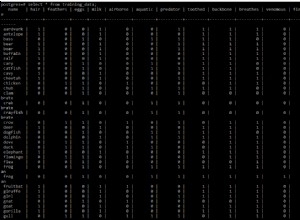
बहुत खूब! मैंने देखा है कि यह सबसे जटिल "इंडेक्स मर्ज" है।
आमतौर पर (शायद हमेशा ), आप एक इंडेक्स-मर्ज-इंटरसेक्ट को बदलने के लिए 'समग्र' इंडेक्स बना सकते हैं, और बेहतर प्रदर्शन कर सकते हैं . बदलें key2 केवल (pinned) . से करने के लिए (pinned, DeviceId) . यह हो सकता है 'छेड़छाड़' से छुटकारा पाएं और इसे तेज करें।
सामान्य तौर पर, ऑप्टिमाइज़र केवल हताशा में इंडेक्स मर्ज का उपयोग करता है। (मुझे लगता है कि यह शीर्षक प्रश्न का उत्तर है।) क्वेरी या शामिल मूल्यों में कोई भी मामूली परिवर्तन, और ऑप्टिमाइज़र इंडेक्स मर्ज के बिना क्वेरी निष्पादित करेगा।
अस्थायी तालिका में सुधार __codes मूल्यों की एक बड़ी श्रृंखला के साथ एक स्थायी तालिका बनाना है, फिर अपने प्रो के अंदर उस तालिका से मूल्यों की एक श्रृंखला का उपयोग करें। यदि आप मारियाडीबी का उपयोग कर रहे हैं, तो गतिशील रूप से निर्मित "अनुक्रम" तालिका का उपयोग करें। उदाहरण के लिए 'टेबल' seq_1_to_100 प्रभावी ढंग से . है संख्या 1..100 के साथ एक कॉलम की एक तालिका। इसे घोषित करने या इसे आबाद करने की कोई आवश्यकता नहीं है।
आप अन्य REPEAT से छुटकारा पा सकते हैं कंप्यूटिंग . द्वारा लूप Code . से समय ।
LOOPs . से बचना सबसे बड़ा प्रदर्शन लाभ होगा।
वह सब कर लें, तब मेरे पास अन्य सुझाव हो सकते हैं।