ANY एग्रीगेट ऐसा कुछ नहीं है जिसे हम सीधे ट्रांजैक्ट एसक्यूएल में लिख सकते हैं। यह केवल एक आंतरिक विशेषता है जिसका उपयोग क्वेरी अनुकूलक और निष्पादन इंजन द्वारा किया जाता है।
मैं व्यक्तिगत रूप से ANY का काफी शौकीन हूं कुल मिलाकर, इसलिए यह जानना थोड़ा निराशाजनक था कि यह काफी मौलिक तरीके से टूटा हुआ है। मैं यहां जिस 'टूटे' स्वाद की बात कर रहा हूं, वह गलत-परिणाम वाली किस्म है।
इस पोस्ट में, मैं दो विशेष स्थानों पर एक नज़र डालता हूँ जहाँ ANY समुच्चय सामान्य रूप से दिखाई देता है, गलत परिणाम की समस्या प्रदर्शित करता है, और जहां आवश्यक हो समाधान सुझाता है।
पृष्ठभूमि के लिए ANY कुल, कृपया मेरी पिछली पोस्ट देखें अनिर्दिष्ट प्रश्न योजनाएं:कोई भी कुल।
1. प्रति समूह क्वेरी एक पंक्ति
यह एक बहुत ही प्रसिद्ध समाधान के साथ सबसे आम दिन-आज की क्वेरी आवश्यकताओं में से एक होना चाहिए। आप शायद इस तरह की क्वेरी हर दिन लिखते हैं, स्वचालित रूप से पैटर्न का पालन करते हुए, वास्तव में इसके बारे में सोचे बिना।
विचार ROW_NUMBER . का उपयोग करके पंक्तियों के इनपुट सेट को क्रमांकित करना है विंडो फ़ंक्शन, ग्रुपिंग कॉलम या कॉलम द्वारा विभाजित। यह एक सामान्य तालिका अभिव्यक्ति . में लिपटा हुआ है या व्युत्पन्न तालिका , और उन पंक्तियों तक फ़िल्टर किया जाता है जहां परिकलित पंक्ति संख्या एक के बराबर होती है। चूंकि ROW_NUMBER प्रत्येक समूह के लिए एक पर पुनरारंभ होता है, यह हमें प्रति समूह आवश्यक एक पंक्ति देता है।
उस सामान्य पैटर्न में कोई समस्या नहीं है। प्रति समूह क्वेरी एक पंक्ति का प्रकार जो ANY . के अधीन है समग्र समस्या वह है जहां हम इस बात की परवाह नहीं करते कि कौन सी विशेष पंक्ति चुनी गई है प्रत्येक समूह से।
उस स्थिति में, यह स्पष्ट नहीं है कि अनिवार्य ORDER BY . में किस कॉलम का उपयोग किया जाना चाहिए ROW_NUMBER . का खंड खिड़की समारोह। आखिरकार, हम स्पष्ट रूप से परवाह नहीं करते कौन सी पंक्ति चुनी गई है। PARTITION BY का पुन:उपयोग करना एक सामान्य तरीका है ORDER BY में कॉलम (स्तंभों) खंड। यहीं समस्या हो सकती है।
उदाहरण
आइए एक खिलौना डेटा सेट का उपयोग करके एक उदाहरण देखें:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
आवश्यकता प्रत्येक समूह से डेटा की किसी एक पूरी पंक्ति को वापस करने की है, जहां समूह सदस्यता को कॉलम c1 में मान द्वारा परिभाषित किया गया है ।

ROW_NUMBER का अनुसरण कर रहे हैं पैटर्न, हम निम्नलिखित की तरह एक प्रश्न लिख सकते हैं (ORDER BY . पर ध्यान दें ROW_NUMBER . का खंड विंडो फ़ंक्शन PARTITION BY से मेल खाता है खंड):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
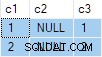
N.rn = 1; जैसा कि प्रस्तुत किया गया है, यह क्वेरी सही परिणामों के साथ सफलतापूर्वक निष्पादित होती है। परिणाम तकनीकी रूप से गैर-नियतात्मक हैं चूंकि SQL सर्वर प्रत्येक समूह में पंक्तियों में से किसी एक को वैध रूप से वापस कर सकता है। फिर भी, यदि आप इस क्वेरी को स्वयं चलाते हैं, तो आपको वही परिणाम दिखाई देने की संभावना है जो मैं करता हूं:
निष्पादन योजना उपयोग किए गए SQL सर्वर के संस्करण पर निर्भर करती है, और डेटाबेस संगतता स्तर पर निर्भर नहीं करती है।
SQL सर्वर 2014 और इससे पहले की योजना है:

SQL सर्वर 2016 या बाद के संस्करण के लिए, आप देखेंगे:

दोनों प्लान सुरक्षित हैं, लेकिन अलग-अलग कारणों से। विभिन्न प्रकार योजना में एक ANY शामिल है समुच्चय, लेकिन विशिष्ट प्रकार ऑपरेटर कार्यान्वयन बग प्रकट नहीं करता है।
अधिक जटिल SQL सर्वर 2016+ योजना ANY . का उपयोग नहीं करती है कुल मिलाकर। क्रमबद्ध करें पंक्ति क्रमांकन संचालन के लिए आवश्यक क्रम में पंक्तियों को रखता है। सेगमेंट ऑपरेटर प्रत्येक नए समूह की शुरुआत में एक ध्वज सेट करता है। अनुक्रम प्रोजेक्ट पंक्ति संख्या की गणना करता है। अंत में, फ़िल्टर ऑपरेटर केवल उन्हीं पंक्तियों को पास करता है जिनकी गणना की गई पंक्ति संख्या एक है।
बग
इस डेटा सेट के साथ गलत परिणाम प्राप्त करने के लिए, हमें SQL सर्वर 2014 या इससे पहले के संस्करण और ANY का उपयोग करने की आवश्यकता है एग्रीगेट को स्ट्रीम एग्रीगेट . में लागू करने की ज़रूरत है या उत्सुक हैश एग्रीगेट ऑपरेटर (फ्लो डिस्टिंक्ट हैश मैच एग्रीगेट बग उत्पन्न नहीं करता)।
ऑप्टिमाइज़र को स्ट्रीम एग्रीगेट . चुनने के लिए प्रोत्साहित करने का एक तरीका विभिन्न प्रकार . के बजाय कॉलम c1 . द्वारा ऑर्डरिंग प्रदान करने के लिए क्लस्टर इंडेक्स जोड़ना है :
CREATE CLUSTERED INDEX c ON #Data (c1);
उस परिवर्तन के बाद, निष्पादन योजना बन जाती है:

ANY समुच्चय गुणों . में दृश्यमान हैं विंडो जब स्ट्रीम एग्रीगेट ऑपरेटर चुना गया है:

क्वेरी का परिणाम है:
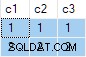
यह गलत है . SQL सर्वर ने उन पंक्तियों को लौटा दिया है जो मौजूद नहीं हैं स्रोत डेटा में। कोई स्रोत पंक्तियाँ नहीं हैं जहाँ c2 = 1 और c3 = 1 उदाहरण के लिए। एक अनुस्मारक के रूप में, स्रोत डेटा है:
निष्पादन योजना गलती से अलग की गणना करती है ANY c2 . के लिए समुच्चय और c3 कॉलम, नल की अनदेखी। प्रत्येक समुच्चय स्वतंत्र रूप से पहला गैर-शून्य लौटाता है मान इसका सामना करता है, एक परिणाम देता है जहां c2 . के लिए मान और c3 विभिन्न स्रोत पंक्तियों . से आते हैं . यह मूल SQL क्वेरी विनिर्देशन का अनुरोध नहीं है।
वही गलत परिणाम साथ या बिना उत्पन्न किया जा सकता है एक OPTION (HASH GROUP) adding जोड़कर संकुल अनुक्रमणिका ईजर हैश एग्रीगेट . के साथ एक योजना तैयार करने का संकेत स्ट्रीम एग्रीगेट . के बजाय ।
शर्तें
यह समस्या तभी हो सकती है जब एक से अधिक ANY समुच्चय मौजूद हैं, और समेकित डेटा में शून्य है। जैसा कि नोट किया गया है, समस्या केवल स्ट्रीम एग्रीगेट . को प्रभावित करती है और उत्सुक हैश एग्रीगेट ऑपरेटरों; अलग क्रमबद्ध करें और विभिन्न प्रवाह प्रभावित नहीं हैं।
SQL सर्वर 2016 आगे कई ANY introducing शुरू करने से बचने का प्रयास करता है स्रोत कॉलम अशक्त होने पर किसी एक पंक्ति प्रति समूह पंक्ति क्रमांकन क्वेरी पैटर्न के लिए समुच्चय। जब ऐसा होता है, तो निष्पादन योजना में सेगमेंट . होगा , अनुक्रम परियोजना , और फ़िल्टर करें कुल के बजाय ऑपरेटरों। यह योजना आकार हमेशा सुरक्षित है, क्योंकि कोई ANY नहीं है समुच्चय का उपयोग किया जाता है।
SQL Server 2016+ में बग को पुन:प्रस्तुत करना
SQL सर्वर ऑप्टिमाइज़र यह पता लगाने में सही नहीं है कि एक कॉलम मूल रूप से NOT NULL होने के लिए बाध्य है। डेटा हेरफेर के माध्यम से अभी भी एक शून्य मध्यवर्ती मान उत्पन्न कर सकता है।
इसे पुन:पेश करने के लिए, हम एक तालिका से शुरू करेंगे जहां सभी कॉलम NOT NULL . के रूप में घोषित किए गए हैं :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
हम इस डेटा सेट से कई तरह से नल उत्पन्न कर सकते हैं, जिनमें से अधिकांश को ऑप्टिमाइज़र सफलतापूर्वक पता लगा सकता है, और इसलिए ANY शुरू करने से बचें। अनुकूलन के दौरान समुच्चय।
रडार के नीचे खिसकने वाले नल को जोड़ने का एक तरीका नीचे दिखाया गया है:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; वह क्वेरी निम्न आउटपुट उत्पन्न करती है:
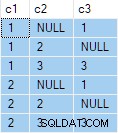
अगला कदम उस क्वेरी विनिर्देश का उपयोग मानक "किसी भी एक पंक्ति प्रति समूह" क्वेरी के स्रोत डेटा के रूप में करना है:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; किसी भी संस्करण . पर SQL सर्वर का, जो निम्न योजना तैयार करता है:
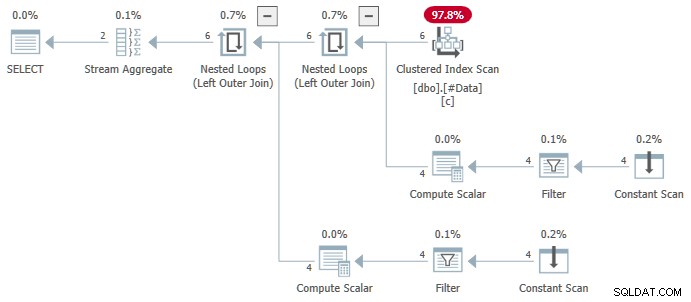
स्ट्रीम एग्रीगेट एकाधिक ANY शामिल हैं समुच्चय, और परिणाम गलत . है . लौटाई गई पंक्तियों में से कोई भी स्रोत डेटा सेट में दिखाई नहीं देती है:
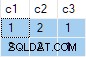
db<>fiddle ऑनलाइन डेमो
समाधान
इस बग के ठीक होने तक एकमात्र पूर्ण विश्वसनीय समाधान उस पैटर्न से बचना है जहां ROW_NUMBER ORDER BY . में एक ही कॉलम है क्लॉज जैसा कि PARTITION BY में है खंड।
जब हमें परवाह नहीं है किससे प्रत्येक समूह से एक पंक्ति का चयन किया जाता है, यह दुर्भाग्यपूर्ण है कि ORDER BY खंड की बिल्कुल जरूरत है। समस्या को दूर करने का एक तरीका ORDER BY @@SPID जैसे रन टाइम स्थिरांक का उपयोग करना है विंडो फ़ंक्शन में।
2. गैर-नियतात्मक अद्यतन
एकाधिक ANY के साथ समस्या अशक्त इनपुट पर समुच्चय प्रति समूह क्वेरी पैटर्न किसी एक पंक्ति तक सीमित नहीं है। क्वेरी ऑप्टिमाइज़र एक आंतरिक ANY पेश कर सकता है कई परिस्थितियों में एकत्र। उन मामलों में से एक गैर-नियतात्मक अद्यतन है।
एक गैर-नियतात्मक अद्यतन वह जगह है जहाँ कथन इस बात की गारंटी नहीं देता है कि प्रत्येक लक्ष्य पंक्ति को अधिकतम एक बार अद्यतन किया जाएगा। दूसरे शब्दों में, कम से कम एक लक्ष्य पंक्ति के लिए कई स्रोत पंक्तियाँ हैं। दस्तावेज़ीकरण इस बारे में स्पष्ट रूप से चेतावनी देता है:
अपडेट ऑपरेशन के लिए मानदंड प्रदान करने के लिए FROM क्लॉज को निर्दिष्ट करते समय सावधानी बरतें।एक अद्यतन विवरण के परिणाम अपरिभाषित होते हैं यदि कथन में एक FROM खंड शामिल है जो इस तरह से निर्दिष्ट नहीं है कि अद्यतन किए जाने वाले प्रत्येक स्तंभ घटना के लिए केवल एक मान उपलब्ध है, कि अगर अद्यतन विवरण नियतात्मक नहीं है।
एक गैर-नियतात्मक अद्यतन को संभालने के लिए, ऑप्टिमाइज़र पंक्तियों को एक कुंजी (इंडेक्स या आरआईडी) द्वारा समूहित करता है और ANY लागू करता है शेष स्तंभों के लिए समुच्चय। कई उम्मीदवारों में से एक पंक्ति का चयन करने और अद्यतन करने के लिए उस पंक्ति के मानों का उपयोग करने का मूल विचार है। पिछले ROW_NUMBER . से स्पष्ट समानताएं हैं समस्या है, इसलिए इसमें कोई आश्चर्य की बात नहीं है कि गलत अपडेट प्रदर्शित करना काफी आसान है।
पिछले मुद्दे के विपरीत, SQL सर्वर वर्तमान में कोई विशेष कदम नहीं लेता है एकाधिक ANY से बचने के लिए गैर-नियतात्मक अद्यतन करते समय अशक्त स्तंभों पर एकत्र करता है। इसलिए निम्नलिखित सभी SQL सर्वर संस्करणों से संबंधित है , SQL सर्वर 2019 CTP 3.0 सहित।
उदाहरण
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>fiddle ऑनलाइन डेमो
तार्किक रूप से, इस अद्यतन को हमेशा एक त्रुटि उत्पन्न करनी चाहिए:लक्ष्य तालिका किसी भी कॉलम में नल की अनुमति नहीं देती है। स्रोत तालिका से जो भी मिलान पंक्ति चुनी जाती है, कॉलम को अपडेट करने का प्रयास c2 या c3 शून्य करने के लिए जरूरी होता है।
दुर्भाग्य से, अद्यतन सफल होता है, और लक्ष्य तालिका की अंतिम स्थिति आपूर्ति किए गए डेटा के साथ असंगत होती है:
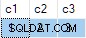
मैंने इसे एक बग के रूप में रिपोर्ट किया है। गैर-नियतात्मक UPDATE लिखने से बचने के लिए वैकल्पिक उपाय है बयान, इसलिए ANY अस्पष्टता को हल करने के लिए समुच्चय की आवश्यकता नहीं है।
जैसा कि उल्लेख किया गया है, SQL सर्वर ANY पेश कर सकता है यहां दिए गए दो उदाहरणों की तुलना में अधिक परिस्थितियों में समुच्चय। अगर ऐसा तब होता है जब एग्रीगेट किए गए कॉलम में नल होते हैं, तो गलत नतीजों की संभावना होती है.