मान लीजिए कि आप उन सभी रोगियों को ढूंढना चाहते हैं, जिन्हें कभी फ्लू का टीका नहीं लगा है। या, AdventureWorks2012 . में , एक समान प्रश्न हो सकता है, "मुझे उन सभी ग्राहकों को दिखाएं जिन्होंने कभी कोई आदेश नहीं दिया है।" NOT IN . का उपयोग करके व्यक्त किया गया , एक पैटर्न जिसे मैं अक्सर देखता हूं, जो कुछ इस तरह दिखाई देगा (मैं जोनाथन केहैयस (@SQLPoolBoy) द्वारा इस स्क्रिप्ट से बढ़े हुए हेडर और डिटेल टेबल का उपयोग कर रहा हूं):
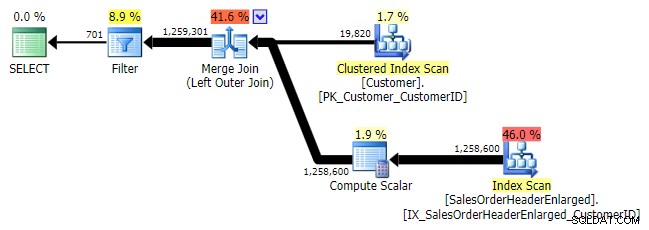
सेल्स से ग्राहक आईडी चुनें। ग्राहक जहां ग्राहक आईडी नहीं है (बिक्री से ग्राहक आईडी चुनें। SalesOrderHeaderEnlarged);
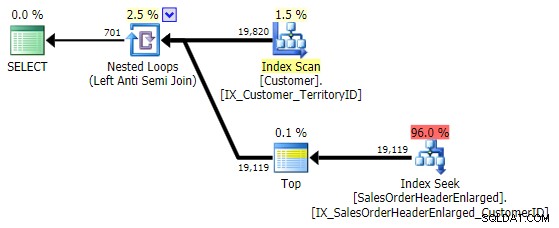
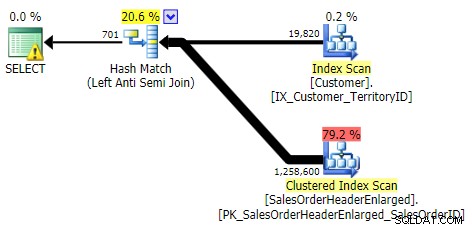
जब मैं इस पैटर्न को देखता हूं, तो मैं रोता हूं। लेकिन प्रदर्शन कारणों से नहीं - आखिरकार, यह इस मामले में एक अच्छी पर्याप्त योजना बनाता है:
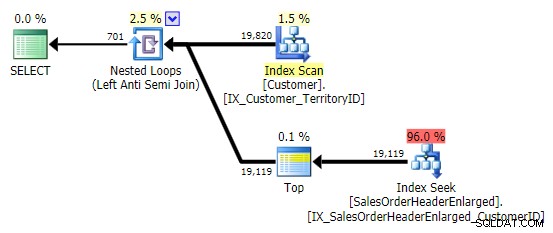
मुख्य समस्या यह है कि यदि लक्ष्य कॉलम NULLable है, तो परिणाम आश्चर्यजनक हो सकते हैं (SQL सर्वर इसे लेफ्ट एंटी सेमी जॉइन के रूप में प्रोसेस करता है, लेकिन यह आपको विश्वसनीय रूप से नहीं बता सकता है कि दाईं ओर एक NULL बराबर है - या इसके बराबर नहीं है - बाईं ओर का संदर्भ)। इसके अलावा, यदि कॉलम NULLable है, तो अनुकूलन अलग तरह से व्यवहार कर सकता है, भले ही इसमें वास्तव में कोई NULL मान न हो (गेल शॉ ने 2010 में इस बारे में बात की थी)।
इस मामले में, लक्ष्य कॉलम अशक्त नहीं है, लेकिन मैं उन संभावित मुद्दों का उल्लेख करना चाहता था NOT IN के साथ - मैं भविष्य की पोस्ट में इन मुद्दों की अधिक गहन जांच कर सकता हूं।
TL;DR संस्करण
नहीं में . के बजाय , एक सहसंबद्ध मौजूद नहीं . का उपयोग करें इस क्वेरी पैटर्न के लिए। हमेशा। जब अन्य सभी चर समान होते हैं, तो अन्य विधियां प्रदर्शन के मामले में इसका मुकाबला कर सकती हैं, लेकिन अन्य सभी विधियां या तो प्रदर्शन समस्याओं या अन्य चुनौतियों का परिचय देती हैं।
विकल्प
तो हम इस प्रश्न को और किन तरीकों से लिख सकते हैं?
बाहरी आवेदन
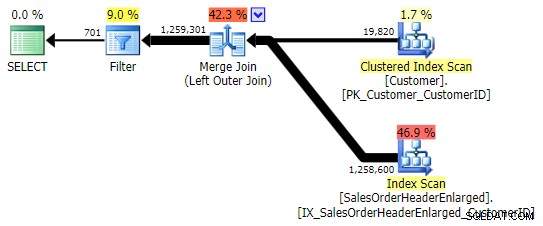
एक तरह से हम इस परिणाम को व्यक्त कर सकते हैं एक सहसंबद्ध बाहरी लागू का उपयोग कर रहा है ।
सेल्स से सी. कस्टमर आईडी चुनें। कोटर के रूप में ग्राहक आवेदन करें (सेल्स से ग्राहक आईडी चुनें।तार्किक रूप से, यह एक लेफ्ट एंटी सेमी जॉइन भी है, लेकिन परिणामी प्लान में लेफ्ट एंटी सेमी जॉइन ऑपरेटर नहीं है, और यह
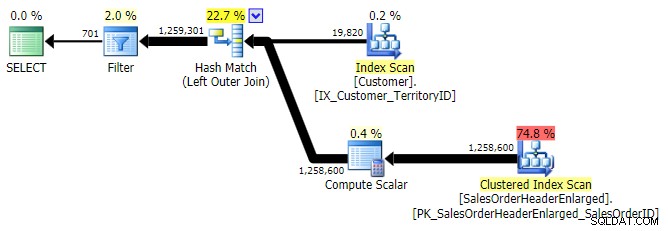
NOT INकी तुलना में काफी अधिक महंगा लगता है। समकक्ष। ऐसा इसलिए है क्योंकि यह अब वाम विरोधी अर्ध-जुड़ाव नहीं है; इसे वास्तव में एक अलग तरीके से संसाधित किया जाता है:एक बाहरी जुड़ाव सभी मिलान और गैर-मिलान वाली पंक्तियों को लाता है, और *फिर* मैचों को खत्म करने के लिए एक फ़िल्टर लागू किया जाता है:
बाएं बाहरी शामिल हों
एक अधिक विशिष्ट विकल्प है
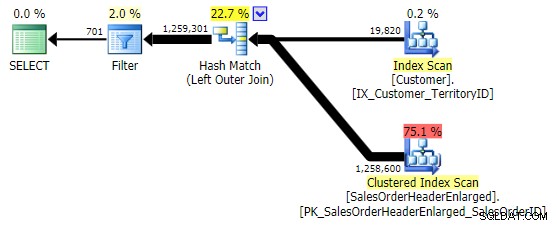
बाएं बाहरी जॉइनजहां दाहिनी ओरNULLहै . इस मामले में क्वेरी होगी:चुनें c.CustomerID from Sales.Customer as cLEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged as hON c.CustomerID =h.CustomerIDWHERE h.CustomerID IS NULL;यह वही परिणाम देता है; हालाँकि, OUTER APPLY की तरह, यह सभी पंक्तियों में शामिल होने की एक ही तकनीक का उपयोग करता है, और उसके बाद ही मैचों को समाप्त करता है:
हालांकि, आपको सावधान रहने की जरूरत है कि आप
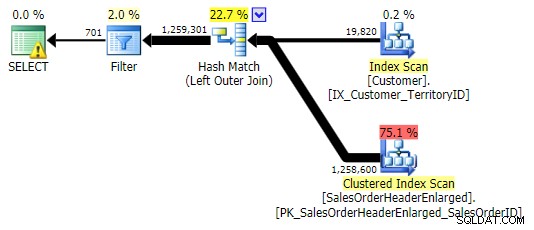
NULL. के लिए किस कॉलम की जांच करते हैं . इस मामले मेंCustomerIDतार्किक विकल्प है क्योंकि यह जॉइनिंग कॉलम है; यह अनुक्रमित भी होता है। मैंSalesOrderIDpicked चुन सकता था , जो कि क्लस्टरिंग कुंजी है, इसलिए यहCustomerID. पर अनुक्रमणिका में भी है . लेकिन मैं एक और कॉलम चुन सकता था जो शामिल होने के लिए उपयोग की जाने वाली अनुक्रमणिका में नहीं है (या बाद में हटा दिया जाता है), जिससे एक अलग योजना बनती है। या यहां तक कि एक NULLable कॉलम, जो गलत (या कम से कम अप्रत्याशित) परिणामों की ओर ले जाता है, क्योंकि उस पंक्ति के बीच अंतर करने का कोई तरीका नहीं है जो मौजूद नहीं है और एक पंक्ति जो मौजूद है लेकिन जहां वह कॉलमNULL. और पाठक/डेवलपर/समस्या निवारक के लिए यह स्पष्ट नहीं हो सकता है कि यह मामला है। तो मैं भी इन तीनों का परीक्षण करूँगाWHEREखंड:जहाँ h.SalesOrderID खाली है; -- संकुलित, इसलिए अनुक्रमणिका का भाग जहाँ h.SubTotal IS NULL है; - अशक्त नहीं, सूचकांक का हिस्सा नहीं जहां h.Comment IS NULL; -- अशक्त, अनुक्रमणिका का भाग नहींपहली भिन्नता ऊपर की तरह ही योजना बनाती है। अन्य दो मर्ज जॉइन के बजाय हैश जॉइन चुनते हैं, और
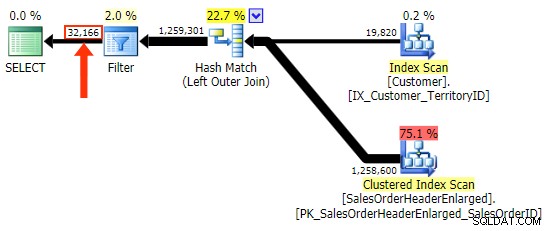
ग्राहकमें एक संकरा इंडेक्स चुनते हैं तालिका, भले ही क्वेरी अंततः पृष्ठों की समान संख्या और डेटा की मात्रा को पढ़कर समाप्त हो जाती है। हालांकि, जबकिh.SubTotalभिन्नता सही परिणाम देती है:
एच.टिप्पणीभिन्नता नहीं है, क्योंकि इसमें वे सभी पंक्तियाँ शामिल हैं जहाँh.Comment IS NULL. है , साथ ही वे सभी पंक्तियाँ जो किसी भी ग्राहक के लिए मौजूद नहीं थीं। फ़िल्टर लागू होने के बाद मैंने आउटपुट में पंक्तियों की संख्या में सूक्ष्म अंतर को हाइलाइट किया है:
फ़िल्टर में कॉलम चयन के बारे में सावधान रहने की आवश्यकता के अलावा, मुझे
बाएं बाहरी जॉइनके साथ दूसरी समस्या है प्रपत्र यह है कि यह स्व-दस्तावेजीकरण नहीं है, उसी तरह जैसे किFROM dbo.table_a, dbo.table_b WHERE ...के "पुराने-शैली" रूप में एक आंतरिक जुड़ाव होता है। स्व-दस्तावेजीकरण नहीं है। इसके द्वारा मेरा मतलब है कि जब इसेWHERE. पर धकेला जाता है, तो शामिल होने के मानदंड को भूलना आसान होता है खंड, या इसके लिए अन्य फ़िल्टर मानदंडों के साथ मिश्रित होने के लिए। मुझे एहसास है कि यह काफी व्यक्तिपरक है, लेकिन वहां है।छोड़कर
यदि हम सभी में रुचि रखते हैं तो जॉइन कॉलम (जो परिभाषा के अनुसार दोनों तालिकाओं में है), हम
EXCEPTका उपयोग कर सकते हैं - एक विकल्प जो इन वार्तालापों में अधिक दिखाई नहीं देता (शायद इसलिए - आमतौर पर - आपको उन स्तंभों को शामिल करने के लिए क्वेरी को विस्तारित करने की आवश्यकता होती है जिनकी आप तुलना नहीं कर रहे हैं):Sales से CustomerID चुनें।यह ठीक उसी योजना के साथ आता है जैसे
NOT INऊपर भिन्नता:
एक बात का ध्यान रखें कि
EXCEPTएक निहितDISTINCT. शामिल है - इसलिए यदि आपके पास ऐसे मामले हैं जहां आप "बाएं" तालिका में समान मान वाली एकाधिक पंक्तियां चाहते हैं, तो यह फ़ॉर्म उन डुप्लिकेट को समाप्त कर देगा। इस विशिष्ट मामले में कोई समस्या नहीं है, बस कुछ ध्यान में रखना है - जैसेUNIONबनामयूनियन ऑल।मौजूद नहीं है
इस पैटर्न के लिए मेरी प्राथमिकता निश्चित रूप से है
NOTEXISTS:Sales से CustomerID का चयन करें। जहां मौजूद नहीं है वहां के रूप में ग्राहक (Sales.SalesOrderHeaderEnlarged जहां CustomerID =c.CustomerID);(और हाँ, मैं
SELECT 1. का उपयोग करता हूं इसके बजायचुनें *... प्रदर्शन कारणों से नहीं, क्योंकि SQL सर्वर परवाह नहीं करता है कि आपEXISTSके अंदर किस कॉलम का उपयोग करते हैं और उन्हें अनुकूलित करता है, लेकिन केवल इरादे को स्पष्ट करने के लिए:यह मुझे याद दिलाता है कि यह "सबक्वायरी" वास्तव में कोई डेटा नहीं लौटाता है।)इसका प्रदर्शन
NOT IN. के समान है औरछोड़कर, और यह एक समान योजना तैयार करता है, लेकिन एनयूएलएल या डुप्लीकेट के कारण संभावित मुद्दों से ग्रस्त नहीं है:
प्रदर्शन परीक्षण
मैंने यह प्रमाणित करने के लिए कि
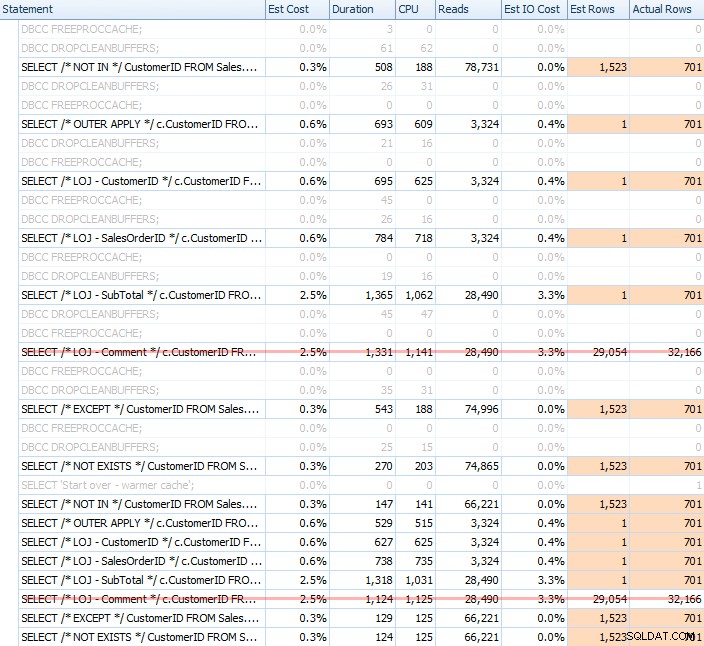
NOTEXISTSके बारे में मेरी लंबे समय से चली आ रही धारणा को प्रमाणित करने के लिए, ठंडे और गर्म दोनों कैश के साथ, कई परीक्षण चलाए। सही चुनाव होना सही रहा। सामान्य आउटपुट इस तरह दिखता था:
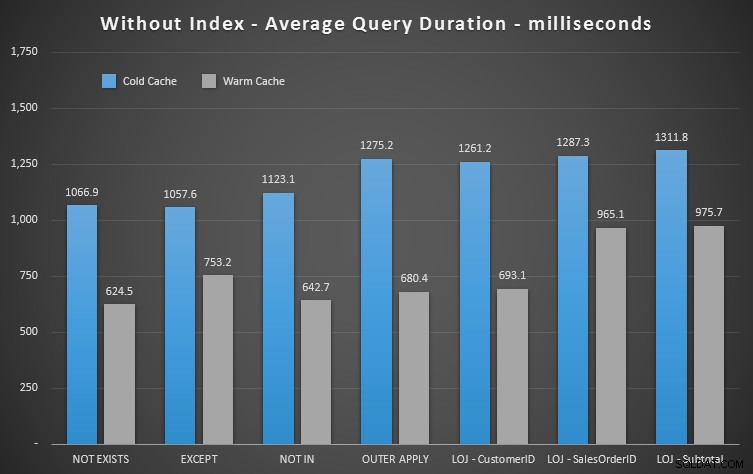
ग्राफ़ पर 20 रन का औसत प्रदर्शन दिखाते समय मैं मिश्रण से गलत परिणाम निकालूंगा (मैंने इसे केवल यह प्रदर्शित करने के लिए शामिल किया था कि परिणाम कितने गलत हैं), और मैंने यह सुनिश्चित करने के लिए परीक्षणों में अलग-अलग क्रम में प्रश्नों को निष्पादित किया। कि एक प्रश्न पिछली क्वेरी के कार्य से लगातार लाभान्वित नहीं हो रहा था। अवधि पर ध्यान केंद्रित करते हुए, यहां परिणाम हैं:
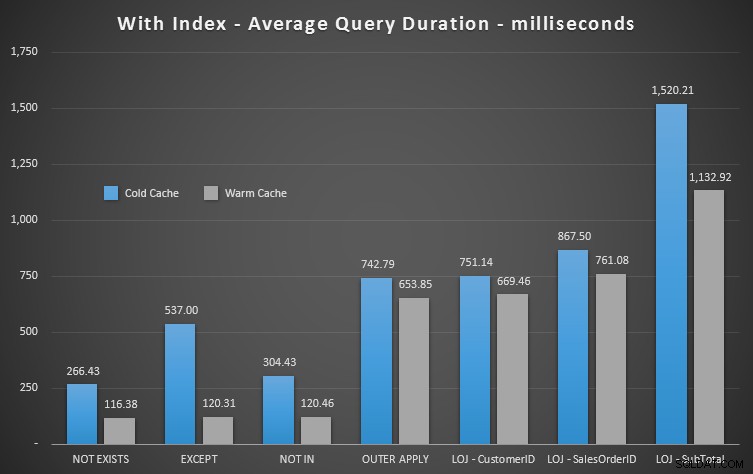
यदि हम अवधि को देखते हैं और पढ़ने को अनदेखा करते हैं, तो NOT EXISTS आपका विजेता है, लेकिन बहुत अधिक नहीं। EXCEPT और NOT IN बहुत पीछे नहीं हैं, लेकिन फिर से आपको यह निर्धारित करने के लिए प्रदर्शन से अधिक देखने की जरूरत है कि क्या ये विकल्प मान्य हैं, और अपने परिदृश्य में परीक्षण करें।
अगर कोई सपोर्टिंग इंडेक्स न हो तो क्या करें?
ऊपर दिए गए प्रश्न, निश्चित रूप से,
Sales.SalesOrderHeaderEnlarged.CustomerIDके सूचकांक से लाभान्वित होते हैं। . यदि हम इस सूचकांक को छोड़ दें तो ये परिणाम कैसे बदलते हैं? इंडेक्स छोड़ने के बाद, मैंने फिर से परीक्षणों का एक ही सेट चलाया:DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ऑन [सेल्स]।[SalesOrderHeaderEnlarged];इस बार विभिन्न तरीकों के बीच प्रदर्शन के मामले में बहुत कम विचलन था। पहले मैं प्रत्येक विधि के लिए योजनाएं दिखाऊंगा (जिनमें से अधिकांश, आश्चर्य की बात नहीं है, लापता सूचकांक की उपयोगिता को इंगित करते हैं जिसे हमने अभी-अभी गिराया है)। फिर मैं एक नया ग्राफ़ दिखाऊंगा जिसमें कोल्ड कैश और वार्म कैश दोनों के साथ प्रदर्शन प्रोफ़ाइल को दर्शाया गया है।
में नहीं, इसके अलावा, मौजूद नहीं है (तीनों समान थे)
बाहरी आवेदन
बाएं बाहरी जॉइन (पंक्तियों की संख्या को छोड़कर तीनों समान थे)
प्रदर्शन परिणाम
जब हम इन नए परिणामों को देखते हैं तो हम तुरंत देख सकते हैं कि सूचकांक कितना उपयोगी है। एक मामले को छोड़कर सभी मामलों में (बाएं बाहरी जुड़ाव जो वैसे भी सूचकांक के बाहर जाता है), परिणाम स्पष्ट रूप से खराब होते हैं जब हमने सूचकांक को गिरा दिया है:
तो हम देख सकते हैं कि, जबकि कम ध्यान देने योग्य प्रभाव है,
NOTEXISTSअवधि के मामले में अभी भी आपका मामूली विजेता है। और उन स्थितियों में जहां अन्य दृष्टिकोण स्कीमा अस्थिरता के लिए अतिसंवेदनशील होते हैं, यह आपकी सबसे सुरक्षित पसंद भी है।निष्कर्ष
यह आपको बताने का एक बहुत लंबा तरीका था, तालिका ए में सभी पंक्तियों को खोजने के पैटर्न के लिए जहां तालिका बी में कुछ शर्त मौजूद नहीं है,
मौजूद नहीं हैआम तौर पर आपका सबसे अच्छा विकल्प होने जा रहा है। लेकिन, हमेशा की तरह, आपको अपने स्कीमा, डेटा और हार्डवेयर का उपयोग करके और अपने स्वयं के कार्यभार के साथ मिश्रित करके, अपने स्वयं के वातावरण में इन प्रतिमानों का परीक्षण करने की आवश्यकता है।