कभी-कभी किसी कंपनी में बड़ी मात्रा में डेटा का प्रबंधन करना कठिन होता है, विशेष रूप से डेटा एनालिटिक्स और IoT उपयोग के घातीय वृद्धि के साथ। आकार के आधार पर, डेटा की यह मात्रा आपके सिस्टम के प्रदर्शन को प्रभावित कर सकती है और आपको शायद अपने डेटाबेस को स्केल करना होगा या इसे ठीक करने का कोई तरीका खोजना होगा। आपके PostgreSQL डेटाबेस को स्केल करने के विभिन्न तरीके हैं और उनमें से एक है शेयरिंग। इस ब्लॉग में, हम देखेंगे कि Sharding क्या है और कार्य को सरल बनाने के लिए ClusterControl का उपयोग करके PostgreSQL में इसे कैसे कॉन्फ़िगर किया जाए।
शेयरिंग क्या है?
शेयरिंग एक बड़ी तालिका से डेटा को कई छोटी तालिका में अलग करके डेटाबेस को अनुकूलित करने की क्रिया है। छोटी तालिकाएँ शार्प (या विभाजन) हैं। विभाजन और साझाकरण समान अवधारणाएं हैं। मुख्य अंतर यह है कि शार्डिंग का अर्थ है कि डेटा कई कंप्यूटरों में फैला हुआ है, जबकि विभाजन एक डेटाबेस उदाहरण के भीतर डेटा के सबसेट को समूहीकृत करने के बारे में है।
शेयरिंग दो प्रकार की होती है:
-
क्षैतिज साझाकरण:प्रत्येक नई तालिका में बड़ी तालिका के समान स्कीमा होती है लेकिन अद्वितीय पंक्तियां होती हैं। यह तब उपयोगी होता है जब क्वेरीज़ पंक्तियों का एक सबसेट लौटाती हैं जिन्हें अक्सर एक साथ समूहीकृत किया जाता है।
-
वर्टिकल शेयरिंग:प्रत्येक नई तालिका में एक स्कीमा होता है जो मूल तालिका के स्कीमा का सबसेट होता है। यह तब उपयोगी होता है जब क्वेरीज़ डेटा के स्तंभों का केवल एक सबसेट लौटाती हैं।
आइए एक उदाहरण देखें:
मूल तालिका
| ID | <थ स्कोप="col"> देश | ||
|---|---|---|---|
| 1 | जेम्स स्मिथ | 26 | यूएसए |
| 2 | मैरी जॉनसन | 31 | जर्मनी |
| 3 | रॉबर्ट विलियम्स | 54 | कनाडा |
| 4 | जेनिफर ब्राउन | 47 | फ्रांस |
वर्टिकल शेयरिंग
| Shard1 | <वें colspan="2" स्कोप="col"> ||||
|---|---|---|---|---|
| ID | नाम | आयु | आईडी | देश |
| 1 | जेम्स स्मिथ | 26 | 1 | यूएसए |
| 2 | मैरी जॉनसन | 31 | 2 | जर्मनी |
| 3 | रॉबर्ट विलियम्स | 54 | 3 | कनाडा |
| 4 | जेनिफर ब्राउन | 47 | 4 | फ्रांस |
क्षैतिज साझाकरण
| Shard1 | <वें colspan="4" स्कोप="col"> |||||||
|---|---|---|---|---|---|---|---|
| ID | नाम | आयु | देश | ID | नाम | आयु | देश |
| 1 | जेम्स स्मिथ | 26 | यूएसए | 3 | रॉबर्ट विलियम्स | 54 | कनाडा |
| 2 | मैरी जॉनसन | 31 | जर्मनी | 4 | जेनिफर ब्राउन | 47 | फ्रांस |
अब जब हमने कुछ साझाकरण अवधारणाओं की समीक्षा की है, तो चलिए अगले चरण पर आगे बढ़ते हैं।
एक PostgreSQL क्लस्टर कैसे परिनियोजित करें?
हम इस कार्य के लिए ClusterControl का उपयोग करेंगे। यदि आप अभी तक ClusterControl का उपयोग नहीं कर रहे हैं, तो आप इसे स्थापित कर सकते हैं और "आयात" विकल्प का चयन करके अपने वर्तमान PostgreSQL डेटाबेस को तैनात या आयात कर सकते हैं और सभी क्लस्टर नियंत्रण सुविधाओं जैसे बैकअप, स्वचालित विफलता, अलर्ट, निगरानी, आदि का लाभ उठाने के लिए चरणों का पालन कर सकते हैं। ।
ClusterControl से परिनियोजन करने के लिए, बस "तैनाती" विकल्प चुनें और दिखाई देने वाले निर्देशों का पालन करें।
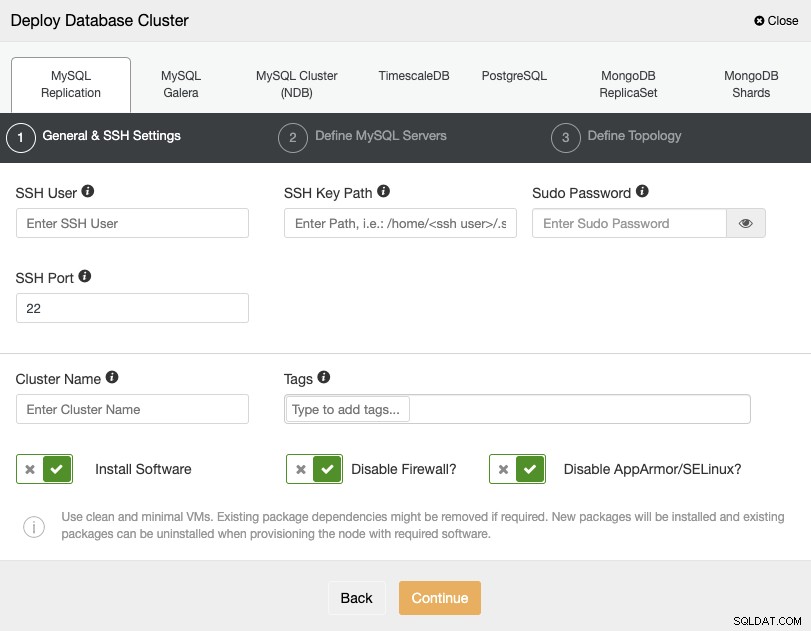
PostgreSQL का चयन करते समय, आपको अपना उपयोगकर्ता, कुंजी या पासवर्ड निर्दिष्ट करना होगा, और SSH द्वारा आपके सर्वर से कनेक्ट करने के लिए पोर्ट। आप अपने नए क्लस्टर के लिए एक नाम भी जोड़ सकते हैं और यदि आप चाहें, तो आप अपने लिए संबंधित सॉफ़्टवेयर और कॉन्फ़िगरेशन स्थापित करने के लिए ClusterControl का उपयोग भी कर सकते हैं।
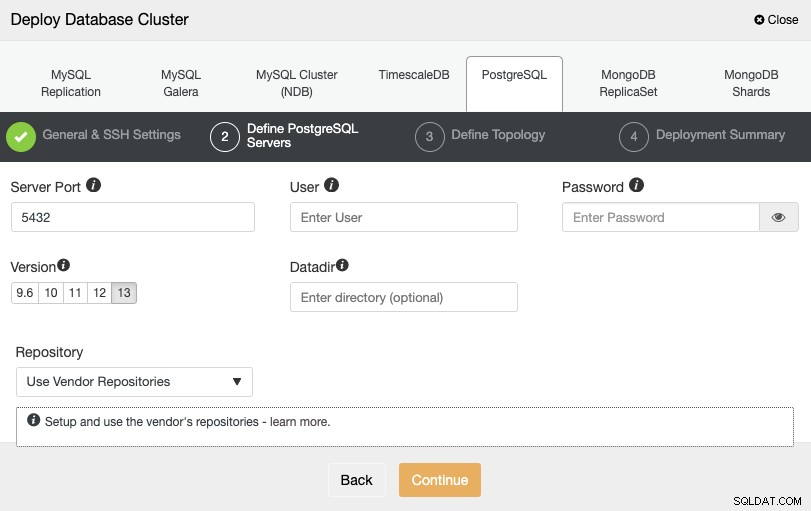
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस क्रेडेंशियल्स को परिभाषित करने की आवश्यकता है , संस्करण, और डेटादिर (वैकल्पिक)। आप यह भी निर्दिष्ट कर सकते हैं कि किस भंडार का उपयोग करना है।
अगले चरण के लिए, आपको अपने सर्वर को उस क्लस्टर में जोड़ना होगा जिसे आप IP पते या होस्टनाम का उपयोग करके बनाने जा रहे हैं।
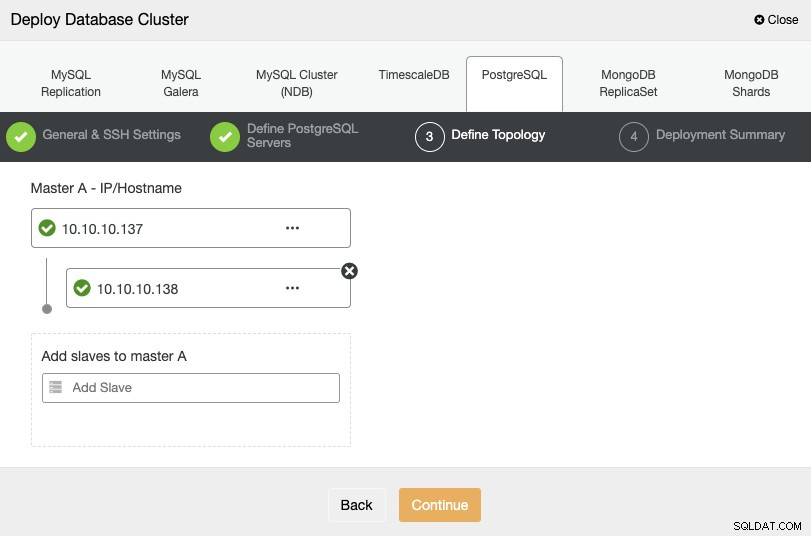
आखिरी चरण में, आप चुन सकते हैं कि आपकी प्रतिकृति सिंक्रोनस होगी या नहीं एसिंक्रोनस, और फिर बस "तैनाती" दबाएं।
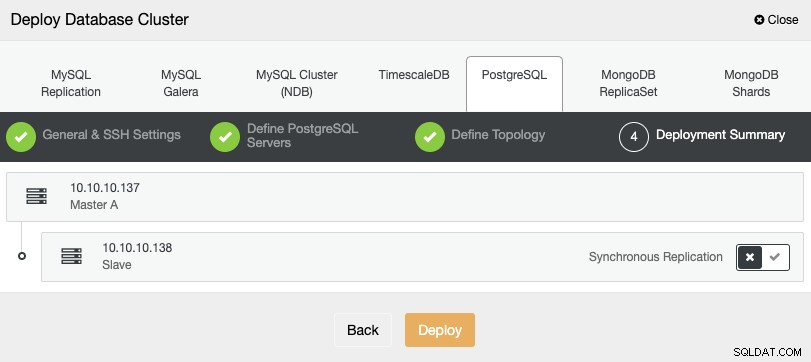
कार्य समाप्त होने के बाद, आपको अपना नया PostgreSQL क्लस्टर दिखाई देगा मुख्य क्लस्टर नियंत्रण स्क्रीन।

अब जब आपने अपना क्लस्टर बना लिया है, तो आप उस पर कई कार्य कर सकते हैं जैसे लोड बैलेंसर (HAProxy), कनेक्शन पूलर (pgBouncer), या एक नई प्रतिकृति जोड़ना।
शेयरिंग को कॉन्फ़िगर करने के लिए कम से कम दो अलग-अलग PostgreSQL क्लस्टर रखने के लिए प्रक्रिया को दोहराएं, जो अगला चरण है।
PostgreSQL शेयरिंग कैसे कॉन्फ़िगर करें?
अब हम पोस्टग्रेएसक्यूएल पार्टिशन और फॉरेन डेटा रैपर (एफडीडब्ल्यू) का उपयोग करके शेयरिंग को कॉन्फ़िगर करेंगे। यह कार्यक्षमता PostgreSQL को अन्य सर्वरों में संग्रहीत डेटा तक पहुंचने की अनुमति देती है। यह सामान्य PostgreSQL स्थापना में डिफ़ॉल्ट रूप से उपलब्ध एक एक्सटेंशन है।
हम निम्नलिखित परिवेश का उपयोग करेंगे:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersFDW एक्सटेंशन को सक्षम करने के लिए, आपको बस अपने मुख्य सर्वर में निम्न कमांड चलाने की आवश्यकता है, इस मामले में, Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONअब ग्राहकों को पंजीकृत तिथि के अनुसार विभाजित तालिका बनाते हैं:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);और निम्नलिखित विभाजन:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');ये विभाजन स्थानीय हैं। आइए अब कुछ परीक्षण मान डालें और उनकी जाँच करें:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');यहां आप सभी डेटा देखने के लिए मुख्य विभाजन को क्वेरी कर सकते हैं:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)या संबंधित विभाजन को भी क्वेरी करें:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
जैसा कि आप देख सकते हैं, डेटा को पंजीकृत तिथि के अनुसार विभिन्न विभाजनों में डाला गया था। अब, रिमोट नोड में, इस मामले में Shard2, चलिए एक और टेबल बनाते हैं:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);आपको इस Shard2 सर्वर को Shard1 में इस प्रकार बनाना होगा:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');और उपयोगकर्ता इसे एक्सेस करने के लिए:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');अब, Shard1 में FOREIGN TABLE बनाएं:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;और आइए Shard1 से इस नई दूरस्थ तालिका में डेटा डालें:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1यदि सब कुछ ठीक रहा, तो आपको Shard1 और Shard2 दोनों से डेटा एक्सेस करने में सक्षम होना चाहिए:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)बस। अब आप अपने PostgreSQL क्लस्टर में Sharding का उपयोग कर रहे हैं।
निष्कर्ष
PostgreSQL में विभाजन और साझाकरण अच्छी विशेषताएं हैं। यदि आपको प्रदर्शन को बेहतर बनाने के लिए, या यहां तक कि अन्य स्थितियों में डेटा को आसान तरीके से शुद्ध करने के लिए डेटा को एक बड़ी तालिका में अलग करने की आवश्यकता होती है, तो यह आपकी मदद करता है। जब आप शेयरिंग का उपयोग कर रहे हों तो एक महत्वपूर्ण बिंदु एक अच्छी शार्ड कुंजी चुनना है जो डेटा को नोड्स के बीच सर्वोत्तम तरीके से वितरित करता है। साथ ही, आप PostgreSQL परिनियोजन को सरल बनाने और निगरानी, चेतावनी, स्वचालित विफलता, बैकअप, पॉइंट-इन-टाइम पुनर्प्राप्ति, आदि जैसी कुछ सुविधाओं का लाभ उठाने के लिए ClusterControl का उपयोग कर सकते हैं।



