यह आलेख तालिका भावों पर एक श्रृंखला का चौथा भाग है। भाग 1 और भाग 2 में मैंने व्युत्पन्न तालिकाओं के वैचारिक उपचार को कवर किया। भाग 3 में मैंने व्युत्पन्न तालिकाओं के अनुकूलन विचारों को शामिल करना शुरू किया। इस महीने मैं व्युत्पन्न तालिकाओं के अनुकूलन के और पहलुओं को कवर करता हूं; विशेष रूप से, मैं व्युत्पन्न तालिकाओं के प्रतिस्थापन/अननेस्टिंग पर ध्यान केंद्रित करता हूं।
अपने उदाहरणों में मैं TSQLV5 और PerformanceV5 नामक नमूना डेटाबेस का उपयोग करूँगा। आप यहां TSQLV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट और इसके ईआर आरेख यहां पा सकते हैं। आप यहां परफॉरमेंसV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट पा सकते हैं।
अननेस्टिंग/प्रतिस्थापन
टेबल एक्सप्रेशन का अननेस्टिंग/प्रतिस्थापन एक क्वेरी लेने की एक प्रक्रिया है जिसमें टेबल एक्सप्रेशन का नेस्टिंग शामिल है, और जैसे कि इसे एक क्वेरी के साथ प्रतिस्थापित करना जहां नेस्टेड लॉजिक समाप्त हो गया है। मुझे इस बात पर जोर देना चाहिए कि व्यवहार में, कोई वास्तविक प्रक्रिया नहीं है जिसमें SQL सर्वर नेस्टेड लॉजिक के साथ मूल क्वेरी स्ट्रिंग को नेस्टिंग के बिना एक नई क्वेरी स्ट्रिंग में परिवर्तित करता है। वास्तव में क्या होता है कि क्वेरी पार्सिंग प्रक्रिया मूल क्वेरी को बारीकी से प्रतिबिंबित करने वाले लॉजिकल ऑपरेटरों का प्रारंभिक पेड़ बनाती है। फिर, SQL सर्वर इस क्वेरी ट्री में परिवर्तन लागू करता है, कुछ अनावश्यक चरणों को समाप्त करता है, कई चरणों को कम चरणों में संक्षिप्त करता है, और ऑपरेटरों को चारों ओर ले जाता है। इसके परिवर्तनों में, जब तक कुछ शर्तों को पूरा किया जाता है, SQL सर्वर मूल रूप से तालिका अभिव्यक्ति सीमाओं के आसपास चीजों को स्थानांतरित कर सकता है-कभी-कभी प्रभावी रूप से नेस्टेड इकाइयों को समाप्त कर देता है। यह सब एक इष्टतम योजना खोजने के प्रयास में है।
इस लेख में मैं दोनों मामलों को कवर करता हूं जहां इस तरह के अननेस्टिंग होते हैं, साथ ही साथ अननेस्टिंग इनहिबिटर भी होते हैं। यही है, जब आप कुछ क्वेरी तत्वों का उपयोग करते हैं तो यह SQL सर्वर को क्वेरी ट्री में तार्किक ऑपरेटरों को स्थानांतरित करने में सक्षम होने से रोकता है, इसे मूल क्वेरी में प्रयुक्त तालिका अभिव्यक्तियों की सीमाओं के आधार पर ऑपरेटरों को संसाधित करने के लिए मजबूर करता है।
मैं एक साधारण उदाहरण का प्रदर्शन करके शुरू करूँगा जहाँ व्युत्पन्न तालिकाएँ अननेस्टेड हो जाती हैं। मैं एक नेस्टिंग इनहिबिटर के लिए एक उदाहरण भी प्रदर्शित करूँगा। फिर मैं उन असामान्य मामलों के बारे में बात करूँगा जहाँ अननेस्टिंग अवांछनीय हो सकती है, जिसके परिणामस्वरूप त्रुटियाँ या प्रदर्शन में गिरावट हो सकती है, और उन मामलों में अननेस्टिंग इनहिबिटर को नियोजित करके अननेस्टिंग को कैसे रोका जा सकता है, यह प्रदर्शित करता हूँ।
निम्न क्वेरी (हम इसे क्वेरी 1 कहेंगे) व्युत्पन्न तालिकाओं की एकाधिक नेस्टेड परतों का उपयोग करती है, जहां प्रत्येक तालिका अभिव्यक्ति स्थिरांक के आधार पर बुनियादी फ़िल्टरिंग तर्क लागू करती है:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; जैसा कि आप देख सकते हैं, प्रत्येक तालिका अभिव्यक्ति एक भिन्न तिथि से शुरू होने वाली ऑर्डर तिथियों की श्रेणी को फ़िल्टर करती है। SQL सर्वर इस बहु-स्तरित क्वेरीिंग लॉजिक को अननेस्ट करता है, जो इसे चार फ़िल्टरिंग विधेय को एक एकल में मर्ज करने में सक्षम बनाता है जो सभी चार विधेय के प्रतिच्छेदन का प्रतिनिधित्व करता है।
चित्र 1 में दिखाए गए प्रश्न 1 की योजना की जांच करें।
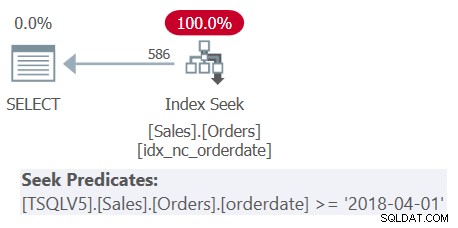 चित्र 1:प्रश्न 1 के लिए योजना
चित्र 1:प्रश्न 1 के लिए योजना
ध्यान दें कि सभी चार फ़िल्टरिंग विधेय चार के प्रतिच्छेदन का प्रतिनिधित्व करने वाले एकल विधेय में विलय कर दिए गए थे। योजना idx_nc_orderdate इंडेक्स में सीक विधेय के रूप में एकल मर्ज किए गए विधेय के आधार पर एक सीक लागू करती है। इस इंडेक्स को ऑर्डरडेट (स्पष्ट रूप से), ऑर्डरिड (स्पष्ट रूप से ऑर्डरिड पर क्लस्टर इंडेक्स की उपस्थिति के कारण) इंडेक्स कुंजी के रूप में परिभाषित किया गया है।
यह भी देखें कि भले ही सभी टेबल एक्सप्रेशन SELECT * का उपयोग करते हैं और केवल सबसे बाहरी क्वेरी ब्याज के दो कॉलम प्रोजेक्ट करती है:ऑर्डरडेट और ऑर्डरिड, उपरोक्त इंडेक्स को कवरिंग माना जाता है। जैसा कि मैंने भाग 3 में समझाया है, अनुक्रमणिका चयन जैसे अनुकूलन उद्देश्यों के लिए, SQL सर्वर तालिका अभिव्यक्तियों के उन स्तंभों की उपेक्षा करता है जो अंततः प्रासंगिक नहीं हैं। हालांकि याद रखें कि आपको उन स्तंभों को क्वेरी करने के लिए अनुमतियों की आवश्यकता है।
जैसा कि उल्लेख किया गया है, SQL सर्वर टेबल एक्सप्रेशन को अननेस्ट करने का प्रयास करेगा, लेकिन अगर यह अननेस्टिंग इनहिबिटर में ठोकर खाता है तो अननेस्टिंग से बच जाएगा। एक निश्चित अपवाद के साथ जिसका मैं बाद में वर्णन करूंगा, TOP या OFFSET FETCH का उपयोग अननेस्टिंग को रोक देगा। इसका कारण यह है कि TOP या OFFSET FETCH के साथ तालिका व्यंजक को अननेस्ट करने का प्रयास करने से मूल क्वेरी के अर्थ में परिवर्तन हो सकता है।
एक उदाहरण के रूप में, निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 2 कहेंगे):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; TOP फ़िल्टर में पंक्तियों की इनपुट संख्या एक BIGINT-टाइप किया गया मान है। इस उदाहरण में मैं अधिकतम BIGINT मान (2 ^ 63 - 1, SELECT POWER (2।, 63) - 1) का उपयोग करके T-SQL में गणना कर रहा हूं। भले ही आप और मैं जानते हैं कि हमारी ऑर्डर तालिका में कभी भी इतनी पंक्तियाँ नहीं होंगी, और इसलिए TOP फ़िल्टर वास्तव में अर्थहीन है, SQL सर्वर को फ़िल्टर के सार्थक होने की सैद्धांतिक संभावना को ध्यान में रखना होगा। नतीजतन, SQL सर्वर इस क्वेरी में टेबल एक्सप्रेशन को अननेस्ट नहीं करता है। प्रश्न 2 की योजना चित्र 2 में दिखाई गई है।
 चित्र 2:क्वेरी 2 के लिए योजना
चित्र 2:क्वेरी 2 के लिए योजना
अननेस्टिंग इनहिबिटर्स ने SQL सर्वर को फ़िल्टरिंग विधेय को मर्ज करने में सक्षम होने से रोक दिया, जिससे योजना का आकार वैचारिक क्वेरी के अधिक निकट हो गया। हालांकि, यह देखना दिलचस्प है कि SQL सर्वर ने अभी भी उन स्तंभों को अनदेखा कर दिया जो अंततः सबसे बाहरी क्वेरी के लिए प्रासंगिक नहीं थे, और इसलिए ऑर्डरडेट, ऑर्डरिड पर कवरिंग इंडेक्स का उपयोग करने में सक्षम थे।
यह समझाने के लिए कि TOP और OFFSET-FETCH अननेस्टिंग इनहिबिटर क्यों हैं, आइए एक साधारण प्रेडिकेट पुशडाउन ऑप्टिमाइज़ेशन तकनीक लें। प्रेडिकेट पुशडाउन का अर्थ है कि ऑप्टिमाइज़र लॉजिकल क्वेरी प्रोसेसिंग में दिखाई देने वाले मूल बिंदु की तुलना में एक फ़िल्टर विधेय को पहले के बिंदु पर धकेलता है। उदाहरण के लिए, मान लें कि आपके पास एक क्वेरी है जिसमें इनर जॉइन और WHERE फ़िल्टर दोनों शामिल हैं, जो जॉइन के एक तरफ से कॉलम पर आधारित है। तार्किक क्वेरी प्रसंस्करण के संदर्भ में, शामिल होने के बाद WHERE फ़िल्टर का मूल्यांकन किया जाना चाहिए। लेकिन अक्सर ऑप्टिमाइज़र शामिल होने से पहले फ़िल्टर को एक चरण में धकेल देगा, क्योंकि इससे काम करने के लिए कम पंक्तियों के साथ जुड़ना छोड़ देता है, जिसके परिणामस्वरूप आमतौर पर अधिक इष्टतम योजना होती है। याद रखें कि इस तरह के परिवर्तनों की अनुमति केवल उन मामलों में दी जाती है जहां मूल क्वेरी का अर्थ संरक्षित होता है, इस अर्थ में कि आपको सही परिणाम सेट प्राप्त करने की गारंटी है।
निम्नलिखित कोड पर विचार करें, जिसमें एक व्युत्पन्न तालिका के विरुद्ध WHERE फ़िल्टर के साथ एक बाहरी क्वेरी है, जो बदले में एक TOP फ़िल्टर वाली तालिका अभिव्यक्ति पर आधारित है:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; तालिका अभिव्यक्ति में ORDER BY क्लॉज की कमी के कारण यह क्वेरी निश्चित रूप से गैर-निर्धारिती है। जब मैंने इसे चलाया, तो SQL सर्वर 2018 से पहले ऑर्डर की तारीखों के साथ पहली तीन पंक्तियों तक पहुंच गया, इसलिए मुझे आउटपुट के रूप में एक खाली सेट मिला:
orderid orderdate ----------- ---------- (0 rows affected)
जैसा कि उल्लेख किया गया है, तालिका अभिव्यक्ति में TOP के उपयोग ने यहां तालिका अभिव्यक्ति के अघोषित/प्रतिस्थापन को रोका। यदि SQL सर्वर ने टेबल एक्सप्रेशन को अननेस्टेड किया होता, तो प्रतिस्थापन प्रक्रिया निम्न क्वेरी के बराबर होती:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
ORDER BY क्लॉज की कमी के कारण यह क्वेरी भी गैर-निर्धारिती है, लेकिन स्पष्ट रूप से, इसका मूल क्वेरी की तुलना में एक अलग अर्थ है। यदि Sales.Orders तालिका में 2018 या उसके बाद के कम से कम तीन ऑर्डर दिए गए हैं—और यह करता है—तो यह क्वेरी मूल क्वेरी के विपरीत, तीन पंक्तियों को अनिवार्य रूप से वापस कर देगी। जब मैंने इस क्वेरी को चलाया तो मुझे यह परिणाम मिला:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
यदि उपरोक्त दो प्रश्नों की गैर-निर्धारक प्रकृति आपको भ्रमित करती है, तो यहां एक नियतात्मक प्रश्न के साथ एक उदाहरण दिया गया है:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; टेबल एक्सप्रेशन तीन ऑर्डर को न्यूनतम ऑर्डर आईडी के साथ फ़िल्टर करता है। बाहरी क्वेरी तब उन तीन आदेशों से फ़िल्टर करती है जो 8 जुलाई, 2017 को या उसके बाद दिए गए थे। पता चलता है कि केवल एक योग्य आदेश है। यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
मान लीजिए कि SQL सर्वर ने मूल क्वेरी में टेबल एक्सप्रेशन को अननेस्टेड किया है, जिसके परिणामस्वरूप प्रतिस्थापन प्रक्रिया निम्न क्वेरी के बराबर है:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
इस क्वेरी का अर्थ मूल क्वेरी से अलग है। यह क्वेरी पहले 8 जुलाई, 2017 को या उसके बाद दिए गए ऑर्डर को फ़िल्टर करती है और फिर सबसे कम ऑर्डर आईडी वाले शीर्ष तीन को फ़िल्टर करती है। यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
मूल क्वेरी के अर्थ को बदलने से बचने के लिए, SQL सर्वर यहां अननेस्टिंग/प्रतिस्थापन लागू नहीं करता है।
पिछले दो उदाहरणों में WHERE और TOP फ़िल्टरिंग का एक साधारण मिश्रण शामिल था, लेकिन अननेस्टिंग के परिणामस्वरूप अतिरिक्त परस्पर विरोधी तत्व हो सकते हैं। उदाहरण के लिए, क्या होगा यदि आपके पास टेबल एक्सप्रेशन और बाहरी क्वेरी में अलग-अलग ऑर्डरिंग विनिर्देश हैं, जैसे निम्न उदाहरण में:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; आप महसूस करते हैं कि यदि SQL सर्वर ने टेबल एक्सप्रेशन को अननेस्टेड किया है, तो दो अलग-अलग ऑर्डरिंग विनिर्देशों को एक में संक्षिप्त कर दिया गया है, परिणामी क्वेरी का मूल क्वेरी से अलग अर्थ होगा। यह या तो गलत पंक्तियों को फ़िल्टर कर देता या परिणाम पंक्तियों को गलत प्रस्तुति क्रम में प्रस्तुत करता। संक्षेप में, आपको एहसास होता है कि SQL सर्वर के लिए सुरक्षित बात यह है कि टॉप और ऑफ़सेट-फ़ेच प्रश्नों पर आधारित टेबल एक्सप्रेशन के अननेस्टिंग/प्रतिस्थापन से बचना है।
मैंने पहले उल्लेख किया था कि इस नियम का एक अपवाद है कि TOP और OFFSET-FETCH का उपयोग अननेस्टिंग को रोकता है। वह तब होता है जब आप ORDER BY क्लॉज के साथ या बिना नेस्टेड टेबल एक्सप्रेशन में TOP (100) PERCENT का उपयोग करते हैं। SQL सर्वर को पता चलता है कि कोई वास्तविक फ़िल्टरिंग नहीं चल रही है और विकल्प को अनुकूलित करता है। इसे प्रदर्शित करने वाला एक उदाहरण यहां दिया गया है:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; टॉप फ़िल्टर को नज़रअंदाज कर दिया जाता है, अननेस्टिंग होती है, और आपको वही प्लान मिलता है जो पहले चित्र 1 में क्वेरी 1 के लिए दिखाया गया था।
नेस्टेड टेबल एक्सप्रेशन में बिना FETCH क्लॉज के OFFSET 0 ROWS का उपयोग करते समय, कोई वास्तविक फ़िल्टरिंग भी नहीं चल रही है। तो, सैद्धांतिक रूप से SQL सर्वर इस विकल्प को भी अनुकूलित कर सकता था और अननेस्टिंग को सक्षम कर सकता था, लेकिन इस लेखन की तारीख में ऐसा नहीं होता है। इसे प्रदर्शित करने वाला एक उदाहरण यहां दिया गया है:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; आपको वही योजना मिलती है जो पहले चित्र 2 में प्रश्न 2 के लिए दिखाई गई थी, जो दर्शाती है कि कोई भी घोंसला नहीं बनाया गया था।
पहले मैंने समझाया था कि अननेस्टिंग/प्रतिस्थापन प्रक्रिया वास्तव में एक नई क्वेरी स्ट्रिंग उत्पन्न नहीं करती है जो तब अनुकूलित हो जाती है, बल्कि उन परिवर्तनों के साथ करना पड़ता है जो SQL सर्वर तार्किक ऑपरेटरों के पेड़ पर लागू होता है। एसक्यूएल सर्वर नेस्टेड टेबल एक्सप्रेशन के साथ एक क्वेरी को अनुकूलित करने के तरीके के बीच एक अंतर है बनाम नेस्टिंग के बिना वास्तविक तार्किक समकक्ष क्वेरी। टेबल एक्सप्रेशन जैसे व्युत्पन्न टेबल, साथ ही सबक्वेरी का उपयोग सरल पैरामीटराइजेशन को रोकता है। लेख में पहले दिखाई गई क्वेरी 1 को याद करें:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; चूंकि क्वेरी व्युत्पन्न तालिकाओं का उपयोग करती है, इसलिए सरल पैरामीटरकरण नहीं होता है। यही है, SQL सर्वर स्थिरांक को मापदंडों से प्रतिस्थापित नहीं करता है और फिर क्वेरी को अनुकूलित करता है, बल्कि स्थिरांक के साथ क्वेरी को अनुकूलित करता है। स्थिरांक पर आधारित विधेय के साथ, SQL सर्वर प्रतिच्छेदन अवधियों को मर्ज कर सकता है, जिसके परिणामस्वरूप हमारे मामले में योजना में एकल विधेय होता है, जैसा कि पहले चित्र 1 में दिखाया गया है।
इसके बाद, निम्नलिखित क्वेरी पर विचार करें (हम इसे क्वेरी 3 कहेंगे), जो कि क्वेरी 1 का तार्किक समकक्ष है, लेकिन जहां आप स्वयं नेस्टिंग लागू करते हैं:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
इस क्वेरी की योजना चित्र 3 में दिखाई गई है।
 चित्र 3:क्वेरी 3 के लिए योजना
चित्र 3:क्वेरी 3 के लिए योजना
इस योजना को सरल मानकीकरण के लिए सुरक्षित माना जाता है, इसलिए स्थिरांक को मापदंडों से प्रतिस्थापित किया जाता है, और इसके परिणामस्वरूप, विधेय विलय नहीं होते हैं। मानकीकरण के लिए प्रेरणा निश्चित रूप से समान प्रश्नों को निष्पादित करते समय योजना के पुन:उपयोग की संभावना को बढ़ा रही है जो केवल उनके द्वारा उपयोग किए जाने वाले स्थिरांक में भिन्न होते हैं।
जैसा कि उल्लेख किया गया है, क्वेरी 1 में व्युत्पन्न तालिकाओं के उपयोग ने सरल मानकीकरण को रोका। इसी तरह, उपश्रेणियों के उपयोग से सरल मानकीकरण को रोका जा सकेगा। उदाहरण के लिए, WHERE क्लॉज में जोड़े गए सबक्वेरी के आधार पर अर्थहीन विधेय के साथ हमारी पिछली क्वेरी 3 है:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
इस बार सरल पैरामीटरकरण नहीं होता है, SQL सर्वर को स्थिरांक के साथ विधेय द्वारा दर्शाए गए प्रतिच्छेदन अवधियों को मर्ज करने के लिए सक्षम करता है, जिसके परिणामस्वरूप वही योजना होती है जैसा कि पहले चित्र 1 में दिखाया गया है।
यदि आपके पास स्थिरांक का उपयोग करने वाले तालिका अभिव्यक्तियों के साथ प्रश्न हैं, और यह आपके लिए महत्वपूर्ण है कि SQL सर्वर ने कोड को पैरामीटर किया है, और किसी भी कारण से आप इसे स्वयं पैरामीटर नहीं कर सकते हैं, तो याद रखें कि आपके पास योजना गाइड के साथ मजबूर पैरामीटरकरण का उपयोग करने का विकल्प है। उदाहरण के तौर पर, निम्न कोड क्वेरी 3 के लिए ऐसी योजना मार्गदर्शिका बनाता है:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; योजना मार्गदर्शिका बनाने के बाद फिर से क्वेरी 3 चलाएँ:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; आपको वही योजना मिलती है जो पहले चित्र 3 में पैरामीटरयुक्त विधेय के साथ दिखाई गई थी।
जब आप कर लें, तो योजना मार्गदर्शिका छोड़ने के लिए निम्न कोड चलाएँ:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
अननेस्टिंग को रोकना
याद रखें कि SQL सर्वर ऑप्टिमाइज़ेशन कारणों से टेबल एक्सप्रेशन को अननेस्ट करता है। लक्ष्य बिना घोंसले की तुलना में कम लागत वाली योजना खोजने की संभावना को बढ़ाना है। यह अनुकूलक द्वारा लागू किए गए अधिकांश परिवर्तन नियमों के लिए सही है। हालांकि, कुछ असामान्य मामले हो सकते हैं, जहां आप घोंसले के शिकार को रोकना चाहेंगे। यह या तो त्रुटियों से बचने के लिए हो सकता है (हां कुछ असामान्य मामलों में अननेस्टिंग के परिणामस्वरूप त्रुटियां हो सकती हैं) या प्रदर्शन कारणों से एक निश्चित योजना आकार को मजबूर करने के लिए, अन्य प्रदर्शन संकेतों का उपयोग करने के समान। याद रखें, आपके पास बहुत बड़ी संख्या के साथ TOP का उपयोग करके अननेस्टिंग को रोकने का एक आसान तरीका है।
त्रुटियों से बचने के लिए उदाहरण
मैं एक ऐसे मामले से शुरू करूंगा जहां टेबल एक्सप्रेशन को अननेस्टिंग करने से त्रुटियां हो सकती हैं।
निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 4 कहेंगे):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
यह उदाहरण इस अर्थ में थोड़ा गलत है कि दूसरे फ़िल्टर विधेय को फिर से लिखना आसान है, इसलिए इसका परिणाम कभी भी त्रुटि (छूट <0.1) में नहीं होगा, लेकिन यह मेरे लिए मेरी बात को स्पष्ट करने के लिए एक सुविधाजनक उदाहरण है। छूट गैर-ऋणात्मक हैं। इसलिए भले ही शून्य छूट के साथ ऑर्डर लाइनें हों, क्वेरी को उन्हें फ़िल्टर करना चाहिए (पहला फ़िल्टर विधेय कहता है कि छूट तालिका में न्यूनतम छूट से अधिक होनी चाहिए)। हालाँकि, इस बात का कोई आश्वासन नहीं है कि SQL सर्वर लिखित क्रम में विधेय का मूल्यांकन करेगा, इसलिए आप शॉर्ट सर्किट पर भरोसा नहीं कर सकते।
चित्र 4 में दिखाए गए प्रश्न 4 की योजना की जांच करें।
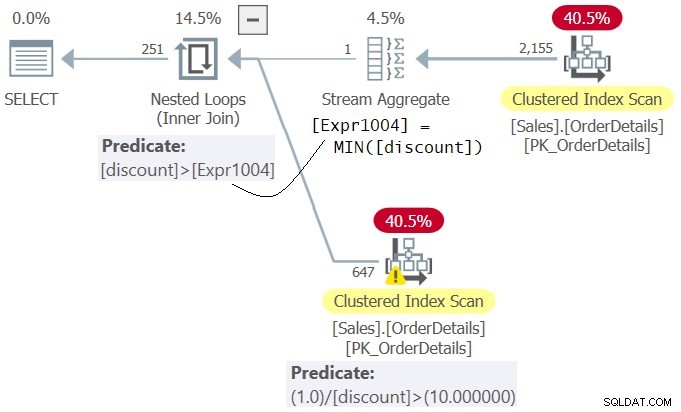 चित्र 4:क्वेरी 4 के लिए योजना
चित्र 4:क्वेरी 4 के लिए योजना
ध्यान दें कि योजना में विधेय 1.0 / छूट> 10.0 (WHERE क्लॉज में दूसरा) का मूल्यांकन विधेय छूट>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
शायद आप सोच रहे हैं कि आप व्युत्पन्न तालिका का उपयोग करके त्रुटि से बच सकते हैं, फ़िल्टरिंग कार्यों को एक आंतरिक और एक बाहरी से अलग कर सकते हैं, जैसे:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; हालाँकि, SQL सर्वर व्युत्पन्न तालिका के अननेस्टिंग को लागू करता है, जिसके परिणामस्वरूप पहले चित्र 4 में दिखाया गया एक ही योजना है, और परिणामस्वरूप, यह कोड भी शून्य त्रुटि से विभाजित होने पर विफल हो जाता है:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
यहां एक आसान समाधान है एक नेस्टिंग अवरोधक को पेश करना, जैसे (हम इस समाधान को प्रश्न 5 कहेंगे):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; प्रश्न 5 की योजना चित्र 5 में दिखाई गई है।
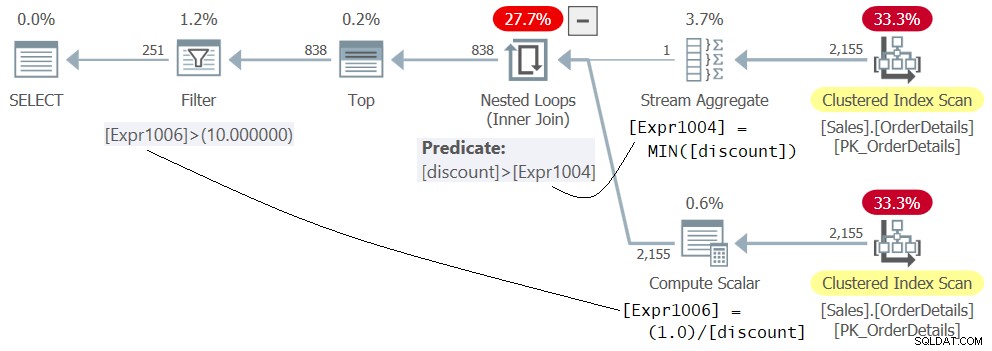 चित्र 5:प्रश्न 5 के लिए योजना
चित्र 5:प्रश्न 5 के लिए योजना
इस तथ्य से भ्रमित न हों कि नेस्टेड लूप्स ऑपरेटर के आंतरिक भाग में अभिव्यक्ति 1.0 / छूट दिखाई देती है, जैसे कि पहले मूल्यांकन किया जा रहा हो। यह सिर्फ सदस्य Expr1006 की परिभाषा है। नेस्टेड लूप्स ऑपरेटर द्वारा पहले न्यूनतम छूट वाली पंक्तियों को फ़िल्टर किए जाने के बाद विधेय Expr1006> 10.0 का वास्तविक मूल्यांकन फ़िल्टर ऑपरेटर द्वारा योजना के अंतिम चरण के रूप में लागू किया जाता है। यह समाधान बिना किसी त्रुटि के सफलतापूर्वक चलता है।
प्रदर्शन कारणों के लिए उदाहरण
मैं ऐसे मामले को जारी रखूंगा जहां टेबल एक्सप्रेशन को अननेस्टिंग प्रदर्शन को नुकसान पहुंचा सकता है।
संदर्भ को PerformanceV5 डेटाबेस में बदलने और सांख्यिकी IO और TIME को सक्षम करने के लिए निम्न कोड चलाकर प्रारंभ करें:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 6 कहेंगे):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
ऑप्टिमाइज़र एक सहायक कवरिंग इंडेक्स को शिपरिड और ऑर्डरडेट के साथ प्रमुख कुंजी के रूप में पहचानता है। इसलिए यह इंडेक्स के ऑर्डर किए गए स्कैन के साथ एक योजना बनाता है, जिसके बाद ऑर्डर-आधारित स्ट्रीम एग्रीगेट ऑपरेटर होता है, जैसा कि चित्र 6 में क्वेरी 6 की योजना में दिखाया गया है।
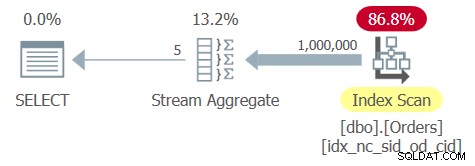 चित्र 6:प्रश्न 6 के लिए योजना
चित्र 6:प्रश्न 6 के लिए योजना
आदेश तालिका में 1,00,000 पंक्तियाँ हैं, और समूहीकरण स्तंभ शिपरिड बहुत सघन है—केवल 5 विशिष्ट शिपर आईडी हैं, जिसके परिणामस्वरूप 20% घनत्व (प्रति विशिष्ट मान का औसत प्रतिशत) है। इंडेक्स लीफ के पूर्ण स्कैन को लागू करने में कुछ हज़ार पृष्ठों को पढ़ना शामिल है, जिसके परिणामस्वरूप मेरे सिस्टम पर लगभग एक तिहाई सेकंड का रन टाइम होता है। यहाँ प्रदर्शन आँकड़े हैं जो मुझे इस क्वेरी के निष्पादन के लिए मिले हैं:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
इंडेक्स ट्री वर्तमान में तीन स्तर गहरा है।
आइए ऑर्डर की संख्या को 1,000 से 1,000,000,000 के कारक तक बढ़ाएं, लेकिन फिर भी केवल 5 अलग-अलग शिपर्स के साथ। इंडेक्स लीफ में पृष्ठों की संख्या 1,000 के कारक से बढ़ेगी, और इंडेक्स ट्री के परिणामस्वरूप शायद एक अतिरिक्त स्तर (चार स्तर गहरा) होगा। इस योजना में रैखिक स्केलिंग है। आप लगभग 4,00,000 तार्किक रीड्स और कुछ मिनटों के रन टाइम के साथ समाप्त होंगे।
जब आपको ग्रुपिंग कॉलम (महत्वपूर्ण!) में बहुत अधिक घनत्व के साथ एक बड़ी टेबल के खिलाफ MIN या MAX एग्रीगेट की गणना करने की आवश्यकता होती है, और ग्रुपिंग कॉलम और एग्रीगेशन कॉलम पर एक सपोर्टिंग बी-ट्री इंडेक्स कुंजीबद्ध होता है, तो बहुत अधिक इष्टतम होता है चित्र 6 में से एक की तुलना में योजना आकार की कल्पना करें। एक योजना आकार की कल्पना करें जो शिपर्स टेबल पर कुछ इंडेक्स से शिपर आईडी के छोटे सेट को स्कैन करता है, और एक लूप में प्रत्येक शिपर के लिए ऑर्डर पर सपोर्टिंग इंडेक्स के खिलाफ एग्रीगेट प्राप्त करने के लिए लागू होता है। तालिका में 1,000,000 पंक्तियों के साथ, 5 खोज में 15 पढ़ना शामिल होगा। 1,000,000,000 पंक्तियों के साथ, 5 खोजों में 20 पढ़ना शामिल होगा। एक ट्रिलियन पंक्तियों के साथ, कुल 25 पढ़ता है। जाहिर है, एक बहुत अधिक इष्टतम योजना। आप वास्तव में शिपर्स टेबल को क्वेरी करके और ऑर्डर के खिलाफ स्केलर एग्रीगेट सबक्वेरी का उपयोग करके एग्रीगेट प्राप्त करके ऐसी योजना प्राप्त कर सकते हैं, जैसे (हम इस समाधान को क्वेरी 7 कहेंगे):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
इस क्वेरी की योजना चित्र 7 में दिखाई गई है।
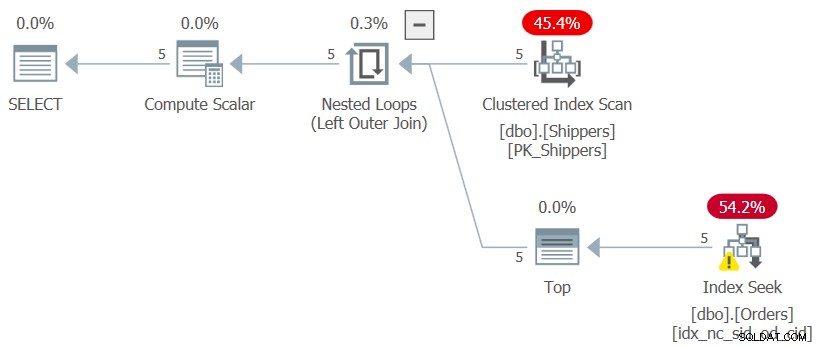 चित्र 7:प्रश्न 7 की योजना
चित्र 7:प्रश्न 7 की योजना
वांछित योजना आकार प्राप्त किया गया है, और इस क्वेरी के निष्पादन के लिए प्रदर्शन संख्या अपेक्षा के अनुरूप नगण्य है:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
जब तक ग्रुपिंग कॉलम बहुत घना है, ऑर्डर टेबल का आकार वस्तुतः महत्वहीन हो जाता है।
लेकिन जश्न मनाने से पहले एक पल रुकिए। केवल उन शिपर्स को रखने की आवश्यकता है जिनकी ऑर्डर तालिका में अधिकतम संबंधित ऑर्डर तिथि 2018 को या उसके बाद है। एक साधारण पर्याप्त अतिरिक्त की तरह लगता है। क्वेरी 7 के आधार पर एक व्युत्पन्न तालिका को परिभाषित करें, और बाहरी क्वेरी में फ़िल्टर लागू करें, जैसे (हम इस समाधान को क्वेरी 8 कहेंगे):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; काश, SQL सर्वर व्युत्पन्न तालिका क्वेरी, साथ ही साथ सबक्वेरी को हटा देता है, समूहीकृत क्वेरी तर्क के समतुल्य को समूहीकृत क्वेरी तर्क में परिवर्तित करता है, जिसमें समूहीकरण स्तंभ के रूप में शिपरिड होता है। और जिस तरह से SQL सर्वर समूहित क्वेरी को अनुकूलित करना जानता है वह इनपुट डेटा पर एक एकल पास पर आधारित होता है, जिसके परिणामस्वरूप एक योजना बहुत ही समान होती है जो पहले चित्र 6 में दिखाई गई थी, केवल अतिरिक्त फ़िल्टर के साथ। प्रश्न 8 की योजना चित्र 8 में दिखाई गई है।
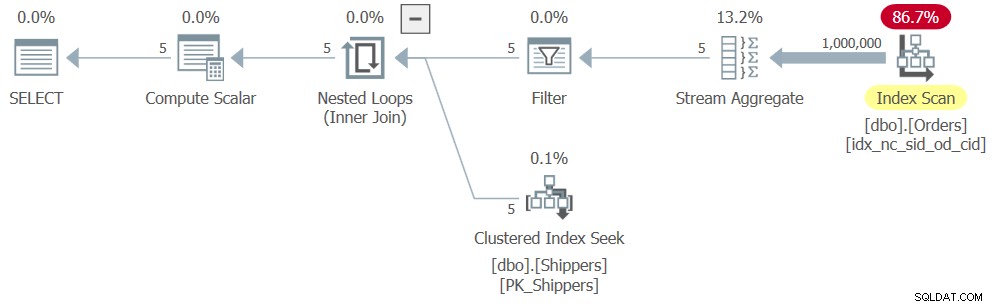 चित्र 8:क्वेरी 8 के लिए योजना
चित्र 8:क्वेरी 8 के लिए योजना
नतीजतन, स्केलिंग रैखिक है, और प्रदर्शन संख्याएं क्वेरी 6 के लिए समान हैं:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
फिक्स एक अननेस्टिंग इनहिबिटर को पेश करना है। यह तालिका अभिव्यक्ति में एक TOP फ़िल्टर जोड़कर किया जा सकता है, जिस पर व्युत्पन्न तालिका आधारित है, जैसे (हम इस समाधान को क्वेरी 9 कहेंगे):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; इस क्वेरी के लिए योजना चित्र 9 में दिखाई गई है और इसमें वांछित योजना आकार की तलाश है:
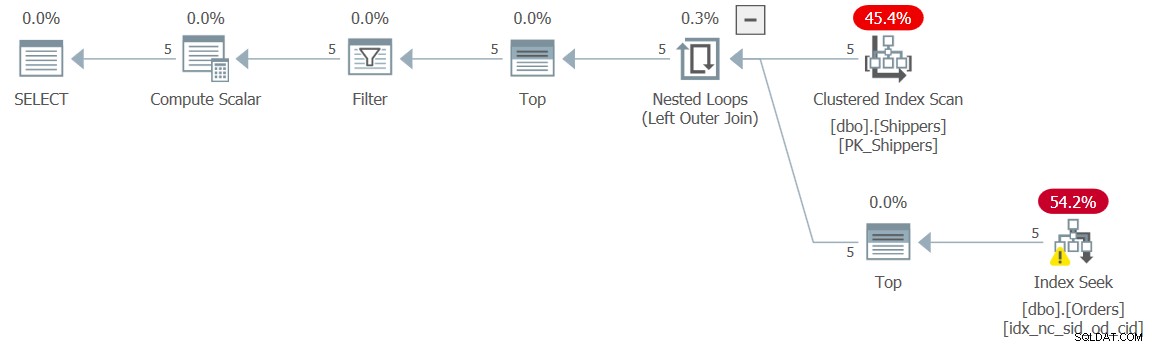 चित्र 9:प्रश्न 9 के लिए योजना
चित्र 9:प्रश्न 9 के लिए योजना
इस निष्पादन के लिए प्रदर्शन संख्याएँ निश्चित रूप से नगण्य हैं:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
फिर भी एक अन्य विकल्प MAX एग्रीगेट को समकक्ष TOP (1) फ़िल्टर से प्रतिस्थापित करके सबक्वेरी के अननेस्टिंग को रोकना है, जैसे (हम इस समाधान को क्वेरी 10 कहेंगे):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; इस क्वेरी के लिए योजना चित्र 10 में दिखाई गई है और फिर से, वांछित आकार की तलाश के साथ है।
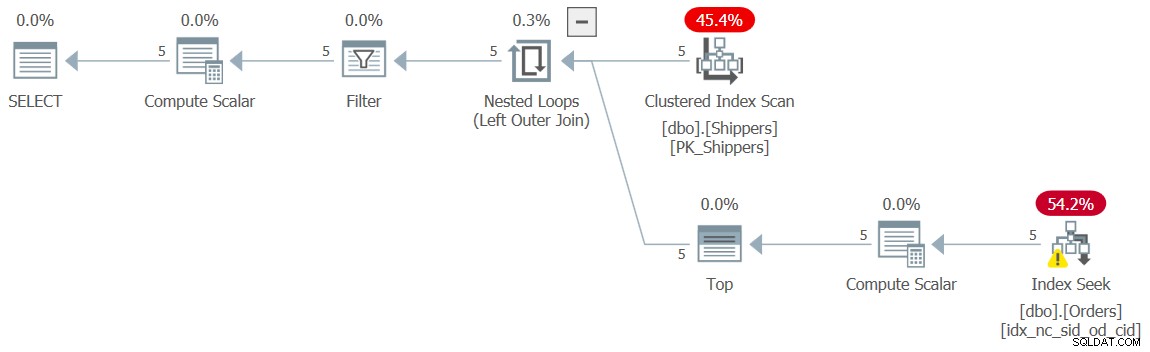 चित्र 10:प्रश्न 10 के लिए योजना
चित्र 10:प्रश्न 10 के लिए योजना
मुझे इस निष्पादन के लिए परिचित नगण्य प्रदर्शन संख्याएँ मिलीं:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
जब आप काम पूरा कर लें, तो प्रदर्शन आंकड़ों की रिपोर्ट करना बंद करने के लिए निम्न कोड चलाएँ:
SET STATISTICS IO, TIME OFF;
सारांश
इस लेख में मैंने व्युत्पन्न तालिकाओं के अनुकूलन के बारे में पिछले महीने शुरू की गई चर्चा को जारी रखा। इस महीने मैंने व्युत्पन्न तालिकाओं को हटाने पर ध्यान केंद्रित किया। मैंने समझाया कि आम तौर पर बिना नेस्टिंग के तुलना में अधिक इष्टतम योजना में अननेस्टिंग का परिणाम होता है, लेकिन साथ ही ऐसे उदाहरण भी शामिल होते हैं जहां यह अवांछनीय है। मैंने एक उदाहरण दिखाया जहां अननेस्टिंग के परिणामस्वरूप एक त्रुटि हुई और साथ ही एक उदाहरण जिसके परिणामस्वरूप प्रदर्शन में गिरावट आई। मैंने दिखाया कि कैसे TOP जैसे अननेस्टिंग इनहिबिटर लगाकर अननेस्टिंग को रोका जा सकता है।
अगले महीने मैं सीटीई पर ध्यान केंद्रित करते हुए नामित तालिका अभिव्यक्तियों की खोज जारी रखूंगा।