मैं दूसरे प्रश्न से शुरू करूंगा, जो आसान है। dplyr . का उपयोग करना पैकेज, आप उपयोग कर सकते हैं top_n किसी दिए गए कॉलम के लिए n सबसे बड़ी पंक्तियाँ प्राप्त करने के लिए। उदाहरण के लिए:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
ध्यान दें कि यदि nवें स्थान के लिए संबंध हैं तो आपको n से अधिक पंक्तियाँ मिलेंगी। इस प्रकार top_n(p_ash_r_100, 10, SMPL_CNT) चौथे के लिए 17-तरफा टाई के कारण पूरे नमूना डेटा सेट को वापस कर देगा।
पहले प्रश्न के लिए, geom_area . के लिए दस्तावेज़ीकरण एक सुराग प्रदान करता है:
इससे पता चलता है कि geom_area उम्मीद है कि x से मैप किया गया कॉलम संख्यात्मक होना चाहिए। p_ash_r_100 . के लिए लिस्टिंग के आधार पर , SMPL_TIME एक चरित्र वेक्टर प्रतीत होता है। lubridate के साथ पैकेज, हम SMPL_TIME में कनवर्ट कर सकते हैं दिनांक-समय पर dmy_hm . के साथ :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
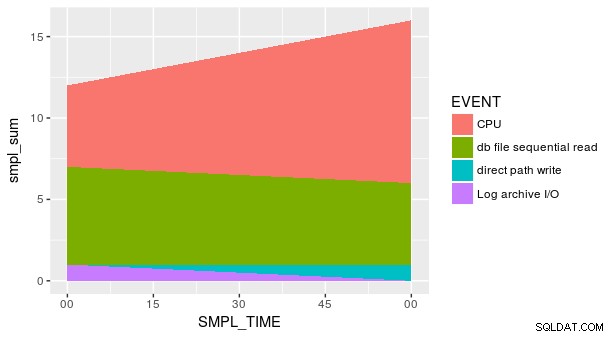
हालाँकि, यह आपके इच्छित प्लॉट को प्राप्त करने के लिए पर्याप्त नहीं है क्योंकि y . के कई मान हैं x . के प्रत्येक संयोजन के लिए और fill (जो geom_area . के लिए सही सौंदर्यबोध है , नहीं "col ")। प्लॉट करने से पहले हमें डेटा को संक्षेप में प्रस्तुत करना होगा:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
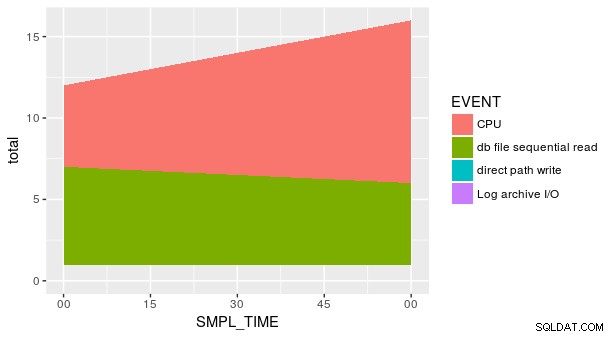
फिर भी साजिश अभी भी सही नहीं है। ऐसा इसलिए है क्योंकि SMPL_TIME . का हर संयोजन और EVENT डेटा सेट में प्रतिनिधित्व नहीं है। हमें स्पष्ट रूप से बताना होगा geom_area वह y उन लापता पंक्तियों के लिए शून्य के बराबर है। एक तरीका आसान fill . का उपयोग करना है tidyr::spread . में तर्क ।
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()