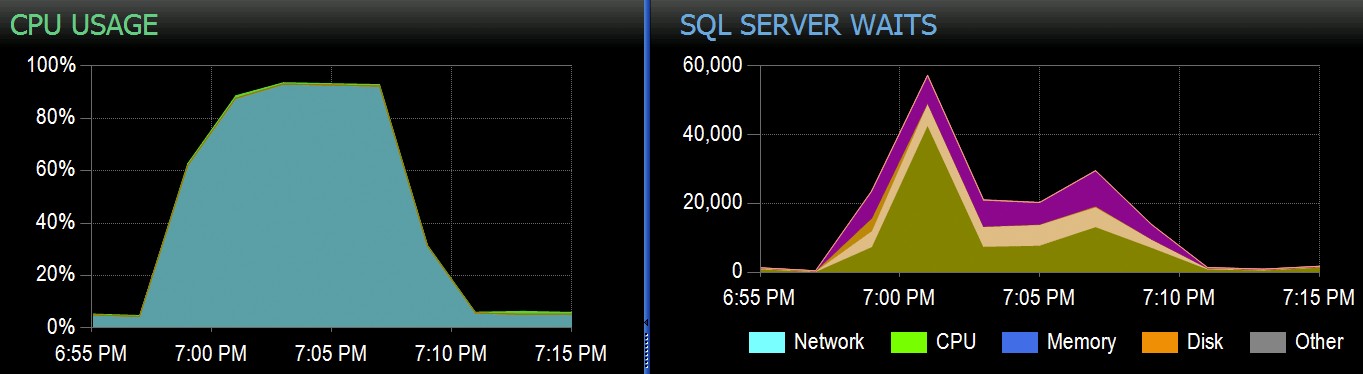
स्टैक ओवरफ्लो में, हमारे पास क्लस्टर्ड कॉलमस्टोर इंडेक्स का उपयोग करते हुए कुछ टेबल हैं, और ये हमारे अधिकांश कार्यभार के लिए बहुत अच्छा काम करते हैं। लेकिन हम हाल ही में एक ऐसी स्थिति में आए हैं जहां "सही तूफान" - एक ही सीसीआई से सभी प्रक्रियाओं को हटाने की कोशिश कर रहे कई प्रक्रियाएं - सीपीयू को अभिभूत कर देंगी क्योंकि वे सभी व्यापक रूप से समानांतर चले गए और अपने ऑपरेशन को पूरा करने के लिए लड़े। यहाँ यह सोलरविंड्स SQL संतरी में कैसा दिखता है:
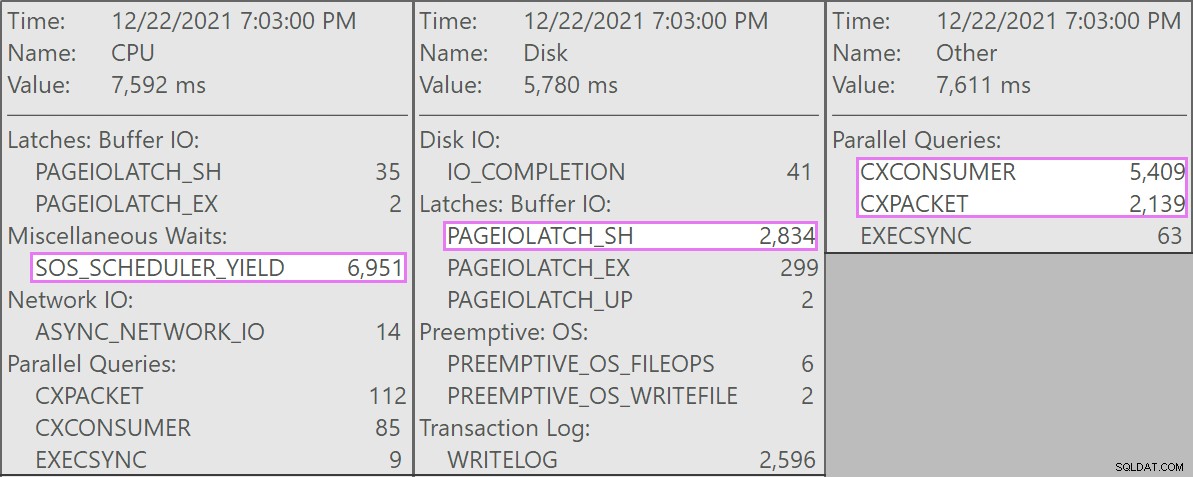
और यहां इन प्रश्नों से जुड़ी दिलचस्प प्रतीक्षाएं हैं:
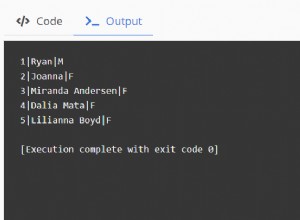
प्रतिस्पर्धा करने वाले सभी प्रश्न इस रूप में थे:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
योजना इस तरह दिखी:

और स्कैन पर चेतावनी ने हमें कुछ बहुत ही चरम अवशिष्ट I/O की सलाह दी:

तालिका में 1.9 बिलियन पंक्तियाँ हैं लेकिन केवल 32GB है (धन्यवाद, स्तंभ भंडारण!)। फिर भी, इन एकल-पंक्ति हटाने में प्रत्येक में 10-15 सेकंड का समय लगेगा, जिसमें से अधिकांश समय SOS_SCHEDULER_YIELD पर खर्च किया जाएगा। ।
शुक्र है, चूंकि इस परिदृश्य में डिलीट ऑपरेशन एसिंक्रोनस हो सकता है, हम दो बदलावों के साथ समस्या को हल करने में सक्षम थे (हालांकि मैं यहां बहुत अधिक सरलीकरण कर रहा हूं):
- हमने
MAXDOPको सीमित कर दिया है डेटाबेस स्तर पर इसलिए ये डिलीट इतने समानांतर नहीं जा सकते हैं - हमने एप्लिकेशन से आने वाली प्रक्रियाओं के क्रमांकन में सुधार किया है (मूल रूप से, हम एक डिस्पैचर के माध्यम से हटाए गए कतारबद्ध हैं)
DBA के रूप में, हम आसानी से MAXDOP . को नियंत्रित कर सकते हैं , जब तक कि इसे क्वेरी स्तर पर ओवरराइड न किया गया हो (एक और दिन के लिए एक और खरगोश छेद)। हम आवश्यक रूप से इस हद तक एप्लिकेशन को नियंत्रित नहीं कर सकते हैं, खासकर यदि यह वितरित है या हमारा नहीं है। हम इस मामले में एप्लिकेशन लॉजिक को बड़े पैमाने पर बदले बिना कैसे क्रमानुसार लिख सकते हैं?
एक नकली सेटअप
मैं स्थानीय रूप से दो अरब-पंक्ति तालिका बनाने की कोशिश नहीं करने जा रहा हूं - सटीक तालिका पर कोई फर्क नहीं पड़ता - लेकिन हम छोटे पैमाने पर कुछ अनुमान लगा सकते हैं और उसी मुद्दे को पुन:उत्पन्न करने का प्रयास कर सकते हैं।
आइए दिखाते हैं कि यह SuggestedEdits है तालिका (वास्तव में, यह नहीं है)। लेकिन इसका उपयोग करना एक आसान उदाहरण है क्योंकि हम स्कीमा को स्टैक एक्सचेंज डेटा एक्सप्लोरर से खींच सकते हैं। इसे आधार के रूप में उपयोग करते हुए, हम एक समान तालिका बना सकते हैं (कुछ मामूली परिवर्तनों के साथ इसे पॉप्युलेट करना आसान बनाने के लिए) और उस पर एक क्लस्टर्ड कॉलमस्टोर इंडेक्स फेंक सकते हैं:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
इसे 100 मिलियन पंक्तियों के साथ भरने के लिए, हम sys.all_objects . से जुड़ सकते हैं और sys.all_columns पांच बार (मेरे सिस्टम पर, यह हर बार 2.68 मिलियन पंक्तियों का उत्पादन करेगा, लेकिन YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
फिर, हम स्थान की जांच कर सकते हैं:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
यह केवल 1.3GB है, लेकिन यह पर्याप्त होना चाहिए:

हमारे क्लस्टर्ड Columnstore Delete की नकल करना
यहां एक साधारण क्वेरी दी गई है जो मोटे तौर पर हमारे एप्लिकेशन द्वारा तालिका में किए जा रहे कार्यों से मेल खाती है:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
हालांकि यह योजना बिल्कुल सही मेल नहीं है:
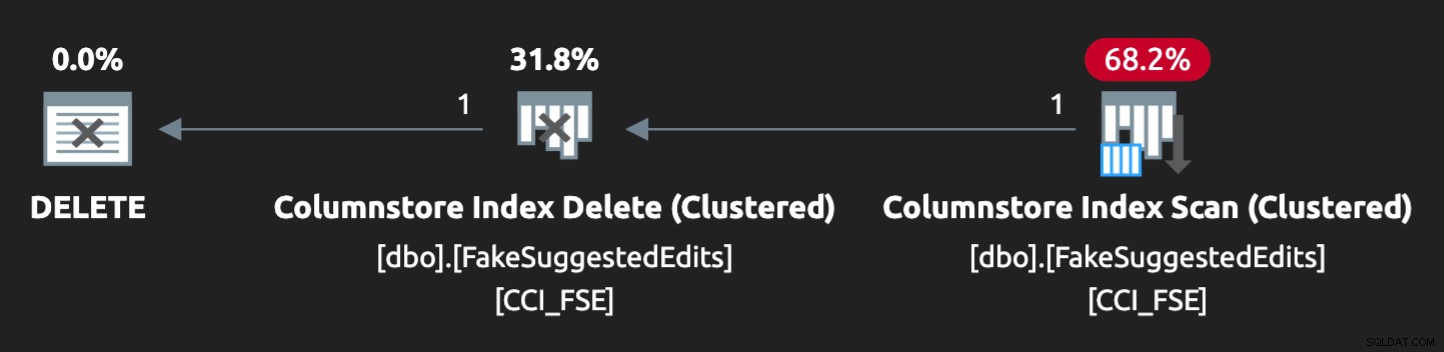
इसे समानांतर बनाने के लिए और अपने अल्प लैपटॉप पर समान विवाद उत्पन्न करने के लिए, मुझे इस संकेत के साथ अनुकूलक को थोड़ा मजबूर करना पड़ा:
OPTION (QUERYTRACEON 8649);
अब, यह सही लग रहा है:

समस्या का पुनरुत्पादन
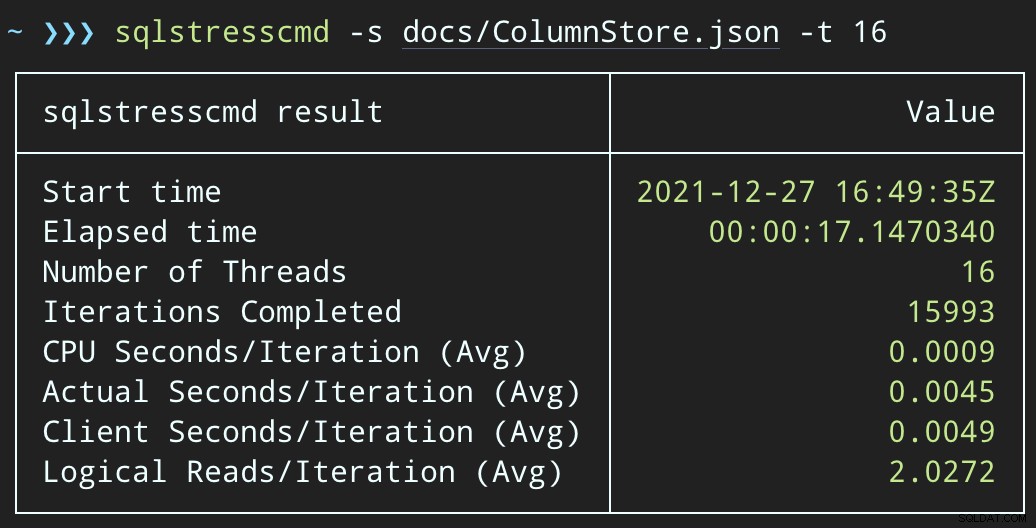
फिर, हम 16 और 32 थ्रेड्स का उपयोग करके 1,000 रैंडम पंक्तियों को हटाने के लिए SqlStressCmd का उपयोग करके समवर्ती डिलीट गतिविधि का एक उछाल बना सकते हैं:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
हम यह देख सकते हैं कि यह सीपीयू पर कितना दबाव डालता है:
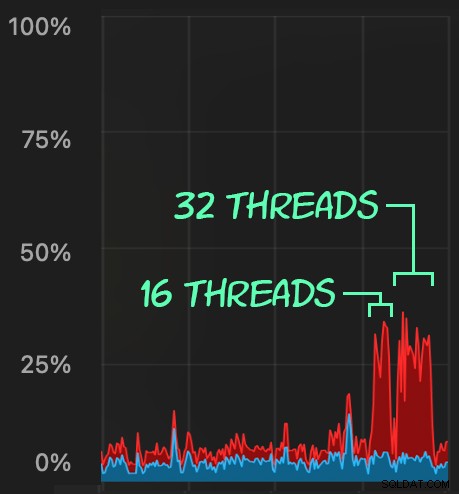
सीपीयू पर तनाव क्रमशः लगभग 64 और 130 सेकंड के पूरे बैच में रहता है:
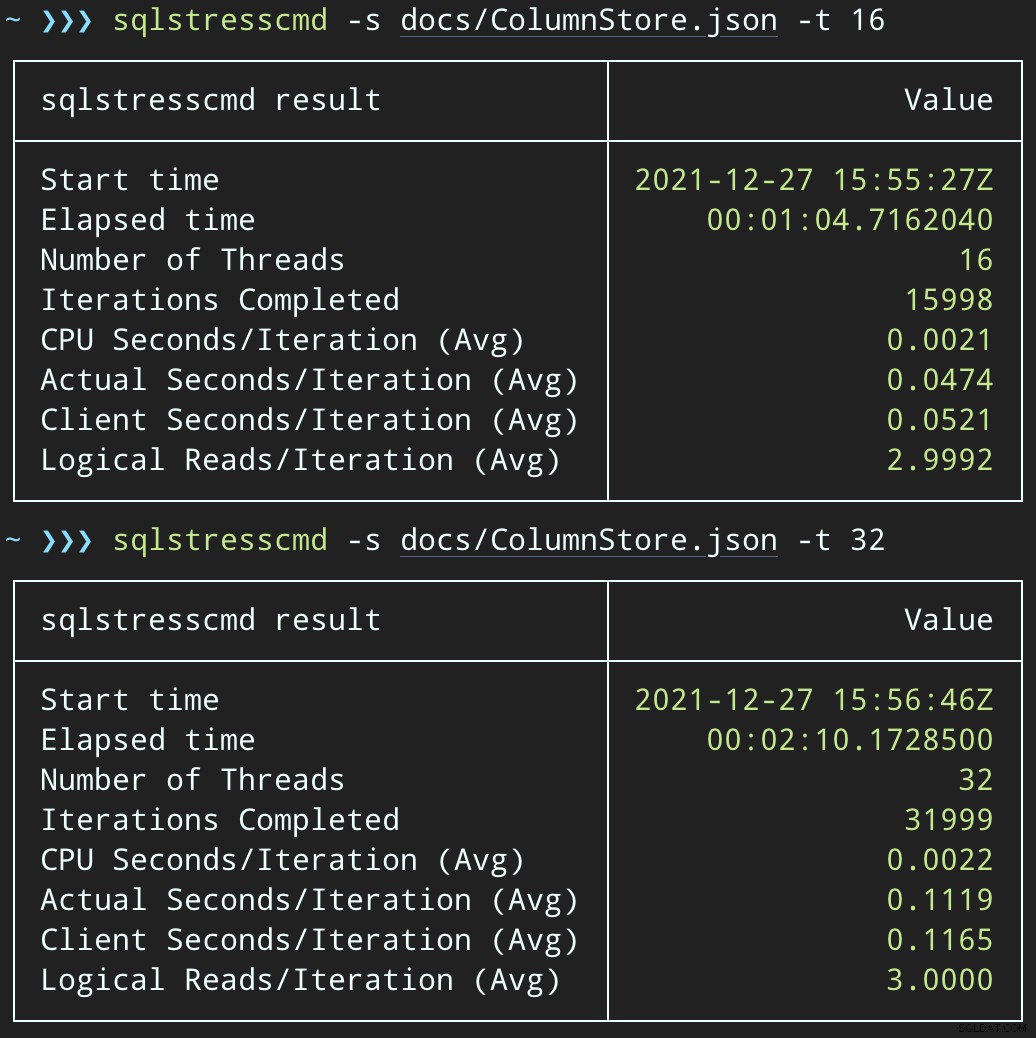
नोट:SQLQueryStress से आउटपुट कभी-कभी पुनरावृत्तियों पर थोड़ा कम होता है, लेकिन मैंने पुष्टि की है कि आप जिस काम को करने के लिए कहते हैं वह ठीक हो जाता है।
एक संभावित समाधान:एक हटाएं कतार
प्रारंभ में, मैंने डेटाबेस में एक कतार तालिका शुरू करने के बारे में सोचा, जिसका उपयोग हम गतिविधि को हटाने के लिए कर सकते हैं:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
एप्लिकेशन से आने वाले इन दुष्ट डिलीट को इंटरसेप्ट करने और बैकग्राउंड प्रोसेसिंग के लिए उन्हें कतार में रखने के लिए हमें केवल एक INSTEAD OF ट्रिगर की आवश्यकता होती है। दुर्भाग्य से, आप क्लस्टर्ड कॉलमस्टोर इंडेक्स वाली टेबल पर ट्रिगर नहीं बना सकते:
संदेश 35358, स्तर 16, राज्य 1तालिका 'dbo.FakeSuggestedEdits' पर TRIGGER बनाएं विफल रहा क्योंकि आप क्लस्टर्ड कॉलमस्टोर इंडेक्स वाली तालिका पर ट्रिगर नहीं बना सकते। ट्रिगर के तर्क को किसी अन्य तरीके से लागू करने पर विचार करें, या यदि आपको ट्रिगर का उपयोग करना है, तो इसके बजाय एक हीप या बी-ट्री इंडेक्स का उपयोग करें।
हमें एप्लिकेशन कोड में एक न्यूनतम परिवर्तन की आवश्यकता होगी, ताकि यह डिलीट को हैंडल करने के लिए एक संग्रहीत कार्यविधि को कॉल करे:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
यह स्थायी स्थिति नहीं है; यह ऐप में केवल एक चीज बदलते समय व्यवहार को वही रखने के लिए है। एक बार जब ऐप बदल जाता है और एड हॉक डिलीट क्वेरी सबमिट करने के बजाय इस संग्रहीत प्रक्रिया को सफलतापूर्वक कॉल कर रहा है, तो संग्रहीत प्रक्रिया बदल सकती है:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; ENDचुनें
कतार के प्रभाव का परीक्षण
अब, अगर हम इसके बजाय संग्रहीत कार्यविधि को कॉल करने के लिए SqlQueryStress बदलते हैं:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
और समान बैच सबमिट करें (16K या 32K पंक्तियों को कतार में रखते हुए):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
CPU प्रभाव थोड़ा अधिक है:
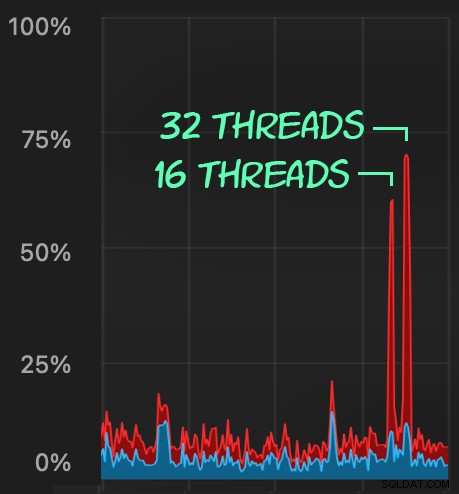
लेकिन कार्यभार अधिक तेज़ी से समाप्त होता है — क्रमशः 16 और 23 सेकंड:
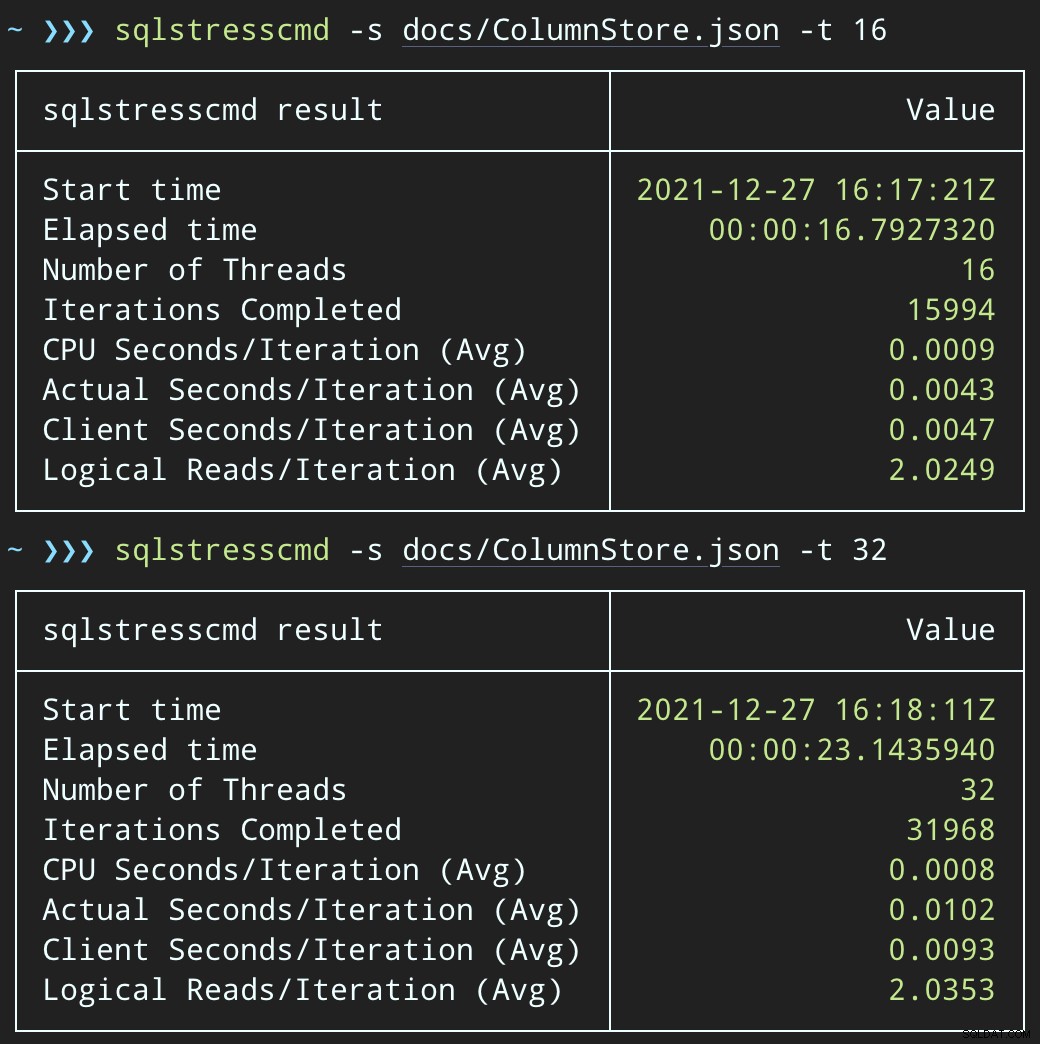
यह उस दर्द में एक महत्वपूर्ण कमी है जो अनुप्रयोगों को महसूस होगा क्योंकि वे उच्च समवर्ती अवधि में आते हैं।
हमें अभी भी हटाना है, हालांकि
हमें अभी भी उन डिलीट को बैकग्राउंड में प्रोसेस करना है, लेकिन अब हम बैचिंग शुरू कर सकते हैं और रेट पर पूरा नियंत्रण रख सकते हैं और किसी भी देरी को हम ऑपरेशंस के बीच इंजेक्ट करना चाहते हैं। कतार को संसाधित करने के लिए संग्रहीत प्रक्रिया की बहुत ही बुनियादी संरचना यहां दी गई है (बेशक पूरी तरह से निहित लेनदेन नियंत्रण, त्रुटि प्रबंधन, या कतार तालिका सफाई के बिना):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END अब, पंक्तियों को हटाने में अधिक समय लगेगा - 10,000 पंक्तियों के लिए औसत 223 सेकंड है, जिनमें से 100 जानबूझकर देरी है। लेकिन कोई उपयोगकर्ता प्रतीक्षा नहीं कर रहा है, तो कौन परवाह करता है? सीपीयू प्रोफाइल लगभग शून्य है, और ऐप कतार में आइटम जोड़ना जारी रख सकता है जैसा कि वह चाहता है, पृष्ठभूमि नौकरी के साथ लगभग शून्य संघर्ष के साथ। 10,000 पंक्तियों को संसाधित करते समय, मैंने कतार में एक और 16K पंक्तियाँ जोड़ीं, और यह पहले की तरह ही सीपीयू का उपयोग करता था - जब काम नहीं चल रहा था, तब से केवल एक सेकंड अधिक समय लगता है:
और योजना अब इस तरह दिखती है, बेहतर अनुमानित/वास्तविक पंक्तियों के साथ:
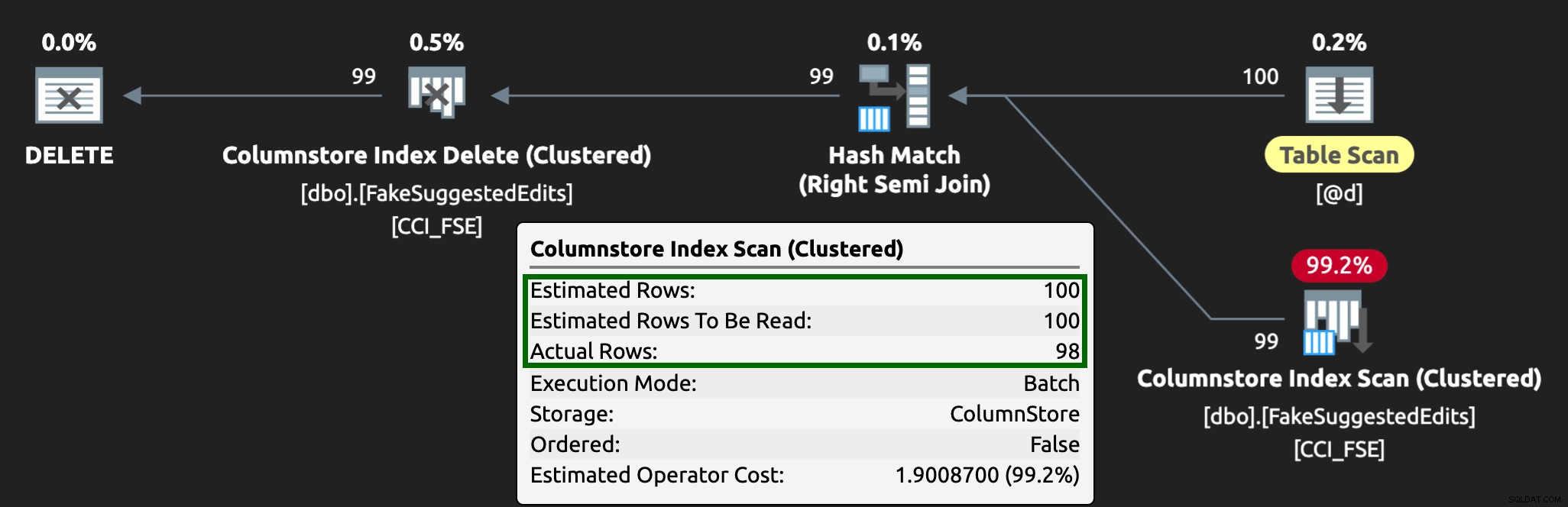
मैं इस कतार तालिका दृष्टिकोण को उच्च डीएमएल संगामिति से निपटने का एक प्रभावी तरीका देख सकता हूं, लेकिन इसके लिए डीएमएल जमा करने वाले अनुप्रयोगों के साथ कम से कम लचीलेपन की आवश्यकता होती है - यह एक कारण है कि मुझे वास्तव में अनुप्रयोगों को संग्रहीत प्रक्रियाओं को कॉल करना पसंद है, क्योंकि वे हमें डेटा के करीब और अधिक नियंत्रण प्रदान करें।
अन्य विकल्प
यदि आपके पास एप्लिकेशन से आने वाली डिलीट क्वेरी को बदलने की क्षमता नहीं है - या, यदि आप डिलीट को बैकग्राउंड प्रोसेस के लिए स्थगित नहीं कर सकते हैं - तो आप डिलीट के प्रभाव को कम करने के लिए अन्य विकल्पों पर विचार कर सकते हैं:
- बिंदु लुकअप का समर्थन करने के लिए विधेय स्तंभों पर एक गैर-संकुल सूचकांक (हम एप्लिकेशन को बदले बिना अलगाव में ऐसा कर सकते हैं)
- केवल सॉफ्ट डिलीट का उपयोग करना (अभी भी एप्लिकेशन में बदलाव की आवश्यकता है)
यह देखना दिलचस्प होगा कि क्या ये विकल्प समान लाभ प्रदान करते हैं, लेकिन मैं उन्हें भविष्य की पोस्ट के लिए सहेज कर रखूंगा।