 बड़े होकर, मुझे ऐसे खेल पसंद थे जो स्मृति और पैटर्न मिलान कौशल का परीक्षण करते थे। मेरे कई दोस्तों के पास साइमन था, जबकि मेरे पास आइंस्टीन नाम का एक नॉक-ऑफ था। दूसरों के पास एक अटारी टच मी था, जो तब भी मुझे पता था कि एक संदिग्ध नामकरण निर्णय था। आजकल, पैटर्न मिलान का अर्थ मेरे लिए कुछ अलग है, और यह दैनिक डेटाबेस प्रश्नों का एक महंगा हिस्सा हो सकता है।
बड़े होकर, मुझे ऐसे खेल पसंद थे जो स्मृति और पैटर्न मिलान कौशल का परीक्षण करते थे। मेरे कई दोस्तों के पास साइमन था, जबकि मेरे पास आइंस्टीन नाम का एक नॉक-ऑफ था। दूसरों के पास एक अटारी टच मी था, जो तब भी मुझे पता था कि एक संदिग्ध नामकरण निर्णय था। आजकल, पैटर्न मिलान का अर्थ मेरे लिए कुछ अलग है, और यह दैनिक डेटाबेस प्रश्नों का एक महंगा हिस्सा हो सकता है।
मुझे हाल ही में स्टैक ओवरफ़्लो पर कुछ टिप्पणियां मिलीं, जहां एक उपयोगकर्ता कह रहा था, जैसे कि वास्तव में, वह CHARINDEX LEFT . से बेहतर प्रदर्शन करता है या LIKE . एक मामले में, व्यक्ति ने डेविड लोज़िंस्की के एक लेख का हवाला दिया, "एसक्यूएल:LIKE बनाम सबस्ट्रिंग बनाम बाएँ/दाएँ बनाम CHARINDEX।" हां, लेख से पता चलता है कि, काल्पनिक उदाहरण में, CHARINDEX सर्वश्रेष्ठ प्रदर्शन किया। हालांकि, चूंकि मैं हमेशा इस तरह के कंबल बयानों के बारे में उलझन में हूं, और तार्किक कारण के बारे में नहीं सोच सका कि एक स्ट्रिंग फ़ंक्शन हमेशा हमेशा क्यों होगा दूसरे से बेहतर प्रदर्शन करें, बाकी सब बराबर होने के साथ , मैंने उसके परीक्षण चलाए। निश्चित रूप से, मेरी मशीन पर मेरे परिणाम अलग-अलग थे (विस्तार करने के लिए क्लिक करें):
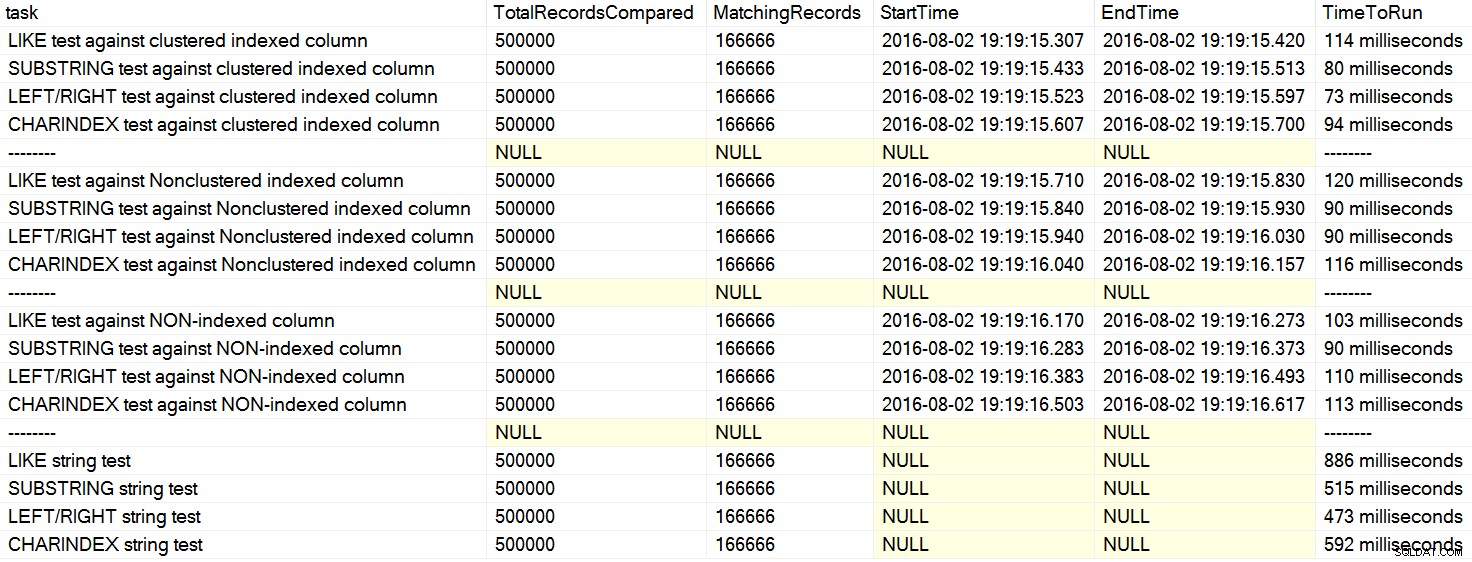 मेरी मशीन पर, CHARINDEX धीमा था बाएँ/दाएँ/सबस्ट्रिंग की तुलना में।
मेरी मशीन पर, CHARINDEX धीमा था बाएँ/दाएँ/सबस्ट्रिंग की तुलना में।
डेविड के परीक्षण मूल रूप से इन क्वेरी संरचनाओं की तुलना कर रहे थे - कच्चे अवधि के संदर्भ में - एक कॉलम मान की शुरुआत या अंत में एक स्ट्रिंग पैटर्न की तलाश में:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
बस इन क्लॉज को देखकर, आप देख सकते हैं कि क्यों CHARINDEX कम कुशल हो सकता है - यह कई अतिरिक्त कार्यात्मक कॉल करता है जो अन्य दृष्टिकोणों को निष्पादित नहीं करना पड़ता है। डेविड की मशीन पर इस दृष्टिकोण ने सर्वश्रेष्ठ प्रदर्शन क्यों किया, मुझे यकीन नहीं है; हो सकता है कि उसने कोड को ठीक वैसे ही चलाया जैसे पोस्ट किया गया था, और परीक्षणों के बीच वास्तव में बफ़र्स को नहीं छोड़ा, जैसे कि बाद के परीक्षणों को कैश्ड डेटा से लाभ हुआ।
सैद्धांतिक रूप से, CHARINDEX अधिक सरलता से व्यक्त किया जा सकता था, उदा.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(लेकिन यह वास्तव में मेरे आकस्मिक परीक्षणों में और भी खराब प्रदर्शन करता है।)
और ये भी क्यों हैं OR शर्तें, मुझे यकीन नहीं है। वास्तविक रूप से, अधिकांश समय आप दो प्रकार की पैटर्न खोजों में से एक कर रहे होते हैं:इससे प्रारंभ होता है या शामिल है (समाप्त . की तलाश करना बहुत कम आम है ) और उनमें से अधिकतर मामलों में, उपयोगकर्ता यह बताना चाहता है कि क्या वे से शुरू करना चाहते हैं या शामिल है , कम से कम हर उस एप्लिकेशन में जिसमें मैं अपने करियर में शामिल रहा हूं।
OR . का उपयोग करने के बजाय, उन्हें अलग प्रकार की क्वेरी के रूप में अलग करना समझ में आता है सशर्त, चूंकि से प्रारंभ होता है एक इंडेक्स का उपयोग कर सकते हैं (यदि कोई मौजूद है जो एक खोज के लिए पर्याप्त उपयुक्त है, या क्लस्टर इंडेक्स की तुलना में पतला है), जबकि के साथ समाप्त होता है नहीं कर सकता (और या स्थितियां सामान्य रूप से अनुकूलक पर रिंच फेंकती हैं)। अगर मैं भरोसा कर सकता हूँ LIKE एक इंडेक्स का उपयोग करने के लिए जब यह कर सकता है, और अधिकांश या सभी मामलों में उपरोक्त अन्य समाधानों की तुलना में अच्छा या बेहतर प्रदर्शन करने के लिए, तो मैं इस तर्क को बहुत आसान बना सकता हूं। एक संग्रहीत कार्यविधि में दो पैरामीटर हो सकते हैं - खोजा जा रहा पैटर्न, और प्रदर्शन करने के लिए खोज का प्रकार (आम तौर पर चार प्रकार के स्ट्रिंग मिलान होते हैं - इसके साथ शुरू होता है, इसके साथ समाप्त होता है, इसमें शामिल होता है, या सटीक मिलान होता है)।
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
यह गतिशील एसक्यूएल का उपयोग किए बिना प्रत्येक संभावित मामले को संभालता है; OPTION (RECOMPILE) ऐसा इसलिए है क्योंकि आप "समाप्त होने वाली" (जिसे लगभग निश्चित रूप से स्कैन करने की आवश्यकता होगी) के लिए अनुकूलित योजना को "शुरुआत के साथ" क्वेरी के लिए पुन:उपयोग करने के लिए अनुकूलित नहीं करना चाहते हैं, या इसके विपरीत; यह यह भी सुनिश्चित करेगा कि अनुमान सही हैं ("एस के साथ शुरू होता है" शायद "क्यूएक्स से शुरू होता है" से बहुत अलग कार्डिनैलिटी है)। यहां तक कि अगर आपके पास ऐसा परिदृश्य है जहां उपयोगकर्ता 99% समय में एक प्रकार की खोज चुनते हैं, तो आप पुन:संकलित करने के बजाय यहां गतिशील एसक्यूएल का उपयोग कर सकते हैं, लेकिन उस स्थिति में आप पैरामीटर स्नीफिंग के लिए अभी भी कमजोर होंगे। कई सशर्त तर्क प्रश्नों में, पुन:संकलित और/या पूर्ण-ऑन डायनेमिक SQL अक्सर सबसे समझदार दृष्टिकोण होता है ("रसोई सिंक" के बारे में मेरी पोस्ट देखें)।
परीक्षा
चूंकि मैंने हाल ही में नए वाइडवर्ल्ड इम्पोर्टर्स नमूना डेटाबेस को देखना शुरू किया है, इसलिए मैंने वहां अपना परीक्षण चलाने का फैसला किया। ColumnStore अनुक्रमणिका या अस्थायी इतिहास तालिका के बिना एक सभ्य आकार की तालिका खोजना कठिन था, लेकिन Sales.Invoices , जिसमें 70,510 पंक्तियाँ हैं, एक साधारण nvarchar(20) . है CustomerPurchaseOrderNumber . नामक कॉलम कि मैंने परीक्षणों के लिए उपयोग करने का निर्णय लिया। (यह क्यों है nvarchar(20) जब हर एक मान 5-अंकीय संख्या है, तो मुझे कोई जानकारी नहीं है, लेकिन पैटर्न मिलान वास्तव में परवाह नहीं करता है यदि बाइट्स नीचे की संख्या या स्ट्रिंग का प्रतिनिधित्व करते हैं।)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| पैटर्न | # पंक्तियों में | तालिका का% |
| "1" से शुरू होता है | 70,505 | 99.993% |
| "2" से शुरू होता है | 5 | 0.007% |
| "5" पर समाप्त होता है | 6,897 | 9.782% |
| "30" पर समाप्त होता है | 749 | 1.062% |
मैंने कई खोज मानदंडों के साथ आने के लिए तालिका में मूल्यों पर चारों ओर पोक किया जो पंक्तियों की बहुत अलग संख्या उत्पन्न करेगा, उम्मीद है कि किसी दिए गए दृष्टिकोण के साथ किसी भी टिपिंग पॉइंट व्यवहार को प्रकट करने के लिए। दाईं ओर वे खोज क्वेरी हैं जिन पर मैं पहुंचा।
मैं खुद को साबित करना चाहता था कि उपरोक्त प्रक्रिया सभी संभावित खोजों के लिए OR का उपयोग करने वाले किसी भी प्रश्न की तुलना में निर्विवाद रूप से बेहतर थी। सशर्त, चाहे वे LIKE . का उपयोग करें या नहीं , LEFT/RIGHT , SUBSTRING , या CHARINDEX . मैंने डेविड की बुनियादी क्वेरी संरचनाएं लीं और उन्हें संग्रहीत प्रक्रियाओं में डाल दिया (चेतावनी के साथ कि मैं वास्तव में उनके इनपुट के बिना "शामिल" का परीक्षण नहीं कर सकता, और मुझे उनका OR बनाना था मेरे तर्क के एक संस्करण के साथ, पंक्तियों की समान संख्या प्राप्त करने के लिए थोड़ा अधिक लचीला तर्क दें। मैंने खोज कॉलम पर और गर्म और ठंडे कैश दोनों के तहत एक इंडेक्स के साथ और उसके बिना प्रक्रियाओं का परीक्षण करने की भी योजना बनाई है।
प्रक्रियाएं:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
मैंने डेविड की प्रक्रियाओं के संस्करणों को उनके मूल इरादे के लिए सही बनाया, यह मानते हुए कि वास्तव में किसी भी पंक्ति को खोजने की आवश्यकता है जहां खोज पैटर्न शुरुआत में है *या* स्ट्रिंग का अंत। मैंने इसे बस इसलिए किया ताकि मैं विभिन्न दृष्टिकोणों के प्रदर्शन की तुलना कर सकूं, ठीक उसी तरह जैसे उन्होंने उन्हें लिखा था, यह देखने के लिए कि क्या इस डेटा सेट पर मेरे परिणाम मेरे सिस्टम पर उनकी मूल स्क्रिप्ट के मेरे परीक्षणों से मेल खाएंगे। इस मामले में मेरे खुद के संस्करण को पेश करने का कोई कारण नहीं था, क्योंकि यह बस उसके LIKE % + @pattern OR LIKE @pattern + % से मेल खाएगा। भिन्नता।
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO प्रक्रियाओं के साथ, मैं परीक्षण कोड उत्पन्न कर सकता था - जो अक्सर मूल समस्या जितना ही मजेदार होता है। सबसे पहले, एक लॉगिंग टेबल:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
फिर कोड जो विभिन्न प्रक्रियाओं और तर्कों का उपयोग करके चुनिंदा संचालन करेगा:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; परिणाम
मैंने इन परीक्षणों को एक वर्चुअल मशीन पर चलाया, जिसमें 4 CPU और 32 GB RAM के साथ Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149) चल रहा था। मैंने परीक्षण के प्रत्येक सेट को 11 बार चलाया; गर्म कैश परीक्षणों के लिए, मैंने परिणामों के पहले सेट को फेंक दिया क्योंकि उनमें से कुछ वास्तव में कोल्ड कैश परीक्षण थे।
मैं पैटर्न दिखाने के लिए परिणामों को रेखांकन करने के तरीके के साथ संघर्ष कर रहा था, ज्यादातर इसलिए कि कोई पैटर्न नहीं थे। लगभग हर तरीका एक परिदृश्य में सबसे अच्छा और दूसरे में सबसे खराब था। निम्नलिखित तालिकाओं में, मैंने प्रत्येक कॉलम के लिए सबसे अच्छा और सबसे खराब प्रदर्शन करने वाली प्रक्रिया पर प्रकाश डाला, और आप देख सकते हैं कि परिणाम निर्णायक नहीं हैं:
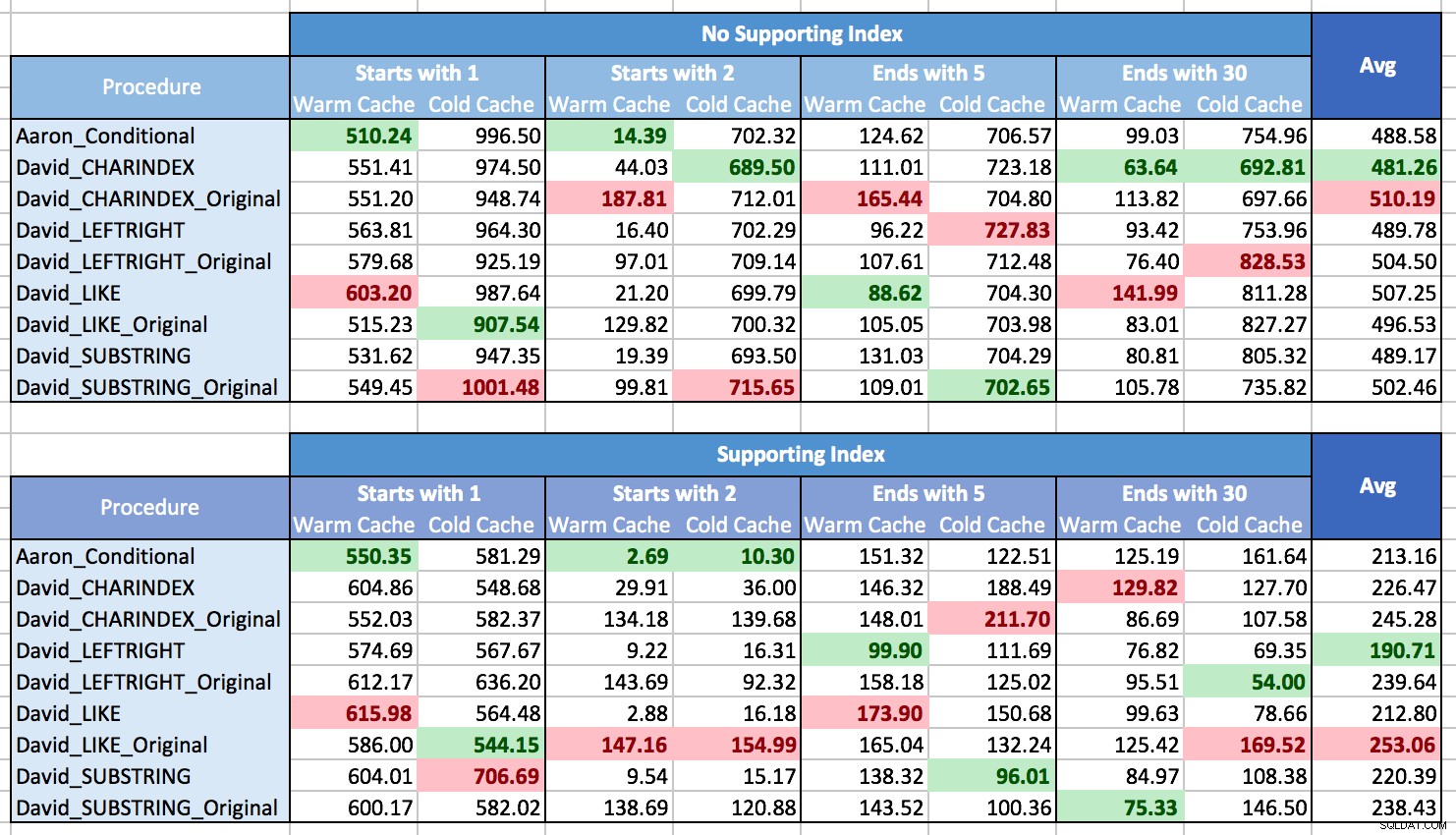 इन परीक्षणों में, कभी-कभी CHARINDEX जीता, और कभी-कभी ऐसा नहीं हुआ।
इन परीक्षणों में, कभी-कभी CHARINDEX जीता, और कभी-कभी ऐसा नहीं हुआ।
मैंने जो सीखा है, वह यह है कि, कुल मिलाकर, यदि आप कई अलग-अलग स्थितियों का सामना करने जा रहे हैं (विभिन्न प्रकार के पैटर्न मिलान, एक सहायक सूचकांक के साथ या नहीं, डेटा हमेशा स्मृति में नहीं हो सकता), वास्तव में कोई नहीं है स्पष्ट विजेता, और औसतन प्रदर्शन की सीमा बहुत छोटी है (वास्तव में, चूंकि एक गर्म कैश हमेशा मदद नहीं करता है, मुझे संदेह होगा कि परिणाम उन्हें प्राप्त करने की तुलना में परिणामों को प्रस्तुत करने की लागत से अधिक प्रभावित हुए थे)। व्यक्तिगत परिदृश्यों के लिए, मेरे परीक्षणों पर भरोसा न करें; अपने हार्डवेयर, कॉन्फ़िगरेशन, डेटा और उपयोग के पैटर्न को देखते हुए कुछ बेंचमार्क स्वयं चलाएं।
चेतावनी
कुछ चीज़ें जिन पर मैंने इन परीक्षणों के लिए विचार नहीं किया:
- संकुल बनाम गैर-संकुलित . चूंकि यह संभावना नहीं है कि आपका क्लस्टर इंडेक्स उस कॉलम पर होगा जहां आप स्ट्रिंग की शुरुआत या अंत के खिलाफ पैटर्न मिलान खोज कर रहे हैं, और चूंकि दोनों मामलों में एक तलाश काफी हद तक समान होगी (और स्कैन के बीच अंतर बड़े पैमाने पर होगा सूचकांक चौड़ाई बनाम तालिका चौड़ाई का कार्य हो), मैंने केवल गैर-संकुल सूचकांक का उपयोग करके प्रदर्शन का परीक्षण किया। यदि आपके पास कोई विशिष्ट परिदृश्य है जहां यह अंतर अकेले पैटर्न मिलान पर गहरा अंतर डालता है, तो कृपया मुझे बताएं।
- अधिकतम प्रकार . अगर आप
varchar(max). के अंदर स्ट्रिंग खोज रहे हैं /nvarchar(max), उन्हें अनुक्रमित नहीं किया जा सकता है, इसलिए जब तक आप मान के भागों का प्रतिनिधित्व करने के लिए गणना किए गए कॉलम का उपयोग नहीं करते हैं, तब तक एक स्कैन की आवश्यकता होगी - चाहे आप शुरुआत के साथ समाप्त होते हैं, या शामिल हैं। प्रदर्शन ओवरहेड स्ट्रिंग के आकार से संबंधित है या नहीं, या अतिरिक्त ओवरहेड केवल प्रकार के कारण पेश किया गया है, मैंने परीक्षण नहीं किया।
- पूर्ण-पाठ खोज . मैंने इस फीचर के साथ यहां और तेहर खेला है, और मैं इसे वर्तनी कर सकता हूं, लेकिन अगर मेरी समझ सही है, तो यह केवल तभी मददगार हो सकता है जब आप पूरे नॉन-स्टॉप शब्दों की खोज कर रहे हों, और इस बात से चिंतित न हों कि वे स्ट्रिंग में कहां थे मिला। यह उपयोगी नहीं होगा यदि आप पाठ के अनुच्छेदों को संग्रहीत कर रहे थे और "Y" से शुरू होने वाले सभी पैराग्राफ को ढूंढना चाहते थे, जिसमें "द" शब्द हो या प्रश्न चिह्न के साथ समाप्त हो।
सारांश
इस परीक्षण से दूर चलने वाला एकमात्र कंबल कथन यह है कि स्ट्रिंग पैटर्न मिलान करने का सबसे प्रभावी तरीका क्या है, इसके बारे में कोई कंबल कथन नहीं है। जबकि मैं लचीलेपन और रखरखाव के लिए अपने सशर्त दृष्टिकोण के पक्षपाती हूं, यह सभी परिदृश्यों में प्रदर्शन विजेता नहीं था। मेरे लिए, जब तक मैं प्रदर्शन में बाधा नहीं डाल रहा हूं और मैं सभी रास्ते अपना रहा हूं, मैं निरंतरता के लिए अपने दृष्टिकोण का उपयोग करना जारी रखूंगा। जैसा कि मैंने ऊपर सुझाव दिया है, यदि आपके पास एक बहुत ही संकीर्ण परिदृश्य है और आप अवधि में छोटे अंतर के प्रति बहुत संवेदनशील हैं, तो आप यह निर्धारित करने के लिए अपने स्वयं के परीक्षण चलाना चाहेंगे कि कौन सी विधि लगातार आपके लिए सबसे अच्छा प्रदर्शन करने वाली है।



