पिछले लेख में हमने स्टार स्कीमा मॉडल पर चर्चा की थी। डेटा वेयरहाउस मॉडलिंग में इसके महत्व के संदर्भ में स्नोफ्लेक स्कीमा स्टार स्कीमा के बगल में है। इसे स्टार स्कीमा से विकसित किया गया था, और यह अपने पूर्ववर्ती पर कुछ फायदे प्रदान करता है। लेकिन ये फायदे एक कीमत पर आते हैं। इस लेख में, हम चर्चा करेंगे कि स्नोफ्लेक स्कीमा का उपयोग कब और कैसे किया जाए।
द स्नोफ्लेक स्कीमा
स्नोफ्लेक स्कीमा का नाम इस तथ्य से आता है कि आयाम तालिकाएं शाखा से बाहर निकलती हैं और बर्फ के टुकड़े की तरह दिखती हैं। जब हम ऊपर दिए गए मॉडल को देखते हैं, तो हम देखेंगे कि यह एक तथ्य तालिका है जो कुछ आयाम तालिकाओं से घिरी हुई है, जिनमें से कुछ उपरोक्त शाखाओं में बंटी हुई हैं। स्टार स्कीमा के विपरीत, स्नोफ्लेक स्कीमा में आयाम तालिकाओं की अपनी श्रेणियां हो सकती हैं।
स्नोफ्लेक स्कीमा के पीछे सत्तारूढ़ विचार यह है कि आयाम तालिकाएँ पूरी तरह से सामान्यीकृत हैं। प्रत्येक आयाम तालिका का वर्णन एक या अधिक लुकअप तालिकाओं द्वारा किया जा सकता है। प्रत्येक लुकअप तालिका को एक या अधिक अतिरिक्त लुकअप तालिकाओं द्वारा वर्णित किया जा सकता है। यह तब तक दोहराया जाता है जब तक कि मॉडल पूरी तरह से सामान्य न हो जाए। स्टार स्कीमा आयाम तालिकाओं को सामान्य करने की प्रक्रिया को स्नोफ्लेकिंग कहा जाता है।
आप इस लेख में सामान्यीकरण के बारे में बहुत कुछ सुन रहे होंगे। सामान्यीकरण क्या है? मूल रूप से, यह एक डेटाबेस को इस तरह से व्यवस्थित कर रहा है जो अतिरेक को कम करता है और डेटा अखंडता की रक्षा करता है। सामान्यीकरण और असामान्यीकरण के बारे में अधिक जानने के लिए इस पोस्ट को देखें।
स्नोफ्लेक स्कीमा उदाहरण:बिक्री मॉडल
पहले, हम एक काल्पनिक बिक्री विभाग के मॉडल के लिए एक स्टार स्कीमा का उपयोग करते थे - यह बिक्री गतिविधियों और परिणामों को ट्रैक करने के लिए उपयोग किए जाने वाले डेटा मार्ट के समान होगा। मॉडल के पांच आयाम हैं:उत्पाद , समय , स्टोर , बिक्री टाइप करें और कर्मचारी . fact_sales टेबल, कीमत और मात्रा आयाम तालिकाओं में मानों के आधार पर संग्रहीत और समूहीकृत होते हैं। एक पुनश्चर्या के लिए, नीचे दिए गए स्टार स्कीमा बिक्री मॉडल पर एक नज़र डालें:
यहाँ वही मॉडल है जो स्नोफ्लेक स्कीमा के रूप में व्यवस्थित है:
dim_employee और dim_sales_type आयाम तालिकाएं बिल्कुल स्टार स्कीमा मॉडल की तरह ही हैं क्योंकि वे पहले से ही सामान्यीकृत हैं।
दूसरी ओर, हमने बाकी आयाम तालिकाओं पर सामान्यीकरण नियम लागू किए।


dim_product स्टार स्कीमा से आयाम तालिका को स्नोफ्लेक मॉडल में दो तालिकाओं में विभाजित किया गया है। dim_product_type dim_product टेबल। इसका उपयोग करते हुए, हमने कुछ डेटा अखंडता समस्याओं से बचा लिया।
यह मान लेना तर्कसंगत है कि हमारे पास पहले से ही सभी उत्पाद नाम और उनके संबंधित प्रकार ईटीएल प्रक्रिया के हिस्से के रूप में सम्मिलित हैं, लेकिन मान लीजिए कि हमें अधिक उत्पाद नाम और प्रकार जोड़ने की आवश्यकता है। एक स्टार स्कीमा में हम गलती से गलत उत्पाद प्रकार को तालिका में दर्ज कर सकते हैं। स्नोफ्लेक स्कीमा में:
- यदि हमें नए उत्पाद प्रकार का नाम मिलता है, तो हम एक नया उत्पाद प्रकार जोड़ सकते हैं और फिर उस प्रकार को नए जोड़े गए रिकॉर्ड से जोड़ सकते हैं। हालांकि, इसके परिणामस्वरूप उपयोगकर्ता गलत जानकारी दर्ज कर सकता है, जैसे कि स्टार स्कीमा में।
- हम यह देखने के लिए जांच कर सकते हैं कि क्या उत्पाद नाम जिसे हम जोड़ना चाहते हैं वह पहले से मौजूद है। यदि हां, तो हम इसकी आईडी प्राप्त कर सकते हैं; यदि नहीं, तो एक चेतावनी सामने आएगी जिसमें हमसे पूछा जाएगा कि क्या हम एक नया उत्पाद और संबंधित प्रकार जोड़ना चाहते हैं।

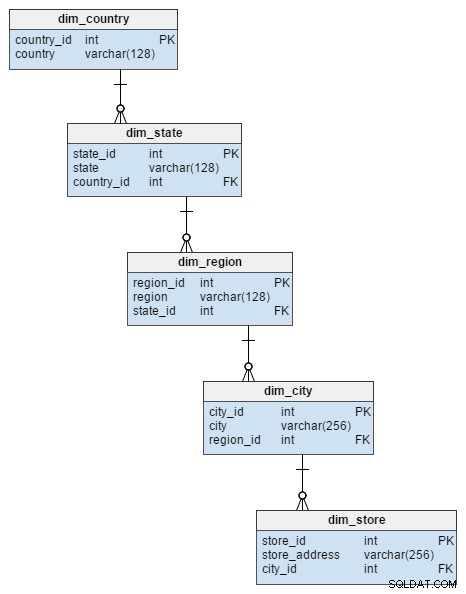
dim_store स्टार स्कीमा से आयाम तालिका को स्नोफ्लेक स्कीमा में 5 तालिकाओं द्वारा दर्शाया गया है। ये dim_store टेबल। इस तालिका को सामान्य करने से न केवल डेटा अखंडता जोखिम से बचा जा सकता है, बल्कि कुछ डिस्क स्थान भी बचाया जा सकता है।
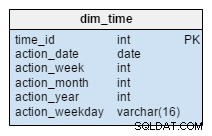
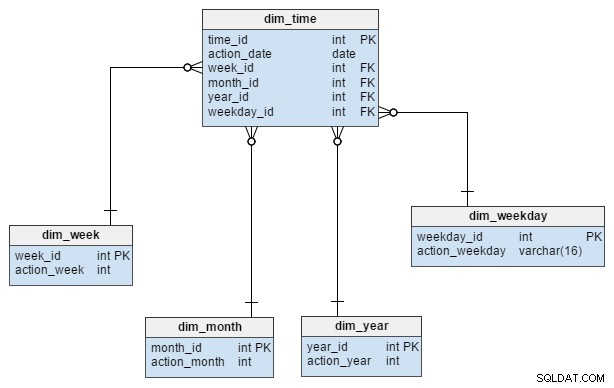
dim_time आयाम को पांच तालिकाओं के साथ दर्शाया गया है। हम dim_week . के बारे में सोच सकते हैं , dim_month , dim_year और dim_weekday शब्दकोशों के रूप में तालिकाएँ जो dim_time टेबल।
dim_week , dim_month , dim_year और dim_weekday टेबल चार अलग-अलग पदानुक्रम हैं जिनका उपयोग हमारे समय के आयाम का वर्णन करने के लिए किया जाता है। जरूरत पड़ने पर हम क्वार्टर या अन्य संबंधित टेबल जैसे और आयाम जोड़ सकते हैं। इस उदाहरण में, dim_month एक शब्दकोश है जिसमें 12 महीने हैं; केवल इस आयाम से, हमारे पास यह जानने का कोई तरीका नहीं है कि वह महीना किस वर्ष का है; यह dim_year टेबल।
स्नोफ्लेक स्कीमा उदाहरण:आपूर्ति आदेश मॉडल
हमने जिस अन्य डेटा मार्ट पर चर्चा की वह आपूर्ति ऑर्डर के लिए था। विचार निम्नलिखित चार आयामों के लिए सभी आपूर्ति आदेश डेटा को संग्रहीत और एकत्रित करना है:उत्पाद , समय , आपूर्तिकर्ता और कर्मचारी . एक बार फिर, हम संबंधित स्टार स्कीमा पर एक नज़र डालेंगे:
इसे स्नोफ्लेक स्कीमा में बदलने पर, हमें निम्न मॉडल मिलता है:
बिक्री मॉडल के लिए बताए गए समान सामान्यीकरण नियम dim_product , dim_time और dim_supplier आयाम तालिकाएँ।
स्नोफ्लेक स्कीम के फायदे और नुकसान
दो मुख्य लाभ हैं स्नोफ्लेक स्कीमा के लिए:
- बेहतर डेटा गुणवत्ता (डेटा अधिक संरचित है, इसलिए डेटा अखंडता की समस्याएं कम हो जाती हैं)
- असामान्यीकृत मॉडल में कम डिस्क स्थान का उपयोग किया जाता है
सबसे उल्लेखनीय नुकसान स्नोफ्लेक मॉडल के लिए यह है कि इसके लिए अधिक जटिल प्रश्नों की आवश्यकता होती है। ये क्वेरीज़, उनके जुड़ने की संख्या में वृद्धि के साथ, प्रदर्शन को उल्लेखनीय रूप से कम कर सकती हैं।
हम स्नोफ्लेक स्कीमा बिक्री मॉडल के लिए स्टार स्कीमा लेख में उपयोग की गई उसी क्वेरी को फिर से लिखेंगे। 2016 में बर्लिन स्टोर में बेचे जाने वाले सभी फ़ोन-प्रकार के उत्पादों की मात्रा वापस करने के लिए आवश्यक क्वेरी यहां दी गई है:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
द स्टारफ्लेक स्कीमा
स्टारफ्लेक स्कीमा स्नोफ्लेक और स्टार स्कीमा का एक संयोजन है। हम इसे एक स्नोफ्लेक स्कीमा के रूप में देख सकते हैं जिसमें कुछ आयाम तालिकाएं असामान्य हैं। जब सही तरीके से उपयोग किया जाता है, तो स्टारफ्लेक स्कीमा दोनों दुनिया का सबसे अच्छा दृष्टिकोण दे सकता है। जाहिर है, मॉडल के स्नोफ्लेक भाग को डिस्क स्थान बचाना चाहिए, जबकि स्टार भाग को प्रदर्शन में सुधार करना चाहिए।
ऊपर दिया गया मॉडल मूल रूप से एक स्नोफ्लेक मॉडल है जिसमें एक असामान्य dim_time टेबल। चूंकि यह स्कीमा आवश्यक क्वेरी जॉइन की संख्या को कम करता है, यह प्रदर्शन में सुधार कर सकता है। दूसरी ओर, हम डिस्क स्थान की उल्लेखनीय मात्रा नहीं खोएंगे, क्योंकि अधिकांश तालिका विशेषताएँ और विदेशी कुंजी विशेषताएँ int साझा करती हैं। टाइप करें।
गैलेक्सी स्कीमा
डेटा वेयरहाउसिंग में, एक आकाशगंगा स्कीमा तब होती है जब दो या दो से अधिक तथ्य तालिकाएँ एक या अधिक आयाम तालिकाएँ साझा करती हैं। इस स्कीमा का उपयोग करने का एक कारण डिस्क स्थान को बचाना है। हमने नीचे एक नमूना आकाशगंगा स्कीमा बनाया है:
यहां, हमारे पास दो तथ्य तालिकाएं हैं, fact_sales और fact_supply_order , जो सीधे तीन आयाम तालिकाएं साझा करती हैं:dim_product , dim_employee और dim_time . ध्यान दें कि यहां तक कि dim_store और dim_supplier समान लुकअप तालिका साझा करें, dim_city ।
हम इस तरह से जगह बचाएंगे, लेकिन दो डेटा मार्ट (इस मामले में, बिक्री और आपूर्ति ऑर्डर) को एक गैलेक्सी स्कीमा में शामिल करने से पहले हमें कुछ बातों को ध्यान में रखना होगा:
- क्या उनके साथ जुड़ने के पीछे कोई तर्क है? उदा. क्या दोनों डेटा मार्ट का उपयोग एक ही विभाग द्वारा किया जाएगा?
- क्या हमें यकीन है कि हमें बिल्कुल समान आयाम और दानेदार बनाने की आवश्यकता है दोनों डेटा मार्ट के लिए?
स्नोफ्लेक स्कीमा का उपयोग अक्सर डेटा मॉडलिंग में किया जाता है। यह उन परिस्थितियों में सही विकल्प हो सकता है जहां प्रदर्शन से डिस्क स्थान अधिक महत्वपूर्ण है। यदि हम अंतरिक्ष-बचत और प्रदर्शन के बीच संतुलन चाहते हैं, तो हम स्टारफ्लेक स्कीमा का उपयोग कर सकते हैं। फिर भी, किसी विशिष्ट समस्या के लिए सही फिट कई मापदंडों पर निर्भर करता है। यह आईटी के उन क्षेत्रों में से एक है जहां हम सर्वोत्तम समाधान के साथ आने के लिए कारकों के साथ 'खेल' सकते हैं।



