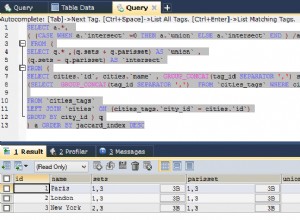
IME, MySQL उप-प्रश्नों को अनुकूलित करने में अच्छा नहीं करता है - विशेष रूप से यह पुश-विधेय को प्रबंधित नहीं करता है।
मैं इस बारे में थोड़ा उलझन में हूं कि वास्तव में क्वेरी का क्या इरादा है - विशेष रूप से 'उप-अभिभावक'
बाएं_आईडी और दाएं_आईडी को एक ही इंडेक्स में डालने से आपको कुछ सुधार मिलेगा।
जबकि आप क्वेरी को एक संग्रहीत प्रक्रिया में अनियंत्रित करके कुछ सुधार प्राप्त करेंगे, यह देखते हुए कि आप हर बार लगभग पूरे डेटासेट का पता लगा रहे हैं, एक बेहतर समाधान यह होगा कि पेड़ की गहराई को कम किया जाए और इसे प्रत्येक नोड के लिए एक विशेषता के रूप में संग्रहीत किया जाए। वास्तव में ऐसा लगता है कि आप इसे केवल बाहरी क्वेरी में कम से कम दो बार पार कर रहे हैं।
हालांकि मैंने देखा कि क्वेरी के अंत में:
HAVING depth > 0
AND depth <= 1
जो निश्चित रूप से वही है जो
HAVING depth=1
जो तब क्वेरी को अनुकूलित करने का एक बहुत ही अलग तरीका प्रदान करता है (सभी नोड्स प्राप्त करके प्रारंभ करें जहां दाएं =बाएं + 1 बिना बच्चों वाले नोड्स को खोजने के लिए और श्रेणी आईडी की जांच करने के तरीके पर काम करते हैं)।