर बताए गए तीन बिंदुओं से संबंधित है। अत्यधिक CPU, RAM, या डिस्क उपयोग द्वारा एक उच्च लोड औसत उत्पन्न किया जा सकता है।
नेटवर्क
एक नेटवर्क समस्या सभी सिस्टम को प्रभावित कर सकती है क्योंकि एप्लिकेशन डेटाबेस से कनेक्ट नहीं हो सकता (या पैकेज खोने को कनेक्ट कर सकता है), इसलिए यह वास्तव में मॉनिटर करने के लिए एक महत्वपूर्ण मीट्रिक है। आप विलंबता या पैकेट हानि की निगरानी कर सकते हैं, और मुख्य समस्या एक नेटवर्क संतृप्ति, एक हार्डवेयर समस्या, या केवल एक खराब नेटवर्क कॉन्फ़िगरेशन हो सकती है।
डेटाबेस निगरानी
अपने PostgreSQL डेटाबेस की निगरानी करना न केवल यह देखने के लिए महत्वपूर्ण है कि क्या आपको कोई समस्या हो रही है, बल्कि यह भी जानना है कि क्या आपको अपने डेटाबेस के प्रदर्शन को बेहतर बनाने के लिए कुछ बदलने की आवश्यकता है, जो शायद सबसे महत्वपूर्ण चीजों में से एक है। एक डेटाबेस में निगरानी करने के लिए। आइए देखते हैं कुछ मेट्रिक्स जो इसके लिए महत्वपूर्ण हैं।
क्वेरी मॉनिटरिंग
सामान्य तौर पर, डेटाबेस डिफ़ॉल्ट रूप से संगतता और स्थिरता को ध्यान में रखते हुए कॉन्फ़िगर किए जाते हैं, इसलिए आपको अपने प्रश्नों और उनके पैटर्न को जानना होगा, और आपके पास मौजूद ट्रैफ़िक के आधार पर अपने डेटाबेस को कॉन्फ़िगर करना होगा। यहां, आप किसी विशिष्ट क्वेरी के लिए क्वेरी प्लान की जांच करने के लिए EXPLAIN कमांड का उपयोग कर सकते हैं, और आप प्रत्येक नोड पर SELECT, INSERT, UPDATE, या DELETEs की मात्रा की निगरानी भी कर सकते हैं। यदि आपके पास एक ही समय में एक लंबी क्वेरी या बड़ी संख्या में क्वेरी चल रही हैं, तो यह सभी प्रणालियों के लिए एक समस्या हो सकती है।
सक्रिय सत्र
आपको सक्रिय सत्रों की संख्या पर भी नजर रखनी चाहिए। यदि आप सीमा के करीब हैं, तो आपको यह जांचना होगा कि क्या कुछ गलत है या यदि आपको डेटाबेस कॉन्फ़िगरेशन में अधिकतम कनेक्शन मान बढ़ाने की आवश्यकता है। संख्या में अंतर कनेक्शन की वृद्धि या कमी हो सकती है। कनेक्शन पूलिंग, लॉकिंग या नेटवर्क समस्याओं का गलत उपयोग कनेक्शन की संख्या से संबंधित सबसे आम समस्याएं हैं।
डेटाबेस लॉक
यदि आपके पास कोई प्रश्न है जो किसी अन्य प्रश्न की प्रतीक्षा कर रहा है, तो आपको यह जांचना होगा कि क्या वह अन्य प्रश्न एक सामान्य प्रक्रिया है या कुछ नया है। कुछ मामलों में, अगर कोई बड़ी टेबल पर अपडेट कर रहा है, उदाहरण के लिए, यह क्रिया आपके डेटाबेस के सामान्य व्यवहार को प्रभावित कर सकती है, जिससे बड़ी संख्या में ताले बन सकते हैं।
प्रतिकृति स्थिति
प्रतिकृति की निगरानी के लिए प्रमुख मीट्रिक अंतराल और प्रतिकृति स्थिति हैं। सबसे आम मुद्दे नेटवर्किंग मुद्दे, हार्डवेयर संसाधन मुद्दे, या कम आयाम वाले मुद्दे हैं। यदि आप एक प्रतिकृति समस्या का सामना कर रहे हैं, तो आपको इसे जल्द से जल्द जानना होगा क्योंकि उच्च उपलब्धता वातावरण सुनिश्चित करने के लिए आपको इसे ठीक करने की आवश्यकता होगी।
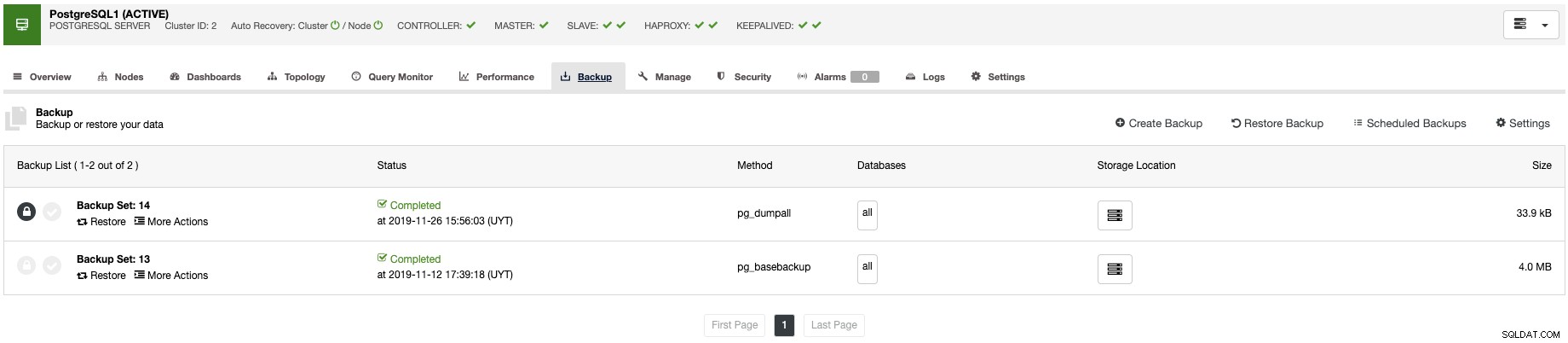
बैकअप
डेटा हानि से बचना बुनियादी डीबीए कार्यों में से एक है, इसलिए आपको केवल बैकअप लेने की आवश्यकता नहीं है, आपको पता होना चाहिए कि क्या बैकअप पूरा हो गया था, और यदि यह प्रयोग करने योग्य है। आमतौर पर, इस अंतिम बिंदु पर ध्यान नहीं दिया जाता है, लेकिन बैकअप प्रक्रिया में शायद यह सबसे महत्वपूर्ण जांच है।
डेटाबेस लॉग
आपको त्रुटियों, प्रमाणीकरण समस्याओं, या यहां तक कि लंबे समय तक चलने वाली क्वेरी के लिए अपने डेटाबेस लॉग की निगरानी करनी चाहिए। अधिकांश त्रुटियों को ठीक करने के लिए विस्तृत उपयोगी जानकारी के साथ लॉग फ़ाइल में लिखा जाता है।
सूचनाएं और चेतावनी
यदि आपको प्रत्येक समस्या के बारे में सूचना प्राप्त नहीं होती है, तो केवल सिस्टम की निगरानी करना पर्याप्त नहीं है। चेतावनी प्रणाली के बिना, आपको यह देखने के लिए निगरानी उपकरण पर जाना चाहिए कि क्या सब कुछ ठीक है, और यह संभव हो सकता है कि आपको कई घंटे पहले से कोई बड़ी समस्या हो रही हो। अलर्ट करने का यह कार्य ईमेल अलर्ट, टेक्स्ट अलर्ट या स्लैक जैसे अन्य टूल का उपयोग करके किया जा सकता है।
पोस्टग्रेएसक्यूएल के लिए सभी आवश्यक मेट्रिक्स की निगरानी के लिए एक उपकरण खोजना वास्तव में मुश्किल है, सामान्य तौर पर, आपको एक से अधिक का उपयोग करने की आवश्यकता होगी और यहां तक कि कुछ स्क्रिप्टिंग की भी आवश्यकता होगी। मॉनिटरिंग और अलर्टिंग कार्य को केंद्रीकृत करने का एक तरीका क्लस्टरकंट्रोल का उपयोग करना है, जो आपको बैकअप प्रबंधन, मॉनिटरिंग और अलर्टिंग, परिनियोजन और स्केलिंग, स्वचालित पुनर्प्राप्ति, और आपके डेटाबेस को प्रबंधित करने में मदद करने के लिए अधिक महत्वपूर्ण सुविधाएँ प्रदान करता है। ये सभी सुविधाएं एक ही सिस्टम पर हैं।
यहाँ एक महत्वपूर्ण बिंदु यह है कि ClusterControl क्लाउड, ऑन-प्रिमाइसेस, या यहाँ तक कि दोनों के संयोजन पर काम करता है। यहाँ आवश्यकता नोड्स तक SSH की पहुँच की है, और फिर, ClusterControl उनकी देखभाल करेगा।
ClusterControl के साथ अपने PostgreSQL डेटाबेस की निगरानी करना
ClusterControl एक प्रबंधन और निगरानी प्रणाली है जो आपके डेटाबेस को एक अनुकूल इंटरफेस से तैनात, प्रबंधित, मॉनिटर और स्केल करने में मदद करती है। इसमें शीर्ष ओपन-सोर्स डेटाबेस प्रौद्योगिकियों के लिए समर्थन है और आप नियमित रूप से प्रदर्शन करने वाले कई डेटाबेस कार्यों को स्वचालित कर सकते हैं जैसे नए नोड्स जोड़ना और स्केल करना, बैकअप चलाना और पुनर्स्थापित करना, और बहुत कुछ।
ClusterControl आपको कुछ सबसे सामान्य मीट्रिक का विश्लेषण करने के लिए डैशबोर्ड के पूर्वनिर्धारित सेट के साथ रीयल-टाइम में अपने सर्वर की निगरानी करने की अनुमति देता है।
यह आपको क्लस्टर में उपलब्ध ग्राफ़ को अनुकूलित करने की अनुमति देता है, और आप अधिक विस्तृत डैशबोर्ड बनाने के लिए एजेंट-आधारित निगरानी को सक्षम कर सकते हैं।
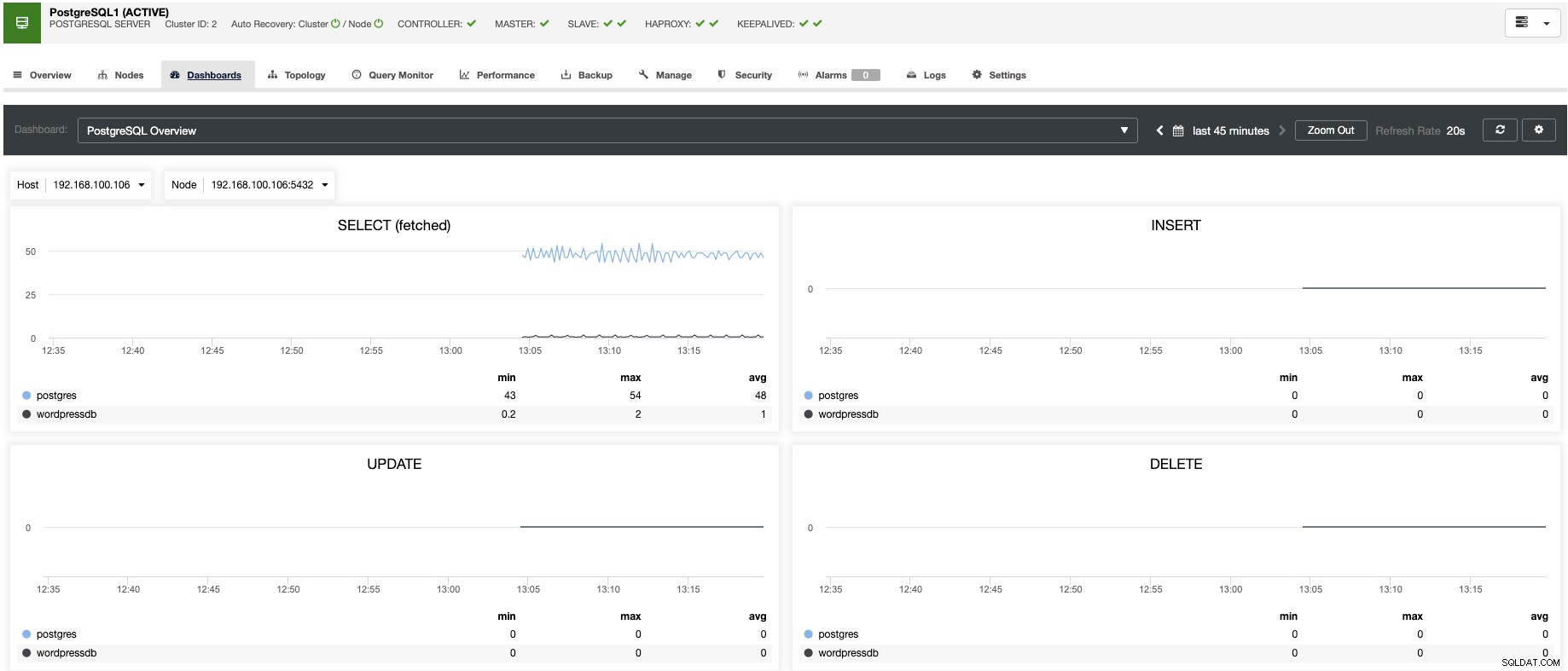
आप अलर्ट भी बना सकते हैं, जो आपको आपके क्लस्टर में होने वाली घटनाओं की सूचना देते हैं, या पेजरड्यूटी या स्लैक जैसी विभिन्न सेवाओं के साथ एकीकृत करते हैं।
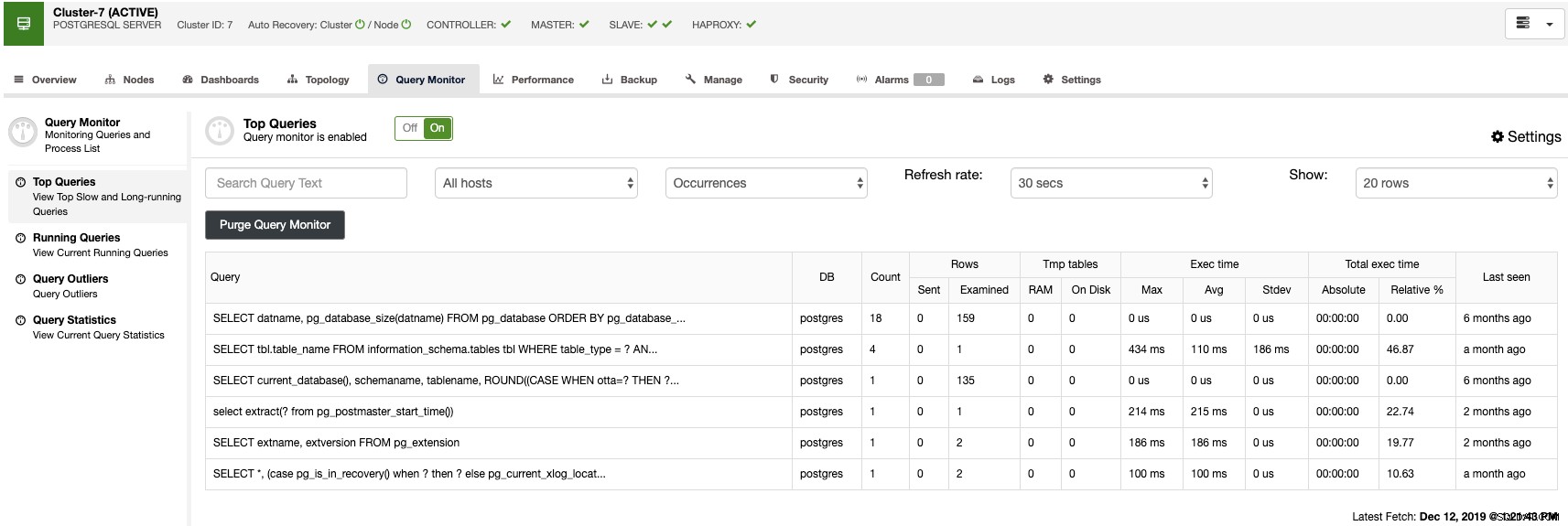
क्वेरी मॉनिटर सेक्शन में, आप अपने डेटाबेस ट्रैफिक पर नजर रखने के लिए शीर्ष क्वेरी, चल रही क्वेरी, क्वेरी आउटलेयर और क्वेरी आंकड़े पा सकते हैं।
इन सुविधाओं के साथ, आप देख सकते हैं कि आपका PostgreSQL डेटाबेस कैसा चल रहा है।
बैकअप प्रबंधन के लिए, ClusterControl इसे आपके डेटा की सुरक्षा, सुरक्षा और पुनर्प्राप्ति के लिए केंद्रीकृत करता है, और सत्यापन बैकअप सुविधा के साथ, आप पुष्टि कर सकते हैं कि बैकअप जाना अच्छा है या नहीं।
यह सत्यापन बैकअप कार्य बैकअप को एक अलग स्टैंडअलोन होस्ट में पुनर्स्थापित करेगा, ताकि आप सुनिश्चित कर सकें कि बैकअप काम कर रहा है।
आखिरकार, आपको लॉग्स की जांच करने के लिए अपने डेटाबेस नोड तक पहुंचने की आवश्यकता नहीं है, आप अपने सभी डेटाबेस लॉग को ClusterControl लॉग सेक्शन में केंद्रीकृत पा सकते हैं।
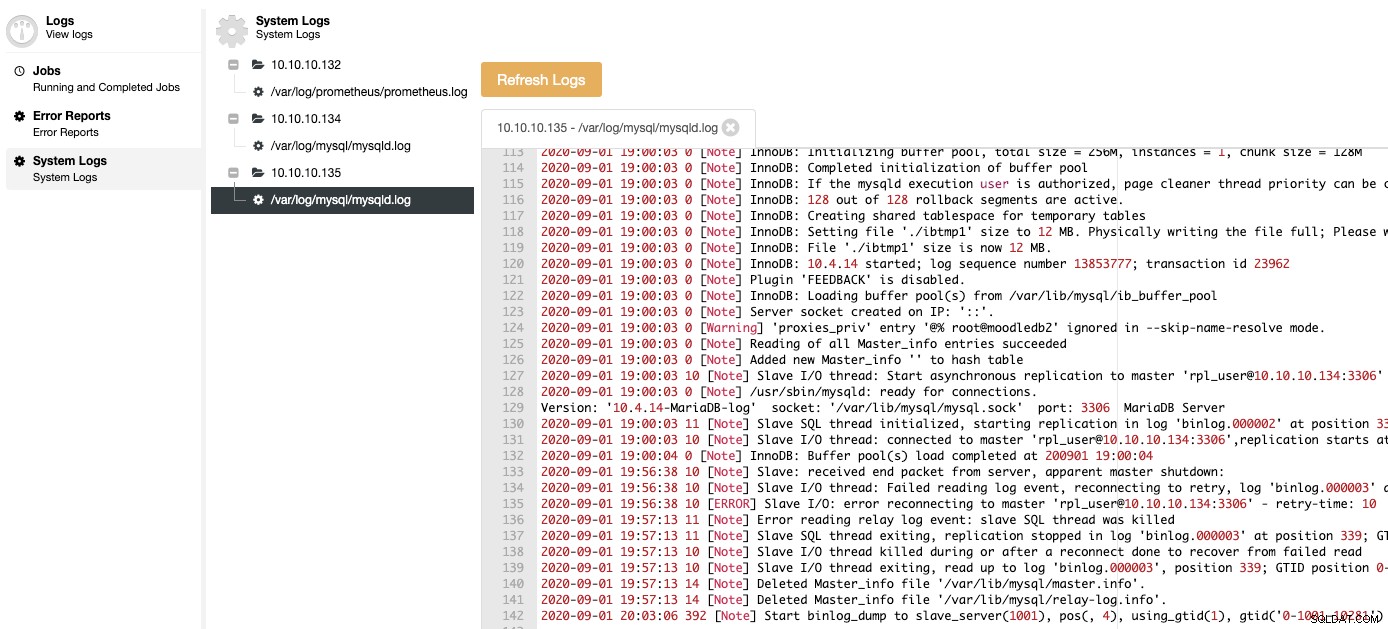
जैसा कि आप देख सकते हैं, आप एक ही केंद्रीकृत प्रणाली से सभी उल्लिखित चीजों को संभाल सकते हैं:ClusterControl।
ClusterControl कमांड लाइन से निगरानी करना
स्क्रिप्टिंग और कार्यों को स्वचालित करने के लिए, या यदि आप केवल कमांड लाइन पसंद करते हैं, तो ClusterControl में s9s टूल है। यह आपके डेटाबेस क्लस्टर के प्रबंधन या निगरानी के लिए एक कमांड-लाइन टूल है।
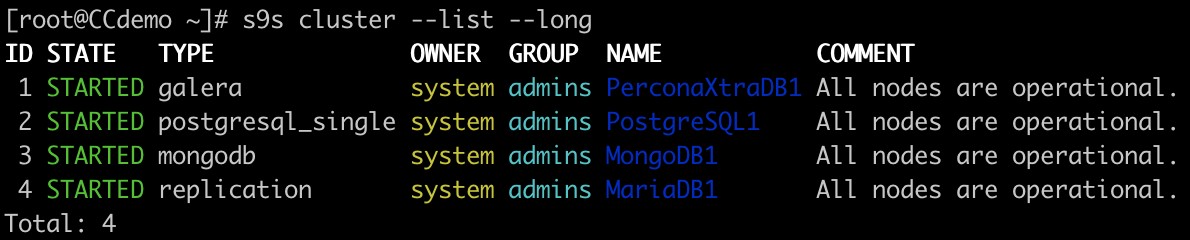
क्लस्टर सूची
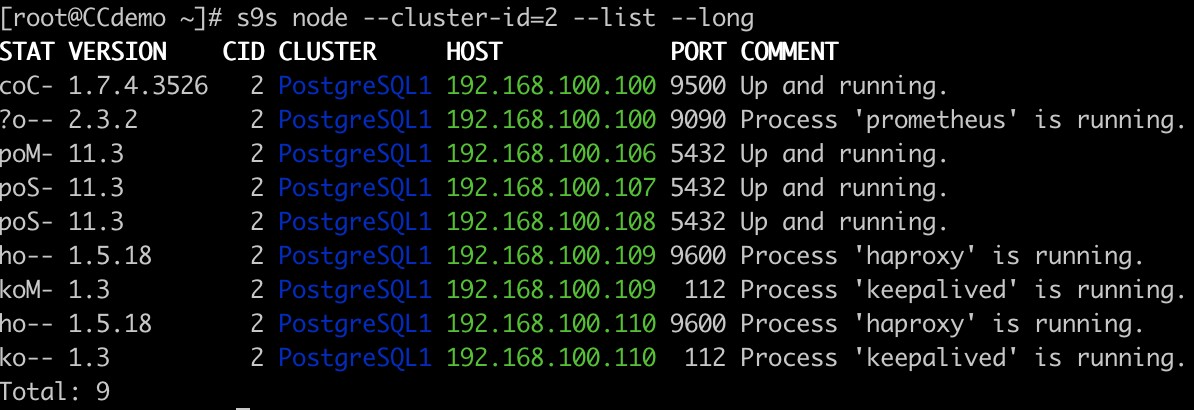
नोड सूची
आप ClusterControl UI में उपलब्ध सभी कार्यों (और इससे भी अधिक) को निष्पादित कर सकते हैं, और आप इस सुविधा को वहां से प्रबंधित करने के लिए स्लैक जैसे कुछ बाहरी टूल के साथ एकीकृत कर सकते हैं।
निष्कर्ष
जैसा कि आप देख सकते हैं, निगरानी नितांत आवश्यक है, चाहे वह ऑन-प्रिमाइसेस, क्लाउड पर, या यहां तक कि उनके मिश्रण पर भी चल रहा हो, और यह कैसे करना है इसका सबसे अच्छा तरीका बुनियादी ढांचे और सिस्टम पर ही निर्भर करता है। इस ब्लॉग में, हमने आपके PostgreSQL वातावरण में निगरानी के लिए कुछ महत्वपूर्ण मेट्रिक्स का उल्लेख किया है, काम करने के लिए ClusterControl का उपयोग कैसे करें।