मेरे मित्र पीटर लार्सन ने मुझे एक टी-एसक्यूएल चुनौती भेजी जिसमें मांग के साथ आपूर्ति का मिलान शामिल था। जहां तक चुनौतियों का सवाल है, तो यह बहुत बड़ी चुनौती है। वास्तविक जीवन में यह एक बहुत ही सामान्य आवश्यकता है; इसका वर्णन करना आसान है, और कर्सर-आधारित समाधान का उपयोग करके उचित प्रदर्शन के साथ इसे हल करना काफी आसान है। एक कुशल सेट-आधारित समाधान का उपयोग करके इसे हल करना मुश्किल हिस्सा है।
जब पीटर मुझे एक पहेली भेजता है, तो मैं आमतौर पर सुझाए गए समाधान के साथ प्रतिक्रिया करता हूं, और वह आमतौर पर बेहतर प्रदर्शन करने वाले, शानदार समाधान के साथ आता है। मुझे कभी-कभी संदेह होता है कि वह मुझे एक महान समाधान के साथ आने के लिए प्रेरित करने के लिए पहेलियाँ भेजता है।
चूंकि कार्य एक सामान्य आवश्यकता का प्रतिनिधित्व करता है और बहुत दिलचस्प है, मैंने पीटर से पूछा कि क्या वह बुरा मानेंगे यदि मैं इसे और उनके समाधान sqlperformance.com पाठकों के साथ साझा करता हूं, और वह मुझे जाने देने में प्रसन्न थे।
इस महीने, मैं चुनौती और क्लासिक कर्सर-आधारित समाधान प्रस्तुत करूंगा। बाद के लेखों में, मैं सेट-आधारित समाधान प्रस्तुत करूंगा—जिनमें पीटर और मैंने काम किया है।
चुनौती
चुनौती में नीलामी नामक तालिका को क्वेरी करना शामिल है, जिसे आप निम्नलिखित कोड का उपयोग करके बनाते हैं:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); इस तालिका में मांग और आपूर्ति प्रविष्टियां हैं। मांग प्रविष्टियों को कोड डी के साथ चिह्नित किया जाता है और एस के साथ आपूर्ति प्रविष्टियों को चिह्नित किया जाता है। आपका कार्य एक अस्थायी तालिका में परिणाम लिखकर आईडी ऑर्डरिंग के आधार पर आपूर्ति और मांग मात्रा का मिलान करना है। प्रविष्टियां क्रिप्टोकुरेंसी खरीदने और बेचने के आदेश जैसे बीटीसी/यूएसडी, स्टॉक खरीदने और बेचने के आदेश जैसे एमएसएफटी/यूएसडी, या कोई अन्य वस्तु या अच्छी जहां आपको मांग के साथ आपूर्ति से मेल खाने की आवश्यकता हो, का प्रतिनिधित्व कर सकती है। ध्यान दें कि नीलामी प्रविष्टियों में मूल्य विशेषता नहीं है। जैसा कि उल्लेख किया गया है, आपको आईडी ऑर्डरिंग के आधार पर आपूर्ति और मांग की मात्रा से मेल खाना चाहिए। यह आदेश कीमत (आपूर्ति प्रविष्टियों के लिए आरोही और मांग प्रविष्टियों के लिए अवरोही) या किसी अन्य प्रासंगिक मानदंड से प्राप्त किया जा सकता था। इस चुनौती में, विचार यह था कि चीजों को सरल रखा जाए और यह मान लिया जाए कि आईडी पहले से ही मिलान के लिए प्रासंगिक क्रम का प्रतिनिधित्व करता है।
उदाहरण के तौर पर, नीलामी तालिका को नमूना डेटा के एक छोटे से सेट से भरने के लिए निम्न कोड का उपयोग करें:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
आपको इस तरह आपूर्ति और मांग की मात्रा से मेल खाना चाहिए:
- मांग 1 और आपूर्ति 1000 के लिए 5.0 की मात्रा का मिलान किया जाता है, मांग 1 को कम करने और आपूर्ति 1000 के 3.0 को छोड़कर
- डिमांड 2 और सप्लाई 1000 के लिए 3.0 की मात्रा का मिलान किया जाता है, जिससे डिमांड 2 और सप्लाई 1000 दोनों कम हो जाते हैं
- डिमांड 3 और सप्लाई 2000 के लिए 6.0 की मात्रा का मिलान किया जाता है, डिमांड 3 के 2.0 को छोड़कर और सप्लाई 2000 को कम कर देता है
- डिमांड 3 और सप्लाई 3000 के लिए 2.0 की मात्रा का मिलान किया जाता है, जिससे डिमांड 3 और सप्लाई 3000 दोनों कम हो जाती हैं
- मांग 5 और आपूर्ति 4000 के लिए 2.0 की मात्रा का मिलान किया जाता है, जिससे मांग 5 और आपूर्ति 4000 दोनों कम हो जाती हैं
- डिमांड 6 और सप्लाई 5000 के लिए 4.0 की मात्रा का मिलान किया जाता है, डिमांड 6 के 4.0 को छोड़कर और सप्लाई 5000 को कम कर देता है
- डिमांड 6 और सप्लाई 6000 के लिए 3.0 की मात्रा का मिलान किया जाता है, डिमांड 6 के 1.0 को छोड़कर सप्लाई 6000 को कम किया जाता है
- मांग 6 और आपूर्ति 7000 के लिए 1.0 की मात्रा का मिलान किया जाता है, मांग 6 को कम करने और आपूर्ति 7000 के 1.0 को छोड़कर
- मांग 7 और आपूर्ति 7000 के लिए 1.0 की मात्रा का मिलान किया जाता है, मांग 7 के 3.0 को छोड़कर आपूर्ति 7000 को कम किया जाता है; मांग 8 किसी भी आपूर्ति प्रविष्टि से मेल नहीं खाती है और इसलिए पूरी मात्रा 2.0 के साथ छोड़ दी जाती है
आपका समाधान निम्न डेटा को परिणामी अस्थायी तालिका में लिखने वाला है:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
नमूना डेटा का बड़ा सेट
समाधानों के प्रदर्शन का परीक्षण करने के लिए, आपको नमूना डेटा के एक बड़े सेट की आवश्यकता होगी। इसमें मदद करने के लिए, आप GetNums फ़ंक्शन का उपयोग कर सकते हैं, जिसे आप निम्न कोड चलाकर बनाते हैं:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO यह फ़ंक्शन अनुरोधित श्रेणी में पूर्णांकों का एक क्रम देता है।
इस फ़ंक्शन के साथ, आप नमूना डेटा के साथ नीलामी तालिका को पॉप्युलेट करने के लिए पीटर द्वारा प्रदान किए गए निम्न कोड का उपयोग कर सकते हैं, आवश्यकतानुसार इनपुट को अनुकूलित कर सकते हैं:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; जैसा कि आप देख सकते हैं, आप खरीदारों और विक्रेताओं की संख्या के साथ-साथ न्यूनतम और अधिकतम खरीदार और विक्रेता मात्रा को अनुकूलित कर सकते हैं। उपरोक्त कोड 200,000 खरीदारों और 200,000 विक्रेताओं को निर्दिष्ट करता है, जिसके परिणामस्वरूप नीलामी तालिका में कुल 400,000 पंक्तियाँ होती हैं। अंतिम प्रश्न आपको बताता है कि तालिका में कितनी मांग (डी) और आपूर्ति (एस) प्रविष्टियां लिखी गईं। यह उपरोक्त इनपुट के लिए निम्न आउटपुट देता है:
Code Items ---- ----------- D 200000 S 200000
मैं उपरोक्त कोड का उपयोग करके विभिन्न समाधानों के प्रदर्शन का परीक्षण करने जा रहा हूं, खरीदारों और विक्रेताओं की संख्या को निम्नलिखित पर सेट कर रहा हूं:50,000, 100,000, 150,000, और 200,000। इसका मतलब है कि मुझे तालिका में पंक्तियों की कुल संख्या मिल जाएगी:100,000, 200,000, 300,000, और 400,000। बेशक, आप अपने समाधानों के प्रदर्शन का परीक्षण करने के लिए इनपुट को कस्टमाइज़ कर सकते हैं।
कर्सर-आधारित समाधान
पीटर ने कर्सर-आधारित समाधान प्रदान किया। यह बहुत ही बुनियादी है, जो इसके महत्वपूर्ण लाभों में से एक है। इसका उपयोग बेंचमार्क के रूप में किया जाएगा।
समाधान दो कर्सर का उपयोग करता है:एक आईडी द्वारा आदेशित मांग प्रविष्टियों के लिए और दूसरा आईडी द्वारा आदेशित आपूर्ति प्रविष्टियों के लिए। पूर्ण स्कैन और प्रति कर्सर एक प्रकार से बचने के लिए, निम्न अनुक्रमणिका बनाएं:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
यहाँ संपूर्ण समाधान का कोड है:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; जैसा कि आप देख सकते हैं, कोड एक अस्थायी तालिका बनाकर शुरू होता है। यह तब दो कर्सर घोषित करता है और प्रत्येक से एक पंक्ति प्राप्त करता है, वर्तमान मांग मात्रा को चर @DemandQuantity और वर्तमान आपूर्ति मात्रा को @SupplyQuantity पर लिखता है। यह तब तक प्रविष्टियों को एक लूप में संसाधित करता है जब तक कि अंतिम फ़ेच सफल नहीं हो जाता। कोड लूप के शरीर में निम्नलिखित तर्क लागू करता है:
यदि वर्तमान मांग मात्रा वर्तमान आपूर्ति मात्रा से कम या उसके बराबर है, तो कोड निम्न कार्य करता है:
- वर्तमान जोड़ी के साथ अस्थायी तालिका में एक पंक्ति लिखता है, मांग मात्रा (@DemandQuantity) के साथ मिलान मात्रा के रूप में
- वर्तमान मांग मात्रा को वर्तमान आपूर्ति मात्रा (@SupplyQuantity) से घटाता है
- अगली पंक्ति को डिमांड कर्सर से प्राप्त करता है
अन्यथा, कोड निम्न कार्य करता है:
- जाँचता है कि क्या वर्तमान आपूर्ति मात्रा शून्य से अधिक है, और यदि ऐसा है, तो यह निम्न कार्य करता है:
- वर्तमान जोड़ी के साथ, आपूर्ति मात्रा के साथ मिलान मात्रा के साथ अस्थायी तालिका में एक पंक्ति लिखता है
- वर्तमान आपूर्ति मात्रा को वर्तमान मांग मात्रा से घटाता है
- आपूर्ति कर्सर से अगली पंक्ति प्राप्त करता है
एक बार लूप हो जाने के बाद, मिलान करने के लिए और जोड़े नहीं हैं, इसलिए कोड केवल कर्सर संसाधनों को साफ़ करता है।
एक प्रदर्शन के दृष्टिकोण से, आपको कर्सर लाने और लूपिंग का विशिष्ट ओवरहेड मिलता है। फिर फिर, यह समाधान मांग डेटा पर एक एकल आदेशित पास और आपूर्ति डेटा पर एक एकल आदेशित पास करता है, प्रत्येक आपके द्वारा पहले बनाए गए इंडेक्स में खोज और रेंज स्कैन का उपयोग करता है। कर्सर प्रश्नों की योजना चित्र 1 में दिखाई गई है।

चित्र 1:कर्सर प्रश्नों के लिए योजनाएं
चूंकि योजना बिना किसी सॉर्टिंग के प्रत्येक भाग (मांग और आपूर्ति) की तलाश और ऑर्डर की गई रेंज स्कैन करती है, इसमें रैखिक स्केलिंग है। इसका परीक्षण करते समय मुझे जो प्रदर्शन संख्याएँ मिलीं, उनसे इसकी पुष्टि हुई, जैसा कि चित्र 2 में दिखाया गया है।
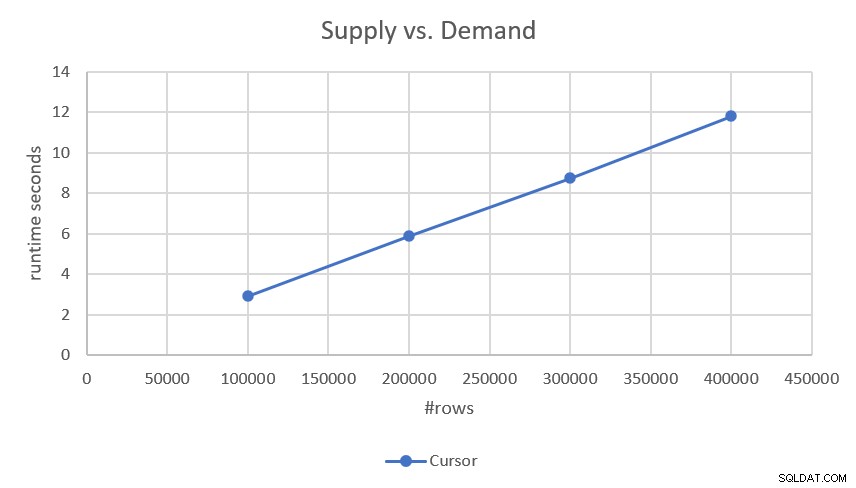
चित्र 2:कर्सर-आधारित समाधान का प्रदर्शन
यदि आप अधिक सटीक रन टाइम में रुचि रखते हैं, तो वे यहां हैं:
- 100,000 पंक्तियां (50,000 मांगें और 50,000 आपूर्ति):2.93 सेकंड
- 200,000 पंक्तियाँ:5.89 सेकंड
- 300,000 पंक्तियाँ:8.75 सेकंड
- 400,000 पंक्तियाँ:11.81 सेकंड
यह देखते हुए कि समाधान में रैखिक स्केलिंग है, आप आसानी से अन्य पैमानों के साथ रन टाइम का अनुमान लगा सकते हैं। उदाहरण के लिए, एक लाख पंक्तियों (जैसे, 500,000 माँग और 500,000 आपूर्ति) के साथ इसे चलाने में लगभग 29.5 सेकंड का समय लगना चाहिए।
चुनौती चालू है
कर्सर-आधारित समाधान में रैखिक स्केलिंग है और, जैसे, यह बुरा नहीं है। लेकिन यह सामान्य कर्सर लाने और ओवरहेड लूपिंग करता है। जाहिर है, आप सीएलआर-आधारित समाधान का उपयोग करके समान एल्गोरिदम को लागू करके इस ओवरहेड को कम कर सकते हैं। सवाल यह है कि क्या आप इस कार्य के लिए एक अच्छा प्रदर्शन करने वाले सेट-आधारित समाधान के साथ आ सकते हैं?
जैसा कि उल्लेख किया गया है, मैं अगले महीने से सेट-आधारित समाधानों का पता लगाऊंगा- दोनों खराब प्रदर्शन और अच्छा प्रदर्शन करने वाले। इस बीच, यदि आप चुनौती के लिए तैयार हैं, तो देखें कि क्या आप अपने स्वयं के सेट-आधारित समाधान के साथ आ सकते हैं।
अपने समाधान की शुद्धता को सत्यापित करने के लिए, पहले इसके परिणाम की तुलना नमूना डेटा के छोटे सेट के लिए यहां दिखाए गए परिणाम से करें। आप कर्सर समाधान के परिणाम के बीच सममित अंतर को सत्यापित करके नमूना डेटा के एक बड़े सेट के साथ अपने समाधान के परिणाम की वैधता की जांच भी कर सकते हैं और आपका समाधान खाली है। यह मानते हुए कि कर्सर का परिणाम #PairingsCursor नामक एक अस्थायी तालिका में संग्रहीत है और आपका #MyPairings नामक एक अस्थायी तालिका में, आप इसे प्राप्त करने के लिए निम्न कोड का उपयोग कर सकते हैं:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
परिणाम खाली होना चाहिए।
शुभकामनाएँ!
[समाधान पर जाएं:भाग 1 | भाग 2 | भाग 3 ]