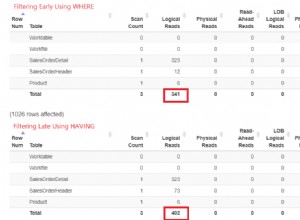
यह आलेख नामित तालिका अभिव्यक्तियों के बारे में श्रृंखला का 7वां भाग है। भाग 5 और भाग 6 में मैंने सामान्य तालिका अभिव्यक्तियों (सीटीई) के वैचारिक पहलुओं को शामिल किया। इस महीने और अगले महीने मेरा ध्यान सीटीई के अनुकूलन विचारों की ओर जाता है।
मैं नामित टेबल एक्सप्रेशन की अननेस्टिंग अवधारणा को जल्दी से फिर से शुरू करके शुरू करूंगा और सीटीई के लिए इसकी प्रयोज्यता प्रदर्शित करूंगा। फिर मैं अपना ध्यान दृढ़ता के विचारों पर लगाऊंगा। मैं पुनरावर्ती और गैर-पुनरावर्ती सीटीई के दृढ़ता पहलुओं के बारे में बात करूंगा। जब यह वास्तव में अस्थायी तालिकाओं के साथ काम करने के लिए अधिक समझ में आता है, तो मैं समझाता हूं कि सीटीई के साथ रहना कब समझ में आता है।
अपने उदाहरणों में मैं नमूना डेटाबेस TSQLV5 और PerformanceV5 का उपयोग करना जारी रखूंगा। आप यहां TSQLV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट और इसके ईआर आरेख यहां पा सकते हैं। आप यहां परफॉरमेंसV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट पा सकते हैं।
प्रतिस्थापन/अननेस्टिंग
श्रृंखला के भाग 4 में, जो व्युत्पन्न तालिकाओं के अनुकूलन पर केंद्रित है, मैंने तालिका अभिव्यक्तियों को हटाने/प्रतिस्थापन की एक प्रक्रिया का वर्णन किया है। मैंने समझाया कि जब SQL सर्वर व्युत्पन्न तालिकाओं से जुड़ी एक क्वेरी को अनुकूलित करता है, तो यह पार्सर द्वारा उत्पादित लॉजिकल ऑपरेटरों के प्रारंभिक पेड़ पर परिवर्तन नियम लागू करता है, संभवतः मूल रूप से तालिका अभिव्यक्ति सीमाओं के आसपास चीजों को स्थानांतरित कर देता है। यह इस हद तक होता है कि जब आप व्युत्पन्न तालिकाओं का उपयोग करके किसी क्वेरी के लिए एक योजना की तुलना किसी क्वेरी के लिए एक योजना के साथ करते हैं जो सीधे अंतर्निहित आधार तालिकाओं के विरुद्ध जाती है, जहां आपने स्वयं अननेस्टिंग तर्क लागू किया है, तो वे समान दिखते हैं। मैंने इनपुट के रूप में बहुत बड़ी संख्या में पंक्तियों के साथ TOP फ़िल्टर का उपयोग करके अननेस्टिंग को रोकने के लिए एक तकनीक का भी वर्णन किया। मैंने कुछ मामलों का प्रदर्शन किया जहां यह तकनीक काफी उपयोगी थी—एक जहां लक्ष्य त्रुटियों से बचना था और दूसरा अनुकूलन कारणों से।
सीटीई के प्रतिस्थापन/अननेस्टिंग का टीएल; डीआर संस्करण यह है कि प्रक्रिया वैसी ही है जैसी यह व्युत्पन्न तालिकाओं के साथ है। अगर आप इस कथन से खुश हैं, तो आप बेझिझक इस सेक्शन को छोड़ सकते हैं और पर्सिस्टेंसी के बारे में सीधे अगले सेक्शन पर जा सकते हैं। आपने कुछ भी महत्वपूर्ण नहीं छोड़ा जो आपने पहले नहीं पढ़ा है। हालाँकि, यदि आप मेरे जैसे हैं, तो आप शायद इस बात का प्रमाण चाहते हैं कि वास्तव में ऐसा ही है। फिर, आप शायद इस खंड को पढ़ना जारी रखना चाहेंगे और मेरे द्वारा उपयोग किए जाने वाले कोड का परीक्षण करना चाहेंगे क्योंकि मैं उन प्रमुख अननेस्टिंग उदाहरणों पर दोबारा गौर करता हूं जिन्हें मैंने पहले व्युत्पन्न तालिकाओं के साथ प्रदर्शित किया था और उन्हें सीटीई का उपयोग करने के लिए परिवर्तित किया था।
भाग 4 में मैंने निम्नलिखित प्रश्न का प्रदर्शन किया (हम इसे प्रश्न 1 कहेंगे):
USE TSQLV5;
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; क्वेरी में व्युत्पन्न तालिकाओं के तीन नेस्टिंग स्तर, साथ ही एक बाहरी क्वेरी शामिल है। प्रत्येक स्तर आदेश तिथियों की एक अलग श्रेणी को फ़िल्टर करता है। प्रश्न 1 की योजना चित्र 1 में दिखाई गई है।
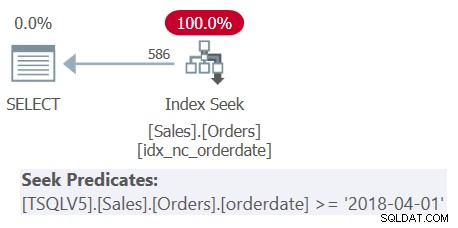 चित्र 1:क्वेरी 1 के लिए निष्पादन योजना
चित्र 1:क्वेरी 1 के लिए निष्पादन योजना
चित्र 1 में योजना स्पष्ट रूप से दिखाती है कि व्युत्पन्न तालिकाओं का अननेस्टिंग हुआ क्योंकि सभी फ़िल्टर विधेय करते हैं जहां एक एकल समावेशी फ़िल्टर विधेय में विलय हो जाता है।
मैंने समझाया कि आप इनपुट के रूप में बहुत बड़ी संख्या में पंक्तियों के साथ एक सार्थक TOP फ़िल्टर (जैसा कि TOP 100 PERCENT के विपरीत) का उपयोग करके अननेस्टिंग प्रक्रिया को रोक सकते हैं, जैसा कि निम्नलिखित क्वेरी से पता चलता है (हम इसे क्वेरी 2 कहेंगे):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; प्रश्न 2 की योजना चित्र 2 में दिखाई गई है।
 चित्र 2:क्वेरी 2 के लिए निष्पादन योजना
चित्र 2:क्वेरी 2 के लिए निष्पादन योजना
यह योजना स्पष्ट रूप से दिखाती है कि नेस्टिंग नहीं हुई क्योंकि आप व्युत्पन्न तालिका सीमाओं को प्रभावी ढंग से देख सकते हैं।
आइए सीटीई का उपयोग करके उन्हीं उदाहरणों को आजमाएं। यहाँ क्वेरी 1 को CTE का उपयोग करने के लिए रूपांतरित किया गया है:
WITH C1 AS
(
SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; आपको ठीक वही योजना मिलती है जो पहले चित्र 1 में दिखाई गई थी, जहां आप देख सकते हैं कि घोंसला बनाना हुआ था।
यहाँ क्वेरी 2 को CTE का उपयोग करने के लिए रूपांतरित किया गया है:
WITH C1 AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT TOP (9223372036854775807) *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT TOP (9223372036854775807) *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; आपको वही योजना मिलती है जो पहले चित्र 2 में दिखाई गई थी, जहाँ आप देख सकते हैं कि घोंसला नहीं बनाया गया था।
इसके बाद, आइए उन दो उदाहरणों पर फिर से गौर करें जिनका उपयोग मैंने इस तकनीक की व्यावहारिकता को प्रदर्शित करने के लिए किया था, ताकि केवल इस बार सीटीई का उपयोग किया जा सके।
आइए गलत क्वेरी से शुरू करें। निम्न क्वेरी न्यूनतम छूट से अधिक छूट के साथ ऑर्डर लाइन वापस करने का प्रयास करती है, और जहां छूट का पारस्परिक 10 से अधिक है:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
न्यूनतम छूट ऋणात्मक नहीं हो सकती, बल्कि शून्य या अधिक हो सकती है। तो, आप शायद सोच रहे हैं कि यदि किसी पंक्ति में शून्य छूट है, तो पहले विधेय को असत्य का मूल्यांकन करना चाहिए, और शॉर्ट सर्किट को दूसरे विधेय का मूल्यांकन करने के प्रयास को रोकना चाहिए, इस प्रकार त्रुटि से बचना चाहिए। हालांकि, जब आप इस कोड को चलाते हैं तो आपको शून्य त्रुटि से भाग मिलता है:
Msg 8134, Level 16, State 1, Line 99 Divide by zero error encountered.
मुद्दा यह है कि भले ही SQL सर्वर भौतिक प्रसंस्करण स्तर पर शॉर्ट सर्किट अवधारणा का समर्थन करता है, लेकिन इस बात का कोई आश्वासन नहीं है कि यह फ़िल्टर का मूल्यांकन बाएं से दाएं लिखित क्रम में करेगा। ऐसी त्रुटियों से बचने का एक सामान्य प्रयास एक नामित तालिका अभिव्यक्ति का उपयोग करना है जो फ़िल्टरिंग तर्क के उस हिस्से को संभालता है जिसका आप पहले मूल्यांकन करना चाहते हैं, और बाहरी क्वेरी फ़िल्टरिंग तर्क को संभालती है जिसका आप दूसरे मूल्यांकन करना चाहते हैं। सीटीई का उपयोग करके हल करने का प्रयास यहां दिया गया है:
WITH C AS
(
SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; दुर्भाग्य से, हालांकि, टेबल एक्सप्रेशन के अननेस्टिंग का परिणाम मूल समाधान क्वेरी के तार्किक समकक्ष में होता है, और जब आप इस कोड को चलाने का प्रयास करते हैं तो आपको फिर से शून्य त्रुटि से विभाजित मिलता है:
Msg 8134, Level 16, State 1, Line 108 Divide by zero error encountered.
आंतरिक क्वेरी में TOP फ़िल्टर के साथ हमारी ट्रिक का उपयोग करते हुए, आप टेबल एक्सप्रेशन को अननेस्टिंग होने से रोकते हैं, जैसे:
WITH C AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; इस बार कोड बिना किसी त्रुटि के सफलतापूर्वक चलता है।
आइए उस उदाहरण पर आगे बढ़ते हैं जहां आप अनुकूलन कारणों से अननेस्टिंग को रोकने के लिए तकनीक का उपयोग करते हैं। निम्नलिखित कोड केवल 1 जनवरी, 2018 को या उसके बाद की अधिकतम ऑर्डर तिथि वाले शिपर्स लौटाता है:
USE PerformanceV5;
WITH C AS
(
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
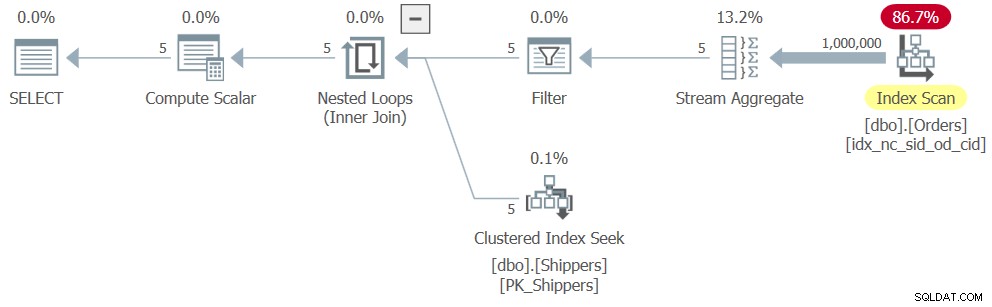
WHERE maxod >= '20180101'; यदि आप सोच रहे हैं कि समूहीकृत क्वेरी और HAVING फ़िल्टर के साथ अधिक सरल समाधान का उपयोग क्यों नहीं किया जाता है, तो इसका संबंध शिपरिड कॉलम के घनत्व से है। ऑर्डर टेबल में 1,000,000 ऑर्डर हैं, और उन ऑर्डर के शिपमेंट को पांच शिपर्स द्वारा नियंत्रित किया गया था, जिसका अर्थ है कि औसतन, प्रत्येक शिपर ने ऑर्डर का 20% संभाला। प्रति शिपर अधिकतम ऑर्डर तिथि की गणना करने वाली समूहबद्ध क्वेरी की योजना सभी 1,000,000 पंक्तियों को स्कैन करेगी, जिसके परिणामस्वरूप हजारों पृष्ठ पढ़े जाएंगे। वास्तव में, यदि आप केवल सीटीई की आंतरिक क्वेरी को हाइलाइट करते हैं (हम इसे क्वेरी 3 कहते हैं) प्रति शिपर अधिकतम ऑर्डर तिथि की गणना करते हैं और इसकी निष्पादन योजना की जांच करते हैं, तो आपको चित्र 3 में दिखाया गया प्लान मिलेगा।
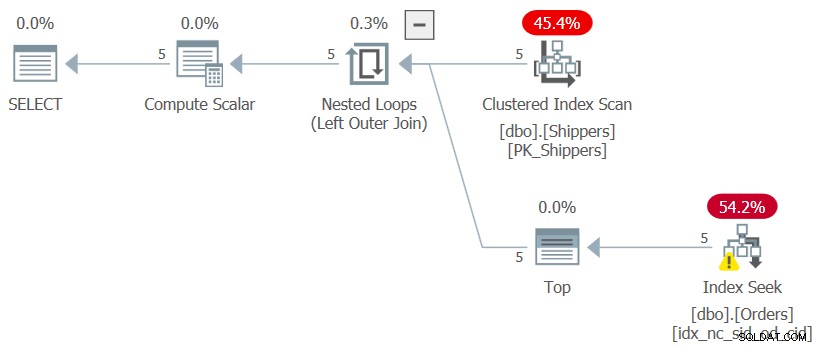 चित्र 3:क्वेरी 3 के लिए निष्पादन योजना
चित्र 3:क्वेरी 3 के लिए निष्पादन योजना
योजना शिपर्स पर क्लस्टर्ड इंडेक्स में पांच पंक्तियों को स्कैन करती है। प्रति शिपर, योजना ऑर्डर पर एक कवरिंग इंडेक्स के खिलाफ एक खोज को लागू करती है, जहां (शिपरिड, ऑर्डरडेट) इंडेक्स की प्रमुख कुंजी हैं, वर्तमान के लिए अधिकतम ऑर्डर तिथि खींचने के लिए लीफ स्तर पर प्रत्येक शिपर सेक्शन में सीधे अंतिम पंक्ति में जा रहे हैं। शिपर चूंकि हमारे पास केवल पांच शिपर्स हैं, इसलिए केवल पांच इंडेक्स सीक ऑपरेशंस हैं, जिसके परिणामस्वरूप एक बहुत ही कुशल योजना है। सीटीई की आंतरिक क्वेरी को निष्पादित करने पर मुझे जो प्रदर्शन उपाय मिले, वे यहां दिए गए हैं:
duration: 0 ms, CPU: 0 ms, reads: 15
हालांकि, जब आप पूरा समाधान चलाते हैं (हम इसे क्वेरी 4 कहेंगे), तो आपको एक पूरी तरह से अलग योजना मिलती है, जैसा कि चित्र 4 में दिखाया गया है।
 चित्र 4:क्वेरी 4 के लिए निष्पादन योजना
चित्र 4:क्वेरी 4 के लिए निष्पादन योजना
क्या हुआ कि SQL सर्वर ने टेबल एक्सप्रेशन को अननेस्टेड किया, समाधान को समूहीकृत क्वेरी के तार्किक समकक्ष में परिवर्तित किया, जिसके परिणामस्वरूप ऑर्डर पर इंडेक्स का पूर्ण स्कैन हुआ। यहाँ प्रदर्शन संख्याएँ हैं जो मुझे इस समाधान के लिए मिली हैं:
duration: 316 ms, CPU: 281 ms, reads: 3854
टेबल एक्सप्रेशन को होने से रोकने के लिए हमें यहां क्या चाहिए, ताकि आंतरिक क्वेरी को ऑर्डर पर इंडेक्स के खिलाफ खोज के साथ अनुकूलित किया जा सके, और बाहरी क्वेरी के परिणामस्वरूप केवल एक फ़िल्टर ऑपरेटर को जोड़ा जा सके। योजना। आप आंतरिक क्वेरी में एक TOP फ़िल्टर जोड़कर हमारी ट्रिक का उपयोग करके इसे प्राप्त करते हैं, जैसे (हम इस समाधान को प्रश्न 5 कहेंगे):
WITH C AS
(
SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; इस समाधान की योजना चित्र 5 में दिखाई गई है।
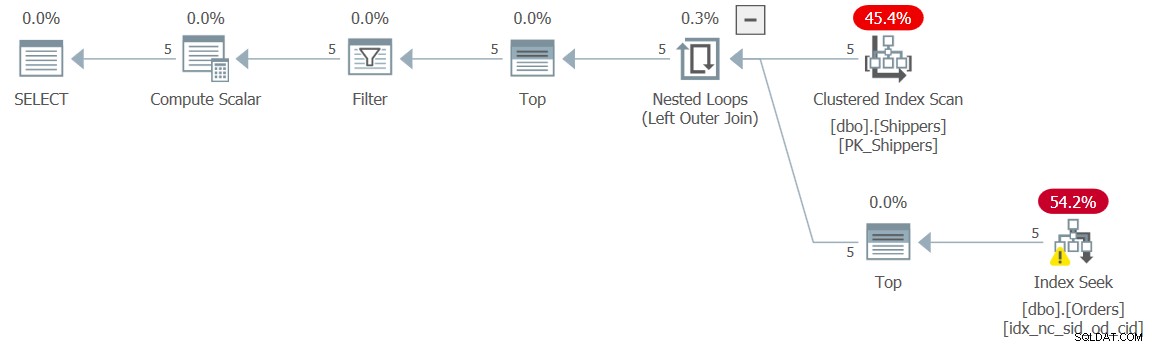 चित्र 5:प्रश्न 5 के लिए निष्पादन योजना
चित्र 5:प्रश्न 5 के लिए निष्पादन योजना
योजना से पता चलता है कि वांछित प्रभाव प्राप्त किया गया था, और तदनुसार प्रदर्शन संख्याएं इसकी पुष्टि करती हैं:
duration: 0 ms, CPU: 0 ms, reads: 15
तो, हमारा परीक्षण पुष्टि करता है कि SQL सर्वर सीटीई के प्रतिस्थापन/अननेस्टिंग को उसी तरह से संभालता है जैसे यह व्युत्पन्न तालिकाओं के लिए करता है। इसका मतलब यह है कि आपको अनुकूलन कारणों से एक दूसरे को पसंद नहीं करना चाहिए, बल्कि वैचारिक मतभेदों के कारण जो आपके लिए महत्वपूर्ण हैं, जैसा कि भाग 5 में चर्चा की गई है।
दृढ़ता
सीटीई और सामान्य रूप से नामित टेबल एक्सप्रेशन से संबंधित एक आम गलत धारणा यह है कि वे किसी प्रकार के दृढ़ता वाहन के रूप में कार्य करते हैं। कुछ लोग सोचते हैं कि SQL सर्वर आंतरिक क्वेरी के परिणाम सेट को कार्य तालिका में बनाए रखता है, और बाहरी क्वेरी वास्तव में उस कार्य तालिका के साथ इंटरैक्ट करती है। व्यवहार में, नियमित गैर-पुनरावर्ती CTE और व्युत्पन्न तालिकाएँ कायम नहीं रहती हैं। मैंने अननेस्टिंग लॉजिक का वर्णन किया है कि SQL सर्वर टेबल एक्सप्रेशन से जुड़ी क्वेरी को ऑप्टिमाइज़ करते समय लागू होता है, जिसके परिणामस्वरूप एक ऐसी योजना होती है जो सीधे अंतर्निहित बेस टेबल के साथ इंटरैक्ट करती है। ध्यान दें कि ऑप्टिमाइज़र इंटरमीडिएट परिणाम सेट को जारी रखने के लिए कार्य तालिकाओं का उपयोग करना चुन सकता है यदि ऐसा करने के लिए या तो प्रदर्शन कारणों से, या अन्य, जैसे हैलोवीन सुरक्षा के लिए ऐसा करना समझ में आता है। जब ऐसा होता है, तो आप योजना में स्पूल या इंडेक्स स्पूल ऑपरेटरों को देखते हैं। हालांकि, ऐसे विकल्प क्वेरी में टेबल एक्सप्रेशन के उपयोग से संबंधित नहीं हैं।
पुनरावर्ती सीटीई
कुछ अपवाद हैं जिनमें SQL सर्वर तालिका अभिव्यक्ति के डेटा को कायम रखता है। एक अनुक्रमित विचारों का उपयोग है। यदि आप किसी दृश्य पर संकुल अनुक्रमणिका बनाते हैं, तो SQL सर्वर दृश्य के संकुल अनुक्रमणिका में सेट आंतरिक क्वेरी के परिणाम को बनाए रखता है, और इसे अंतर्निहित आधार तालिकाओं में किसी भी परिवर्तन के साथ समन्वयित रखता है। दूसरा अपवाद तब होता है जब आप पुनरावर्ती प्रश्नों का उपयोग करते हैं। SQL सर्वर को एंकर के मध्यवर्ती परिणाम सेट और स्पूल में पुनरावर्ती प्रश्नों को जारी रखने की आवश्यकता होती है ताकि यह हर बार पुनरावर्ती सदस्य के निष्पादित होने पर सीटीई नाम के पुनरावर्ती संदर्भ द्वारा दर्शाए गए अंतिम दौर के परिणाम सेट तक पहुंच सके।
इसे प्रदर्शित करने के लिए मैं श्रृंखला के भाग 6 में से एक पुनरावर्ती क्वेरी का उपयोग करूँगा।
Tempdb डेटाबेस में कर्मचारी तालिका बनाने के लिए निम्न कोड का उपयोग करें, इसे नमूना डेटा से भरें, और एक सहायक अनुक्रमणिका बनाएं:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
GO मैंने इस उदाहरण में इनपुट मैनेजर के रूप में कर्मचारी 3 का उपयोग करते हुए, एक इनपुट सबट्री रूट मैनेजर के सभी अधीनस्थों को वापस करने के लिए निम्नलिखित पुनरावर्ती CTE का उपयोग किया:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; इस क्वेरी की योजना (हम इसे प्रश्न 6 कहेंगे) चित्र 6 में दिखाई गई है।
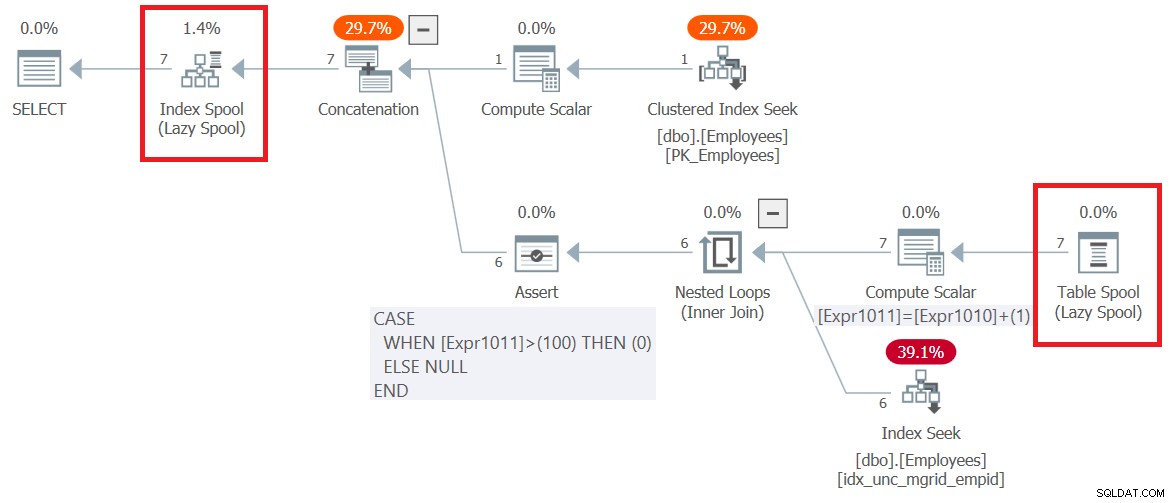 चित्र 6:क्वेरी 6 के लिए निष्पादन योजना
चित्र 6:क्वेरी 6 के लिए निष्पादन योजना
ध्यान दें कि योजना में सबसे पहली चीज जो रूट सेलेक्ट नोड के दाईं ओर होती है, वह है इंडेक्स स्पूल ऑपरेटर द्वारा प्रस्तुत बी-ट्री-आधारित कार्य तालिका का निर्माण। योजना का शीर्ष भाग एंकर सदस्य के तर्क को संभालता है। यह कर्मचारियों पर क्लस्टर इंडेक्स से इनपुट कर्मचारी पंक्ति को खींचता है और इसे स्पूल को लिखता है। योजना का निचला भाग पुनरावर्ती सदस्य के तर्क का प्रतिनिधित्व करता है। इसे बार-बार निष्पादित किया जाता है जब तक कि यह एक खाली परिणाम सेट नहीं लौटाता। नेस्टेड लूप्स ऑपरेटर के लिए बाहरी इनपुट स्पूल (टेबल स्पूल ऑपरेटर) से पिछले दौर के प्रबंधकों को प्राप्त करता है। आंतरिक इनपुट पिछले दौर से प्रबंधकों के प्रत्यक्ष अधीनस्थों को प्राप्त करने के लिए कर्मचारियों (mgrid, empid) पर बनाए गए एक गैर-संकुल सूचकांक के खिलाफ एक इंडेक्स सीक ऑपरेटर का उपयोग करता है। योजना के निचले हिस्से के प्रत्येक निष्पादन का परिणाम सेट इंडेक्स स्पूल को भी लिखा जाता है। ध्यान दें कि कुल मिलाकर, 7 पंक्तियाँ स्पूल को लिखी गई थीं। एक एंकर सदस्य द्वारा लौटाया गया, और 6 अन्य पुनरावर्ती सदस्य के सभी निष्पादनों द्वारा लौटाए गए।
एक तरफ, यह देखना दिलचस्प है कि योजना डिफ़ॉल्ट अधिकतम रिकर्सन सीमा को कैसे संभालती है, जो कि 100 है। ध्यान दें कि निचला कंप्यूट स्केलर ऑपरेटर रिकर्सिव सदस्य के प्रत्येक निष्पादन के साथ एक्सप्र 1011 नामक एक आंतरिक काउंटर को 1 से बढ़ाता रहता है। फिर, यदि यह काउंटर 100 से अधिक है तो Assert ऑपरेटर एक ध्वज को शून्य पर सेट करता है। यदि ऐसा होता है तो SQL सर्वर क्वेरी के निष्पादन को रोक देता है और एक त्रुटि उत्पन्न करता है।
कब नहीं रहना है
गैर-पुनरावर्ती सीटीई पर वापस जाएं, जो आम तौर पर कायम नहीं रहते हैं, यह आप पर है कि आप अनुकूलन के नजरिए से यह पता लगाएं कि अस्थायी तालिकाओं और तालिका चर जैसे वास्तविक दृढ़ता उपकरण बनाम उनका उपयोग करना एक अच्छी बात है। प्रत्येक दृष्टिकोण अधिक इष्टतम होने पर प्रदर्शित करने के लिए मैं कुछ उदाहरणों पर जाऊँगा।
आइए एक उदाहरण से शुरू करें जहां सीटीई अस्थायी तालिकाओं से बेहतर करते हैं। अक्सर ऐसा होता है जब आपके पास एक ही सीटीई के कई मूल्यांकन नहीं होते हैं, बल्कि, शायद केवल एक मॉड्यूलर समाधान जहां प्रत्येक सीटीई का मूल्यांकन केवल एक बार किया जाता है। निम्नलिखित कोड (हम इसे क्वेरी 7 कहेंगे) प्रदर्शन डेटाबेस में ऑर्डर तालिका पर सवाल उठाता है, जिसमें 1,000,000 पंक्तियाँ होती हैं, ताकि ऑर्डर के वर्षों को वापस किया जा सके जिसमें 70 से अधिक अलग-अलग ग्राहकों ने ऑर्डर दिए:
USE PerformanceV5;
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM dbo.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70; यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
मैंने SQL सर्वर 2019 डेवलपर संस्करण का उपयोग करके इस कोड को चलाया, और चित्र 7 में दिखाया गया प्लान मिला।
 चित्र 7:क्वेरी 7 के लिए निष्पादन योजना
चित्र 7:क्वेरी 7 के लिए निष्पादन योजना
ध्यान दें कि CTE के अननेस्टिंग के परिणामस्वरूप एक ऐसी योजना तैयार हुई है जो ऑर्डर टेबल पर एक इंडेक्स से डेटा खींचती है, और इसमें CTE के आंतरिक क्वेरी परिणाम सेट की कोई स्पूलिंग शामिल नहीं है। मेरी मशीन पर इस क्वेरी को निष्पादित करते समय मुझे निम्नलिखित प्रदर्शन संख्याएँ मिलीं:
duration: 265 ms, CPU: 828 ms, reads: 3970, writes: 0
अब एक ऐसे समाधान की कोशिश करते हैं जो सीटीई के बजाय अस्थायी तालिकाओं का उपयोग करता है (हम इसे समाधान 8 कहेंगे), जैसे:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; SELECT orderyear, numcusts FROM #T2 WHERE numcusts > 70; DROP TABLE #T1, #T2;
इस समाधान की योजनाएँ चित्र 8 में दिखाई गई हैं।
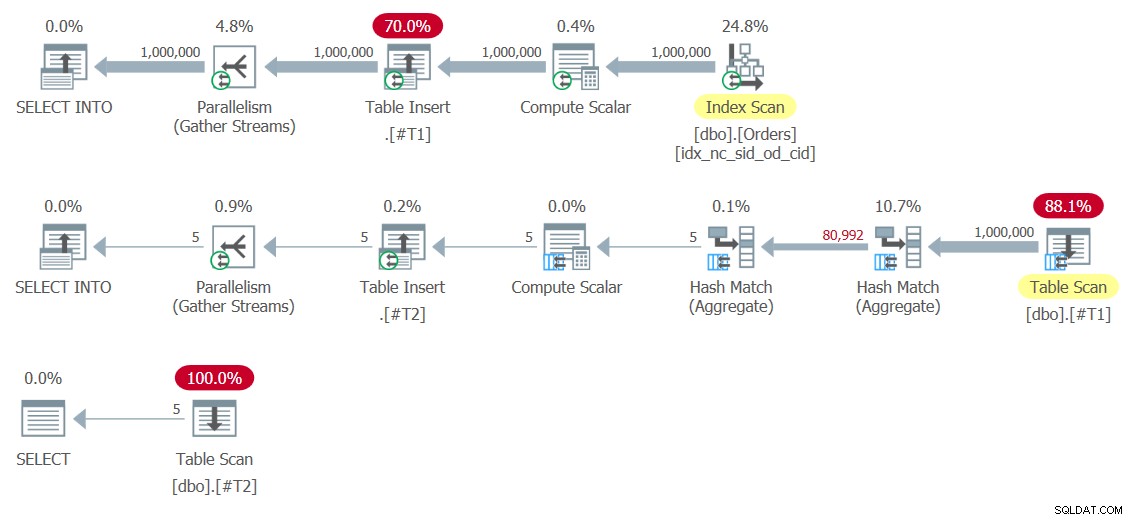 चित्र 8:समाधान 8 के लिए योजनाएं
चित्र 8:समाधान 8 के लिए योजनाएं
अस्थायी टेबल #T1 और #T2 पर परिणाम सेट लिखने वाले टेबल इंसर्ट ऑपरेटरों पर ध्यान दें। पहला वाला विशेष रूप से महंगा है क्योंकि यह #T1 पर 1,000,000 पंक्तियाँ लिखता है। यहाँ प्रदर्शन संख्याएँ हैं जो मुझे इस निष्पादन के लिए मिली हैं:
duration: 454 ms, CPU: 1517 ms, reads: 14359, writes: 359
जैसा कि आप देख सकते हैं, सीटीई के साथ समाधान अधिक इष्टतम है।
कब बने रहना है
तो क्या यह मामला है कि एक मॉड्यूलर समाधान जिसमें प्रत्येक सीटीई का केवल एक ही मूल्यांकन शामिल है, हमेशा अस्थायी तालिकाओं का उपयोग करने के लिए पसंद किया जाता है? जरूरी नही। सीटीई-आधारित समाधानों में जिसमें कई चरण शामिल होते हैं, और जिसके परिणामस्वरूप विस्तृत योजनाएं होती हैं, जहां ऑप्टिमाइज़र को योजना में कई अलग-अलग बिंदुओं पर बहुत सारे कार्डिनैलिटी अनुमानों को लागू करने की आवश्यकता होती है, आप संचित अशुद्धियों के साथ समाप्त हो सकते हैं, जिसके परिणामस्वरूप उप-विकल्प होते हैं। ऐसे मामलों से निपटने का प्रयास करने की तकनीकों में से एक यह है कि कुछ मध्यवर्ती परिणाम अपने आप को अस्थायी तालिकाओं में सेट करते हैं, और यदि आवश्यक हो तो उन पर अनुक्रमणिका भी बनाते हैं, जिससे अनुकूलक को नए आँकड़ों के साथ एक नई शुरुआत मिलती है, जिससे बेहतर गुणवत्ता वाले कार्डिनैलिटी अनुमानों की संभावना बढ़ जाती है। उम्मीद है कि अधिक इष्टतम विकल्पों की ओर ले जाएगा। क्या यह ऐसे समाधान से बेहतर है जो अस्थायी तालिकाओं का उपयोग नहीं करता है, यह कुछ ऐसा है जिसे आपको परीक्षण करने की आवश्यकता होगी। कभी-कभी बेहतर गुणवत्ता वाले कार्डिनैलिटी अनुमान प्राप्त करने के लिए लगातार मध्यवर्ती परिणाम सेट के लिए अतिरिक्त लागत का ट्रेडऑफ़ इसके लायक होगा।
एक अन्य विशिष्ट मामला जहां अस्थायी तालिकाओं का उपयोग करना पसंदीदा तरीका है, जब सीटीई-आधारित समाधान में एक ही सीटीई के कई मूल्यांकन होते हैं, और सीटीई की आंतरिक क्वेरी काफी महंगी होती है। निम्नलिखित सीटीई-आधारित समाधान पर विचार करें (हम इसे क्वेरी 9 कहेंगे), जो प्रत्येक ऑर्डर वर्ष और महीने से एक अलग ऑर्डर वर्ष और महीने से मेल खाता है जिसमें निकटतम ऑर्डर गणना होती है:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate)
)
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2; यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ----------- ----------- ----------- ----------- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2016 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows affected)
प्रश्न 9 की योजना चित्र 9 में दिखाई गई है।
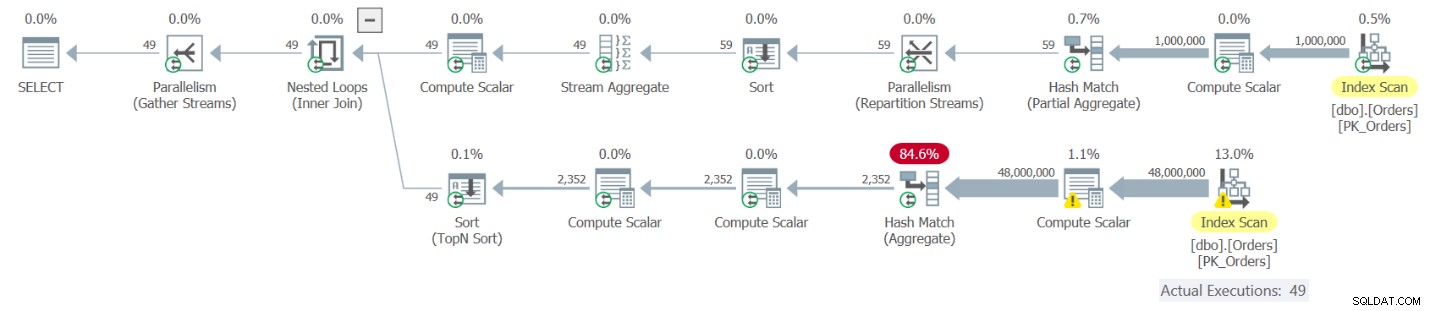 चित्र 9:क्वेरी 9 के लिए निष्पादन योजना
चित्र 9:क्वेरी 9 के लिए निष्पादन योजना
योजना का शीर्ष भाग O1 के रूप में उपनामित OrdCount CTE के उदाहरण से मेल खाता है। यह संदर्भ सीटीई ऑर्डकाउंट के एक मूल्यांकन में परिणत होता है। योजना का यह हिस्सा ऑर्डर टेबल पर एक इंडेक्स से पंक्तियों को खींचता है, उन्हें साल और महीने के अनुसार समूहित करता है, और प्रति समूह ऑर्डर की गिनती को जोड़ता है, जिसके परिणामस्वरूप 49 पंक्तियां होती हैं। योजना का निचला भाग सहसंबद्ध व्युत्पन्न तालिका O2 से मेल खाता है, जिसे O1 से प्रति पंक्ति लागू किया जाता है, इसलिए इसे 49 बार निष्पादित किया जाता है। प्रत्येक निष्पादन ऑर्डकाउंट सीटीई से पूछताछ करता है, और इसलिए सीटीई की आंतरिक क्वेरी का एक अलग मूल्यांकन होता है। आप देख सकते हैं कि योजना का निचला भाग आदेशों, समूहों पर अनुक्रमणिका से सभी पंक्तियों को स्कैन करता है और उन्हें एकत्रित करता है। आप मूल रूप से सीटीई के कुल 50 मूल्यांकन प्राप्त करते हैं, जिसके परिणामस्वरूप ऑर्डर से 1,000,000 पंक्तियों को 50 बार स्कैन किया जाता है, उन्हें समूहबद्ध और एकत्रित किया जाता है। यह एक बहुत ही कुशल समाधान की तरह नहीं लगता है। मेरी मशीन पर इस समाधान को क्रियान्वित करते समय मुझे जो प्रदर्शन उपाय मिले, वे यहां दिए गए हैं:
duration: 16 seconds, CPU: 56 seconds, reads: 130404, writes: 0
यह देखते हुए कि इसमें केवल कुछ दर्जन महीने शामिल हैं, एक अस्थायी तालिका का उपयोग करने के लिए क्या अधिक कुशल होगा, एक एकल गतिविधि के परिणाम को संग्रहीत करने के लिए जो ऑर्डर से पंक्तियों को समूह और एकत्रित करता है, और उसके बाद बाहरी और आंतरिक दोनों इनपुट होते हैं APPLY ऑपरेटर अस्थायी तालिका के साथ सहभागिता करता है। सीटीई के बजाय अस्थायी तालिका का उपयोग करके यहां समाधान है (हम इसे समाधान 10 कहते हैं):
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
INTO #OrdCount
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate);
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM #OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM #OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2;
DROP TABLE #OrdCount; यहां अस्थायी तालिका को अनुक्रमित करने का कोई मतलब नहीं है, क्योंकि TOP फ़िल्टर इसके ऑर्डरिंग विनिर्देश में गणना पर आधारित है, और इसलिए एक प्रकार अपरिहार्य है। हालांकि, यह बहुत अच्छी तरह से हो सकता है कि अन्य मामलों में, अन्य समाधानों के साथ, आपके लिए अपनी अस्थायी तालिकाओं को अनुक्रमित करने पर विचार करना भी प्रासंगिक होगा। किसी भी मामले में, इस समाधान की योजना चित्र 10 में दिखाई गई है।
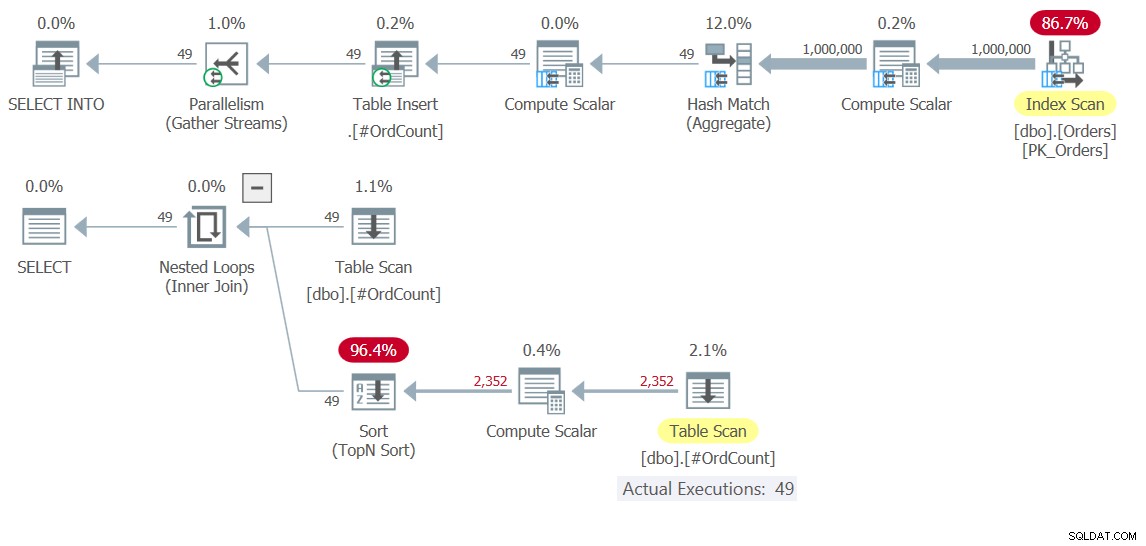 चित्र 10:समाधान 10 के लिए निष्पादन योजनाएं
चित्र 10:समाधान 10 के लिए निष्पादन योजनाएं
शीर्ष योजना में देखें कि कैसे 1,000,000 पंक्तियों को स्कैन करना, उन्हें समूहबद्ध करना और एकत्र करना शामिल है, केवल एक बार होता है। 49 पंक्तियों को अस्थायी तालिका #OrdCount पर लिखा जाता है, और फिर नीचे की योजना नेस्टेड लूप्स ऑपरेटर के बाहरी और आंतरिक इनपुट दोनों के लिए अस्थायी तालिका के साथ इंटरैक्ट करती है, जो APPLY ऑपरेटर के तर्क को संभालती है।
यहाँ प्रदर्शन संख्याएँ हैं जो मुझे इस समाधान के निष्पादन के लिए मिली हैं:
duration: 0.392 seconds, CPU: 0.5 seconds, reads: 3636, writes: 3
यह सीटीई-आधारित समाधान की तुलना में परिमाण के क्रम में तेज़ है।
आगे क्या है?
इस लेख में मैंने सीटीई से संबंधित अनुकूलन विचारों का कवरेज शुरू किया। मैंने दिखाया कि व्युत्पन्न तालिकाओं के साथ होने वाली अननेस्टिंग/प्रतिस्थापन प्रक्रिया सीटीई के साथ उसी तरह काम करती है। मैंने इस तथ्य पर भी चर्चा की कि गैर-पुनरावर्ती सीटीई जारी नहीं रहता है और समझाया कि जब दृढ़ता आपके समाधान के प्रदर्शन के लिए एक महत्वपूर्ण कारक है, तो आपको अस्थायी तालिकाओं और तालिका चर जैसे उपकरणों का उपयोग करके इसे स्वयं संभालना होगा। अगले महीने मैं सीटीई अनुकूलन के अतिरिक्त पहलुओं को शामिल करते हुए चर्चा जारी रखूंगा।