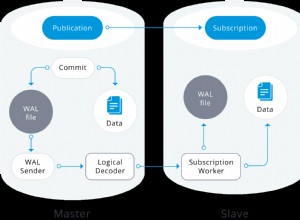
अधिकांश एंटरप्राइज़ डेटाबेस, Oracle में शामिल हैं, किसी दिए गए SQL कथन के लिए उपयुक्त क्वेरी योजना निर्धारित करने के लिए लागत-आधारित अनुकूलक का उपयोग करते हैं। इसका मतलब यह है कि ऑप्टिमाइज़र डेटा के बारे में जानकारी का उपयोग यह निर्धारित करने के लिए करता है कि नियमों पर निर्भर होने के बजाय किसी क्वेरी को कैसे निष्पादित किया जाए (यह वही है जो पुराने नियम-आधारित ऑप्टिमाइज़र ने किया था)।
उदाहरण के लिए, एक साधारण बग-ट्रैकिंग एप्लिकेशन के लिए एक तालिका की कल्पना करें
CREATE TABLE issues (
issue_id number primary key,
issue_text clob,
issue_status varchar2(10)
);
CREATE INDEX idx_issue_status
ON issues( issue_status );
अगर मैं एक बड़ी कंपनी हूं, तो मेरे पास इस तालिका में 1 मिलियन पंक्तियां हो सकती हैं। उनमें से 100 के पास issue_status है ACTIVE में से, 10,000 के पास issue_status है QUEUED की, और 989,900 को COMPLETE का दर्जा प्राप्त है। अगर मैं अपने सक्रिय मुद्दों को खोजने के लिए तालिका के विरुद्ध कोई क्वेरी चलाना चाहता हूं
SELECT *
FROM issues
WHERE issue_status = 'ACTIVE'
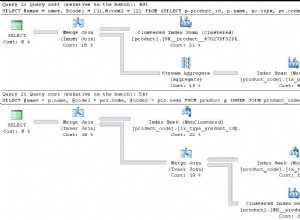
अनुकूलक के पास एक विकल्प है। यह या तो issue_status पर अनुक्रमणिका का उपयोग कर सकता है और फिर इंडेक्स में प्रत्येक पंक्ति के लिए तालिका में एकल-पंक्ति लुकअप करें जो मेल खाता है या यह issues पर एक टेबल स्कैन कर सकता है टेबल। कौन सी योजना अधिक कुशल है यह तालिका में मौजूद डेटा पर निर्भर करेगा। यदि Oracle क्वेरी से तालिका में डेटा का एक छोटा अंश लौटाने की अपेक्षा करता है, तो अनुक्रमणिका का उपयोग करना अधिक कुशल होगा। यदि Oracle को उम्मीद है कि क्वेरी तालिका में डेटा का एक बड़ा हिस्सा लौटाएगी, तो एक टेबल स्कैन अधिक कुशल होगा।
DBMS_STATS.GATHER_TABLE_STATS वह आँकड़े हैं जो Oracle को यह निर्धारण करने की अनुमति देते हैं। यह Oracle को बताता है कि तालिका में लगभग 1 मिलियन पंक्तियाँ हैं, कि issue_status के लिए 3 अलग-अलग मान हैं कॉलम, और यह कि डेटा असमान रूप से वितरित किया जाता है। तो ओरेकल सभी सक्रिय मुद्दों को खोजने के लिए क्वेरी के लिए एक इंडेक्स का उपयोग करना जानता है। लेकिन यह भी जानता है कि जब आप मुड़ते हैं और सभी बंद मुद्दों को देखने की कोशिश करते हैं
SELECT *
FROM issues
WHERE issue_status = 'CLOSED'
कि यह टेबल स्कैन करने के लिए अधिक कुशल होगा।
आंकड़े एकत्र करने से क्वेरी योजनाओं को समय के साथ बदलने की अनुमति मिलती है क्योंकि डेटा वॉल्यूम और डेटा वितरण बदलते हैं। जब आप पहली बार समस्या ट्रैकर स्थापित करते हैं, तो आपके पास बहुत कम पूर्ण समस्याएँ और अधिक सक्रिय और कतारबद्ध समस्याएँ होंगी। समय के साथ, COMPLETED मुद्दों की संख्या बहुत तेजी से बढ़ती है। जैसे-जैसे आप तालिका में अधिक पंक्तियाँ प्राप्त करते हैं और उन पंक्तियों के सापेक्ष अंश जो विभिन्न स्थितियों में हैं, बदल जाते हैं, क्वेरी योजनाएँ बदल जाएंगी, ताकि आदर्श दुनिया में, आपको हमेशा सबसे कुशल योजना मिल सके।