इस श्रृंखला के भाग 1 और भाग 2 में, मैंने सामान्य रूप से नामित तालिका अभिव्यक्तियों के तार्किक, या वैचारिक, पहलुओं और विशेष रूप से व्युत्पन्न तालिकाओं को कवर किया है। इस महीने और अगले महीने मैं व्युत्पन्न तालिकाओं के भौतिक प्रसंस्करण पहलुओं को कवर करने जा रहा हूं। भाग 1 से भौतिक डेटा स्वतंत्रता . को याद करें संबंधपरक सिद्धांत का सिद्धांत। रिलेशनल मॉडल और उस पर आधारित मानक क्वेरी भाषा केवल डेटा के वैचारिक पहलुओं से निपटने के लिए माना जाता है और डेटाबेस प्लेटफॉर्म पर डेटा के भंडारण, अनुकूलन, पहुंच और प्रसंस्करण जैसे भौतिक कार्यान्वयन विवरण छोड़ देता है (कार्यान्वयन ) डेटा के वैचारिक उपचार के विपरीत, जो एक गणितीय मॉडल और एक मानक भाषा पर आधारित है, और इसलिए वहाँ के विभिन्न रिलेशनल डेटाबेस प्रबंधन प्रणालियों में बहुत समान है, डेटा का भौतिक उपचार किसी भी मानक पर आधारित नहीं है, और इसलिए प्रवृत्ति बहुत मंच-विशिष्ट होने के लिए। श्रृंखला में नामित तालिका अभिव्यक्तियों के भौतिक उपचार के अपने कवरेज में मैं Microsoft SQL सर्वर और Azure SQL डेटाबेस में उपचार पर ध्यान केंद्रित करता हूं। अन्य डेटाबेस प्लेटफार्मों में भौतिक उपचार काफी भिन्न हो सकते हैं।
याद रखें कि इस श्रृंखला को ट्रिगर करने वाला कुछ भ्रम है जो SQL सर्वर समुदाय में नामित तालिका अभिव्यक्तियों के आसपास मौजूद है। दोनों शब्दावली के संदर्भ में और अनुकूलन के संदर्भ में। मैंने शृंखला के पहले दो हिस्सों में कुछ शब्दावली संबंधी विचारों को संबोधित किया, और सीटीई, विचारों और इनलाइन टीवीएफ पर चर्चा करते समय भविष्य के लेखों में और अधिक संबोधित करूंगा। नामित तालिका अभिव्यक्तियों के अनुकूलन के लिए, निम्नलिखित मदों के आसपास भ्रम है (मैं यहां व्युत्पन्न तालिकाओं का उल्लेख करता हूं क्योंकि यह इस आलेख का फोकस है):
- दृढ़ता: क्या व्युत्पन्न तालिका कहीं भी कायम है? क्या यह डिस्क पर बना रहता है, और SQL सर्वर इसके लिए मेमोरी को कैसे संभालता है?
- स्तंभ प्रक्षेपण: इंडेक्स मिलान व्युत्पन्न तालिकाओं के साथ कैसे काम करता है? उदाहरण के लिए, यदि कोई व्युत्पन्न तालिका कुछ अंतर्निहित तालिका से स्तंभों का एक निश्चित सबसेट प्रोजेक्ट करती है, और सबसे बाहरी क्वेरी व्युत्पन्न तालिका से स्तंभों का एक सबसेट प्रोजेक्ट करती है, तो SQL सर्वर इतना स्मार्ट है कि कॉलम के अंतिम सबसेट के आधार पर इष्टतम अनुक्रमण का पता लगा सके। वास्तव में इसकी आवश्यकता है? और अनुमतियों के बारे में क्या; क्या उपयोगकर्ता को उन सभी स्तंभों के लिए अनुमति की आवश्यकता है जो आंतरिक प्रश्नों में संदर्भित हैं, या केवल अंतिम के लिए जिनकी वास्तव में आवश्यकता है?
- स्तंभ उपनामों के अनेक संदर्भ: यदि व्युत्पन्न तालिका में एक परिणाम स्तंभ है जो एक नोडेटर्मिनिस्टिक गणना पर आधारित है, उदाहरण के लिए, SYSDATETIME फ़ंक्शन के लिए एक कॉल, और बाहरी क्वेरी में उस कॉलम के कई संदर्भ हैं, तो क्या गणना केवल एक बार या प्रत्येक बाहरी संदर्भ के लिए अलग से की जाएगी। ?
- अननेस्टिंग/प्रतिस्थापन/इनलाइनिंग: SQL सर्वर अनावश्यक, या इनलाइन, व्युत्पन्न तालिका क्वेरी करता है? यही है, क्या SQL सर्वर एक प्रतिस्थापन प्रक्रिया करता है जिससे यह मूल नेस्टेड कोड को एक क्वेरी में परिवर्तित करता है जो सीधे बेस टेबल के विरुद्ध जाता है? और यदि हां, तो क्या इस अवांछित प्रक्रिया से बचने के लिए SQL सर्वर को निर्देश देने का कोई तरीका है?
ये सभी महत्वपूर्ण प्रश्न हैं और इन सवालों के जवाबों में महत्वपूर्ण प्रदर्शन निहितार्थ हैं, इसलिए यह एक अच्छा विचार है कि SQL सर्वर में इन वस्तुओं को कैसे संभाला जाता है, इसकी स्पष्ट समझ है। इस महीने मैं पहली तीन वस्तुओं को संबोधित करने जा रहा हूँ। चौथे आइटम के बारे में कहने के लिए बहुत कुछ है, इसलिए मैं अगले महीने एक अलग लेख समर्पित करूँगा (भाग 4)।
अपने उदाहरणों में मैं TSQLV5 नामक एक नमूना डेटाबेस का उपयोग करूँगा। आप यहां TSQLV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट और इसके ईआर आरेख यहां पा सकते हैं।
दृढ़ता
कुछ लोग सहज रूप से मानते हैं कि SQL सर्वर वर्कटेबल में व्युत्पन्न तालिका (आंतरिक क्वेरी का परिणाम) के तालिका अभिव्यक्ति भाग के परिणाम को जारी रखता है। इस लेखन की तारीख में ऐसा नहीं है; हालाँकि, चूंकि दृढ़ता के विचार एक विक्रेता की पसंद हैं, Microsoft भविष्य में इसे बदलने का निर्णय ले सकता है। दरअसल, SQL सर्वर क्वेरी प्रोसेसिंग के हिस्से के रूप में वर्कटेबल्स (आमतौर पर tempdb में) में इंटरमीडिएट क्वेरी परिणाम जारी रखने में सक्षम है। यदि यह ऐसा करने का विकल्प चुनता है, तो आप योजना में स्पूल ऑपरेटर का कुछ रूप देखते हैं (स्पूल, एगर स्पूल, लेज़ी स्पूल, टेबल स्पूल, इंडेक्स स्पूल, विंडो स्पूल, रो काउंट स्पूल)। हालाँकि, SQL सर्वर की पसंद का कोई कार्यबल में कुछ स्पूल करना है या नहीं, वर्तमान में क्वेरी में नामित तालिका अभिव्यक्तियों के आपके उपयोग से कोई लेना-देना नहीं है। SQL सर्वर कभी-कभी प्रदर्शन कारणों से मध्यवर्ती परिणामों को स्पूल करता है, जैसे बार-बार काम करने से बचना (हालांकि वर्तमान में नामित तालिका अभिव्यक्तियों के उपयोग से असंबंधित), और कभी-कभी अन्य कारणों से, जैसे हैलोवीन सुरक्षा।
जैसा कि उल्लेख किया गया है, अगले महीने मैं व्युत्पन्न तालिकाओं को हटाने का विवरण प्राप्त करूंगा। अभी के लिए, यह कहने के लिए पर्याप्त है कि SQL सर्वर सामान्य रूप से व्युत्पन्न तालिकाओं पर एक अननेस्टिंग/इनलाइनिंग प्रक्रिया लागू करता है, जहां यह अंतर्निहित बेस टेबल के विरुद्ध क्वेरी के साथ नेस्टेड प्रश्नों को प्रतिस्थापित करता है। ठीक है, मैं थोड़ा अधिक सरलीकरण कर रहा हूँ। ऐसा नहीं है कि SQL सर्वर मूल T-SQL क्वेरी स्ट्रिंग को व्युत्पन्न तालिकाओं के साथ उनके बिना एक नई क्वेरी स्ट्रिंग में परिवर्तित करता है; बल्कि SQL सर्वर ऑपरेटरों के एक आंतरिक तार्किक पेड़ में परिवर्तन लागू करता है, और परिणाम यह है कि प्रभावी रूप से व्युत्पन्न तालिकाएं आमतौर पर अननेस्टेड हो जाती हैं। जब आप व्युत्पन्न तालिकाओं वाली क्वेरी के लिए निष्पादन योजना को देखते हैं, तो आप उनमें से कोई भी उल्लेख नहीं देखते हैं क्योंकि अधिकांश अनुकूलन उद्देश्यों के लिए वे मौजूद नहीं होते हैं। आप भौतिक संरचनाओं तक पहुंच देखते हैं जो अंतर्निहित आधार तालिकाओं के लिए डेटा रखती हैं (हीप, बी-ट्री रोस्टोर इंडेक्स और डिस्क-आधारित टेबल के लिए कॉलमस्टोर इंडेक्स और मेमोरी अनुकूलित टेबल के लिए ट्री और हैश इंडेक्स)।
ऐसे मामले हैं जो SQL सर्वर को व्युत्पन्न तालिका को अननेस्ट करने से रोकते हैं, लेकिन उन मामलों में भी SQL सर्वर तालिका अभिव्यक्ति के परिणाम को वर्कटेबल में नहीं रखता है। मैं अगले महीने उदाहरणों के साथ विवरण प्रदान करूंगा।
चूंकि SQL सर्वर व्युत्पन्न तालिकाओं को जारी नहीं रखता है, बल्कि भौतिक संरचनाओं के साथ सीधे इंटरैक्ट करता है जो अंतर्निहित आधार तालिकाओं के लिए डेटा रखता है, व्युत्पन्न तालिकाओं के लिए मेमोरी को कैसे संभाला जाता है, यह सवाल विवादास्पद है। यदि अंतर्निहित बेस टेबल डिस्क-आधारित हैं, तो उनके प्रासंगिक पृष्ठों को बफर पूल में संसाधित करने की आवश्यकता है। यदि अंतर्निहित टेबल मेमोरी-अनुकूलित हैं, तो उनकी प्रासंगिक इन-मेमोरी पंक्तियों को संसाधित करने की आवश्यकता है। लेकिन जब आप व्युत्पन्न तालिकाओं का उपयोग किए बिना सीधे अंतर्निहित तालिकाओं को क्वेरी करते हैं तो यह अलग नहीं है। तो यहाँ कुछ खास नहीं है। जब आप व्युत्पन्न तालिकाओं का उपयोग करते हैं, तो SQL सर्वर को उनके लिए कोई विशेष स्मृति विचार लागू करने की आवश्यकता नहीं होती है। अधिकांश क्वेरी अनुकूलन उद्देश्यों के लिए, वे मौजूद नहीं हैं।
यदि आपके पास कोई ऐसा मामला है जहां आपको किसी कार्य तालिका में कुछ मध्यवर्ती चरण के परिणाम को जारी रखने की आवश्यकता है, तो आपको अस्थायी तालिकाओं या तालिका चर का उपयोग करने की आवश्यकता है—न कि तालिका अभिव्यक्तियों का नाम नहीं।
कॉलम प्रोजेक्शन और SELECT पर एक शब्द *
प्रोजेक्शन संबंधपरक बीजगणित के मूल संचालकों में से एक है। मान लीजिए कि x, y और z विशेषताओं के साथ आपका संबंध R1 है। इसकी विशेषताओं के कुछ सबसेट पर R1 का प्रक्षेपण, जैसे, x और z, एक नया संबंध R2 है, जिसका शीर्षक R1 (हमारे मामले में x और z) से अनुमानित विशेषताओं का सबसेट है, और जिसका शरीर टुपल्स का सेट है R1 के टुपल्स से अनुमानित विशेषता मानों के मूल संयोजन से बनता है।
याद रखें कि एक संबंध का शरीर- टुपल्स का एक सेट होने के नाते- परिभाषा के अनुसार कोई डुप्लिकेट नहीं है। तो यह बिना कहे चला जाता है कि परिणाम संबंध के टुपल्स मूल संबंध से अनुमानित विशेषता मूल्यों का विशिष्ट संयोजन हैं। हालाँकि, याद रखें कि SQL में एक तालिका का मुख्य भाग पंक्तियों का एक बहुसमूह है और एक सेट नहीं है, और सामान्य रूप से, SQL डुप्लिकेट पंक्तियों को तब तक समाप्त नहीं करेगा जब तक कि आप इसे निर्देश नहीं देते। कॉलम x, y और z के साथ तालिका R1 को देखते हुए, निम्न क्वेरी संभावित रूप से डुप्लिकेट पंक्तियों को वापस कर सकती है, और इसलिए रिलेशनल बीजगणित के प्रोजेक्शन ऑपरेटर के सेट को वापस करने के शब्दार्थ का पालन नहीं करती है:
सिलेक्ट x, zFROM R1;
DISTINCT क्लॉज जोड़कर, आप डुप्लिकेट पंक्तियों को समाप्त करते हैं, और रिलेशनल प्रोजेक्शन के शब्दार्थ का अधिक बारीकी से पालन करते हैं:
DISTINCT x चुनें, R1 से z;
बेशक, ऐसे कुछ मामले हैं जहां आप जानते हैं कि आपकी क्वेरी के परिणाम में DISTINCT क्लॉज की आवश्यकता के बिना अलग-अलग पंक्तियाँ हैं, उदाहरण के लिए, जब आपके द्वारा लौटाए जा रहे कॉलम के सबसेट में क्वेरी टेबल से एक कुंजी शामिल होती है। उदाहरण के लिए, यदि x R1 में एक कुंजी है, तो उपरोक्त दो प्रश्न तार्किक रूप से समतुल्य हैं।
किसी भी दर पर, उन प्रश्नों को याद करें जिनका मैंने पहले उल्लेख किया था, जो व्युत्पन्न तालिकाओं और कॉलम प्रोजेक्शन से जुड़े प्रश्नों के अनुकूलन के आसपास थे। इंडेक्स मिलान कैसे काम करता है? यदि एक व्युत्पन्न तालिका कुछ अंतर्निहित तालिका से स्तंभों का एक निश्चित सबसेट प्रोजेक्ट करती है, और सबसे बाहरी क्वेरी व्युत्पन्न तालिका से कॉलम का एक सबसेट प्रोजेक्ट करती है, तो SQL सर्वर पर्याप्त रूप से कॉलम के अंतिम सबसेट के आधार पर इष्टतम अनुक्रमण का पता लगाने के लिए पर्याप्त है जो वास्तव में है आवश्यकता है? और अनुमतियों के बारे में क्या; क्या उपयोगकर्ता को उन सभी स्तंभों के लिए अनुमति की आवश्यकता है जो आंतरिक प्रश्नों में संदर्भित हैं, या केवल अंतिम के लिए जिनकी वास्तव में आवश्यकता है? साथ ही, मान लें कि तालिका अभिव्यक्ति क्वेरी एक परिणाम कॉलम को परिभाषित करती है जो गणना पर आधारित है, लेकिन बाहरी क्वेरी उस कॉलम को प्रोजेक्ट नहीं करती है। क्या गणना का मूल्यांकन बिल्कुल किया जाता है?
आखिरी सवाल से शुरू करते हैं, आइए इसे आजमाते हैं। निम्नलिखित प्रश्न पर विचार करें:
TSQLV5 का उपयोग करें; GO SELECT custid, शहर, 1/0 AS div0errorFROM Sales.Customers;
जैसा कि आप उम्मीद करेंगे, यह क्वेरी शून्य त्रुटि से विभाजित होने पर विफल हो जाती है:
संदेश 8134, स्तर 16, राज्य 1शून्य त्रुटि से विभाजित करें।
इसके बाद, उपरोक्त क्वेरी के आधार पर डी नामक एक व्युत्पन्न तालिका को परिभाषित करें, और बाहरी क्वेरी प्रोजेक्ट डी में केवल कस्टिड और शहर पर, जैसे:
सेलेक्ट कस्टिड, सिटीफ्रॉम (सेलेक्ट कस्टिड, सिटी, 1/0 एएस डिव0 फ्रॉम सेल्स। कस्टमर्स) एएस डी;
जैसा कि उल्लेख किया गया है, SQL सर्वर सामान्य रूप से अननेस्टिंग/प्रतिस्थापन लागू करता है, और चूंकि इस क्वेरी में ऐसा कुछ भी नहीं है जो अननेस्टिंग को रोकता है (इस पर अगले महीने अधिक), उपरोक्त क्वेरी निम्न क्वेरी के बराबर है:
सेलेक्ट कस्टिड, सिटीफ्रॉम सेल्स.कस्टमर;
फिर से, मैं यहाँ थोड़ा अधिक सरलीकरण कर रहा हूँ। वास्तविकता इन दो प्रश्नों की तुलना में थोड़ी अधिक जटिल है, जिन्हें वास्तव में समान माना जा रहा है, लेकिन मैं अगले महीने उन जटिलताओं को प्राप्त करूंगा। मुद्दा यह है कि, अभिव्यक्ति 1/0 क्वेरी की निष्पादन योजना में भी दिखाई नहीं देती है, और इसका मूल्यांकन बिल्कुल भी नहीं किया जाता है, इसलिए उपरोक्त क्वेरी बिना किसी त्रुटि के सफलतापूर्वक चलती है।
फिर भी, तालिका अभिव्यक्ति को मान्य होने की आवश्यकता है। उदाहरण के लिए, निम्नलिखित प्रश्न पर विचार करें:
देश से चुनें (बिक्री से चुनें। देश के अनुसार ग्राहक समूह) एएस डी;
भले ही बाहरी क्वेरी आंतरिक क्वेरी के ग्रुपिंग सेट से केवल एक कॉलम प्रोजेक्ट करती है, आंतरिक क्वेरी मान्य नहीं है क्योंकि यह उन कॉलम को वापस करने का प्रयास करती है जो न तो ग्रुपिंग सेट का हिस्सा हैं और न ही एक समग्र फ़ंक्शन में निहित हैं। यह क्वेरी निम्न त्रुटि के साथ विफल हो जाती है:
Msg 8120, Level 16, State 1कॉलम 'Sales.Customers.custid' चयन सूची में अमान्य है क्योंकि यह या तो एक समग्र कार्य या ग्रुप बाय क्लॉज में शामिल नहीं है।
इसके बाद, आइए इंडेक्स मिलान प्रश्न से निपटें। यदि बाहरी क्वेरी केवल व्युत्पन्न तालिका से कॉलम का एक सबसेट प्रोजेक्ट करती है, तो क्या SQL सर्वर केवल लौटाए गए कॉलम के आधार पर इंडेक्स मिलान करने के लिए पर्याप्त स्मार्ट होगा (और निश्चित रूप से कोई अन्य कॉलम जो सार्थक भूमिका निभाता है, जैसे फ़िल्टरिंग, समूह और इतने पर)? लेकिन इससे पहले कि हम इस प्रश्न से निपटें, आपको आश्चर्य हो सकता है कि हम इससे परेशान क्यों हैं। आपके पास आंतरिक क्वेरी रिटर्न कॉलम क्यों होंगे जिनकी बाहरी क्वेरी की आवश्यकता नहीं है?
इसका उत्तर सरल है, आंतरिक क्वेरी को कुख्यात SELECT * का उपयोग करके कोड को छोटा करने के लिए। हम सभी जानते हैं कि SELECT * का उपयोग करना एक बुरा अभ्यास है, लेकिन मुख्य रूप से ऐसा तब होता है जब इसका उपयोग सबसे बाहरी क्वेरी में किया जाता है। क्या होगा यदि आप एक निश्चित शीर्षक वाली तालिका को क्वेरी करते हैं, और बाद में उस शीर्षक को बदल दिया जाता है? एप्लिकेशन बग के साथ समाप्त हो सकता है। यहां तक कि अगर आप बग के साथ समाप्त नहीं होते हैं, तो आप उन कॉलमों को वापस करके अनावश्यक नेटवर्क ट्रैफ़िक उत्पन्न कर सकते हैं जिनकी एप्लिकेशन को वास्तव में आवश्यकता नहीं है। साथ ही, आप ऐसे मामले में इंडेक्सिंग का कम बेहतर उपयोग करते हैं क्योंकि आप वास्तव में आवश्यक कॉलम पर आधारित कवरिंग इंडेक्स के मिलान की संभावना को कम करते हैं।
उस ने कहा, मैं वास्तव में एक तालिका अभिव्यक्ति में SELECT * का उपयोग करके काफी सहज महसूस करता हूं, यह जानकर कि मैं वैसे भी बाहरीतम क्वेरी में केवल वास्तव में आवश्यक कॉलम प्रोजेक्ट करने जा रहा हूं। तार्किक दृष्टिकोण से, यह कुछ मामूली चेतावनियों के साथ बहुत सुरक्षित है, जो मुझे जल्द ही मिल जाएगा। जब तक ऐसे मामले में इंडेक्स मिलान बेहतर तरीके से किया जाता है, और अच्छी खबर है, यह है।
इसे प्रदर्शित करने के लिए, मान लें कि आपको Sales.Orders तालिका को क्वेरी करने की आवश्यकता है, प्रत्येक ग्राहक के लिए सबसे हाल के तीन ऑर्डर लौटाते हुए। आप एक क्वेरी के आधार पर डी नामक एक व्युत्पन्न तालिका को परिभाषित करने की योजना बना रहे हैं जो पंक्ति संख्या (परिणाम कॉलम राउनम) की गणना करता है जिसे कस्टिड द्वारा विभाजित किया जाता है और ऑर्डरडेट डीईएससी, ऑर्डरिड डीईएससी द्वारा आदेश दिया जाता है। बाहरी क्वेरी D से फ़िल्टर होगी (रिलेशनल प्रतिबंध ) केवल पंक्तियाँ जहाँ रौनम 3 से कम या उसके बराबर है, और प्रोजेक्ट डी को कस्टिड, ऑर्डरडेट, ऑर्डरिड और राउनम पर। अब, Sales.Orders में आपके द्वारा प्रोजेक्ट किए जाने वाले स्तंभों की तुलना में अधिक स्तंभ हैं, लेकिन संक्षिप्तता के लिए, आप चाहते हैं कि आंतरिक क्वेरी SELECT *, साथ ही पंक्ति संख्या गणना का उपयोग करे। यह सुरक्षित है और इंडेक्स मिलान के मामले में इसे बेहतर तरीके से हैंडल किया जाएगा।
अपनी क्वेरी का समर्थन करने के लिए इष्टतम कवरिंग इंडेक्स बनाने के लिए निम्नलिखित कोड का उपयोग करें:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(Custid, orderdate DESC, orderid DESC);
यहां वह प्रश्न है जो कार्य को संग्रहीत करता है (हम इसे प्रश्न 1 कहेंगे):
सेलेक्ट कस्टिड, ऑर्डरडेट, ऑर्डरिड, राउनमफ्रॉम (सेलेक्ट *, ROW_NUMBER () ओवर (कस्टिड ऑर्डर बाय ऑर्डरडेट डीईएससी, ऑर्डरिड डीईएससी) एएस राउनम फ्रॉम सेल्स। ऑर्डर) एएस ड्वेयर राउनम <=3;
आंतरिक क्वेरी के SELECT * और बाहरी क्वेरी की स्पष्ट कॉलम सूची पर ध्यान दें।
इस क्वेरी के लिए योजना, जैसा कि SentryOne Plan Explorer द्वारा प्रस्तुत किया गया है, चित्र 1 में दिखाया गया है।
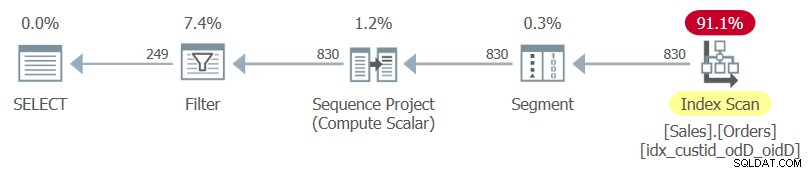 चित्र 1:प्रश्न 1 के लिए योजना
चित्र 1:प्रश्न 1 के लिए योजना
ध्यान दें कि इस योजना में उपयोग किया जाने वाला एकमात्र इंडेक्स इष्टतम कवरिंग इंडेक्स है जिसे आपने अभी बनाया है।
यदि आप केवल आंतरिक क्वेरी को हाइलाइट करते हैं और इसकी निष्पादन योजना की जांच करते हैं, तो आप तालिका के क्लस्टर इंडेक्स को एक सॉर्ट ऑपरेशन के बाद उपयोग करते हुए देखेंगे।
तो यह अच्छी खबर है।
अनुमतियों के लिए, यह एक अलग कहानी है। इंडेक्स मिलान के विपरीत, जहां आपको आंतरिक प्रश्नों द्वारा संदर्भित कॉलम को शामिल करने के लिए इंडेक्स की आवश्यकता नहीं होती है, जब तक कि अंततः उनकी आवश्यकता न हो, आपको सभी संदर्भित कॉलम की अनुमति की आवश्यकता होती है।
इसे प्रदर्शित करने के लिए, उपयोगकर्ता 1 नामक उपयोगकर्ता बनाने के लिए निम्नलिखित कोड का उपयोग करें और कुछ अनुमतियां असाइन करें (बिक्री से सभी कॉलम पर चयन अनुमतियां, और बिक्री से केवल तीन कॉलम पर। ऑर्डर जो अंततः उपरोक्त क्वेरी में प्रासंगिक हैं):/पी>
लॉगिन के बिना उपयोगकर्ता उपयोगकर्ता1 बनाएं; उपयोगकर्ता1 को शोप्लान प्रदान करें; बिक्री पर अनुदान का चयन करें। उपयोगकर्ता 1 को ग्राहक; बिक्री पर अनुदान चयन करें।user1 का रूप धारण करने के लिए निम्न कोड चलाएँ:
EXECUTE AS USER ='user1';Sales.Orders से सभी कॉलम चुनने का प्रयास करें:
बिक्री से *चुनें।आदेश;जैसा कि अपेक्षित था, कुछ स्तंभों पर अनुमतियों की कमी के कारण आपको निम्न त्रुटियाँ मिलती हैं:
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'TSQLV5', स्कीमा 'बिक्री' के कॉलम 'empid' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230 , स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'आवश्यक तिथि' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'TSQLV5', स्कीमा 'बिक्री' के कॉलम 'shippeddate' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'शिपरिड' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'फ्रेट' पर चयन अनुमति को अस्वीकार कर दिया गया था।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपनाम' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपएड्रेस' पर चयन अनुमति को अस्वीकार कर दिया गया था।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'शिपसिटी' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
चयन करें ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपरेगियन' पर अनुमति से इनकार किया गया था।
संदेश 230, स्तर 14, राज्य 1
चयन अनुमति थी ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपपोस्टलकोड' पर अस्वीकृत।
संदेश 230, स्तर 14, राज्य 1
चयन अनुमति ऑब्जेक्ट 'ऑर्डर' का कॉलम 'शिपकाउंट्री', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स'।निम्न क्वेरी का प्रयास करें, केवल उन स्तंभों के साथ प्रोजेक्ट और इंटरैक्ट करें जिनके लिए उपयोगकर्ता1 के पास अनुमतियां हैं:
सेलेक्ट कस्टिड, ऑर्डरडेट, ऑर्डरिड, राउनमफ्रॉम (सेलेक्ट *, ROW_NUMBER () ओवर (कस्टिड ऑर्डर बाय ऑर्डरडेट डीईएससी, ऑर्डरिड डीईएससी) एएस राउनम फ्रॉम सेल्स। ऑर्डर) एएस ड्वेयर राउनम <=3;फिर भी, आपको कुछ कॉलम पर अनुमतियों की कमी के कारण कॉलम अनुमति त्रुटियां मिलती हैं, जिन्हें आंतरिक क्वेरी द्वारा इसके SELECT *:
के माध्यम से संदर्भित किया जाता है। संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'TSQLV5', स्कीमा 'बिक्री' के कॉलम 'empid' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230 , स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'आवश्यक तिथि' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'TSQLV5', स्कीमा 'बिक्री' के कॉलम 'shippeddate' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'आदेश', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'शिपरिड' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'फ्रेट' पर चयन अनुमति को अस्वीकार कर दिया गया था।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपनाम' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपएड्रेस' पर चयन अनुमति को अस्वीकार कर दिया गया था।
संदेश 230, स्तर 14, राज्य 1
ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'बिक्री' के कॉलम 'शिपसिटी' पर चयन अनुमति अस्वीकार कर दी गई थी।
संदेश 230, स्तर 14, राज्य 1
चयन करें ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपरेगियन' पर अनुमति से इनकार किया गया था।
संदेश 230, स्तर 14, राज्य 1
चयन अनुमति थी ऑब्जेक्ट 'ऑर्डर', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स' के कॉलम 'शिपपोस्टलकोड' पर अस्वीकृत।
संदेश 230, स्तर 14, राज्य 1
चयन अनुमति ऑब्जेक्ट 'ऑर्डर' का कॉलम 'शिपकाउंट्री', डेटाबेस 'टीएसक्यूएलवी5', स्कीमा 'सेल्स'।यदि वास्तव में आपकी कंपनी में उपयोगकर्ताओं को केवल प्रासंगिक कॉलम पर अनुमतियां असाइन करने का अभ्यास है, जिनके साथ उन्हें बातचीत करने की आवश्यकता है, तो थोड़ा सा लंबा कोड का उपयोग करना समझ में आता है, और आंतरिक और बाहरी दोनों प्रश्नों में कॉलम सूची के बारे में स्पष्ट होना चाहिए, इस तरह:
सेलेक्ट कस्टिड, ऑर्डरडेट, ऑर्डरिड, राउनमफ्रॉम (सेलेक्ट कस्टिड, ऑर्डरडेट, ऑर्डरिड, ROW_NUMBER() ओवर (कस्टिड ऑर्डर द्वारा ऑर्डरडेट डीईएससी, ऑर्डरिड डीईएससी) सेल्स से राउनम के रूप में। /पूर्व>इस बार, क्वेरी बिना किसी त्रुटि के चलती है।
एक अन्य भिन्नता जिसके लिए उपयोगकर्ता को केवल प्रासंगिक कॉलम पर अनुमति की आवश्यकता होती है, वह है आंतरिक क्वेरी की SELECT सूची में कॉलम नामों के बारे में स्पष्ट होना, और बाहरी क्वेरी में SELECT * का उपयोग करना, जैसे:
सेलेक्ट *FROM (सेलेक्ट कस्टिड, ऑर्डरडेट, ऑर्डरिड, ROW_NUMBER() ओवर (कस्टिड ऑर्डर द्वारा ऑर्डरडेट डीईएससी, ऑर्डरिड डीईएससी) सेल्स से राउनम के रूप में। ऑर्डर) एएस ड्वेयर राउनम <=3;यह क्वेरी भी त्रुटियों के बिना चलती है। हालांकि, मैं इस संस्करण को एक ऐसे संस्करण के रूप में देखता हूं जो बाद में घोंसले के कुछ आंतरिक स्तर में कुछ बदलाव किए जाने पर बग के लिए प्रवण होता है। जैसा कि पहले उल्लेख किया गया है, मेरे लिए सबसे अच्छा अभ्यास सबसे बाहरी क्वेरी में कॉलम सूची के बारे में स्पष्ट होना है। इसलिए जब तक आपको कुछ कॉलम पर अनुमति की कमी के बारे में कोई चिंता नहीं है, मैं आंतरिक प्रश्नों में SELECT * के साथ सहज महसूस करता हूं, लेकिन सबसे बाहरी क्वेरी में एक स्पष्ट कॉलम सूची। यदि कंपनी में विशिष्ट कॉलम अनुमतियों को लागू करना एक सामान्य प्रथा है, तो नेस्टिंग के सभी स्तरों में कॉलम नामों के बारे में स्पष्ट होना सबसे अच्छा है। ध्यान रहे, नेस्टिंग के सभी स्तरों में कॉलम नामों के बारे में स्पष्ट होना वास्तव में अनिवार्य है यदि आपकी क्वेरी का उपयोग स्कीमा बाउंड ऑब्जेक्ट में किया जाता है, क्योंकि स्कीमा बाइंडिंग क्वेरी में कहीं भी SELECT * के उपयोग की अनुमति नहीं देती है।
इस बिंदु पर, आपके द्वारा पहले Sales.Orders पर बनाए गए अनुक्रमणिका को निकालने के लिए निम्न कोड चलाएँ:
ड्रॉप इंडेक्स अगर बिक्री पर idx_custid_odD_oidD मौजूद है। ऑर्डर;SELECT * का उपयोग करने की वैधता से संबंधित इसी तरह की दुविधा के साथ एक और मामला है; EXISTS विधेय की आंतरिक क्वेरी में।
निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 2 कहेंगे):
सेल्स से custid चुनें। CWHERE के रूप में ग्राहक मौजूद हैं (सेल्स से चुनें। O.custid =C.custid के रूप में ऑर्डर);इस क्वेरी की योजना चित्र 2 में दिखाई गई है।
चित्र 2:क्वेरी 2 के लिए योजना
अनुक्रमणिका मिलान लागू करते समय, अनुकूलक को लगा कि अनुक्रमणिका idx_nc_custid Sales पर एक आवरण अनुक्रमणिका है। आदेश क्योंकि इसमें कस्टिड स्तंभ है—इस क्वेरी में एकमात्र सही प्रासंगिक स्तंभ है। यह इस तथ्य के बावजूद है कि इस इंडेक्स में कस्टिड के अलावा कोई अन्य कॉलम नहीं है, और यह कि EXISTS विधेय में आंतरिक क्वेरी SELECT * कहती है। अब तक, व्यवहार व्युत्पन्न तालिकाओं में SELECT * के उपयोग के समान लगता है।
इस क्वेरी के साथ जो अलग है वह यह है कि यह त्रुटियों के बिना चलती है, इस तथ्य के बावजूद कि उपयोगकर्ता 1 के पास Sales.Orders के कुछ स्तंभों पर अनुमति नहीं है। यहां सभी स्तंभों पर अनुमतियों की आवश्यकता नहीं होने का औचित्य साबित करने का तर्क है। आखिरकार, EXISTS विधेय को केवल मिलान पंक्तियों के अस्तित्व की जांच करने की आवश्यकता है, इसलिए आंतरिक क्वेरी की चयन सूची वास्तव में अर्थहीन है। यह शायद सबसे अच्छा होता अगर SQL को ऐसे मामले में SELECT सूची की आवश्यकता नहीं होती, लेकिन वह जहाज पहले ही रवाना हो चुका होता है। अच्छी खबर यह है कि चयन सूची को प्रभावी ढंग से नजरअंदाज कर दिया गया है - दोनों सूचकांक मिलान और आवश्यक अनुमतियों के संदर्भ में।
यह भी प्रतीत होता है कि आंतरिक क्वेरी में SELECT * का उपयोग करते समय व्युत्पन्न तालिकाओं और EXISTS के बीच एक और अंतर है। इस प्रश्न को पहले लेख में याद रखें:
देश से चुनें (बिक्री से चुनें। देश के अनुसार ग्राहक समूह) एएस डी;यदि आपको याद है, तो इस कोड ने एक त्रुटि उत्पन्न की क्योंकि आंतरिक क्वेरी अमान्य है।
वही आंतरिक क्वेरी आज़माएं, केवल इस बार EXISTS विधेय में (हम इस कथन को 3 कहेंगे):
यदि मौजूद है (देश के अनुसार बिक्री से चुनें * ग्राहक समूह) प्रिंट करें 'यह काम करता है! टिप के लिए धन्यवाद दिमित्री कोरोटकेविच!';अजीब तरह से, SQL सर्वर इस कोड को मान्य मानता है, और यह सफलतापूर्वक चलता है। इस कोड की योजना चित्र 3 में दिखाई गई है।
चित्र 3:विवरण 3 के लिए योजना
यह योजना उस योजना के समान है जो आपको तब मिलेगी जब आंतरिक प्रश्न केवल बिक्री से चुनें *। ग्राहक (ग्रुप बाय के बिना)। आखिरकार, आप समूहों के अस्तित्व की जाँच कर रहे हैं, और यदि पंक्तियाँ हैं, तो स्वाभाविक रूप से समूह हैं। वैसे भी, मुझे लगता है कि तथ्य यह है कि SQL सर्वर इस क्वेरी को मान्य मानता है एक बग है। निश्चित रूप से, SQL कोड मान्य होना चाहिए! लेकिन मैं देख सकता हूं कि कुछ लोग यह तर्क क्यों दे सकते हैं कि EXISTS क्वेरी में चयन सूची को अनदेखा किया जाना चाहिए। किसी भी दर पर, योजना एक प्रोबेड लेफ्ट सेमी जॉइन का उपयोग करती है, जिसमें किसी भी कॉलम को वापस करने की आवश्यकता नहीं होती है, बल्कि किसी भी पंक्तियों के अस्तित्व की जांच के लिए केवल एक तालिका की जांच करें। ग्राहकों पर सूचकांक कोई भी सूचकांक हो सकता है।
इस बिंदु पर आप उपयोगकर्ता 1 का प्रतिरूपण रोकने और उसे छोड़ने के लिए निम्न कोड चला सकते हैं:
वापसी; उपयोगकर्ता को छोड़ दें यदि उपयोगकर्ता 1 मौजूद है;इस तथ्य पर वापस जाएं कि मुझे लगता है कि घोंसले के आंतरिक स्तरों में SELECT * का उपयोग करना एक सुविधाजनक अभ्यास है, आपके पास जितने अधिक स्तर होंगे, उतना ही यह अभ्यास आपके कोड को छोटा और सरल करेगा। यहां दो नेस्टिंग स्तरों वाला एक उदाहरण दिया गया है:
सेलेक्ट ऑर्डरिड, ऑर्डरइयर, कस्टिड, एम्पिड, शिपरिडफ्रॉम (सेलेक्ट *, डेटफ्रॉमपार्ट्स (ऑर्डरइयर, 12, 31) से एंडोफियर फ्रॉम (सेलेक्ट *, ईयर (ऑर्डरडेट) एएस ऑर्डर ईयर फ्रॉम सेल्स। ऑर्डर) एएस डी1 ) डी 2 के रूप में ऑर्डरडेट =एंडोफियर;ऐसे मामले हैं जहां इस अभ्यास का उपयोग नहीं किया जा सकता है। उदाहरण के लिए, जब आंतरिक क्वेरी सामान्य कॉलम नामों वाली तालिकाओं में शामिल होती है, जैसे निम्न उदाहरण में:
सेलेक्ट कस्टिड, कंपनी का नाम, ऑर्डरडेट, ऑर्डरिड, राउनमफ्रॉम ( सेलेक्ट *, ROW_NUMBER() ओवर (सी.कस्टिड ऑर्डर द्वारा O.orderdate DESC, O.orderid DESC) सेल्स से राउनम के रूप में। C LEFT OUTER JOIN के रूप में ग्राहक सेल्स.ऑर्डर्स ओ ऑन सी.कस्टिड =ओ.कस्टिड ) जहां ड्वेयर रौनम <=3;Sales.Customers और Sales.Orders दोनों में custid नामक एक कॉलम होता है। आप एक टेबल एक्सप्रेशन का उपयोग कर रहे हैं जो व्युत्पन्न तालिका डी को परिभाषित करने के लिए दो तालिकाओं के बीच जुड़ने पर आधारित है। याद रखें कि तालिका का शीर्षक कॉलम का एक सेट है, और एक सेट के रूप में, आपके पास डुप्लिकेट कॉलम नाम नहीं हो सकते हैं। इसलिए, यह क्वेरी निम्न त्रुटि के साथ विफल हो जाती है:
संदेश 8156, स्तर 16, राज्य 1
कॉलम 'कस्टिड' को 'डी' के लिए कई बार निर्दिष्ट किया गया था।यहां, आपको आंतरिक क्वेरी में कॉलम नामों के बारे में स्पष्ट होना चाहिए, और सुनिश्चित करें कि आप या तो केवल एक टेबल से custid लौटाते हैं, या यदि आप दोनों को वापस करना चाहते हैं तो परिणाम कॉलम में अद्वितीय कॉलम नाम असाइन करें। अधिक बार आप पूर्व दृष्टिकोण का उपयोग करेंगे, जैसे:
सेलेक्ट कस्टिड, कंपनीनाम, ऑर्डरडेट, ऑर्डरिड, राउनमफ्रॉम (सेलेक्ट सी.कस्टिड, सी.कंपनीनाम, ओ.ऑर्डरडेट, ओ.ऑर्डरिड, ROW_NUMBER() ओवर (सी.कस्टिड द्वारा पार्टिशन ऑर्डर द्वारा ओ.ऑर्डरडेट डीईएससी, ओ। ऑर्डरिड डीईएससी) बिक्री से रौनम के रूप में। ग्राहक सी बाएं बाहरी के रूप में बिक्री में शामिल होते हैं। सी.कस्टिड =ओ.कस्टिड के रूप में ऑर्डर ) ड्वेयर रॉनम <=3;के रूप मेंफिर से, आप आंतरिक क्वेरी में कॉलम नामों के साथ स्पष्ट हो सकते हैं और बाहरी क्वेरी में SELECT * का उपयोग कर सकते हैं, जैसे:
सेलेक्ट *से (सेलेक्ट C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION by C.custid ORDER BY O.orderdate DESC, O.orderid DESC) बिक्री से rownum के रूप में .C LEFT OUTER के रूप में ग्राहक बिक्री में शामिल होते हैं। C.custid =O.custid पर O के रूप में आदेश ) DWHERE rownum <=3;के रूप मेंलेकिन जैसा कि मैंने पहले उल्लेख किया है, मैं इसे सबसे बाहरी क्वेरी में कॉलम नामों के बारे में स्पष्ट नहीं होना एक बुरा अभ्यास मानता हूं।
स्तंभ उपनामों के अनेक संदर्भ
आइए अगले आइटम पर आगे बढ़ें- व्युत्पन्न तालिका कॉलम के कई संदर्भ। यदि व्युत्पन्न तालिका में एक परिणाम स्तंभ है जो एक गैर-निर्धारिती गणना पर आधारित है, और बाहरी क्वेरी में उस स्तंभ के कई संदर्भ हैं, तो क्या गणना का मूल्यांकन प्रत्येक संदर्भ के लिए केवल एक बार या अलग से किया जाएगा?
आइए इस तथ्य से शुरू करें कि एक प्रश्न में एक ही नोडेटर्मिनिस्टिक फ़ंक्शन के कई संदर्भों का स्वतंत्र रूप से मूल्यांकन किया जाना चाहिए। एक उदाहरण के रूप में निम्नलिखित प्रश्न पर विचार करें:
चुनें NEWID() mynewid1, NEWID() AS mynewid2;यह कोड दो अलग-अलग GUID दिखाते हुए निम्नलिखित आउटपुट उत्पन्न करता है:
mynewid1 mynewid2---------------------------------------------------- ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406इसके विपरीत, यदि आपके पास एक स्तंभ के साथ एक व्युत्पन्न तालिका है जो एक गैर-निर्धारक गणना पर आधारित है, और बाहरी क्वेरी में उस कॉलम के कई संदर्भ हैं, तो गणना का मूल्यांकन केवल एक बार किया जाना चाहिए। निम्नलिखित प्रश्न पर विचार करें (हम इस प्रश्न 4 को कॉल करेंगे):
mynewid AS mynewid1, mynewid AS mynewid2FROM (चुनें NEWID() as mynewid ) AS D;इस क्वेरी की योजना चित्र 4 में दिखाई गई है।
चित्र 4:क्वेरी 4 के लिए योजना
ध्यान दें कि योजना में NEWID फ़ंक्शन का केवल एक आह्वान है। तदनुसार, आउटपुट एक ही GUID को दो बार दिखाता है:
mynewid1 mynewid2---------------------------------------------------- ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74Aइसलिए, उपरोक्त दो प्रश्न तार्किक रूप से समान नहीं हैं, और ऐसे मामले हैं जहां इनलाइनिंग/प्रतिस्थापन नहीं होता है।
कुछ गैर-नियतात्मक कार्यों के साथ यह प्रदर्शित करना थोड़ा मुश्किल है कि एक क्वेरी में कई आमंत्रण अलग से संभाले जाते हैं। एक उदाहरण के रूप में SYSDATETIME फ़ंक्शन को लें। इसमें 100 नैनोसेकंड परिशुद्धता है। क्या संभावना है कि निम्नलिखित जैसी क्वेरी वास्तव में दो अलग-अलग मान दिखाएगी?
SYSDATETIME() को mydt1, SYSDATETIME() AS mydt2 के रूप में चुनें;यदि आप ऊब चुके हैं, तो ऐसा होने तक आप F5 को बार-बार हिट कर सकते हैं। यदि आपके पास अपने समय के साथ करने के लिए अधिक महत्वपूर्ण चीजें हैं, तो आप एक लूप चलाना पसंद कर सकते हैं, जैसे:
DECLARE @i AS INT =1; जबकि मौजूद है (चुनें * से (चुनें SYSDATETIME() mydt1, SYSDATETIME() AS mydt2 के रूप में) डी के रूप में जहां mydt1 =mydt2) सेट @i + =1; प्रिंट @i;उदाहरण के लिए, जब मैंने यह कोड चलाया, तो मुझे 1971 मिला।
यदि आप यह सुनिश्चित करना चाहते हैं कि nondeterministic फ़ंक्शन केवल एक बार लागू किया गया है, और एकाधिक क्वेरी संदर्भों में समान मान पर भरोसा करते हैं, तो सुनिश्चित करें कि आप फ़ंक्शन आमंत्रण के आधार पर कॉलम के साथ तालिका अभिव्यक्ति परिभाषित करते हैं, और उस कॉलम के एकाधिक संदर्भ हैं बाहरी क्वेरी से, जैसे (हम इस प्रश्न 5 को कॉल करेंगे):
mydt AS mydt1, mydt AS mydt1FROM चुनें (SYSDATETIME() AS mydt चुनें) AS D;इस क्वेरी की योजना चित्र 5 में दिखाई गई है।
चित्र 5:प्रश्न 5 के लिए योजना
योजना में ध्यान दें कि फ़ंक्शन केवल एक बार लागू होता है।
अब यह रोगियों में F5 को बार-बार हिट करने के लिए वास्तव में एक दिलचस्प अभ्यास हो सकता है जब तक कि आपको दो अलग-अलग मान न मिलें। The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;सारांश
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.