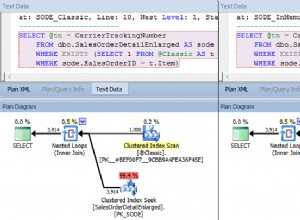
मुझे सच में यकीन नहीं है कि आपका प्रश्न क्या है। हां, इन दो निष्पादन योजनाओं के अनुसार, इस मामले में, सबक्वेरी पद्धति की अपेक्षित लागत कम है। यह बहुत आश्चर्यजनक नहीं लगता, क्योंकि यह आपकी रुचि की सटीक पंक्ति का पता लगाने के लिए इंडेक्स का उपयोग कर सकता है। विशेष रूप से इस मामले में, सबक्वेरी को केवल पीके इंडेक्स का एक बहुत ही त्वरित स्कैन करना होता है। स्थिति भिन्न हो सकती है यदि सबक्वेरी में ऐसे स्तंभ शामिल हों जो अनुक्रमणिका का भाग नहीं थे।
rank() . का उपयोग कर क्वेरी सभी मिलान पंक्तियों को प्राप्त करना है और उन्हें रैंक करना है। मुझे विश्वास नहीं है कि अनुकूलक के पास यह पहचानने के लिए कोई शॉर्ट-सर्किट तर्क है कि यह एक शीर्ष-एन क्वेरी है और इसलिए पूर्ण प्रकार से बचें, भले ही आप वास्तव में शीर्ष-रैंक वाली पंक्ति की परवाह करते हैं।
आप इस फॉर्म को भी आजमा सकते हैं, जिसे ऑप्टिमाइज़र को टॉप-एन क्वेरी के रूप में पहचानना चाहिए। मैं आपके मामले में उम्मीद करूंगा कि इसके लिए इंडेक्स पर टेबल एक्सेस के बाद केवल एक रेंज स्कैन की आवश्यकता होगी।
select *
from (select *
from teste_rank r
where data_mov <= trunc(sysdate)
and codigo = 1
order by data_mov desc)
where rownum=1;