डेटा एनालिटिक्स किसी भी कंपनी में महत्वपूर्ण है क्योंकि आप देख सकते हैं कि अतीत में क्या हुआ था ताकि आप स्मार्ट निर्णय लेने में सक्षम हो सकें या मौजूदा डेटा का उपयोग करके भविष्य की कार्रवाइयों की भविष्यवाणी कर सकें।
डेटा की एक बड़ी मात्रा का विश्लेषण करना कठिन हो सकता है और OLTP और OLAP वर्कलोड को संभालने के लिए आपको एक से अधिक डेटाबेस इंजन का उपयोग करने की आवश्यकता होगी। इस ब्लॉग में, हम देखेंगे कि हीटवेव क्या है, और यह इस कार्य में आपकी कैसे मदद कर सकती है।
हीटवेव क्या है?
हीटवेव क्लाउड में MySQL डेटाबेस सेवा के लिए एक नया एकीकृत इंजन है। यह एक वितरित, स्केलेबल, साझा-कुछ भी नहीं, इन-मेमोरी, कॉलमर, क्वेरी प्रोसेसिंग इंजन है जिसे विश्लेषणात्मक प्रश्नों के तेजी से निष्पादन के लिए डिज़ाइन किया गया है। आधिकारिक दस्तावेज के अनुसार, यह एनालिटिक्स प्रश्नों के लिए MySQL के प्रदर्शन को 400X तक तेज करता है, हजारों कोर तक बढ़ाता है, और प्रत्यक्ष प्रतियोगियों की लागत के लगभग एक तिहाई पर 2.7X तेज है। MySQL डेटाबेस सेवा, हीटवेव के साथ, OLTP और OLAP वर्कलोड को सीधे MySQL डेटाबेस से चलाने के लिए एकमात्र सेवा है।
हीटवेव कैसे काम करता है
एक हीटवेव क्लस्टर में एक MySQL DB सिस्टम नोड और दो या अधिक हीटवेव नोड्स शामिल होते हैं। MySQL DB सिस्टम नोड में एक हीटवेव प्लगइन है जो क्लस्टर प्रबंधन के लिए जिम्मेदार है, हीटवेव क्लस्टर में डेटा लोड कर रहा है, क्वेरी शेड्यूलिंग, और क्वेरी परिणाम MySQL DB सिस्टम पर लौटा रहा है। हीटवेव नोड्स मेमोरी में डेटा स्टोर करते हैं और एनालिटिक्स क्वेरी को प्रोसेस करते हैं। प्रत्येक हीटवेव नोड में हीटवेव का एक उदाहरण होता है।
आवश्यक हीटवेव नोड्स की संख्या आपके डेटा के आकार और हीटवेव क्लस्टर में डेटा लोड करते समय प्राप्त होने वाले संपीड़न की मात्रा पर निर्भर करती है। हम इस उत्पाद की वास्तुकला को निम्न छवि में देख सकते हैं:
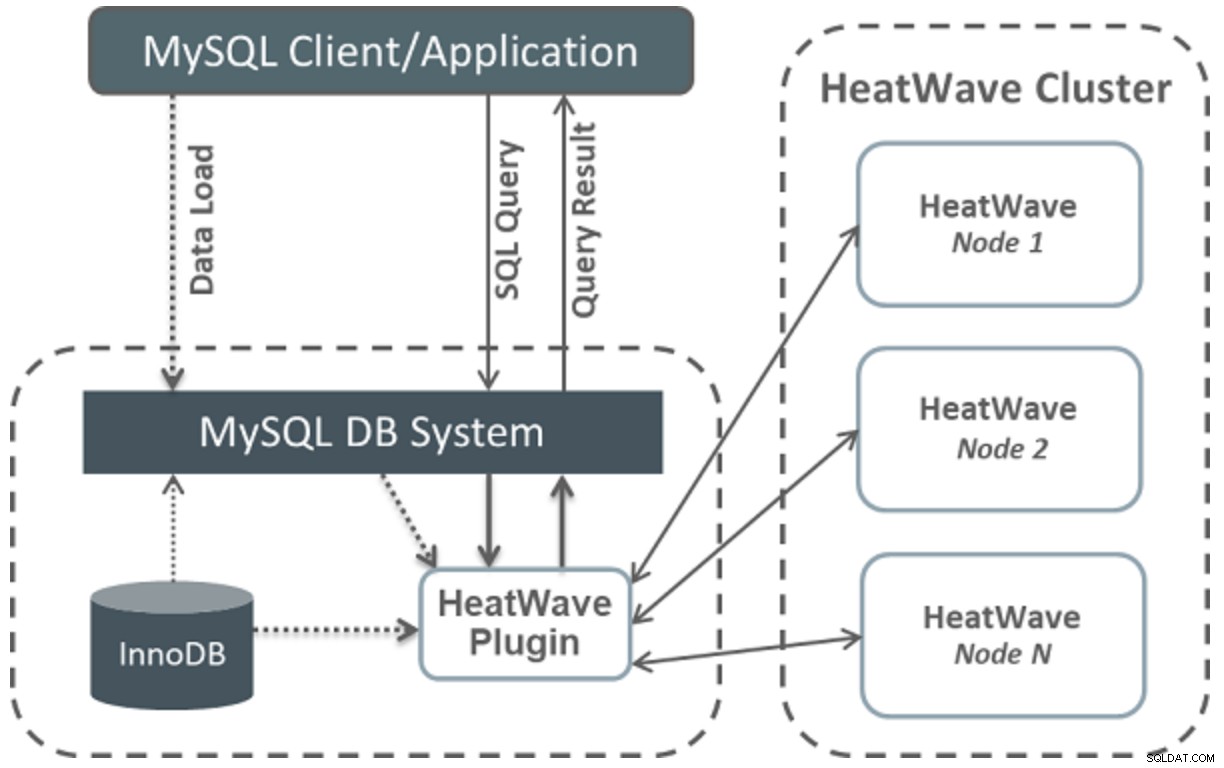
जैसा कि आप देख सकते हैं, उपयोगकर्ता हीटवेव क्लस्टर को सीधे एक्सेस नहीं करते हैं। कुछ पूर्वापेक्षाओं को पूरा करने वाली क्वेरी को त्वरित प्रसंस्करण के लिए MySQL DB सिस्टम से हीटवेव क्लस्टर में स्वचालित रूप से ऑफ़लोड कर दिया जाता है, और परिणाम MySQL DB सिस्टम नोड और फिर MySQL क्लाइंट या क्वेरी जारी करने वाले एप्लिकेशन को वापस कर दिए जाते हैं।
इसका उपयोग कैसे करें
इस सुविधा को सक्षम करने के लिए, आपको Oracle क्लाउड प्रबंधन साइट तक पहुंचना होगा, मौजूदा MySQL DB सिस्टम तक पहुंचना होगा (या एक नया बनाना होगा), और एक एनालिटिक्स क्लस्टर जोड़ना होगा। वहां आप क्लस्टर के प्रकार और नोड्स की संख्या निर्दिष्ट कर सकते हैं। आप अपने कार्यभार के आधार पर आवश्यक संख्या जानने के लिए एस्टीमेट नोड काउंट सुविधा का उपयोग कर सकते हैं।
एक हीटवेव क्लस्टर में डेटा लोड करने के लिए MySQL DB सिस्टम पर टेबल तैयार करने और टेबल लोड संचालन को निष्पादित करने की आवश्यकता होती है।
टेबल तैयार करना
तालिकाओं को तैयार करने में कुछ स्तंभों को बाहर करने के लिए तालिका परिभाषाओं को संशोधित करना, स्ट्रिंग कॉलम एन्कोडिंग को परिभाषित करना, डेटा प्लेसमेंट कुंजियाँ जोड़ना और तालिका के लिए द्वितीयक इंजन के रूप में हीटवेव (RAPID) निर्दिष्ट करना शामिल है, क्योंकि InnoDB प्राथमिक है।
रैपिड को किसी तालिका के द्वितीयक इंजन के रूप में परिभाषित करने के लिए, तालिका बनाएं या तालिका में परिवर्तन करें कथन में SECONDARY_ENGINE तालिका विकल्प निर्दिष्ट करें:
mysql> CREATE TABLE orders (id INT) SECONDARY_ENGINE = RAPID;
or
mysql> ALTER TABLE orders SECONDARY_ENGINE = RAPID;डेटा लोड हो रहा है
किसी तालिका को हीटवेव क्लस्टर में लोड करने के लिए SECONDARY_LOAD कीवर्ड के साथ एक ALTER TABLE ऑपरेशन निष्पादित करना आवश्यक है।
mysql> ALTER TABLE orders SECONDARY_LOAD;जब कोई तालिका लोड की जाती है, तो डेटा क्षैतिज रूप से कटा हुआ होता है और हीटवेव नोड्स के बीच वितरित किया जाता है। तालिका लोड होने के बाद, MySQL DB सिस्टम नोड पर तालिका के डेटा में परिवर्तन स्वचालित रूप से हीटवेव नोड्स में प्रचारित हो जाते हैं।
उदाहरण
इस उदाहरण के लिए, हम टेबल ऑर्डर का उपयोग करेंगे:
mysql> SHOW CREATE TABLE orders\G
*************************** 1. row ***************************
Table: orders
Create Table: CREATE TABLE `orders` (
`O_ORDERKEY` int NOT NULL,
`O_CUSTKEY` int NOT NULL,
`O_ORDERSTATUS` char(1) COLLATE utf8mb4_bin NOT NULL,
`O_TOTALPRICE` decimal(15,2) NOT NULL,
`O_ORDERDATE` date NOT NULL,
`O_ORDERPRIORITY` char(15) COLLATE utf8mb4_bin NOT NULL,
`O_CLERK` char(15) COLLATE utf8mb4_bin NOT NULL,
`O_SHIPPRIORITY` int NOT NULL,
`O_COMMENT` varchar(79) COLLATE utf8mb4_bin NOT NULL,
PRIMARY KEY (`O_ORDERKEY`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_binआप उन स्तंभों को बाहर कर सकते हैं जिन्हें आप हीटवेव पर लोड नहीं करना चाहते:
mysql> ALTER TABLE orders MODIFY `O_COMMENT` varchar(79) NOT NULL NOT SECONDARY;अब, तालिका के लिए RAPID को SECONDARY_ENGINE के रूप में परिभाषित करें:
mysql> ALTER TABLE orders SECONDARY_ENGINE RAPID;सुनिश्चित करें कि आपके पास तालिका परिभाषा में SECONDARY_ENGINE पैरामीटर जोड़ा गया है:
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin SECONDARY_ENGINE=RAPIDऔर अंत में, तालिका को हीटवेव में लोड करें:
mysql> ALTER TABLE orders SECONDARY_LOAD;आप EXPLAIN का उपयोग यह जांचने के लिए कर सकते हैं कि यह सही इंजन का उपयोग कर रहा है या नहीं। आपको कुछ इस तरह दिखना चाहिए:
अतिरिक्त:जहां का उपयोग करना; अस्थायी का उपयोग करना; फाइलसॉर्ट का उपयोग करना; सेकेंडरी इंजन रैपिड का उपयोग करना
MySQL की आधिकारिक साइट पर, आप सामान्य निष्पादन और हीटवेव का उपयोग करने के बीच तुलना देख सकते हैं:
हीटवेव निष्पादन
mysql> SELECT O_ORDERPRIORITY, COUNT(*) AS ORDER_COUNT FROM orders
WHERE O_ORDERDATE >= DATE '1994-03-01' GROUP BY O_ORDERPRIORITY
ORDER BY O_ORDERPRIORITY;
+-----------------+-------------+
| O_ORDERPRIORITY | ORDER_COUNT |
+-----------------+-------------+
| 1-URGENT | 2017573 |
| 2-HIGH | 2015859 |
| 3-MEDIUM | 2013174 |
| 4-NOT SPECIFIED | 2014476 |
| 5-LOW | 2013674 |
+-----------------+-------------+
5 rows in set (0.04 sec)सामान्य निष्पादन
mysql> SELECT O_ORDERPRIORITY, COUNT(*) AS ORDER_COUNT FROM orders
WHERE O_ORDERDATE >= DATE '1994-03-01' GROUP BY O_ORDERPRIORITY
ORDER BY O_ORDERPRIORITY;
+-----------------+-------------+
| O_ORDERPRIORITY | ORDER_COUNT |
+-----------------+-------------+
| 1-URGENT | 2017573 |
| 2-HIGH | 2015859 |
| 3-MEDIUM | 2013174 |
| 4-NOT SPECIFIED | 2014476 |
| 5-LOW | 2013674 |
+-----------------+-------------+
5 rows in set (8.91 sec)जैसा कि आप देख सकते हैं, एक साधारण क्वेरी में भी, क्वेरी के समय में एक महत्वपूर्ण अंतर है। अधिक जानकारी के लिए, आप आधिकारिक दस्तावेज देख सकते हैं।
निष्कर्ष
एक एकल MySQL डेटाबेस का उपयोग OLTP और विश्लेषिकी अनुप्रयोगों दोनों के लिए किया जा सकता है। यह MySQL ऑन-प्रिमाइसेस के साथ 100% संगत है, इसलिए आप अपने OLTP वर्कलोड को ऑन-प्रिमाइसेस रख सकते हैं और अपने एनालिटिक्स वर्कलोड को अपने एप्लिकेशन में बदलाव किए बिना हीटवेव पर ऑफ़लोड कर सकते हैं, या यहां तक कि इसे सीधे Oracle क्लाउड पर उपयोग करके एनालिटिक्स के लिए अपने MySQL प्रदर्शन को बेहतर बना सकते हैं। उद्देश्य।