Mysql में कार्डिनैलिटी एक अनुमान है , और mysql अपने अनुमान को तालिका उपयोग के आंकड़ों पर आधारित करता है:
आप myisam और innodb टेबल इंजन के लिए एकत्र किए गए आँकड़ों के बारे में अधिक पढ़ सकते हैं mysql's और innodb के दस्तावेज़ों में और इन्हें कैसे कॉन्फ़िगर करें:
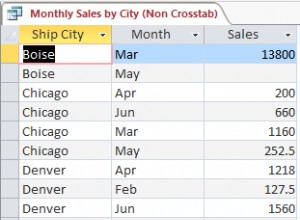
सभी आंकड़े सांख्यिकी तालिका में संगृहीत हैं info_schema के भीतर।
इंडेक्स, जो अनुमानित कार्डिनैलिटी उनकी सटीक कार्डिनैलिटी (क्षेत्र के भीतर अलग-अलग मूल्यों की संख्या) के करीब हैं, लंबे समय पहले बनाए गए थे, इसलिए MySQL ने उनके लिए अधिक आंकड़े एकत्र किए और इसका अनुमान अधिक सटीक है। यदि आप analyse table चलाते हैं इस विशेष तालिका पर, शायद डुप्लिकेट इंडेक्स की कार्डिनैलिटी अब की तुलना में एक-दूसरे के बहुत करीब होगी।
बड़ा सवाल यह है कि आपके पास डुप्लीकेट इंडेक्स क्यों हैं?