यह आलेख दिखाता है कि SQL सर्वर एकाधिक स्तंभों पर एकत्रीकरण के लिए कार्डिनैलिटी अनुमान उत्पन्न करने के लिए एकाधिक एकल-स्तंभ आंकड़ों से घनत्व जानकारी को कैसे जोड़ता है। विवरण उम्मीद से अपने आप में दिलचस्प हैं। वे कार्डिनैलिटी अनुमानक द्वारा उपयोग किए जाने वाले कुछ सामान्य दृष्टिकोणों और एल्गोरिदम में भी अंतर्दृष्टि प्रदान करते हैं।
निम्नलिखित एडवेंचरवर्क्स नमूना डेटाबेस क्वेरी पर विचार करें, जो वेयरहाउस में प्रत्येक शेल्फ पर प्रत्येक बिन में उत्पाद इन्वेंट्री आइटम की संख्या सूचीबद्ध करती है:
Inv.Shelf, INV.Bin, COUNT_BIG(*) Production से चुनेंअनुमानित निष्पादन योजना तालिका से पढ़ी जा रही 1,069 पंक्तियों को दिखाती है, जिन्हें
Shelf. में क्रमबद्ध किया गया है औरBinआदेश, फिर एक स्ट्रीम एग्रीगेट ऑपरेटर का उपयोग करके एकत्र किया गया: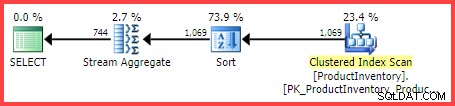
अनुमानित निष्पादन योजना
सवाल यह है कि SQL सर्वर क्वेरी ऑप्टिमाइज़र 744 पंक्तियों के अंतिम अनुमान पर कैसे पहुंचा?
उपलब्ध आंकड़े
उपरोक्त क्वेरी को संकलित करते समय, क्वेरी ऑप्टिमाइज़र
Shelfपर एकल-स्तंभ आँकड़े बनाएगा औरBinकॉलम, यदि उपयुक्त आँकड़े पहले से मौजूद नहीं हैं। अन्य बातों के अलावा, ये आंकड़े अलग-अलग कॉलम मानों की संख्या (घनत्व वेक्टर में) के बारे में जानकारी प्रदान करते हैं:डीबीसीसी SHOW_STATISTICS ( [उत्पादन। उत्पाद सूची], [शेल्फ]) DENSITY_VECTOR के साथ; DBCC SHOW_STATISTICS ( [Production.ProductInventory], [Bin]) DENSITY_VECTOR के साथ;परिणाम नीचे दी गई तालिका में संक्षेपित हैं (तीसरे कॉलम की गणना घनत्व से की जाती है):
| स्तंभ | घनत्व | <थ>1 / घनत्व|
|---|---|---|
| शेल्फ | 0.04761905 | 21 |
| बिन | 0.01612903 | 62 |
शेल्फ और बिन घनत्व वेक्टर जानकारी
जैसा कि दस्तावेज़ीकरण नोट करता है, घनत्व का व्युत्क्रम कॉलम में अलग-अलग मानों की संख्या है। ऊपर दिखाए गए आंकड़ों की जानकारी से, SQL सर्वर जानता है कि 21 अलग-अलग Shelf थे मान और 62 विशिष्ट Bin तालिका में मान, जब आंकड़े एकत्र किए गए थे।
GROUP BY . द्वारा उत्पादित पंक्तियों की संख्या का अनुमान लगाने का कार्य खंड छोटा होता है जब केवल एक कॉलम शामिल होता है (कोई अन्य भविष्यवाणी नहीं मानता)। उदाहरण के लिए, यह देखना आसान है कि GROUP BY Shelf 21 पंक्तियों का उत्पादन करेगा; GROUP BY Bin 62 का उत्पादन करेगा।
हालांकि, यह तुरंत स्पष्ट नहीं है कि SQL सर्वर अलग-अलग (Shelf, Bin) की संख्या का अनुमान कैसे लगा सकता है संयोजन हमारे GROUP BY Shelf, Bin . के लिए सवाल। प्रश्न को थोड़ा अलग तरीके से रखने के लिए:21 अलमारियों और 62 डिब्बे को देखते हुए, कितने अद्वितीय शेल्फ और बिन संयोजन होंगे? समस्या क्षेत्र के भौतिक पहलुओं और अन्य मानवीय ज्ञान को छोड़कर, उत्तर अधिकतम (21, 62) =62 से (21 * 62) =1,302 तक कहीं भी हो सकता है। अधिक जानकारी के बिना, यह जानने का कोई स्पष्ट तरीका नहीं है कि उस सीमा में अनुमान कहाँ लगाया जाए।
फिर भी, हमारी उदाहरण क्वेरी के लिए, SQL सर्वर का अनुमान 744.312 . है पंक्तियाँ (प्लान एक्सप्लोरर दृश्य में 744 तक गोल) लेकिन किस आधार पर?
कार्डिनैलिटी एस्टीमेशन एक्सटेंडेड इवेंट
कार्डिनैलिटी अनुमान प्रक्रिया को देखने का प्रलेखित तरीका विस्तारित ईवेंट query_optimizer_estimate_cardinality का उपयोग करना है ("डीबग" चैनल में होने के बावजूद)। जब इस ईवेंट को एकत्रित करने वाला सत्र चल रहा होता है, तो निष्पादन योजना संचालकों को एक अतिरिक्त संपत्ति मिलती है StatsCollectionId जो अलग-अलग ऑपरेटर अनुमानों को उन गणनाओं से जोड़ता है जो उन्हें उत्पन्न करती हैं। हमारी उदाहरण क्वेरी के लिए, आंकड़े संग्रह आईडी 2 को समग्र ऑपरेटर द्वारा समूह के लिए कार्डिनैलिटी अनुमान से जोड़ा गया है।
हमारी परीक्षण क्वेरी के लिए विस्तारित ईवेंट से प्रासंगिक आउटपुट है:
<डेटा नाम ="कैलकुलेटर"> <प्रकार का नाम ="एक्सएमएल" पैकेज ="पैकेज0"> <मान> <कैलकुलेटर सूची> <डिस्टिंक्टकाउंट कैलक्यूलेटर कैलकुलेटरनाम ="सीडीवीसीप्लान लीफ" सिंगल कॉलमस्टैट ="शेल्फ, बिन" /><लोडेडस्टैट्स>
निश्चित रूप से वहाँ कुछ उपयोगी जानकारी है।
हम देख सकते हैं कि योजना अलग-अलग मूल्यों कैलकुलेटर वर्ग (CDVCPlanLeaf .) को छोड़ती है ) को Shelf . पर एकल स्तंभ आँकड़ों का उपयोग करते हुए नियोजित किया गया था और Bin इनपुट के रूप में। सांख्यिकी संग्रह तत्व इस खंड का मिलान निष्पादन योजना में दिखाई गई आईडी (2) से करता है, जो 744.31 के कार्डिनैलिटी अनुमान को दर्शाता है , और उपयोग की गई सांख्यिकी ऑब्जेक्ट आईडी के बारे में अधिक जानकारी।
दुर्भाग्य से, इवेंट आउटपुट में यह कहने के लिए कुछ भी नहीं है कि कैलकुलेटर अंतिम आंकड़े पर कैसे पहुंचा, जिस चीज में हम वास्तव में रुचि रखते हैं।
अलग-अलग गणनाओं का संयोजन
कम प्रलेखित मार्ग पर जाकर, हम ट्रेस फ़्लैग के साथ क्वेरी के लिए अनुमानित योजना का अनुरोध कर सकते हैं 2363 और 3604 सक्षम:
उत्पादन से INV.शेल्फ़, INV.Bin, COUNT_BIG(*) चुनें। INV.शेल्फ़, INV.BinORDER द्वारा INV.शेल्फ़, INV.BinOPTION (QUERYTRACEON 3604, QUERYTRACEON 2363);
यह SQL सर्वर प्रबंधन स्टूडियो में संदेश टैब पर डीबग जानकारी देता है। दिलचस्प हिस्सा नीचे दिया गया है:
अलग मान गणना शुरू करेंइनपुट ट्री:LogOp_GbAgg OUT(QCOL:[INV]। शेल्फ, QCOL:[INV].Bin,COL:Expr1001,) BY(QCOL:[INV].Shelf,QCOL:[INV].Bin ,) CStCollBaseTable(ID=1, CARD=1069 TBL:Production.ProductInventory AS TBL:INV) AncOp_PrjList AncOp_PrjEl COL:Expr1001 ScaOp_AggFunc StopCountBig ScaOp_Const TI(int,ML=4) XVAR(int,Non one's,Value=0)Plan गणना:CDVCPlanLeaf 0 मल्टी-कॉलम आँकड़े, 2 सिंगल-कॉलम आँकड़े, 0 कॉलम QCOL के लिए गेस लोडेड हिस्टोग्राम:[INV]। कॉलम QCOL के लिए आईडी 3 लोडेड हिस्टोग्राम वाले आँकड़ों से शेल्फ:[INV]। आईडी 4 के साथ आँकड़ों से बिन परिवेश कार्डिनैलिटी 1069 का उपयोग अलग-अलग गणनाओं को संयोजित करने के लिए:21 62संयुक्त विशिष्ट गणना:744.312गणना का परिणाम:744.312आंकड़ों का संग्रह उत्पन्न:CStCollGroupBy(ID=2, CARD=744.312) CStCollBaseTable(ID=1, CARD=1069 TBL:Production.ProductInventory AS TBL:INV)End विशिष्ट मूल्यों की गणना
यह बहुत कुछ वैसी ही जानकारी दिखाता है जैसा कि एक्सटेंडेड इवेंट ने (यकीनन) उपभोग करने में आसान प्रारूप में किया था:
- इनपुट रिलेशनल ऑपरेटर (
LogOp_GbAggके लिए कार्डिनैलिटी अनुमान की गणना करने के लिए - तार्किक समूह कुल मिलाकर) - कैलकुलेटर इस्तेमाल किया गया (
CDVCPlanLeaf) और इनपुट आँकड़े - परिणामी आंकड़े संग्रह विवरण
दिलचस्प नई जानकारी अलग-अलग गणनाओं को संयोजित करने के लिए परिवेशी कार्डिनैलिटी का उपयोग करने का हिस्सा है .
यह स्पष्ट रूप से दर्शाता है कि 21, 62, और 1069 मानों का उपयोग किया गया था, लेकिन (निराशाजनक रूप से) अभी भी ठीक नहीं है कि 744.312 पर पहुंचने के लिए कौन सी गणना की गई थी। परिणाम।
टू द डीबगर!
डीबगर संलग्न करना और सार्वजनिक प्रतीकों का उपयोग करना हमें उदाहरण क्वेरी को संकलित करते समय अनुसरण किए गए कोड पथ का विस्तार से पता लगाने की अनुमति देता है।
नीचे स्नैपशॉट प्रक्रिया में एक प्रतिनिधि बिंदु पर कॉल स्टैक के ऊपरी भाग को दिखाता है:
MSVCR120!logsqllang!OdblNHlogNsqllang!CCardUtilSQL12::ProbSampleWithoutReplacementsqllang!CCardUtilSQL12::CardDistinctMungedsqllang!CCardUtilSQL12::CardDistinctCombinedsqllang!CStCollAbstractLeaf::CardDistinctImplsqllang!IStatsCollection::CardDistinctsqllang!CCardUtilSQL12::CardGroupByHelperCoresqllang!CCardUtilSQL12::PstcollGroupByHelpersqllang!CLogOp_GbAgg::PstcollDeriveCardinalitysqllang!CCardFrameworkSQL12 ::DeriveCardinalityProperties
यहाँ कुछ दिलचस्प विवरण हैं। नीचे से ऊपर की ओर काम करते हुए, हम देखते हैं कि कार्डिनैलिटी को अपडेटेड सीई (CCardFrameworkSQL12) का उपयोग करके निकाला जा रहा है। ) SQL सर्वर 2014 और बाद में उपलब्ध है (मूल CE CCardFrameworkSQL7 . है ), कुल तार्किक ऑपरेटर द्वारा समूह के लिए (CLogOp_GbAgg )।
विशिष्ट कार्डिनैलिटी की गणना में प्रतिस्थापन के बिना नमूने का उपयोग करते हुए, कई इनपुटों को जोड़ना (मंग करना) शामिल है।
H . का संदर्भ और ऊपर से दूसरी विधि में एक (प्राकृतिक) लघुगणक गणना में शैनन एंट्रोपी के उपयोग को दर्शाता है:
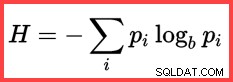
शैनन एंट्रॉपी
दो आँकड़ों के बीच सूचनात्मक सहसंबंध (आपसी जानकारी) का अनुमान लगाने के लिए एन्ट्रापी का उपयोग किया जा सकता है:
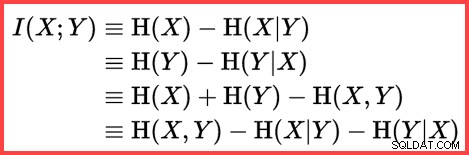
आपसी जानकारी
यह सब एक साथ रखकर, हम एक टी-एसक्यूएल गणना स्क्रिप्ट का निर्माण कर सकते हैं जिस तरह से एसक्यूएल सर्वर प्रतिस्थापन के बिना नमूनाकरण का उपयोग करता है, शैनन एंट्रॉपी, और आपसी जानकारी अंतिम कार्डिनैलिटी अनुमान तैयार करने के लिए।
हम इनपुट नंबरों से शुरू करते हैं (परिवेश कार्डिनैलिटी और प्रत्येक कॉलम में अलग-अलग मानों की संख्या):
DECLARE @Card float =1069, @Distinct1 float =21, @Distinct2 float =62;
आवृत्ति प्रत्येक स्तंभ का प्रति विशिष्ट मान पंक्तियों की औसत संख्या है:
DECLARE @Frequency1 float =@Card / @Distinct1, @Frequency2 float =@Card / @ Distinct2;
प्रतिस्थापन के बिना नमूनाकरण (एसडब्ल्यूआर) पंक्तियों की कुल संख्या से प्रति विशिष्ट मान (आवृत्ति) की औसत संख्या को घटाने का एक साधारण मामला है:
DECLARE @SWR1 float =@Card - @Frequency1, @SWR2 float =@Card - @Frequency2, @SWR3 float =@Card - @Frequency1 - @Frequency2;
एन्ट्रापी (एन लॉग एन) और आपसी जानकारी की गणना करें:
घोषणा @E1 फ्लोट =(@SWR1 + 0.5) * लॉग(@SWR1), @E2 फ्लोट =(@SWR2 + 0.5) * लॉग(@SWR2), @E3 फ्लोट =(@SWR3 + 0.5) * लॉग (@SWR3), @E4 फ्लोट =(@Card + 0.5) * LOG(@Card); -- लघुगणक का उपयोग हमें व्यक्त करने की अनुमति देता है - जोड़ के रूप में गुणा और घटाव के रूप में विभाजनDECLARE @MI फ्लोट =EXP(@E1 + @E2 - @E3 - @E4);
अब हमने अनुमान लगाया है कि आंकड़ों के दो सेट कितने सहसंबद्ध हैं, हम अंतिम अनुमान की गणना कर सकते हैं:
चुनें (1e0 - @MI) * @ Distinct1 * @ Distinct2;
गणना का परिणाम 744.311823994677 है, जो कि 744.312 . है तीन दशमलव स्थानों तक गोल।
सुविधा के लिए, यहाँ एक ब्लॉक में पूरा कोड है:
DECLARE @Card float =1069, @Distinct1 float =21, @Distinct2 float =62; DECLARE @ फ़्रीक्वेंसी1 फ्लोट =@ कार्ड / @ विशिष्ट 1, @ फ़्रिक्वेंसी 2 फ्लोट =@ कार्ड / @ डिस्टिंक्ट 2; - प्रतिस्थापन के बिना नमूनाDECLARE @SWR1 फ्लोट =@ कार्ड - @ फ़्रीक्वेंसी 1, @ एसडब्ल्यूआर 2 फ्लोट =@ कार्ड - @ फ़्रिक्वेंसी 2, @ एसडब्ल्यूआर 3 फ्लोट =@ कार्ड - @ फ़्रिक्वेंसी 1 - @ फ़्रिक्वेंसी 2; - एन्ट्रॉपीडेक्लेयर @E1 फ्लोट =(@SWR1 + 0.5) * लॉग(@SWR1), @E2 फ्लोट =(@SWR2 + 0.5) * लॉग(@SWR2), @E3 फ्लोट =(@SWR3 + 0.5) * लॉग( @SWR3), @E4 फ्लोट =(@Card + 0.5) * LOG(@Card); - आपसी जानकारी DECLARE @MI फ्लोट =EXP(@E1 + @E2 - @E3 - @E4); -- अंतिम अनुमानचुनें (1e0 - @MI) * @ Distinct1 * @ Distinct2;
अंतिम विचार
इस मामले में अंतिम अनुमान अपूर्ण है – उदाहरण क्वेरी वास्तव में 441 returns लौटाती है पंक्तियाँ।
एक बेहतर अनुमान प्राप्त करने के लिए, हम अनुकूलक को Bin के घनत्व के बारे में बेहतर जानकारी प्रदान कर सकते हैं और Shelf एक बहुस्तंभीय आँकड़ों का उपयोग करते हुए स्तंभ। उदाहरण के लिए:
उत्पादन पर आंकड़े stat_Shelf_Bin बनाएं। उत्पाद सूची (शेल्फ़, बिन);
उस आंकड़े के साथ (या तो दिया गया है, या एक समान बहु-स्तंभ अनुक्रमणिका जोड़ने के दुष्प्रभाव के रूप में), उदाहरण क्वेरी के लिए कार्डिनैलिटी अनुमान बिल्कुल सही है। हालांकि इस तरह के एक साधारण एकत्रीकरण की गणना करना दुर्लभ है। अतिरिक्त विधेय के साथ, बहुस्तंभ आँकड़ा कम प्रभावी हो सकता है। फिर भी, यह याद रखना महत्वपूर्ण है कि बहु-स्तंभ आँकड़ों द्वारा प्रदान की गई अतिरिक्त घनत्व जानकारी एकत्रीकरण (साथ ही समानता की तुलना) के लिए उपयोगी हो सकती है।
एक बहु-स्तंभ आंकड़े के बिना, अतिरिक्त विधेय के साथ एक समग्र क्वेरी अभी भी इस आलेख में दिखाए गए आवश्यक तर्क का उपयोग करने में सक्षम हो सकती है। उदाहरण के लिए, तालिका कार्डिनैलिटी पर सूत्र लागू करने के बजाय, इसे चरण दर चरण इनपुट हिस्टोग्राम पर लागू किया जा सकता है।
संबंधित सामग्री:COUNT व्यंजक पर विधेय के लिए कार्डिनैलिटी अनुमान



