आप सभी ने स्केलिंग के बारे में सुना है - आपका आर्किटेक्चर स्केलेबल होना चाहिए, आपको मांग को पूरा करने के लिए स्केल करने में सक्षम होना चाहिए, इत्यादि। जब हम डेटाबेस के बारे में बात करते हैं तो इसका क्या अर्थ होता है? पर्दे के पीछे स्केलिंग कैसा दिखता है? यह विषय विशाल है और सभी पहलुओं को शामिल करने का कोई तरीका नहीं है। यह दो-ब्लॉग पोस्ट श्रृंखला आपको डेटाबेस मापनीयता के विषय में एक अंतर्दृष्टि देने का एक प्रयास है।
हम स्केल क्यों करते हैं?
सबसे पहले, आइए एक नजर डालते हैं कि मापनीयता क्या है। संक्षेप में, हम आपके डेटाबेस सिस्टम द्वारा उच्च भार को संभालने की क्षमता के बारे में बात कर रहे हैं। यह गतिविधि में अल्पकालिक स्पाइक्स से निपटने का मामला हो सकता है, यह आपके डेटाबेस वातावरण में धीरे-धीरे बढ़े हुए कार्यभार से निपटने का मामला हो सकता है। स्केलिंग पर विचार करने के कई कारण हो सकते हैं। उनमें से ज्यादातर अपनी चुनौतियों के साथ आते हैं। हम उस स्थिति के उदाहरणों के माध्यम से कुछ समय बिता सकते हैं जहां हम विस्तार करना चाहते हैं।
संसाधन खपत में वृद्धि
यह सबसे सामान्य है - आपका भार इतना बढ़ गया है कि आपके मौजूदा संसाधन इससे निपटने में सक्षम नहीं हैं। यह कुछ भी हो सकता है। CPU लोड बढ़ गया है और आपका डेटाबेस क्लस्टर उचित और स्थिर क्वेरी निष्पादन समय के साथ डेटा वितरित करने में सक्षम नहीं है। मेमोरी का उपयोग इस हद तक बढ़ गया है कि डेटाबेस अब सीपीयू-बाउंड नहीं है, लेकिन I/O-बाउंड बन गया है और, इस तरह, डेटाबेस नोड्स का प्रदर्शन काफी कम हो गया है। नेटवर्क एक बूटल-नेक भी हो सकता है। आपको यह देखकर आश्चर्य हो सकता है कि नेटवर्किंग से संबंधित किन सीमाओं ने आपके क्लाउड इंस्टेंस को असाइन किया है। वास्तव में, यह सबसे आम सीमा बन सकती है जिससे आपको निपटना होगा क्योंकि नेटवर्क क्लाउड में सब कुछ है - न केवल एप्लिकेशन और डेटाबेस के बीच भेजा गया डेटा बल्कि नेटवर्क पर स्टोरेज भी जुड़ा हुआ है। यह डिस्क उपयोग भी हो सकता है - आपके पास अभी डिस्क स्थान समाप्त हो रहा है या, अधिक संभावना है, यह देखते हुए कि आजकल हमारे पास काफी बड़े डिस्क हो सकते हैं, डेटाबेस का आकार "प्रबंधनीय" आकार से आगे निकल गया है। स्कीमा परिवर्तन जैसा रखरखाव एक चुनौती बन जाता है, डेटा आकार के कारण प्रदर्शन कम हो जाता है, बैकअप को पूरा होने में उम्र लग रही है। स्केल अप की आवश्यकता के लिए वे सभी मामले एक वैध मामला हो सकते हैं।
कार्यभार में अचानक वृद्धि
एक अन्य उदाहरण मामला जहां स्केलिंग की आवश्यकता है, कार्यभार में अचानक वृद्धि है। किसी कारण से (चाहे वह मार्केटिंग प्रयास हो, सामग्री वायरल हो रही हो, आपातकालीन या समान स्थिति हो) आपके बुनियादी ढांचे में डेटाबेस क्लस्टर पर लोड में उल्लेखनीय वृद्धि का अनुभव होता है। सीपीयू लोड छत पर चला जाता है, डिस्क I/O प्रश्नों को धीमा कर रहा है आदि। लगभग हर संसाधन जिसका हमने पिछले अनुभाग में उल्लेख किया था, अतिभारित हो सकता है और समस्याएं पैदा करना शुरू कर सकता है।
नियोजित संचालन
तीसरा कारण जिस पर हम प्रकाश डालना चाहते हैं, वह अधिक सामान्य है - किसी प्रकार का नियोजित संचालन। यह एक नियोजित विपणन गतिविधि हो सकती है जिससे आप अधिक ट्रैफ़िक लाने की उम्मीद करते हैं, ब्लैक फ्राइडे, लोड परीक्षण या बहुत कुछ जो आप पहले से जानते हैं।
उन कारणों में से प्रत्येक की अपनी विशेषताएं हैं। यदि आप पहले से योजना बना सकते हैं, तो आप प्रक्रिया को विस्तार से तैयार कर सकते हैं, उसका परीक्षण कर सकते हैं और जब भी आपका मन करे उस पर अमल कर सकते हैं। आप इसे "कम ट्रैफ़िक" अवधि में करना पसंद करेंगे, जब तक कि आपके कार्यभार में ऐसा कुछ मौजूद है (यह मौजूद नहीं है)। दूसरी ओर, लोड में अचानक वृद्धि, विशेष रूप से यदि वे उत्पादन को प्रभावित करने के लिए पर्याप्त महत्वपूर्ण हैं, तत्काल प्रतिक्रिया को मजबूर करेंगे, चाहे आप कितने भी तैयार हों और यह कितना सुरक्षित हो - यदि आपकी सेवाएं पहले से ही प्रभावित हैं तो आप भी कर सकते हैं प्रतीक्षा करने के बजाय इसके लिए जाएं।
डेटाबेस स्केलिंग के प्रकार
स्केलिंग के दो मुख्य प्रकार हैं:लंबवत और क्षैतिज। दोनों के पक्ष और विपक्ष हैं, दोनों अलग-अलग स्थितियों में उपयोगी हैं। आइए उन पर एक नज़र डालें और दोनों परिदृश्यों के लिए उपयोग के मामलों पर चर्चा करें।
ऊर्ध्वाधर स्केलिंग
यह स्केलिंग विधि शायद सबसे पुरानी है:यदि आपका हार्डवेयर काम के बोझ से निपटने के लिए पर्याप्त नहीं है, तो इसे बेहतर बनाएं। हम यहां केवल मौजूदा नोड्स में संसाधनों को जोड़ने के बारे में बात कर रहे हैं ताकि उन्हें दिए गए कार्यों से निपटने के लिए पर्याप्त रूप से सक्षम बनाया जा सके। इसके कुछ परिणाम हैं जिन पर हम ध्यान देना चाहेंगे।
ऊर्ध्वाधर स्केलिंग के लाभ
सबसे महत्वपूर्ण बात यह है कि सब कुछ समान रहता है। आपके पास डेटाबेस क्लस्टर में तीन नोड थे, आपके पास अभी भी तीन नोड हैं, बस अधिक सक्षम हैं। अपने परिवेश को फिर से डिज़ाइन करने की कोई आवश्यकता नहीं है, यह बदलें कि एप्लिकेशन को डेटाबेस तक कैसे पहुंचना चाहिए - सब कुछ ठीक वैसा ही रहता है, क्योंकि कॉन्फ़िगरेशन-वार, वास्तव में कुछ भी नहीं बदला है।
ऊर्ध्वाधर स्केलिंग का एक अन्य महत्वपूर्ण लाभ यह है कि यह बहुत तेज हो सकता है, खासकर क्लाउड वातावरण में। पूरी प्रक्रिया, काफी हद तक, मौजूदा नोड को रोकने, हार्डवेयर में बदलाव करने, नोड को फिर से शुरू करने के लिए है। क्लासिक, ऑन-प्रिमाइसेस सेटअप के लिए, बिना किसी वर्चुअलाइजेशन के, यह मुश्किल हो सकता है - आपके पास स्वैप के लिए तेज़ CPU उपलब्ध नहीं हो सकता है, डिस्क को बड़े या तेज़ में अपग्रेड करना भी समय लेने वाला हो सकता है, लेकिन क्लाउड वातावरण के लिए, यह सार्वजनिक या निजी हो, यह तीन कमांड चलाने जितना आसान हो सकता है:इंस्टेंस रोकें, इंस्टेंस को बड़े आकार में अपग्रेड करें, इंस्टेंस शुरू करें। वर्चुअल आईपी और री-अटैचेबल वॉल्यूम इंस्टेंस के बीच डेटा को इधर-उधर ले जाना आसान बनाते हैं।
ऊर्ध्वाधर स्केलिंग के नुकसान
ऊर्ध्वाधर स्केलिंग का मुख्य नुकसान यह है कि, इसकी सीमाएं हैं। यदि आप सबसे तेज़ डिस्क वॉल्यूम के साथ उपलब्ध सबसे बड़े इंस्टेंस आकार पर चल रहे हैं, तो आप और कुछ नहीं कर सकते। अपने डेटाबेस क्लस्टर के प्रदर्शन को महत्वपूर्ण रूप से बढ़ाना भी इतना आसान नहीं है। यह ज्यादातर प्रारंभिक उदाहरण आकार पर निर्भर करता है, लेकिन यदि आप पहले से ही काफी प्रदर्शन करने वाले नोड्स चला रहे हैं, तो आप लंबवत स्केलिंग का उपयोग करके 10x स्केल-आउट प्राप्त करने में सक्षम नहीं हो सकते हैं। नोड्स जो 10x तेज होंगे, बस, मौजूद नहीं हो सकते हैं।
क्षैतिज स्केलिंग
क्षैतिज स्केलिंग एक अलग जानवर है। उदाहरण के आकार के साथ ऊपर जाने के बजाय, हम एक ही स्तर पर बने रहते हैं लेकिन हम अधिक नोड्स जोड़कर क्षैतिज रूप से विस्तार करते हैं। फिर से, इस पद्धति के फायदे और नुकसान हैं।
क्षैतिज स्केलिंग के लाभ
क्षैतिज स्केलिंग का मुख्य लाभ यह है कि सैद्धांतिक रूप से, आकाश की सीमा है। स्केल-आउट की कोई कृत्रिम कठोर सीमा नहीं है, भले ही सीमाएं मौजूद हों, मुख्य रूप से क्लस्टर में जोड़े गए प्रत्येक नए नोड के साथ इंट्रा-क्लस्टर संचार बड़ा और बड़ा ओवरहेड होने के कारण।
एक और महत्वपूर्ण लाभ यह होगा कि आप डाउनटाइम की आवश्यकता के बिना क्लस्टर को बढ़ा सकते हैं। यदि आप हार्डवेयर को अपग्रेड करना चाहते हैं, तो आपको इंस्टेंस को रोकना होगा, इसे अपग्रेड करना होगा और फिर से शुरू करना होगा। यदि आप क्लस्टर में अधिक नोड्स जोड़ना चाहते हैं, तो आपको केवल उन नोड्स को प्रोविज़न करना होगा, डेटाबेस सहित, आपको जो भी सॉफ़्टवेयर चाहिए, उसे इंस्टॉल करना होगा और इसे क्लस्टर में शामिल होने देना होगा। वैकल्पिक रूप से (यह निर्भर करता है कि क्लस्टर में डेटा के साथ नए नोड्स का प्रावधान करने के लिए आंतरिक तरीके हैं) आपको इसे स्वयं डेटा के साथ प्रावधान करना पड़ सकता है। आमतौर पर, हालांकि, यह एक स्वचालित प्रक्रिया है।
क्षैतिज स्केलिंग के नुकसान
आपको जिस मुख्य समस्या से निपटना है, वह यह है कि अधिक से अधिक नोड्स जोड़ने से पूरे वातावरण का प्रबंधन करना कठिन हो जाता है। आपको यह बताने में सक्षम होना चाहिए कि कौन से नोड उपलब्ध हैं, ऐसी सूची को बनाए रखा जाना चाहिए और बनाए गए प्रत्येक नए नोड के साथ अद्यतन किया जाना चाहिए। नोड्स और उनकी स्थिति पर नज़र रखने के लिए आपको निर्देशिका सेवा (Consul या Etcd) जैसे बाहरी समाधानों की आवश्यकता हो सकती है। जाहिर है, यह पूरे पर्यावरण की जटिलता को बढ़ाता है।
एक और संभावित समस्या यह है कि स्केल-आउट प्रक्रिया में समय लगता है। नए नोड्स जोड़ना और उन्हें सॉफ़्टवेयर के साथ प्रावधान करना और, विशेष रूप से, डेटा के लिए समय की आवश्यकता होती है। कितना, यह हार्डवेयर (मुख्य रूप से I/O और नेटवर्क थ्रूपुट) और डेटा के आकार पर निर्भर करता है। बड़े सेटअप के लिए यह एक महत्वपूर्ण समय हो सकता है और यह उन स्थितियों के लिए अवरोधक हो सकता है जहां स्केल-अप तुरंत होना है। यदि डेटाबेस क्लस्टर इस हद तक प्रभावित होता है कि संचालन ठीक से नहीं किया जा रहा है, तो नए नोड्स जोड़ने के लिए प्रतीक्षा घंटे स्वीकार्य नहीं हो सकते हैं।
स्केलिंग पूर्वापेक्षाएँ
डेटा प्रतिकृति
स्केलिंग का कोई भी प्रयास किए जाने से पहले, आपके परिवेश को कुछ आवश्यकताओं को पूरा करना होगा। शुरुआत के लिए, आपके आवेदन को एक से अधिक नोड का लाभ उठाने में सक्षम होना चाहिए। यदि यह केवल एक नोड का उपयोग कर सकता है, तो आपके विकल्प लंबवत स्केलिंग तक काफी सीमित हैं। आप ऐसे नोड के आकार को बढ़ा सकते हैं या कुछ हार्डवेयर संसाधनों को नंगे धातु सर्वर में जोड़ सकते हैं और इसे और अधिक प्रदर्शनकारी बना सकते हैं लेकिन यह सबसे अच्छा है जो आप कर सकते हैं:आप हमेशा अधिक प्रदर्शन करने वाले हार्डवेयर की उपलब्धता से सीमित रहेंगे और अंत में, आप पाएंगे आगे बढ़ने के विकल्प के बिना खुद को।
दूसरी ओर, यदि आपके पास अपने एप्लिकेशन द्वारा एकाधिक डेटाबेस नोड्स का उपयोग करने के साधन हैं, तो आप क्षैतिज स्केलिंग से लाभ उठा सकते हैं। आइए यहां रुकें और चर्चा करें कि वास्तव में आपको उनकी पूरी क्षमता के लिए कई नोड्स का उपयोग करने की क्या आवश्यकता है।
शुरुआत में, विभाजित करने की क्षमता लिखने से पढ़ती है। परंपरागत रूप से एप्लिकेशन केवल एक नोड से जुड़ता है। उस नोड का उपयोग एप्लिकेशन द्वारा निष्पादित सभी लेखन और सभी पठन को संभालने के लिए किया जाता है।

स्केलिंग के दृष्टिकोण से क्लस्टर में दूसरा नोड जोड़ने से कुछ भी नहीं बदलता है . आपको यह ध्यान रखना होगा कि, यदि एक नोड विफल हो जाता है, तो दूसरे को ट्रैफ़िक को संभालना होगा, इसलिए किसी भी समय दोनों नोड्स में लोड का योग एक नोड से निपटने के लिए बहुत अधिक नहीं होना चाहिए।

तीन नोड्स उपलब्ध होने से आप दो नोड्स का पूरी तरह से उपयोग कर सकते हैं। यह हमें कुछ पढ़े गए ट्रैफ़िक को स्केल करने की अनुमति देता है:यदि एक नोड में 100% क्षमता है (और हम अधिक से अधिक 70% पर चलेंगे), तो दो नोड 200% का प्रतिनिधित्व करते हैं। तीन नोड्स:300%। यदि एक नोड नीचे है और यदि हम शेष नोड्स को लगभग सीमा तक धकेलते हैं, तो हम कह सकते हैं कि क्लस्टर के ख़राब होने पर हम एकल नोड क्षमता के 170 - 180% के साथ काम करने में सक्षम हैं। यदि सभी तीन नोड उपलब्ध हैं, तो यह हमें प्रत्येक नोड पर एक अच्छा 60% लोड देता है।
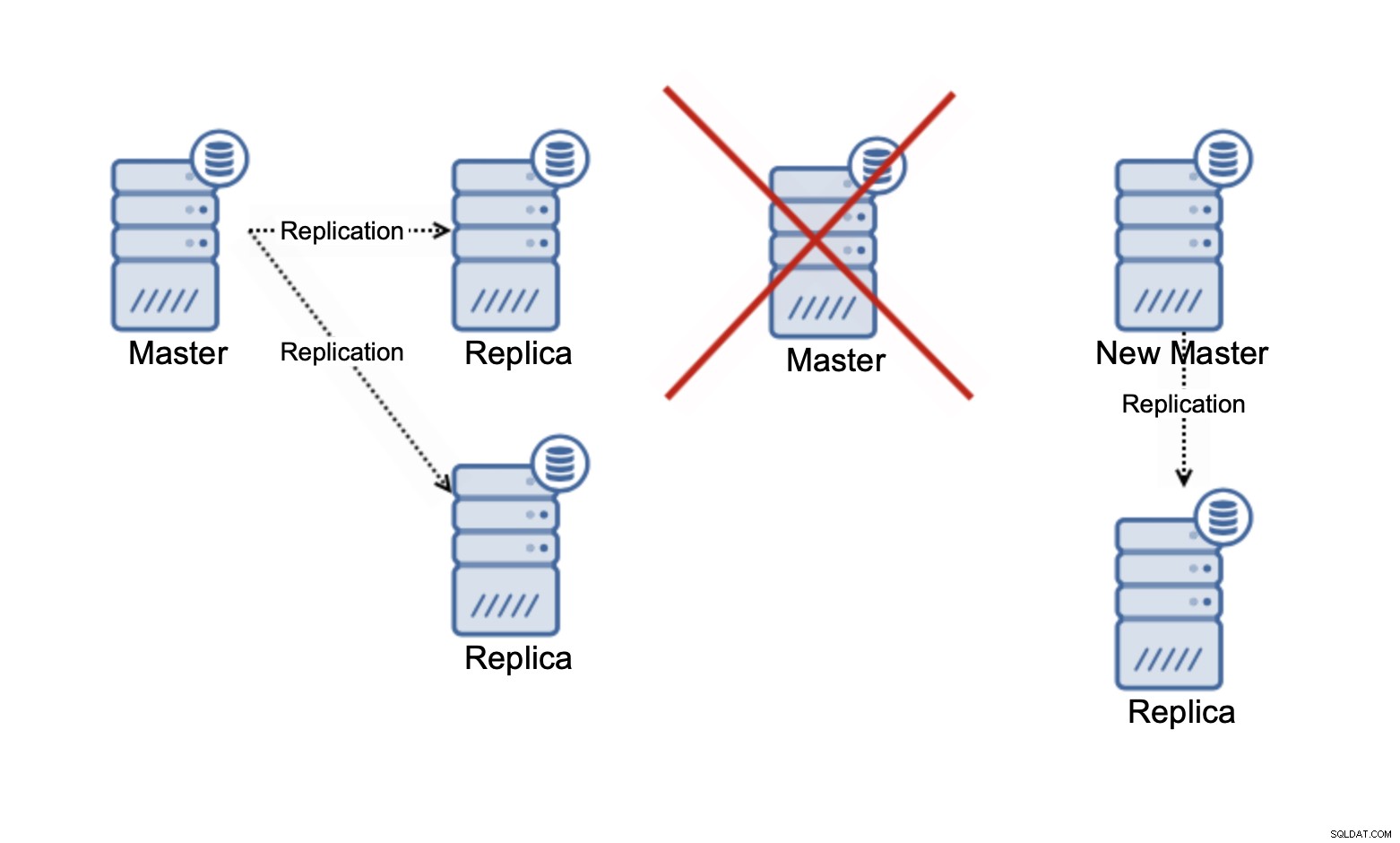
कृपया ध्यान रखें कि हम इस समय केवल स्केलिंग रीडिंग के बारे में बात कर रहे हैं . किसी भी समय प्रतिकृति आपकी लेखन क्षमता में सुधार नहीं कर सकती है। एसिंक्रोनस प्रतिकृति में, आपके पास केवल एक लेखक (मास्टर) होता है, और सिंक्रोनस प्रतिकृति के लिए, जैसे गैलेरा, जहां डेटासेट को सभी नोड्स में साझा किया जाता है, एक नोड पर होने वाले प्रत्येक लेखन को शेष नोड्स पर करना होगा। समूह।
तीन नोड वाले गैलेरा क्लस्टर में, यदि आप एक पंक्ति लिखते हैं, तो आप वास्तव में तीन पंक्तियाँ लिखते हैं, प्रत्येक नोड के लिए एक। अधिक नोड्स या प्रतिकृतियां जोड़ने से कोई फर्क नहीं पड़ेगा। एक ही पंक्ति को तीन नोड्स पर लिखने के बजाय आप इसे पाँच पर लिखेंगे। यही कारण है कि अपने लेखन को एक मल्टी-मास्टर क्लस्टर में विभाजित करना, जहां डेटा सेट सभी नोड्स में साझा किया जाता है (ऐसे मल्टी-मास्टर क्लस्टर होते हैं जहां डेटा को शार्प किया जाता है, उदाहरण के लिए MySQL NDB क्लस्टर - यहां राइट स्केलेबिलिटी कहानी पूरी तरह से अलग है), बहुत ज्यादा समझ में नहीं आता है। यह सभी नोड्स में संभावित लेखन संघर्षों से निपटने के लिए ओवरहेड जोड़ता है, जबकि यह वास्तव में कुल लेखन क्षमता के संबंध में कुछ भी नहीं बदल रहा है।
लोडबैलेंसिंग और रीड/राइट स्प्लिट
यदि आप अपने रीड्स को एसिंक्रोनस प्रतिकृति सेटअप में स्केल करना चाहते हैं, तो रीड्स को राइट्स से विभाजित करने की क्षमता बहुत जरूरी है। आपको एक नोड पर यातायात लिखने में सक्षम होना चाहिए और फिर प्रतिकृति टोपोलॉजी में सभी नोड्स को पढ़ना भेजना चाहिए। जैसा कि हमने पहले उल्लेख किया है, यह कार्यक्षमता मल्टी-मास्टर क्लस्टर्स में भी काफी उपयोगी है क्योंकि यह हमें उन लेखन विरोधों को दूर करने की अनुमति देता है जो तब हो सकते हैं जब आप क्लस्टर में कई नोड्स में राइट्स वितरित करने का प्रयास करते हैं। हम पढ़ने/लिखने का विभाजन कैसे कर सकते हैं? इसे करने के लिए आप कई तरीके अपना सकते हैं। आइए इस विषय पर थोड़ा ध्यान दें।
आवेदन स्तर R/W विभाजन
सबसे सरल परिदृश्य, कम से कम बारंबार होने वाला:आपका एप्लिकेशन कॉन्फ़िगर करने में सक्षम है कि कौन से नोड्स को लिखना चाहिए और कौन से नोड्स को पढ़ना चाहिए। इस कार्यक्षमता को दो तरीकों से कॉन्फ़िगर किया जा सकता है, सबसे सरल नोड्स की हार्डकोडेड सूची है, लेकिन यह बैकग्राउंड थ्रेड्स द्वारा अपडेट किए गए डायनेमिक नोड इन्वेंट्री की तर्ज पर भी कुछ हो सकता है। इस दृष्टिकोण के साथ मुख्य समस्या यह है कि पूरे तर्क को आवेदन के एक भाग के रूप में लिखा जाना है। नोड्स की हार्डकोडेड सूची के साथ, सबसे सरल परिदृश्य में प्रतिकृति टोपोलॉजी में प्रत्येक परिवर्तन के लिए एप्लिकेशन कोड में परिवर्तन की आवश्यकता होगी। दूसरी ओर, सेवा खोज को लागू करने जैसे अधिक उन्नत समाधान लंबे समय तक बनाए रखने के लिए अधिक जटिल होंगे।
कनेक्टर में R/W स्प्लिट
एक अन्य विकल्प यह होगा कि रीड/राइट स्प्लिट करने के लिए कनेक्टर का उपयोग किया जाए। उनमें से सभी के पास यह विकल्प नहीं है, लेकिन कुछ के पास है। एक उदाहरण php-mysqlnd या कनेक्टर/जे होगा। इसे एप्लिकेशन में कैसे एकीकृत किया जाता है, यह कनेक्टर के आधार पर भिन्न हो सकता है। कुछ मामलों में एप्लिकेशन में कॉन्फ़िगरेशन किया जाना है, कुछ मामलों में इसे कनेक्टर के लिए एक अलग कॉन्फ़िगरेशन फ़ाइल में किया जाना है। इस दृष्टिकोण का लाभ यह है कि भले ही आपको अपने आवेदन का विस्तार करना पड़े, अधिकांश नए कोड बाहरी स्रोतों द्वारा उपयोग और रखरखाव के लिए तैयार हैं। इससे ऐसे सेटअप से निपटना आसान हो जाता है और आपको कम कोड (यदि कोई हो) लिखना पड़ता है।
लोडबैलेंसर में R/W स्प्लिट
आखिरकार, सबसे अच्छे समाधानों में से एक:लोडबैलेंसर। विचार सरल है - अपने डेटा को लोडबैलेंसर के माध्यम से पास करें जो पढ़ने और लिखने के बीच अंतर करने और उन्हें उचित स्थान पर भेजने में सक्षम होगा। उपयोगिता के दृष्टिकोण से यह एक बड़ा सुधार है क्योंकि हम डेटाबेस खोज और क्वेरी रूटिंग को एप्लिकेशन से अलग कर सकते हैं। केवल एक चीज जो एप्लिकेशन को करनी है वह है डेटाबेस ट्रैफ़िक को एक एकल समापन बिंदु पर भेजना जिसमें एक होस्टनाम और एक पोर्ट होता है। बाकी पृष्ठभूमि में होता है। लोडबैलेंसर प्रश्नों को बैकएंड डेटाबेस नोड्स में रूट करने के लिए काम कर रहे हैं। लोडबैलेंसर प्रतिकृति टोपोलॉजी खोज भी कर सकते हैं या आप etcd या कॉन्सल का उपयोग करके एक उचित सेवा सूची को लागू कर सकते हैं और इसे अपने बुनियादी ढांचे के ऑर्केस्ट्रेशन टूल जैसे Ansible के माध्यम से अपडेट कर सकते हैं।
यह इस ब्लॉग के पहले भाग का समापन करता है। दूसरे में हम उन चुनौतियों पर चर्चा करेंगे जिनका सामना हम डेटाबेस टियर को स्केल करते समय कर रहे हैं। हम कुछ ऐसे तरीकों पर भी चर्चा करेंगे जिनसे हम अपने डेटाबेस क्लस्टर को बढ़ा सकते हैं।