डेटा को पुनः प्राप्त करने के लिए डेटाबेस के वर्तमान प्रमुख उपयोग-मामले को ध्यान में रखते हुए, यह बहुत महत्वपूर्ण हो जाता है कि इसका प्रदर्शन बहुत अधिक हो और इसे केवल तभी प्राप्त किया जा सकता है जब डेटा को स्टोरेज से सबसे कुशल तरीके से प्राप्त किया जाता है। इसे प्राप्त करने के लिए कई सफल आविष्कार और कार्यान्वयन किए गए हैं। अधिकांश डेटाबेस द्वारा अपनाए जाने वाले प्रसिद्ध तरीकों में से एक है टेबल पर एक इंडेक्स रखना।
डेटाबेस इंडेक्स क्या है?
डेटाबेस इंडेक्स, जैसा कि नाम से पता चलता है, वास्तविक डेटा के लिए एक इंडेक्स बनाए रखता है और इस तरह वास्तविक तालिका से डेटा पुनर्प्राप्त करने के लिए प्रदर्शन में सुधार करता है। अधिक डेटाबेस शब्दावली में, इंडेक्स बहुत कम ट्रैवर्सल में अनुक्रमित डेटा वाले पृष्ठ को लाने की अनुमति देता है क्योंकि डेटा विशिष्ट क्रम में सॉर्ट किया जाता है। अतिरिक्त डेटा लिखने के लिए अतिरिक्त संग्रहण स्थान की कीमत पर सूचकांक लाभ मिलता है। अनुक्रमणिका अंतर्निहित तालिका के लिए विशिष्ट होती हैं और इसमें एक या अधिक कुंजियाँ होती हैं (अर्थात निर्दिष्ट तालिका के एक या अधिक स्तंभ)। इंडेक्स आर्किटेक्चर मुख्य रूप से दो प्रकार के होते हैं
- क्लस्टर इंडेक्स - इंडेक्स डेटा डेटा के दूसरे हिस्से के साथ स्टोर हो जाता है और इंडेक्स की के आधार पर डेटा सॉर्ट हो जाता है। एक निर्दिष्ट तालिका के लिए इस श्रेणी में अधिक से अधिक केवल एक अनुक्रमणिका हो सकती है।
- नॉन-क्लस्टर इंडेक्स - इंडेक्स डेटा अलग से स्टोर किया जाता है और इसमें स्टोरेज के लिए एक पॉइंटर होता है जहां डेटा का दूसरा हिस्सा स्टोर किया जाता है। इसे द्वितीयक सूचकांक के रूप में भी जाना जाता है। एक निर्दिष्ट तालिका में इस श्रेणी के जितने चाहें उतने सूचकांक हो सकते हैं।
इंडेक्स को लागू करने के लिए विभिन्न डेटा संरचनाएं उपयोग की जाती हैं, जिनमें से अधिकांश डेटाबेस द्वारा व्यापक रूप से अपनाए गए कुछ बी-ट्री और हैश हैं।
पोस्टग्रेएसक्यूएल इंडेक्स क्या है?
PostgreSQL केवल गैर-संकुल अनुक्रमणिका का समर्थन करता है। यानी सूचकांक डेटा और पूरा डेटा (यहां आगे हीप डेटा . कहा जाता है) ) एक अलग भंडारण में संग्रहीत हैं। गैर-संकुल अनुक्रमणिका किसी भी दस्तावेज़ में "सामग्री की तालिका" की तरह होती है, जिसमें पहले हम पृष्ठ संख्या की जाँच करते हैं और फिर संपूर्ण सामग्री को पढ़ने के लिए उन पृष्ठ संख्याओं की जाँच करते हैं। एक इंडेक्स के आधार पर पूरा डेटा प्राप्त करने के लिए, यह संबंधित हीप डेटा के लिए एक पॉइंटर रखता है। यह वैसा ही है जैसे पृष्ठ संख्या जानने के बाद, उसे उस पृष्ठ पर जाने और पृष्ठ की वास्तविक सामग्री प्राप्त करने की आवश्यकता होती है।
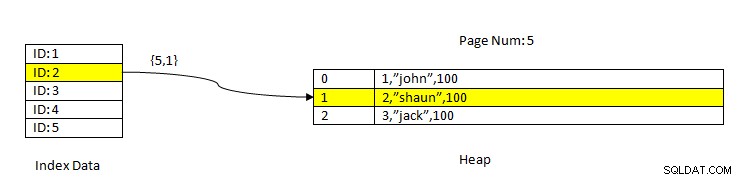 PostgreSQL:डेटा इंडेक्स का उपयोग करके पढ़ा जाता है
PostgreSQL:डेटा इंडेक्स का उपयोग करके पढ़ा जाता है उदाहरण के लिए, तीन कॉलम वाली तालिका और कॉलम ID . पर एक इंडेक्स पर विचार करें . कुंजी आईडी =2 के आधार पर डेटा को पढ़ने के लिए, सबसे पहले, आईडी मान 2 के साथ अनुक्रमित डेटा खोजा जाता है। इसमें पेज नंबर (यानी ब्लॉक नंबर) और उस पेज के भीतर डेटा की ऑफसेट के संदर्भ में एक पॉइंटर (आइटम पॉइंटर कहा जाता है) होता है। वर्तमान उदाहरण में, सूचकांक पृष्ठ संख्या 5 और पृष्ठ में दूसरी पंक्ति वस्तु को इंगित करता है जो बदले में पूरे डेटा (2, "शॉन", 100) के लिए ऑफसेट रहता है। ध्यान दें कि संपूर्ण डेटा में अनुक्रमित डेटा भी होता है जिसका अर्थ है कि एक ही डेटा दो स्टोरेज में दोहराया जाता है।
INDEX प्रदर्शन को बेहतर बनाने में कैसे मदद करता है? खैर, किसी भी INDEX रिकॉर्ड का चयन करने के लिए, यह सभी पृष्ठों को क्रमिक रूप से स्कैन नहीं करता है, बल्कि इसे अंतर्निहित इंडेक्स डेटा संरचना का उपयोग करके कुछ पृष्ठों को आंशिक रूप से स्कैन करने की आवश्यकता होती है। लेकिन एक मोड़ है, चूंकि इंडेक्स डेटा से प्राप्त प्रत्येक रिकॉर्ड को पूरे डेटा के लिए हीप डेटा में देखने की आवश्यकता होती है, जो बहुत सारे यादृच्छिक I/O का कारण बनता है और इसे अनुक्रमिक I/O की तुलना में धीमा प्रदर्शन करने वाला माना जाता है। इसलिए केवल अगर रिकॉर्ड का एक छोटा प्रतिशत चुना जा रहा है (जो PostgreSQL अनुकूलक लागत के आधार पर तय किया गया है), तो केवल PostgreSQL इंडेक्स स्कैन को चुनता है अन्यथा टेबल पर एक इंडेक्स होने के बावजूद, यह अनुक्रम स्कैन का उपयोग करना जारी रखता है।
संक्षेप में, हालांकि सूचकांक निर्माण प्रदर्शन को गति देता है, इसे सावधानी से चुना जाना चाहिए क्योंकि भंडारण के मामले में इसमें ओवरहेड है, INSERT प्रदर्शन में गिरावट आई है।
अब हम सोच सकते हैं, अगर हमें केवल डेटा के इंडेक्स भाग की आवश्यकता है, तो क्या हम केवल इंडेक्स स्टोरेज पेज से ही प्राप्त कर सकते हैं? खैर, इसका उत्तर सीधे तौर पर संबंधित है कि कैसे MVCC इंडेक्स स्टोरेज पर काम करता है जैसा कि आगे बताया गया है।
इंडेक्स करने के लिए MVCC का उपयोग करना
हीप पेजों की तरह, इंडेक्स पेज इंडेक्स टपल के कई संस्करणों को बनाए रखता है लेकिन यह दृश्यता जानकारी को बनाए नहीं रखता है। जैसा कि मेरे पिछले MVCC . में बताया गया है ब्लॉग, टुपल्स के उपयुक्त दृश्य संस्करण को तय करने के लिए, इसे लेनदेन की तुलना करने की आवश्यकता है। टपल डालने/अपडेट/हटाए जाने वाले लेन-देन को हीप टपल के साथ बनाए रखा जाता है लेकिन इंडेक्स टपल के साथ इसे बनाए नहीं रखा जाता है। यह पूरी तरह से संग्रहण को बचाने के लिए किया जाता है और यह स्थान और प्रदर्शन के बीच एक समझौता है।
अब मूल प्रश्न पर वापस आते हैं, क्योंकि इंडेक्स टपल में दृश्यता की जानकारी नहीं है, यह देखने के लिए कि क्या चयनित डेटा दिखाई दे रहा है, संबंधित हीप टपल से परामर्श करने की आवश्यकता है। तो भले ही ढेर टुपल से डेटा के अन्य हिस्सों की आवश्यकता नहीं है, फिर भी दृश्यता की जांच के लिए ढेर पृष्ठों तक पहुंचने की आवश्यकता है। लेकिन फिर से, किसी दिए गए पृष्ठ पर सभी टुपल्स के मामले में एक मोड़ है (इंडेक्स द्वारा इंगित पृष्ठ यानी आइटमपॉइंटर) दिखाई दे रहे हैं, फिर "दृश्यता जांच" के लिए हीप पेज के प्रत्येक आइटम को संदर्भित करने की आवश्यकता नहीं है और इसलिए डेटा केवल वापस किया जा सकता है सूचकांक पृष्ठ से। इस विशेष मामले को "इंडेक्स ओनली स्कैन" कहा जाता है। इसका समर्थन करने के लिए, PostgreSQL पृष्ठ स्तर की दृश्यता की जांच करने के लिए प्रत्येक पृष्ठ के लिए एक दृश्यता मानचित्र रखता है।
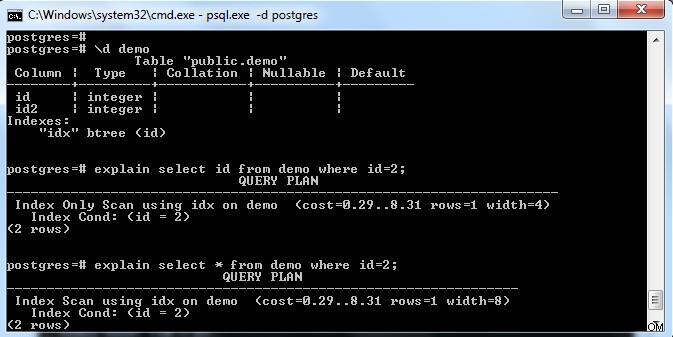
जैसा कि ऊपर की छवि में दिखाया गया है, कॉलम "आईडी" पर एक कुंजी के साथ "डेमो" टेबल पर एक इंडेक्स है। अगर हम केवल इंडेक्स फ़ील्ड (यानी आईडी) का चयन करने का प्रयास करते हैं तो उसने "इंडेक्स ओनली स्कैन" (रेफरिंग पेज को पूरी तरह से दृश्यमान मानते हुए) चुना है।
संकुल अनुक्रमणिका
PostgreSQL में डायरेक्ट क्लस्टर इंडेक्स का कोई समर्थन नहीं है लेकिन आंशिक रूप से इसे प्राप्त करने का एक अप्रत्यक्ष तरीका है। यह निम्न SQL कमांड द्वारा प्राप्त किया जाता है:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]पहला कमांड डेटाबेस को दिए गए इंडेक्स का उपयोग करके एक टेबल (यानी टेबल को सॉर्ट करने के लिए) को क्लस्टर करने का निर्देश देता है। यह सूचकांक पहले ही बन जाना चाहिए था। यह क्लस्टरिंग केवल एक बार का ऑपरेशन है और इसका प्रभाव इस टेबल पर बाद के ऑपरेशन के बाद नहीं रहता है यानी यदि अधिक रिकॉर्ड डाले/अपडेट किए जाते हैं, तो टेबल ऑर्डर नहीं रह सकता है। यदि उपयोगकर्ता द्वारा अभी भी टेबल को क्लस्टर (आदेशित) रखने के लिए आवश्यक है तो वे इंडेक्स नाम दिए बिना पहले कमांड का उपयोग कर सकते हैं।
दूसरा आदेश केवल तालिका को पुन:क्लस्टर करने के लिए उपयोगी है (यानी तालिका जो पहले से ही कुछ अनुक्रमणिका का उपयोग करके क्लस्टर की गई थी)। यह आदेश वर्तमान डेटाबेस में सभी तालिकाओं को फिर से क्लस्टर करता है जो वर्तमान कनेक्टेड उपयोगकर्ता को दिखाई देता है।
उदाहरण के लिए नीचे दिए गए आंकड़े में, पहला SELECT रिकॉर्ड को बिना क्रम में लौटाता है क्योंकि कोई क्लस्टर इंडेक्स नहीं है। भले ही पहले से ही गैर-संकुलित अनुक्रमणिका है लेकिन अभिलेखों को ढेर क्षेत्र से चुना जाता है जहां अभिलेखों को क्रमबद्ध नहीं किया जाता है।
दूसरा चयन कॉलम "आईडी" द्वारा क्रमबद्ध रिकॉर्ड लौटाता है क्योंकि इसे कॉलम "आईडी" वाले इंडेक्स का उपयोग करके क्लस्टर किया गया है।
तीसरा चयन क्रमबद्ध क्रम में आंशिक रिकॉर्ड देता है लेकिन नए सम्मिलित रिकॉर्ड सॉर्ट नहीं किए जाते हैं। चौथा SELECT फिर से सभी रिकॉर्ड्स को क्रमबद्ध क्रम में लौटाता है क्योंकि टेबल को फिर से क्लस्टर किया गया है
 PostgreSQL क्लस्टर कमांड
PostgreSQL क्लस्टर कमांड सूचकांक प्रकार
PostgreSQL नीचे दिए गए अनुसार कई प्रकार के इंडेक्स प्रदान करता है:
- बी-ट्री
- हैश
- GiST
- GIN
- BRIN
प्रत्येक इंडेक्स प्रकार विभिन्न प्रकार की अंतर्निहित डेटा-संरचना को लागू करता है, जो विभिन्न प्रकार के प्रश्नों के लिए सबसे उपयुक्त है। डिफ़ॉल्ट रूप से बी-ट्री इंडेक्स बन जाता है, जो व्यापक रूप से उपयोग किए जाने वाले इंडेक्स हैं। प्रत्येक इंडेक्स प्रकार का विवरण भविष्य के ब्लॉग में शामिल किया जाएगा।
विविध:आंशिक और अभिव्यक्ति सूचकांक
हमने केवल एक तालिका के एक या अधिक स्तंभों पर अनुक्रमणिका के बारे में चर्चा की है लेकिन PostgreSQL पर अनुक्रमणिका बनाने के अन्य दो तरीके हैं
- आंशिक सूचकांक: आंशिक सूचकांक एक विशेष तालिका के लिए एक कुंजी कॉलम के सबसेट का उपयोग करके बनाया गया एक सूचकांक है। सबसेट को क्रिएट इंडेक्स के दौरान दिए गए कंडीशनल एक्सप्रेशन से परिभाषित किया जाता है। तो आंशिक अनुक्रमणिका के साथ, अनुक्रमणिका डेटा संग्रहीत करने के लिए संग्रहण स्थान सहेजा जाता है। तो उपयोगकर्ता को इस तरह से शर्त का चयन करना चाहिए कि वे बहुत सामान्य मान नहीं हैं, क्योंकि अधिक लगातार (सामान्य) मानों के लिए वैसे भी इंडेक्स स्कैन नहीं चुना जाएगा। शेष कार्यक्षमता सामान्य अनुक्रमणिका के समान ही रहती है। उदाहरण:आंशिक अनुक्रमणिका
- अभिव्यक्ति सूचकांक: PostgreSQL में एक्सप्रेशन इंडेक्स एक और तरह का लचीलापन देता है। अब तक चर्चा की गई सभी अनुक्रमणिकाएं, आंशिक अनुक्रमणिका सहित, स्तंभों के एक विशेष समूह पर हैं। लेकिन क्या होगा यदि किसी क्वेरी में एक्सप्रेशन (एक या अधिक कॉलम वाले एक्सप्रेशन) के आधार पर एक टेबल तक पहुंच शामिल है, बिना एक्सप्रेशन इंडेक्स के यह इंडेक्स स्कैन का चयन नहीं करेगा। तो इस तरह के प्रश्नों को तेजी से एक्सेस करने के लिए, PostgreSQL अभिव्यक्ति पर एक इंडेक्स बनाने की अनुमति देता है। शेष कार्यक्षमता सामान्य अनुक्रमणिका के समान ही रहती है।
 उदाहरण:एक्सप्रेशन इंडेक्स
उदाहरण:एक्सप्रेशन इंडेक्स
InnoDB में अनुक्रमणिका संग्रहण
इंडेक्स का उपयोग और कार्यक्षमता ज्यादातर वही है जो पोस्टग्रेएसक्यूएल में क्लस्टर्ड इंडेक्स के मामले में एक बड़ा अंतर है।
InnoDB इंडेक्स की दो श्रेणियों का समर्थन करता है:
- संकुल सूचकांक
- माध्यमिक सूचकांक
संकुल अनुक्रमणिका
InnoDB में क्लस्टर्ड इंडेक्स एक विशेष प्रकार का इंडेक्स है। यहां अनुक्रमित डेटा अलग से संग्रहीत नहीं किया जाता है बल्कि यह संपूर्ण पंक्ति डेटा का हिस्सा होता है। दूसरे शब्दों में, संकुल अनुक्रमणिका केवल तालिका डेटा को अनुक्रमणिका के कुंजी स्तंभ का उपयोग करके भौतिक रूप से क्रमबद्ध करने के लिए बाध्य करती है। इसे "शब्दकोश" के रूप में माना जा सकता है, जहां डेटा को वर्णमाला के आधार पर क्रमबद्ध किया जाता है।
चूंकि क्लस्टर इंडेक्स इंडेक्स कुंजी का उपयोग करके पंक्तियों को सॉर्ट करता है, इसलिए केवल एक क्लस्टर इंडेक्स हो सकता है। इसके अलावा, एक क्लस्टर इंडेक्स होना चाहिए क्योंकि InnoDB विभिन्न डेटा संचालन के दौरान डेटा को बेहतर ढंग से हेरफेर करने के लिए उसी का उपयोग करता है।
निम्न प्राथमिकता के अनुसार तालिका स्तंभों में से किसी एक का उपयोग करके क्लस्टर्ड अनुक्रमणिका स्वचालित रूप से (तालिका निर्माण के भाग के रूप में) बनाई जाती है:
- यदि प्राथमिक कुंजी का उल्लेख तालिका निर्माण के भाग के रूप में किया गया है तो प्राथमिक कुंजी का उपयोग करना।
- कोई भी अद्वितीय कॉलम चुनता है जहां सभी प्रमुख कॉलम न्यूल नहीं हैं।
- अन्यथा आंतरिक रूप से एक सिस्टम कॉलम पर एक छिपा हुआ क्लस्टर इंडेक्स उत्पन्न करता है जिसमें प्रत्येक पंक्ति की पंक्ति आईडी होती है।
PostgreSQL नॉन-क्लस्टर इंडेक्स के विपरीत, InnoDB क्लस्टर इंडेक्स का उपयोग करके एक पंक्ति को तेजी से एक्सेस करता है क्योंकि इंडेक्स सर्च सभी पंक्ति डेटा के साथ सीधे पेज पर जाता है और इसलिए रैंडम I/O से बचता है।
क्लस्टर इंडेक्स का उपयोग करके तालिका डेटा को क्रमबद्ध क्रम में प्राप्त करना बहुत तेज़ है क्योंकि सभी डेटा पहले से ही सॉर्ट किए गए हैं और संपूर्ण डेटा भी उपलब्ध है।
माध्यमिक अनुक्रमणिका
InnoDB में स्पष्ट रूप से बनाए गए इंडेक्स को सेकेंडरी इंडेक्स माना जाता है, जो PostgreSQL नॉन-क्लस्टर इंडेक्स के समान है। सेकेंडरी इंडेक्स स्टोरेज में प्रत्येक रिकॉर्ड में पंक्तियों के प्राथमिक कुंजी कॉलम होते हैं (जो क्लस्टर इंडेक्स बनाने के लिए उपयोग किए जाते थे) और सेकेंडरी इंडेक्स बनाने के लिए निर्दिष्ट कॉलम भी होते हैं।
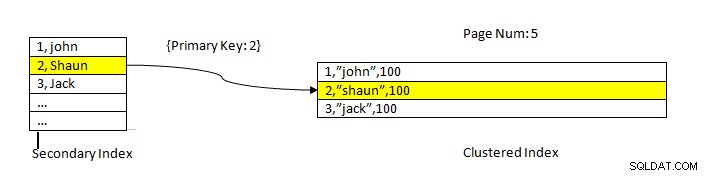 InnoDB:डेटा इंडेक्स का उपयोग करके पढ़ा जाता है
InnoDB:डेटा इंडेक्स का उपयोग करके पढ़ा जाता है सेकेंडरी इंडेक्स का उपयोग करके डेटा प्राप्त करना PostgreSQL के समान है, सिवाय इसके कि InnoDB सेकेंडरी इंडेक्स लुकअप क्लस्टर इंडेक्स से शेष डेटा लाने के लिए पॉइंटर के रूप में एक प्राथमिक कुंजी देता है।
उदाहरण के लिए, जैसा कि ऊपर चित्र में दिखाया गया है, संकुल सूचकांक ID, . कॉलम पर है इसलिए तालिका डेटा उसी के अनुसार क्रमबद्ध किया जाता है। द्वितीयक अनुक्रमणिका स्तंभ “नाम . पर है ”, इसलिए जैसा कि हम देख सकते हैं कि सेकेंडरी इंडेक्स में आईडी और नाम दोनों का मान होता है। एक बार जब हम सेकेंडरी इंडेक्स का उपयोग करके देखते हैं, तो यह संबंधित कुंजी मान के साथ उपयुक्त स्लॉट ढूंढता है। फिर संबंधित प्राथमिक कुंजी का उपयोग क्लस्टर इंडेक्स से डेटा के शेष भाग को संदर्भित करने के लिए किया जाता है।
इंडेक्स के लिए एमवीसीसी
क्लस्टर इंडेक्स एमवीसीसी पारंपरिक इनो डीबी पूर्ववत मॉडल का उपयोग करता है (वास्तव में पूरे डेटा एमवीसीसी के समान, क्योंकि क्लस्टर इंडेक्स पूरे डेटा के अलावा कुछ भी नहीं है)।
लेकिन माध्यमिक सूचकांक एमवीसीसी एमवीसीसी को बनाए रखने के लिए थोड़ा अलग दृष्टिकोण का उपयोग करता है। सेकेंडरी इंडेक्स के अपडेट होने पर, पुरानी इंडेक्स एंट्री को डिलीट-मार्क कर दिया जाता है और नए रिकॉर्ड्स को उसी स्टोरेज में डाला जाता है यानी UPDATE इन-प्लेस नहीं होता है। अंत में, पुरानी अनुक्रमणिका प्रविष्टियाँ शुद्ध हो जाती हैं। अब तक आपने देखा होगा कि InnoDB सेकेंडरी इंडेक्स MVCC लगभग PostgreSQL MVCC मॉडल के समान ही है।
सूचकांक प्रकार
InnoDB केवल B-Tree प्रकार के अनुक्रमणिका का समर्थन करता है और इसलिए अनुक्रमणिका बनाते समय निर्दिष्ट करने की आवश्यकता नहीं है।
विविध:अनुकूली हैश इंडेक्स
जैसा कि पिछले खंड में बताया गया है कि केवल बी-ट्री टाइप इंडेक्स इनो डीबी द्वारा समर्थित है लेकिन एक मोड़ है। InnoDB में स्वचालित रूप से यह पता लगाने की कार्यक्षमता है कि क्या क्वेरी हैश इंडेक्स बनाने से लाभान्वित हो सकती है और तालिका का पूरा डेटा भी मेमोरी में फिट हो सकता है, तो यह स्वचालित रूप से ऐसा करता है।
हैश इंडेक्स क्वेरी के आधार पर मौजूदा बी-ट्री इंडेक्स का उपयोग करके बनाया गया है। यदि कई सेकेंडरी बी-ट्री इंडेक्स हैं, तो यह क्वेरी के अनुसार क्वालिफाई करने वाले को चुनेगा। बनाया गया हैश इंडेक्स पूरा नहीं हुआ है, यह केवल डेटा उपयोग पैटर्न के अनुसार आंशिक इंडेक्स बनाता है।
क्वेरी प्रदर्शन को गतिशील रूप से बेहतर बनाने के लिए यह वास्तव में शक्तिशाली सुविधाओं में से एक है।
निष्कर्ष
किसी भी डेटाबेस में किसी भी इंडेक्स का उपयोग वास्तव में पढ़ने के प्रदर्शन को बेहतर बनाने में सहायक होता है लेकिन साथ ही, यह INSERT/UPDATE प्रदर्शन को कम करता है क्योंकि इसे अतिरिक्त डेटा लिखने की आवश्यकता होती है। इसलिए अनुक्रमणिका को बहुत बुद्धिमानी से चुना जाना चाहिए और केवल तभी बनाया जाना चाहिए जब अनुक्रमणिका कुंजियों का उपयोग डेटा लाने के लिए विधेय के रूप में किया जा रहा हो।
क्लस्टर इंडेक्स के संदर्भ में InnoDB एक बहुत अच्छी सुविधा प्रदान करता है, जो उपयोग-मामलों के आधार पर बहुत उपयोगी हो सकता है। साथ ही, इसकी अनुकूली हैश अनुक्रमण बहुत शक्तिशाली है।
जबकि PostgreSQL विभिन्न प्रकार के इंडेक्स प्रदान करता है, जो वास्तव में फीचर पहुंच विकल्प दे सकता है और व्यावसायिक उपयोग-मामले के आधार पर एक या सभी का उपयोग किया जा सकता है। साथ ही आंशिक और व्यंजक सूचकांक उपयोग के मामले के आधार पर काफी उपयोगी होते हैं।