निम्नलिखित हमारे श्वेतपत्र "हाउ टू डिज़ाइन हाईली अवेलेबल ओपन सोर्स डेटाबेस एनवायरनमेंट" का एक अंश है जिसे मुफ्त में डाउनलोड किया जा सकता है।
“उच्च उपलब्धता” पर कुछ शब्द
इन दिनों किसी भी गंभीर तैनाती के लिए उच्च उपलब्धता जरूरी है। लंबे समय से चले गए हैं जब आप रखरखाव करने के लिए कई घंटों के लिए अपने डेटाबेस का डाउनटाइम शेड्यूल कर सकते हैं। यदि आपकी सेवाएं उपलब्ध नहीं हैं, तो आप ग्राहकों और धन को खो रहे हैं। इसलिए डेटाबेस वातावरण को अत्यधिक उपलब्ध कराना आम तौर पर सर्वोच्च प्राथमिकताओं में से एक है।
यह डेटाबेस प्रशासकों के लिए एक महत्वपूर्ण चुनौती है। सबसे पहले, आप कैसे बताते हैं कि आपका पर्यावरण अत्यधिक उपलब्ध है या नहीं? आप इसे कैसे मापेंगे? उपलब्धता में सुधार के लिए आपको क्या कदम उठाने होंगे? शुरुआत से ही इसे अत्यधिक उपलब्ध कराने के लिए अपने सेटअप को कैसे डिज़ाइन करें?
MySQL (और MariaDB) पारिस्थितिकी तंत्र में कई HA समाधान उपलब्ध हैं, लेकिन हम कैसे जानते हैं कि हम किन पर भरोसा कर सकते हैं? कुछ समाधान कुछ विशिष्ट परिस्थितियों में काम कर सकते हैं, लेकिन इन शर्तों के बाहर लागू होने पर अधिक परेशानी हो सकती है। यहां तक कि एक बुनियादी कार्यक्षमता जैसे MySQL प्रतिकृति, जिसे कई तरीकों से कॉन्फ़िगर किया जा सकता है, महत्वपूर्ण नुकसान पहुंचा सकता है - उदाहरण के लिए, कई लिखने योग्य मास्टर्स के साथ परिपत्र प्रतिकृति। यद्यपि प्रतिकृति का उपयोग करके 'मल्टी-मास्टर सेटअप' स्थापित करना आसान है, यह बहुत आसानी से टूट सकता है और हमें विभिन्न सर्वरों पर अलग-अलग डेटासेट के साथ छोड़ सकता है। एक डेटाबेस के लिए, जिसे अक्सर सत्य का एकल स्रोत माना जाता है, समझौता किए गए डेटा अखंडता के विनाशकारी परिणाम हो सकते हैं।
निम्नलिखित अध्यायों में, हम डेटाबेस में उच्च उपलब्धता के लिए आवश्यकताओं पर चर्चा करेंगे
सेटअप, और सिस्टम को शुरू से कैसे डिज़ाइन करें।
उच्च उपलब्धता मापना
उच्च उपलब्धता क्या है? यह तय करने में सक्षम होने के लिए कि दिया गया वातावरण अत्यधिक उपलब्ध है या नहीं, उसके लिए कुछ मीट्रिक होना आवश्यक है। आप उच्च उपलब्धता को मापने के कई तरीके हैं, हम कुछ सबसे बुनियादी चीजों पर ध्यान केंद्रित करेंगे।
हालांकि, पहले, आइए सोचें कि यह संपूर्ण उच्च उपलब्धता क्या है? इसका उद्देश्य क्या है? यह सुनिश्चित करने के बारे में है कि आपका पर्यावरण अपने उद्देश्य को पूरा करता है। उद्देश्य को कई तरह से परिभाषित किया जा सकता है लेकिन, आमतौर पर, यह कुछ सेवा देने के बारे में होगा। डेटाबेस की दुनिया में, आमतौर पर यह कुछ हद तक डेटा से संबंधित होता है। यह आपके आंतरिक एप्लिकेशन को डेटा प्रदान कर सकता है। यह डेटा को स्टोर करने और विश्लेषणात्मक प्रक्रियाओं द्वारा इसे क्वेरी करने योग्य बनाने के लिए हो सकता है। यह आपके उपयोगकर्ताओं के लिए कुछ डेटा संग्रहीत करने और मांग पर अनुरोध किए जाने पर प्रदान करने के लिए हो सकता है। एक बार जब हम उद्देश्य के बारे में स्पष्ट हो जाते हैं, तो हम इसमें शामिल सफलता कारकों को स्थापित कर सकते हैं। इससे हमें यह परिभाषित करने में मदद मिलेगी कि हमारे विशिष्ट मामले में उच्च उपलब्धता का क्या अर्थ है।
SLA
सर्विस लेवल एग्रीमेंट (SLA)। आंतरिक सेवाओं के लिए SLA को परिभाषित करना भी काफी सामान्य है। एक एसएलए क्या है? यह उस सेवा स्तर की परिभाषा है जिसे आप अपने ग्राहकों को प्रदान करने की योजना बना रहे हैं। यह उनके लिए बेहतर ढंग से समझने के लिए है कि आपने जिस सेवा को खरीदा है या खरीदने की योजना बना रहे हैं, उसके लिए आप किस स्तर की स्थिरता की योजना बना रहे हैं। SLA तैयार करने के लिए आप कई तरीकों का लाभ उठा सकते हैं, लेकिन विशिष्ट हैं:
- सेवा की उपलब्धता (प्रतिशत)
- सेवा की जवाबदेही - विलंबता (औसत, अधिकतम, 95 प्रतिशत, 99 प्रतिशत)
- नेटवर्क पर पैकेट हानि (प्रतिशत)
- थ्रूपुट (औसत, न्यूनतम, 95 पर्सेंटाइल, 99 पर्सेंटाइल)
हालाँकि, यह उससे कहीं अधिक जटिल हो सकता है। एक शार्प, बहु-उपयोगकर्ता वातावरण में आप परिभाषित कर सकते हैं, मान लें, आपका एसएलए इस प्रकार है:"सेवा 99,99% समय उपलब्ध होगी, डाउनटाइम घोषित किया जाता है जब 2% से अधिक उपयोगकर्ता प्रभावित होते हैं। किसी भी घटना को सुलझने में 15 मिनट से ज्यादा का समय नहीं लग सकता। इस तरह के एसएलए को क्वेरी प्रतिक्रिया समय को शामिल करने के लिए भी बढ़ाया जा सकता है:"डाउनटाइम कहा जाता है यदि 99 प्रतिशत विलंबता प्रश्नों के लिए 200 मिलीसेकंड से अधिक है"।
नौ
उपलब्धता को आम तौर पर "नौ" में मापा जाता है, आइए देखें कि वास्तव में "नौ" गारंटी की दी गई राशि क्या है। नीचे दी गई तालिका विकिपीडिया से ली गई है:
| उपलब्धता % | प्रति वर्ष डाउनटाइम | डाउनटाइम प्रति माह | प्रति सप्ताह डाउनटाइम | प्रति दिन डाउनटाइम |
|---|---|---|---|---|
| 90% ("एक नौ") | 36.5 दिन | 72 घंटे | 16.8 घंटे | 2.4 घंटे |
| 95% ("डेढ़ नाइन") | 18.25 दिन | 36 घंटे | 8.4 घंटे | 1.2 घंटे |
| 97% | 10.96 दिन | 21.6 घंटे | 5.04 घंटे | 43.2 मिनट |
| 98% | 7.30 दिन | 14.4 घंटे | 3.36 घंटे | 28.8 मिनट |
| 99% ("दो नौ") | 3.65 दिन | 7.20 घंटे | 1.68 घंटे | 14.4 मिनट |
| 99.5% ("ढाई नौ") | 1.83 दिन | 3.60 घंटे | 50.4 मिनट | 7.2 मिनट |
| 99.8% | 17.52 घंटे | 86.23 मिनट | 20.16 मिनट | 2.88 मिनट |
| 99.9% ("तीन नौ") | 8.76 घंटे | 43.8 मिनट | 10.1 मिनट | 1.44 मिनट |
| 99.95% ("साढ़े तीन नौ") | 4.38 घंटे | 21.56 मिनट | 5.04 मिनट | 43.2 सेकेंड |
| 99.99% ("चार नौ") | 52.56 मिनट | 4.38 मिनट | 1.01 मिनट | 8.64 सेकेंड |
| 99.995% ("साढ़े चार नौ") | 26.28 मिनट | 2.16 मिनट | 30.24 सेकेंड | 4.32 सेकेंड |
| 99.999% ("पांच नौ") | 5.26 मिनट | 25.9 s | 6.05 s | 864.3 ms |
| 99.9999% ("छः नौ") | 31.5 सेकेंड | 2.59 सेकेंड | 604.8 ms | 86.4 ms |
| 99.99999% ("सात नौ") | 3.15 सेकेंड | 262.97 ms | 60.48 ms | 8.64 ms |
| 99.999999% ("आठ नौ") | 315.569 ms | 26.297 ms | 6.048 ms | 0.864 ms |
| 99.9999999% ("नौ नौ") | 31.5569 ms | 2.6297 ms | 0.6048 ms | 0.0864 ms |
जैसा कि हम देख सकते हैं, यह तेजी से बढ़ता है। पांच नाइन (99,999% उपलब्धता) एक वर्ष के दौरान 5.26 मिनट के डाउनटाइम के बराबर है। उपलब्धता की गणना विभिन्न, छोटी श्रेणियों में भी की जा सकती है:प्रति माह, प्रति सप्ताह, प्रति दिन। उन नंबरों को ध्यान में रखें, क्योंकि वे तब उपयोगी होंगे जब हम उपलब्धता के विभिन्न स्तरों को बनाए रखने से जुड़ी लागतों पर चर्चा करना शुरू करेंगे।
उपलब्धता मापना
यह बताने के लिए कि डाउनटाइम है या नहीं, किसी को पर्यावरण के बारे में जानकारी होनी चाहिए। आपको मेट्रिक्स को ट्रैक करने की आवश्यकता है जो आपके सिस्टम की उपलब्धता को परिभाषित करते हैं। यह ध्यान रखना महत्वपूर्ण है कि व्यापक तस्वीर को ध्यान में रखते हुए आपको इसे ग्राहक के दृष्टिकोण से मापना चाहिए। इससे कोई फर्क नहीं पड़ता कि आपके डेटाबेस ऊपर हैं, मान लीजिए, नेटवर्क समस्या के कारण, कोई भी एप्लिकेशन उन तक नहीं पहुंच सकता है। आपके सेटअप के हर एक बिल्डिंग ब्लॉक का उपलब्धता पर प्रभाव पड़ता है।
उपलब्धता डेटा देखने के लिए अच्छी जगहों में से एक वेब सर्वर लॉग है। सभी अनुरोध जो त्रुटियों के साथ समाप्त हुए, इसका मतलब है कि कुछ हुआ है। यह HTTP त्रुटि 500 एप्लिकेशन द्वारा लौटाया जा सकता है, क्योंकि डेटाबेस कनेक्शन विफल हो गया। वे कुछ डेटाबेस मुद्दों की ओर इशारा करते हुए प्रोग्रामेटिक त्रुटियां हो सकती हैं, और जो अपाचे के त्रुटि लॉग में समाप्त हो गईं। आप डेटाबेस सर्वर के अपटाइम के रूप में सरल मीट्रिक का भी उपयोग कर सकते हैं, हालांकि, अधिक जटिल SLA के साथ यह निर्धारित करना मुश्किल हो सकता है कि एक डेटाबेस की अनुपलब्धता ने आपके उपयोगकर्ता आधार को कैसे प्रभावित किया। कोई फर्क नहीं पड़ता कि आप क्या करते हैं, आपको एक से अधिक मीट्रिक का उपयोग करना चाहिए - यह उन मुद्दों को पकड़ने के लिए आवश्यक है जो आपके पर्यावरण की विभिन्न परतों पर हो सकते हैं।
मैजिक नंबर:"तीन"
हालांकि उच्च उपलब्धता भी अतिरेक के बारे में है, डेटाबेस समूहों के मामले में, तीन एक जादुई संख्या है। अतिरेक के लिए दो नोड्स होना पर्याप्त नहीं है - ऐसा सेटअप कोई अंतर्निहित उच्च उपलब्धता प्रदान नहीं करता है। निश्चित रूप से, यह केवल एक नोड से बेहतर हो सकता है, लेकिन सेवाओं को पुनर्प्राप्त करने के लिए मानवीय हस्तक्षेप की आवश्यकता है। आइए देखें ऐसा क्यों है।
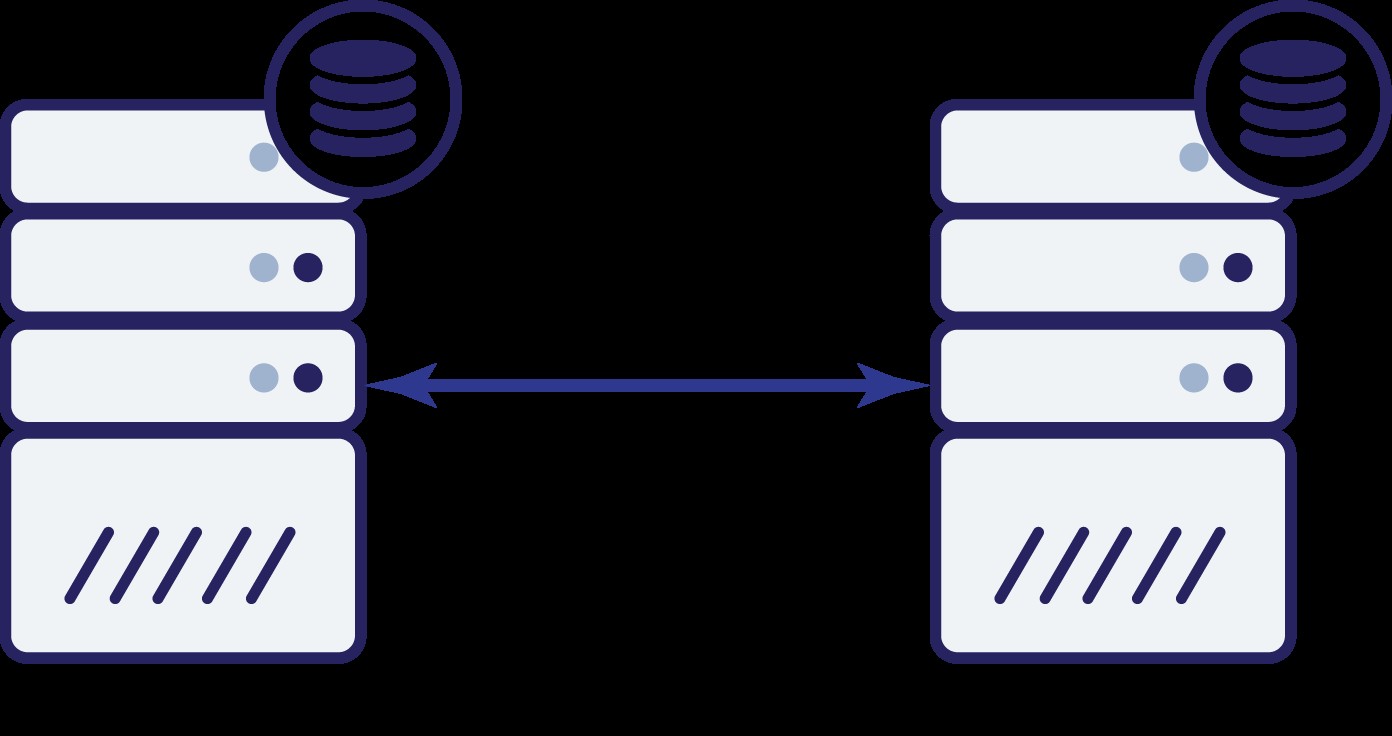
आइए मान लें कि हमारे पास दो नोड हैं, ए और बी। उनके बीच एक नेटवर्क लिंक है। आइए मान लें कि ए और बी दोनों लिखते हैं और एप्लिकेशन बेतरतीब ढंग से चुनता है कि कहां कनेक्ट करना है (जिसका अर्थ है कि एप्लिकेशन का हिस्सा नोड ए से कनेक्ट होगा और दूसरा हिस्सा नोड बी से कनेक्ट होगा)। अब, आइए कल्पना करें कि हमारे पास एक नेटवर्क समस्या है जिसके परिणामस्वरूप A और B के बीच नेटवर्क कनेक्टिविटी खो गई है।
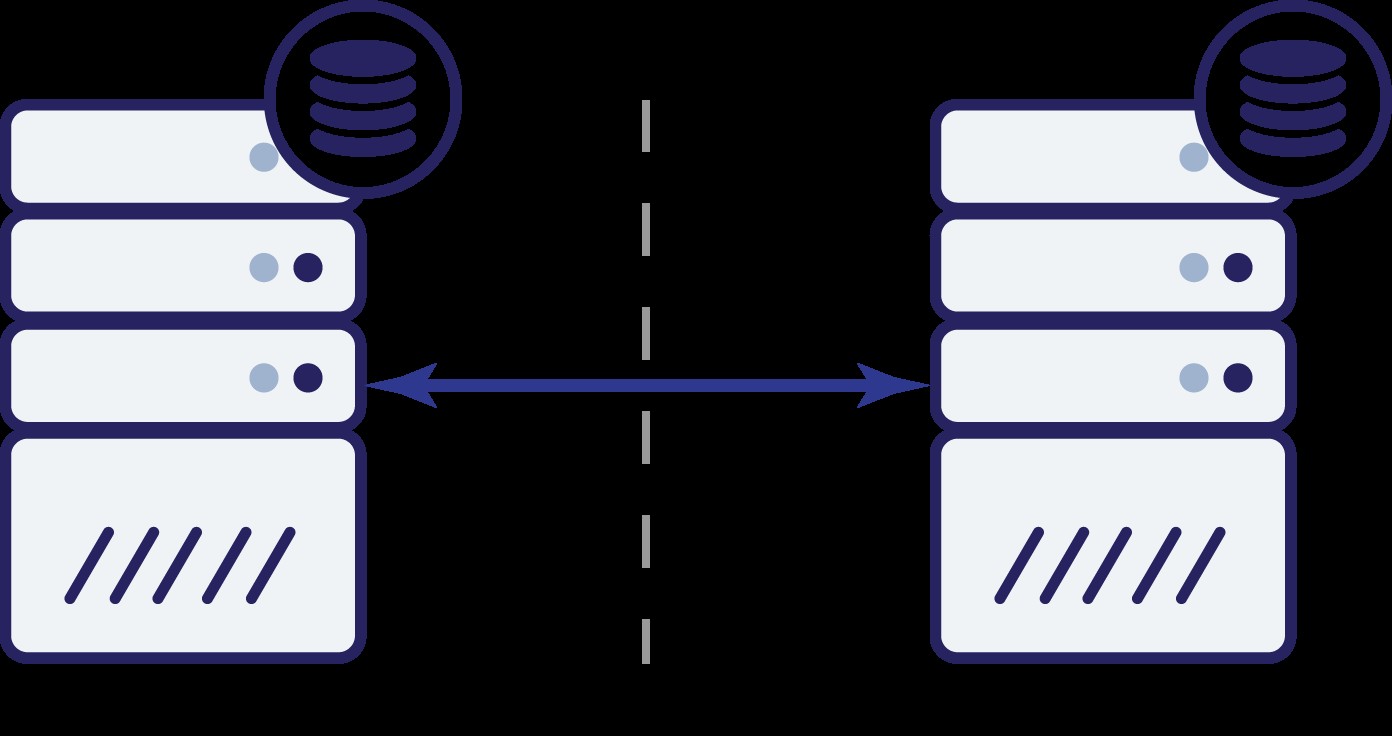
अब क्या? न तो A और न ही B दूसरे नोड की स्थिति जान सकते हैं। दो क्रियाएं हैं जो दोनों नोड्स द्वारा की जा सकती हैं:
- वे ट्रैफ़िक स्वीकार करना जारी रख सकते हैं
- वे काम करना बंद कर सकते हैं और किसी भी ट्रैफ़िक की सेवा से इनकार कर सकते हैं
आइए पहले विकल्प के बारे में सोचें। जब तक अन्य नोड वास्तव में नीचे है, यह पसंदीदा कार्रवाई है - हम चाहते हैं कि हमारा डेटाबेस यातायात की सेवा जारी रखे। आखिर उच्च उपलब्धता के पीछे यही मुख्य विचार है। क्या होगा, हालांकि, यदि दोनों नोड्स एक दूसरे से डिस्कनेक्ट होने के दौरान यातायात स्वीकार करना जारी रखेंगे? दोनों तरफ नया डेटा जोड़ा जाएगा, और डेटासेट सिंक से बाहर हो जाएंगे। जब नेटवर्क की समस्या का समाधान हो जाएगा, तो उन दो डेटासेट को मर्ज करना एक कठिन काम होगा। इसलिए, दोनों नोड्स को ऊपर और चालू रखना स्वीकार्य नहीं है। समस्या यह है - नोड ए कैसे बता सकता है कि नोड बी जीवित है या नहीं (और इसके विपरीत)? उत्तर है - यह नहीं हो सकता। यदि सभी कनेक्टिविटी बंद है, तो विफल नोड को विफल नेटवर्क से अलग करने का कोई तरीका नहीं है। परिणामस्वरूप, दोनों नोड्स के लिए एकमात्र सुरक्षित कार्रवाई है कि वे सभी संचालन बंद कर दें और
ट्रैफ़िक परोसने से इनकार कर दें।
आइए अब सोचें कि ऐसी स्थिति में तीसरा नोड कैसे हमारी मदद कर सकता है।
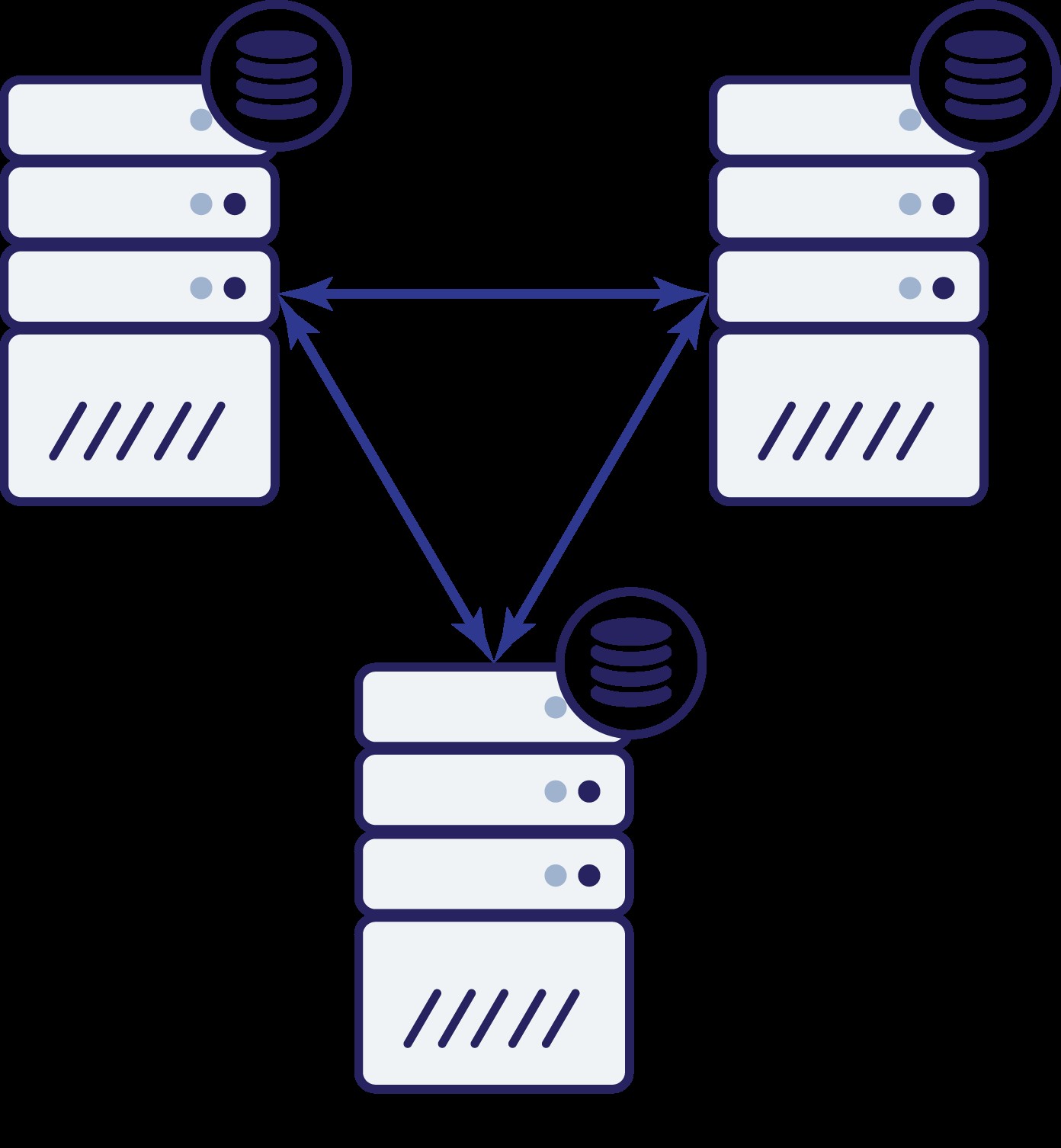
तो अब हमारे पास तीन नोड हैं:ए, बी और सी। सभी एक दूसरे से जुड़े हुए हैं, सभी पढ़ने और लिखने को संभाल रहे हैं।
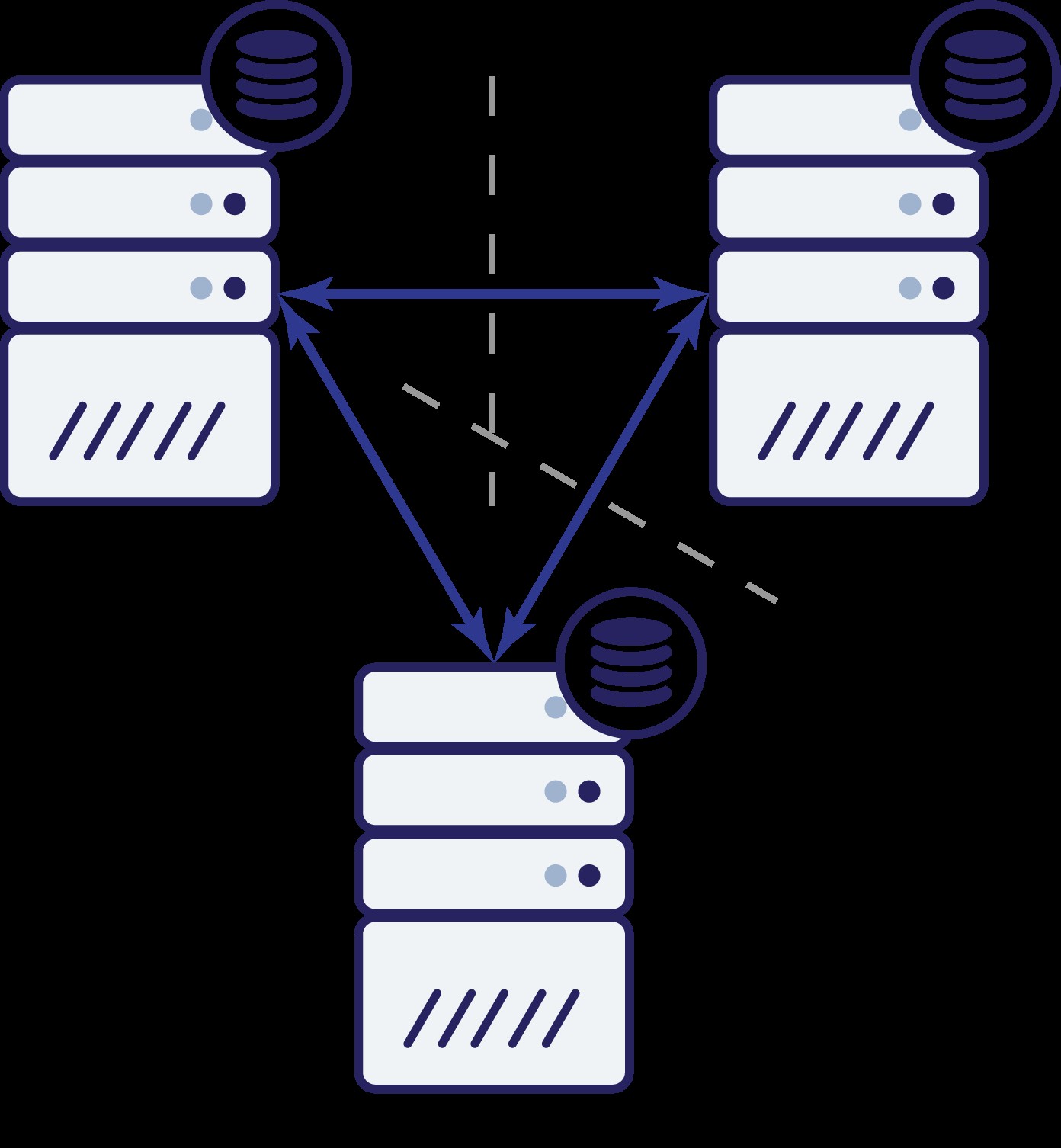
फिर से, पिछले उदाहरण की तरह, नेटवर्क समस्याओं के कारण नोड बी को बाकी क्लस्टर से काट दिया गया है। आगे क्या हो सकता है? खैर, स्थिति काफी हद तक वैसी ही है जैसी हमने पहले चर्चा की थी। दो विकल्प - नोड बी या तो नीचे हो सकता है (और शेष क्लस्टर जारी रहना चाहिए) या यह ऊपर हो सकता है, इस मामले में इसे किसी भी यातायात को संभालने की अनुमति नहीं दी जानी चाहिए। क्या अब हम बता सकते हैं कि क्लस्टर की स्थिति क्या है? वास्तव में हाँ। हम देख सकते हैं कि नोड ए और सी एक दूसरे से बात कर सकते हैं और परिणामस्वरूप, वे सहमत हो सकते हैं कि नोड बी उपलब्ध नहीं है। वे यह नहीं बता पाएंगे कि ऐसा क्यों हुआ, लेकिन वे यह जानते हैं कि क्लस्टर में तीन नोड्स में से दो में अभी भी एक-दूसरे के बीच संपर्क है। यह देखते हुए कि वे दो नोड अधिकांश क्लस्टर बनाते हैं, यह ट्रैफ़िक को संभालना जारी रखना संभव बनाता है। वहीं नोड बी यह भी घटा सकता है कि समस्या उसके पक्ष में है। यह न तो नोड ए और न ही नोड सी तक पहुंच सकता है, जिससे नोड बी बाकी क्लस्टर से अलग हो जाता है। चूंकि यह अलग-थलग है और बहुमत (3 में से 1) का हिस्सा नहीं है, इसलिए यह केवल सुरक्षित कार्रवाई कर सकता है कि ट्रैफ़िक देना बंद कर दिया जाए और किसी भी प्रश्न को स्वीकार करने से इनकार कर दिया जाए, यह सुनिश्चित करते हुए कि डेटा बहाव नहीं होगा।
बेशक, इसका मतलब यह नहीं है कि आपके पास क्लस्टर में केवल तीन नोड हो सकते हैं। यदि आप बेहतर विफलता सहिष्णुता चाहते हैं, तो आप और जोड़ना चाह सकते हैं। ध्यान रखें, हालांकि, यदि आप उच्च उपलब्धता में सुधार करना चाहते हैं तो यह एक विषम संख्या होनी चाहिए। इसके अलावा, हम ऊपर के उदाहरणों में "नोड्स" के बारे में बात कर रहे थे। कृपया ध्यान रखें कि यह डेटासेंटर, उपलब्धता क्षेत्र आदि के लिए भी सही है। यदि आपके पास दो डेटासेंटर हैं, प्रत्येक में समान संख्या में नोड्स हैं (मान लें कि प्रत्येक में तीन नोड हैं), और आप उन दो डीसी के बीच कनेक्टिविटी खो देते हैं, तो वही सिद्धांत यहां लागू होते हैं। - आप यह नहीं बता सकते हैं कि क्लस्टर के किस आधे हिस्से को ट्रैफिक संभालना शुरू करना चाहिए। यह बताने में सक्षम होने के लिए, आपके पास तीसरे डेटासेंटर में एक पर्यवेक्षक होना चाहिए। यह नोड्स का एक और सेट हो सकता है, या केवल एक होस्ट, कार्य के साथ
शेष डेटासेटर की स्थिति का निरीक्षण करने और निर्णय लेने में भाग लेने के लिए (यहां एक उदाहरण गैलेरा मध्यस्थ होगा)।
विफलता के एकल बिंदु
उच्च उपलब्धता विफलता के एकल बिंदु (एसपीओएफ) को हटाने और प्रक्रिया में नए लोगों को पेश नहीं करने के बारे में है। एसपीओएफ क्या हैं? आपके बुनियादी ढांचे का कोई भी हिस्सा, जो विफल होने पर, SLA में परिभाषित डाउनटाइम लाता है, SPOF कहलाता है। इंफ्रास्ट्रक्चर डिजाइन के लिए एक समग्र दृष्टिकोण की आवश्यकता होती है, विभिन्न घटकों को एक दूसरे से स्वतंत्र रूप से डिजाइन नहीं किया जा सकता है। सबसे अधिक संभावना है, आप संपूर्ण डिज़ाइन के लिए ज़िम्मेदार नहीं हैं -
डेटाबेस व्यवस्थापक डेटाबेस पर ध्यान केंद्रित करते हैं, उदाहरण के लिए, नेटवर्क परत पर नहीं। फिर भी, आपको अन्य भागों को ध्यान में रखना होगा और उन टीमों के साथ काम करना होगा जो उनके लिए जिम्मेदार हैं, यह सुनिश्चित करने के लिए कि न केवल जिस हिस्से के लिए आप जिम्मेदार हैं, वह सही ढंग से डिज़ाइन किया गया है, बल्कि यह भी कि बुनियादी ढांचे के शेष बिट्स का उपयोग करके डिज़ाइन किया गया है। समान सिद्धांत। उसके ऊपर, इस तरह का ज्ञान कि कैसे संपूर्ण
इन्फ्रास्ट्रक्चर को डिज़ाइन किया गया है, आपको डेटाबेस स्टैक को डिज़ाइन करने में भी मदद करता है। यह जानना कि क्या समस्याएं हो सकती हैं, डेटाबेस की उपलब्धता को प्रभावित करने से रोकने के लिए कुछ तंत्र बनाने में मदद करता है।