आपके एप्लिकेशन की कार्यक्षमता या किसी विशिष्ट संग्रहीत कार्यविधि के प्रदर्शन या विकास परिवेश में एक तदर्थ क्वेरी के प्रदर्शन का परीक्षण करते समय, आपको अपने विकास डेटाबेस में विशिष्ट या उत्पादन डेटाबेस में संग्रहीत डेटा के समान डेटा संग्रहीत करने की आवश्यकता होती है। ऐसा इसलिए है क्योंकि 50 रिकॉर्ड संसाधित करने वाली क्वेरी का प्रदर्शन उसी क्वेरी के प्रदर्शन से भिन्न होगा जो 50M पंक्तियों को संसाधित कर रहा है। परीक्षण उद्देश्यों के लिए विकास डेटाबेस सर्वर पर उत्पादन डेटाबेस की एक प्रति को पुनर्स्थापित करना हमेशा एक वैध विकल्प नहीं होता है, क्योंकि इन डेटाबेस में संग्रहीत महत्वपूर्ण डेटा और सभी कर्मचारियों को देखने के लिए खुला नहीं होना चाहिए, जब तक कि आप एक नया विकसित नहीं कर रहे हैं एप्लिकेशन और अभी तक कोई उत्पादन डेटाबेस नहीं है।
परीक्षण डेटा के साथ विकास डेटाबेस तालिकाओं को भरना सबसे अच्छा और सबसे सुरक्षित विकल्प है। परीक्षण डेटा पीढ़ी उत्पादन डेटा को बदले बिना एप्लिकेशन के प्रदर्शन या नई कार्यक्षमता के परीक्षण के लिए उपयोगी है। परीक्षण डेटा उत्पन्न करने का कोई भी सीधा-आगे तरीका नहीं है जो सभी परिदृश्यों में फिट होगा, खासकर जब आपको जटिल प्रश्नों और लेनदेन के प्रदर्शन का परीक्षण करने के लिए बड़ी मात्रा में डेटा उत्पन्न करने की आवश्यकता होती है जिसमें आपको परीक्षण मामलों के सभी संभावित संयोजनों को कवर करना चाहिए।
बड़ी मात्रा में डेटा के साथ एक तालिका भरने के लिए, सबसे आसान तरीका एक साधारण स्क्रिप्ट लिखना है जो आपके लिए आवश्यक डुप्लिकेट की संख्या के साथ डेटाबेस तालिका में समान रिकॉर्ड सम्मिलित करता रहता है। लेकिन समस्या यह है कि SQL सर्वर क्वेरी ऑप्टिमाइज़र डेटा वितरण में अंतर के कारण उत्पादन डेटाबेस पर निर्मित विकास डेटाबेस से भिन्न योजना बनाएगा। उदाहरण के लिए, नीचे दी गई स्क्रिप्ट छात्रों की तालिका को GO नंबर . का उपयोग करके 100K निरर्थक परीक्षण रिकॉर्ड से भर देगी कथन:
छात्रों में सम्मिलित करें (प्रथम नाम, अंतिम नाम, जन्मतिथि, STDAपता) मान ('जॉन', 'होरोल्ड', '2005-10-01', 'लंदन, St15') 25000 छात्रों में प्रवेश करें (प्रथम नाम, अंतिम नाम, जन्मतिथि, STDAपता) VALUES ('माइक', 'Zikle','2005-06-08','London, St18')GO 25000छात्रों में प्रवेश करें (प्रथम नाम, अंतिम नाम, जन्मतिथि, STDAपता) मान ('फारुक', 'सेड्रिक',' 2005-03-15', 'लंदन, सेंट 24') 25000 छात्रों में प्रवेश करें (प्रथम नाम, अंतिम नाम, जन्मतिथि, एसटीडीपता) मान ('फैसल', 'अली', '2005-12-05', 'लंदन, सेंट 41') GO 25000 एक अन्य विकल्प प्रत्येक कॉलम के डेटा प्रकार के आधार पर यादृच्छिक डेटा उत्पन्न करना है। IDENTITY प्रॉपर्टी वाला आईडी कॉलम आपकी ओर से किसी भी कोडिंग प्रयास की आवश्यकता के बिना स्वचालित रूप से अनुक्रम संख्या उत्पन्न करेगा। लेकिन अगर आप छात्रों के लिए रैंडम ग्रेड जेनरेट करने की योजना बना रहे हैं, तो आप RAND() से लाभ उठा सकते हैं। टी-एसक्यूएल फ़ंक्शन और परिणाम को आवश्यक संख्यात्मक डेटा प्रकार के रूप में डालें। उदाहरण के लिए, नीचे दी गई स्क्रिप्ट तीन अलग-अलग डेटा प्रकारों के साथ 1 और 100 के बीच के छात्र के लिए 100K यादृच्छिक ग्रेड उत्पन्न करेगी:INTEGER ग्रेड, वास्तविक ग्रेड और दशमलव ग्रेड, आपके गणितीय और प्रोग्रामिंग कौशल के आधार पर इन मूल्यों की श्रेणियों को नियंत्रित करने की क्षमता के साथ। , जैसा कि नीचे दिखाया गया है:
छात्र ग्रेड (एसटीडीग्रेड) मूल्यों में डालें (कास्ट (रैंड (चेकसम (नया ())) * 100 int के रूप में)) INT_GrageGO 100000 के रूप में छात्र ग्रेड (एसटीडीग्रेड) मूल्यों में डालें (कास्ट (रैंड (चेकसम (नया ())))* 100 वास्तविक के रूप में)) AS Real_GrageGO 100000छात्रों के ग्रेड में डालें (STDGrade) मान (CAST(RAND(CHECKSUM(NEWID()))*100 दशमलव के रूप में(6,2))) दशमलव के रूप में_GrageGO 100000
एडवेंचरवर्क्स और नॉर्थविंड Microsoft परीक्षण डेटाबेस का उपयोग करके यादृच्छिक नाम उत्पन्न करना भी प्राप्त किया जा सकता है . आपको इन डेटाबेस को Microsoft वेबसाइट से डाउनलोड करना होगा, इन डेटाबेस को अपने SQL सर्वर इंस्टेंस में संलग्न करना होगा और अपने विकास डेटाबेस में यादृच्छिक नाम उत्पन्न करने के लिए इन डेटाबेस में संग्रहीत डेटा से लाभ लेना होगा। उदाहरण के लिए, AdventureworksDW2016CTP3 डेटाबेस से DimCustomer तालिका में लगभग 18K प्रथम नाम, मध्य नाम और अंतिम नाम हैं जिनका आप उपयोग कर सकते हैं। आप 18K मान को पार करने के लिए इन नामों के संयोजनों की एक बड़ी संख्या उत्पन्न करने के लिए क्रॉस जॉइन स्टेटमेंट का भी उपयोग कर सकते हैं। निम्नलिखित स्क्रिप्ट का उपयोग 100K प्रथम नाम और अंतिम नाम उत्पन्न करने के लिए किया जा सकता है:
छात्र ग्रेड में सम्मिलित करें (प्रथम_नाम, अंतिम_नाम) शीर्ष 100000 एन का चयन करें। [प्रथम नाम], सीएन।>Microsoft परीक्षण डेटाबेस से यादृच्छिक ईमेल पते और दिनांक भी उत्पन्न किए जा सकते हैं। उदाहरण के लिए, एक ही DimCustomer तालिका से जन्मतिथि कॉलम और ईमेल पता कॉलम हमें यादृच्छिक तिथियां और ईमेल पते प्रदान कर सकते हैं। नीचे दी गई स्क्रिप्ट का उपयोग जन्मतिथि और ईमेल पतों के 100K संयोजन को उत्पन्न करने के लिए किया जा सकता है:
छात्र ग्रेड (जन्मतिथि, ईमेल पता) में डालें शीर्ष 100000 एन.जन्मतिथि, सीएन.ईमेल पता एडवेंचरवर्क्स डीडब्ल्यू2016सीटीपी3 से चुनें।[डीबीओ]।AdventureWorks2016CTP3 परीक्षण डेटाबेस से Person.CountryRegion तालिका का उपयोग करके देश कॉलम के यादृच्छिक मान भी उत्पन्न किए जा सकते हैं। यह आपको 200 से अधिक देशों के नाम और कोड प्रदान कर सकता है जिनका आप अपने विकास डेटाबेस में लाभ उठा सकते हैं। उदाहरण के लिए, आप इसे देश के नाम और कोड के बीच मैप करने के लिए लुकअप टेबल के रूप में ले सकते हैं, जैसा कि नीचे दी गई स्क्रिप्ट में है:
इन्टर इन टू मैप्ड कॉन्ट्रीज़ (कंट्री रीजन कोड, नाम) चुनें [कंट्री रीजनकोड], [नाम] [एडवेंचरवर्क्स2016 सीटीपी3] से। 1 और 238 के बीच उत्पन्न, नीचे दी गई स्क्रिप्ट के रूप में:स्टूडेंट्सग्रेड्स (देश_नाम) मानों में डालें ((मैप्ड कॉन्ट्रीज से नाम चुनें जहां आईडी =कास्ट (रैंड (चेकसम (नया ())) * 238 int के रूप में)) 10000 पर जाएं>यादृच्छिक पता मान उत्पन्न करने के लिए, आप व्यक्ति में संग्रहीत डेटा से लाभ उठा सकते हैं। AdventureWorks2016CTP3 परीक्षण डेटाबेस से पता तालिका। इसमें अपने स्थानिक स्थान के साथ 19K से अधिक विभिन्न पते हैं, जिन्हें आप आसानी से अपने विकास डेटाबेस में उपयोग कर सकते हैं और इन मानों से यादृच्छिक संयोजन ले सकते हैं, उसी तरह जैसे हमने पिछले उदाहरण में किया था। व्यक्ति से यादृच्छिक 100K पते उत्पन्न करने के लिए नीचे दी गई स्क्रिप्ट का आसानी से उपयोग किया जा सकता है। पता तालिका:
छात्र ग्रेड (STD_Address) मानों में प्रवेश करें (([AdventureWorks2016CTP3] से नाम चुनें। [व्यक्ति]। [पता] जहां [AddressID] =CAST (RAND (CHECKSUM (NEWID ())) * 19614 int के रूप में)) GO 100000विशिष्ट सिस्टम उपयोगकर्ताओं के लिए यादृच्छिक पासवर्ड उत्पन्न करने के लिए, हम CRYPT_GEN_RANDOM से लाभ उठा सकते हैं टी-एसक्यूएल समारोह। यह फ़ंक्शन क्रिप्टो एपीआई (सीएपीआई) द्वारा उत्पन्न बाइट्स की एक निर्दिष्ट संख्या की लंबाई के साथ एक क्रिप्टोग्राफ़िक, बेतरतीब ढंग से उत्पन्न हेक्साडेसिमल संख्या देता है। उस फ़ंक्शन से लौटाया गया मान अधिक सार्थक पासवर्ड रखने के लिए VARCHAR डेटा प्रकार में परिवर्तित किया जा सकता है, जैसा कि नीचे दी गई स्क्रिप्ट में है, जो 100K यादृच्छिक पासवर्ड उत्पन्न करता है:
सिस्टम यूज़र (उपयोगकर्ता_पासवर्ड) में सम्मिलित करें, कन्वर्ट चुनें(varchar(20), CRYPT_GEN_RANDOM(20))GO 100000विकास डेटाबेस तालिकाओं को भरने के लिए परीक्षण डेटा उत्पन्न करना भी आसानी से और प्रत्येक डेटा प्रकार के लिए स्क्रिप्ट लिखने या तीसरे पक्ष के टूल का उपयोग किए बिना समय बर्बाद किए बिना किया जा सकता है। आप बाजार में विभिन्न उपकरण पा सकते हैं जिनका उपयोग परीक्षण डेटा उत्पन्न करने के लिए किया जा सकता है। इन अद्भुत उपकरणों में से एक है SQL सर्वर के लिए dbForge डेटा जेनरेटर . यह विकास डेटाबेस के लिए सार्थक परीक्षण डेटा की तेजी से पीढ़ी के लिए एक शक्तिशाली जीयूआई उपकरण है। dbForge डेटा जनरेशन टूल में समझदार कॉन्फ़िगरेशन विकल्पों के साथ 200+ पूर्वनिर्धारित डेटा जनरेटर शामिल हैं जो आपको कॉलम-इंटेलिजेंट रैंडम डेटा का अनुकरण करने की अनुमति देते हैं। यह टूल पहले से ही डेटा से भरे SQL सर्वर डेटाबेस के लिए डेमो डेटा जेनरेट करने और अपने स्वयं के कस्टम टेस्ट डेटा जेनरेटर बनाने की अनुमति देता है। SQL सर्वर के लिए dbForge डेटा जेनरेटर वास्तविक डेटा की तरह दिखने वाले नमूना डेटा की लाखों पंक्तियों के साथ SQL सर्वर तालिकाओं को पॉप्युलेट करके डेमो डेटा जनरेशन पर खर्च किए गए आपके समय और प्रयास को बचा सकता है। SQL सर्वर के लिए dbForge डेटा जेनरेटर सबसे अधिक उपयोग किए जाने वाले डेटा प्रकारों जैसे कि बेसिक, बिजनेस, हेल्थ, आईटी, लोकेशन, पेमेंट और पर्सन डेटा टाइप्स के साथ टेबल को पॉप्युलेट करने में मदद करता है। नीचे दिया गया आंकड़ा दिखाता है कि यह टूल कितनी आसानी से काम करता है:
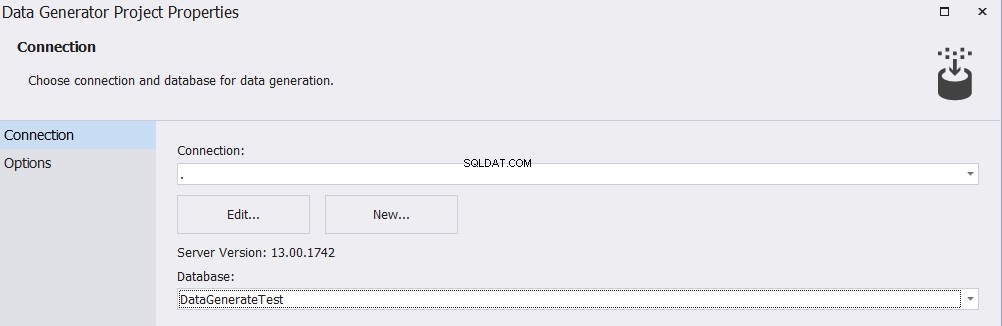
SQL सर्वर टूल के लिए dbForge डेटा जेनरेटर स्थापित करने और उस टूल को चलाने के बाद, आपको कनेक्शन विंडो में लक्ष्य सर्वर नाम और डेटाबेस नाम निर्दिष्ट करना होगा जैसा कि नीचे दिखाया गया है:
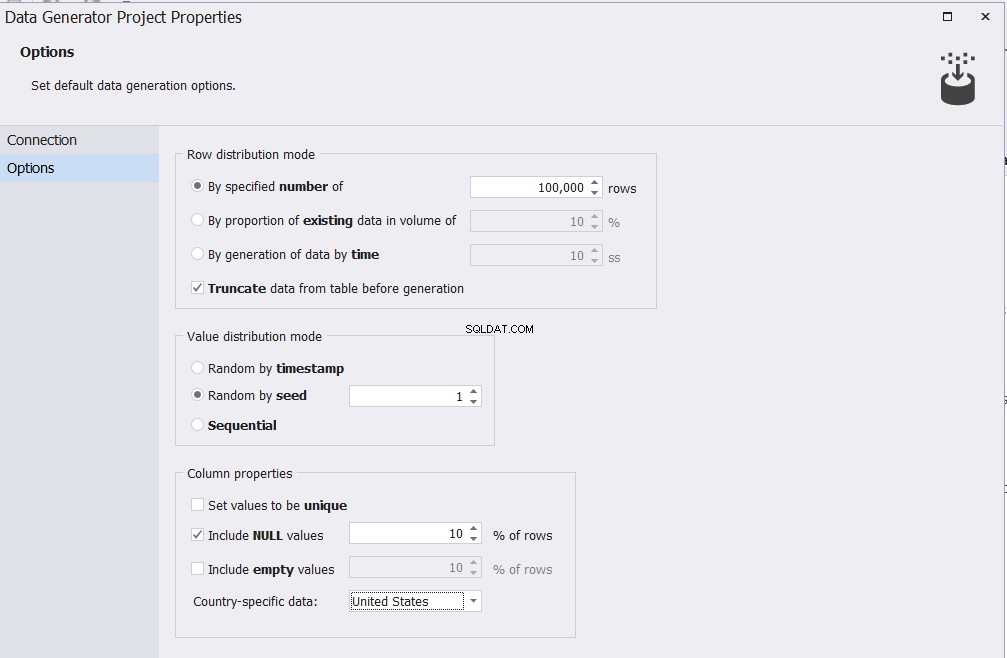
विकल्प विंडो में, आप अपनी तालिका में सम्मिलित की जाने वाली पंक्तियों की संख्या और उत्पन्न परीक्षण डेटा मानदंड को नियंत्रित करने वाले अन्य विभिन्न विकल्पों को निर्दिष्ट कर सकते हैं, जैसा कि नीचे दिखाया गया है:
अपनी परीक्षण डेटा आवश्यकताओं के अनुरूप विकल्पों को अनुकूलित करने के बाद, पर क्लिक करें
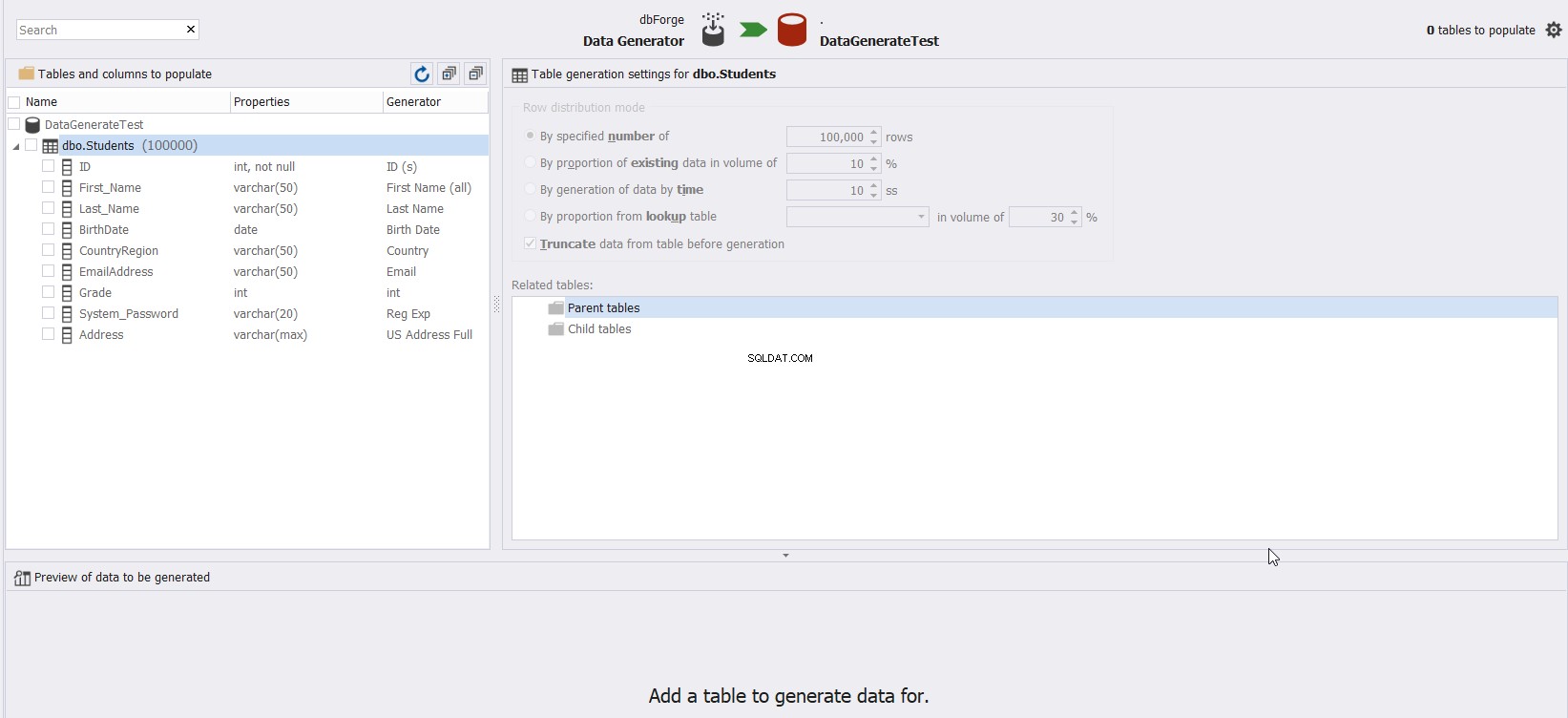
बटन, और चयनित डेटाबेस के अंतर्गत सभी तालिकाओं और स्तंभों की सूची के साथ एक नई विंडो प्रदर्शित होगी, जिसमें पूछा जाएगा आप नीचे दिखाए गए अनुसार परीक्षण डेटा से भरने के लिए कौन सी तालिका चुनें:
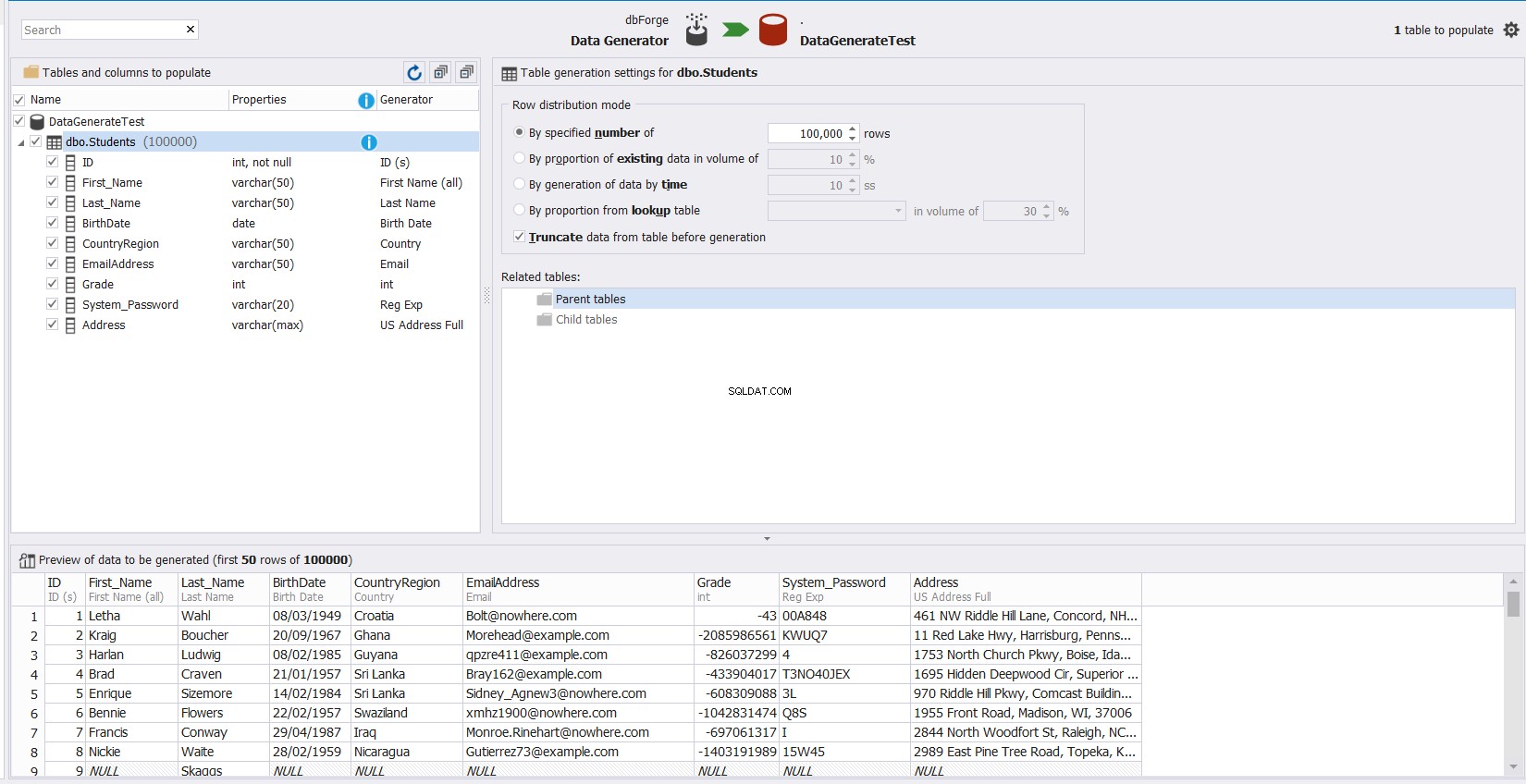
बस उस तालिका का चयन करें जिसे आपको डेटा से भरने की आवश्यकता है, और टूल स्वचालित रूप से आपको विंडो के नीचे पूर्वावलोकन अनुभाग में सुझाए गए डेटा और उस तालिका के प्रत्येक कॉलम के लिए अनुकूलन योग्य विकल्प प्रदान करेगा जिसे आप आसानी से अनुकूलित कर सकते हैं, जैसा कि दिखाया गया है नीचे:
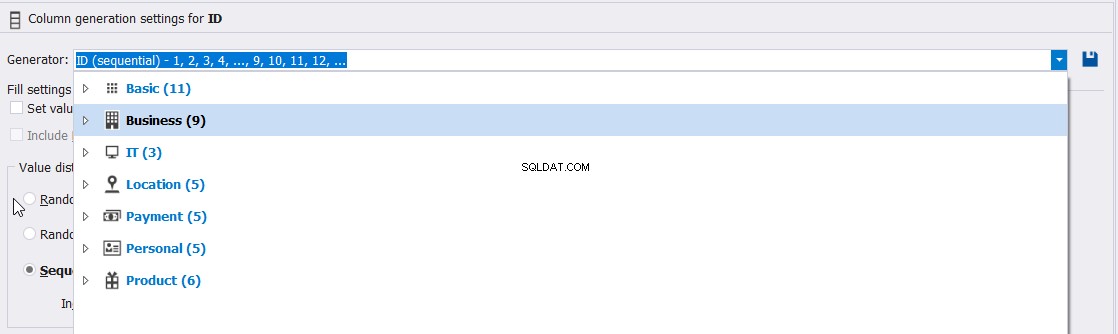
उदाहरण के लिए, आप बिल्ट-इन जेनरेटर डेटा प्रकारों में से चुन सकते हैं जिनका उपयोग पहले बताए अनुसार आईडी कॉलम मान जेनरेट करने के लिए किया जा सकता है:
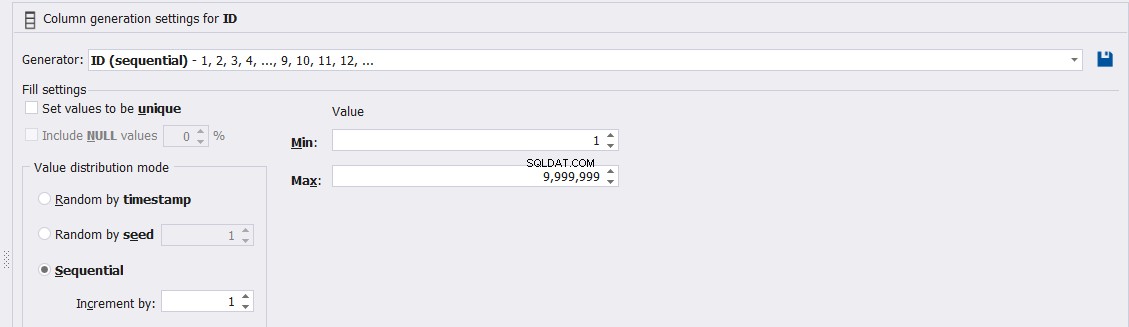
या उस आईडी कॉलम मानों की विशेषताओं को कस्टमाइज़ करें, जैसे कि विशिष्टता, न्यूनतम, अधिकतम और जेनरेट किए गए मानों की वृद्धि, जैसा कि नीचे दिया गया है:
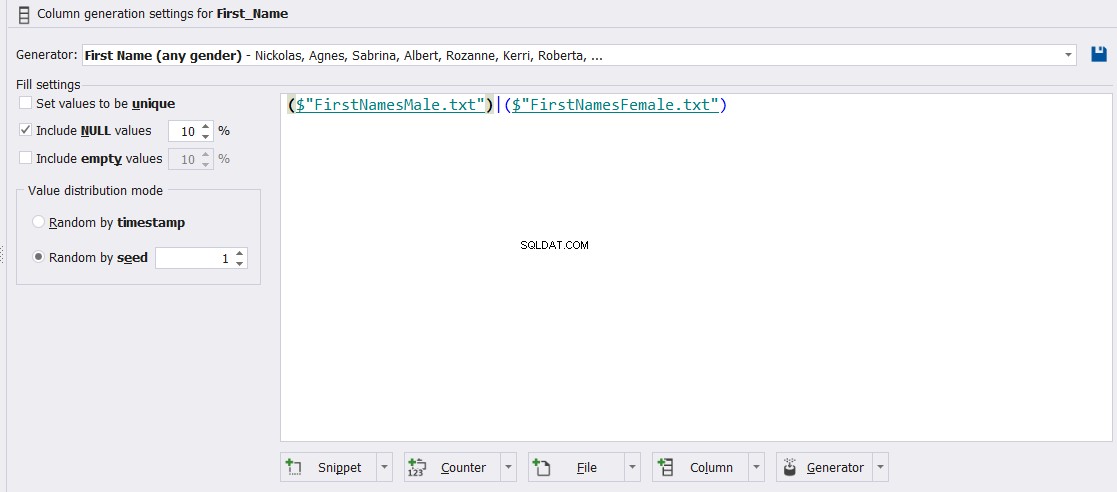
इसके अलावा, First_Name कॉलम को पुरुष या महिला या इन दो प्रकारों के संयोजन तक सीमित किया जा सकता है। साथ ही, आप उस कॉलम में NULL या खाली मानों के प्रतिशत को नियंत्रित कर सकते हैं, जैसा कि नीचे दिखाया गया है:
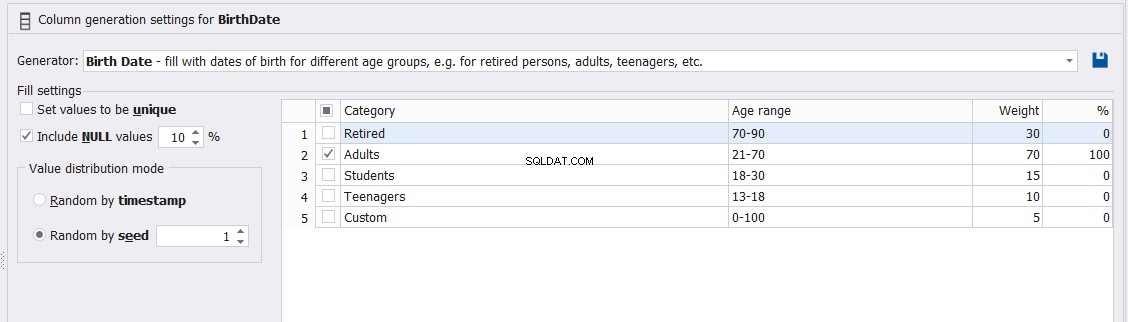
जन्मतिथि कॉलम को उस श्रेणी को निर्दिष्ट करके भी नियंत्रित किया जा सकता है जिसके अंतर्गत ये छात्र आते हैं, जैसे छात्र, किशोर, वयस्क या सेवानिवृत्त जैसा कि नीचे दिखाया गया है:
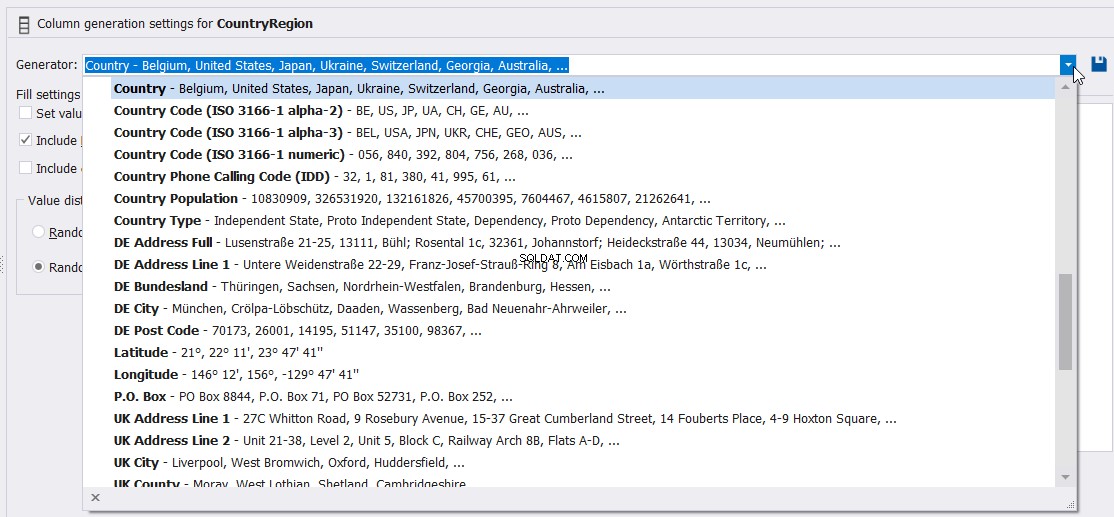
आप पूरी तरह से वर्णित जनरेटर को भी निर्दिष्ट कर सकते हैं जिसका उपयोग नीचे दिखाए गए अनुसार देश कॉलम मान उत्पन्न करने के लिए किया जा सकता है:
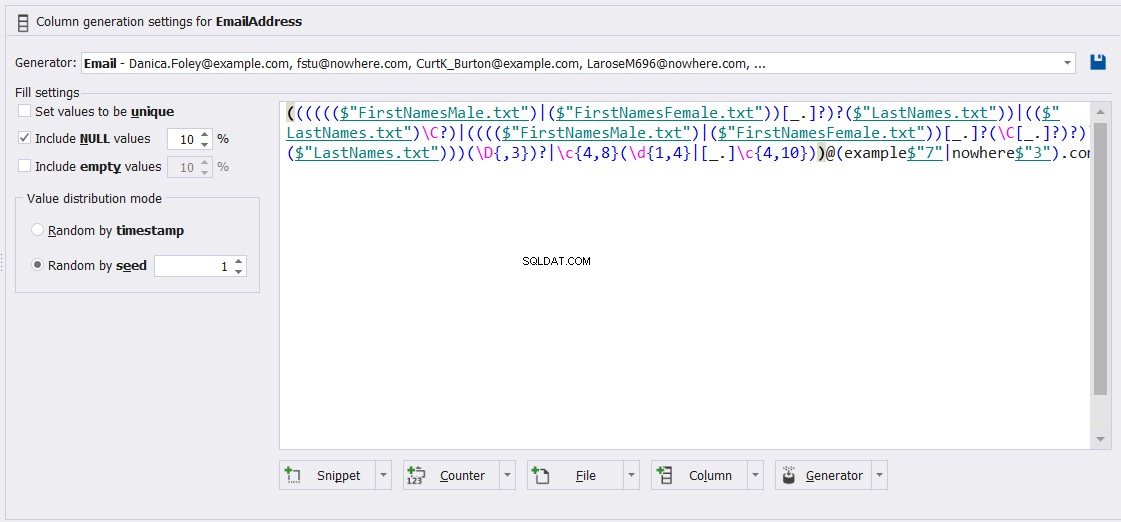
और उस समीकरण को अनुकूलित करें जिसका उपयोग ईमेल पता कॉलम मान उत्पन्न करने के लिए निम्नानुसार किया जाएगा:
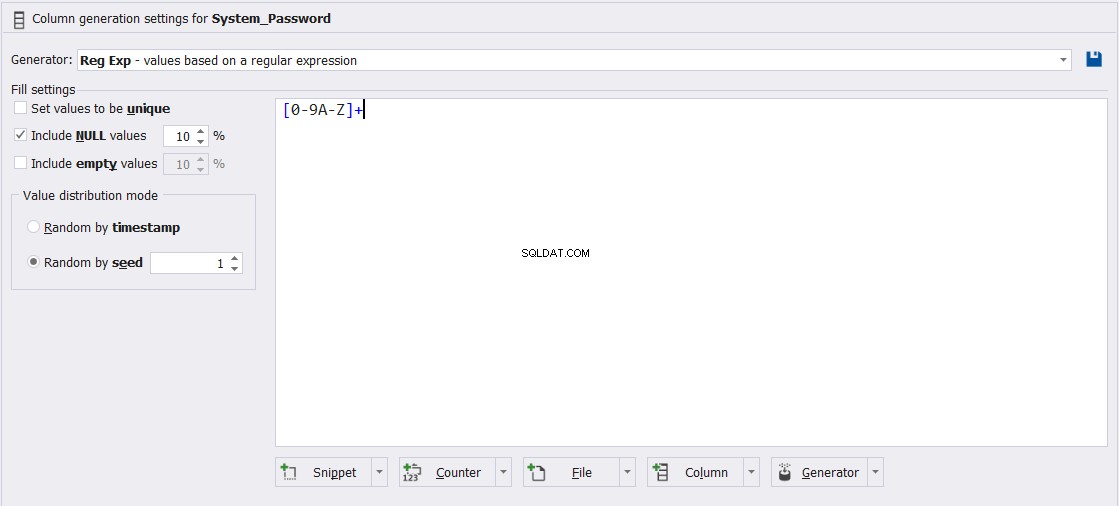
अनुकूलन योग्य समीकरण की जटिलता के अतिरिक्त, हम पासवर्ड कॉलम मान उत्पन्न करते हैं, जैसा कि नीचे दिखाया गया है:
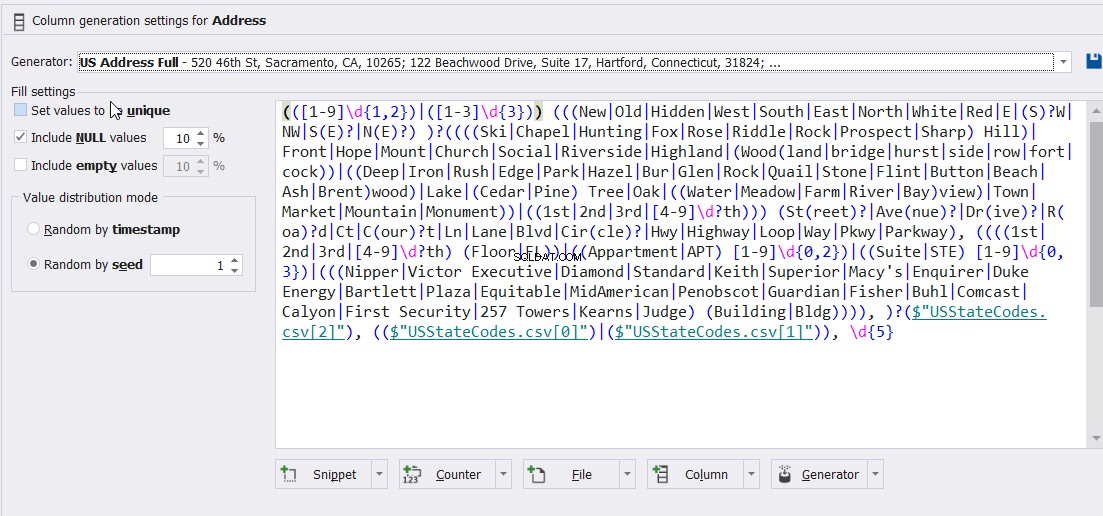
और अंत में, मेरे उदाहरण के लिए और इस जादुई उपकरण के लिए नहीं, जनरेटर और समीकरण नीचे पता कॉलम मान उत्पन्न करने के लिए उपयोग किए जाते हैं:
इस दौरे के बाद, आप कल्पना कर सकते हैं कि यह जादुई उपकरण आपके एप्लिकेशन की कार्यक्षमता का परीक्षण करने के लिए डेटा उत्पन्न करने और वास्तविक समय परिदृश्यों को अनुकरण करने में आपकी सहायता कैसे करेगा। इसे इंस्टॉल करें और सभी उपलब्ध सुविधाओं और विकल्पों का लाभ उठाएं।
उपयोगी टूल:
SQL सर्वर के लिए dbForge डेटा जेनरेटर - SQL सर्वर डेटाबेस के लिए सार्थक परीक्षण डेटा की तेज़ पीढ़ी के लिए शक्तिशाली GUI टूल।