हम सभी खोज इंजन की वर्तनी की गलतियों, नाम वर्तनी के अंतर, या किसी अन्य स्थिति में खोज इंजन की क्षमता से खराब हो गए हैं, जहां खोज शब्द उन पृष्ठों पर मेल खा सकते हैं जिनके लेखक किसी शब्द की अलग वर्तनी का उपयोग करना पसंद कर सकते हैं। हमारे अपने डेटाबेस-संचालित अनुप्रयोगों में ऐसी सुविधाओं को जोड़ने से हमारे अनुप्रयोगों को समान रूप से समृद्ध और बढ़ाया जा सकता है, और जबकि वाणिज्यिक संबंधपरक डेटाबेस प्रबंधन प्रणाली (आरडीबीएमएस) प्रसाद इस समस्या के लिए अपने स्वयं के पूर्ण विकसित अनुकूलित समाधान प्रदान करते हैं, इन उपकरणों की लाइसेंसिंग लागत से बाहर हो सकता है छोटे डेवलपर्स या छोटी सॉफ्टवेयर विकास फर्मों तक पहुंचें।
कोई यह तर्क दे सकता है कि इसके बजाय एक वर्तनी परीक्षक का उपयोग करके ऐसा किया जा सकता है। हालाँकि, किसी नाम या अन्य शब्द की सही, लेकिन वैकल्पिक, वर्तनी का मिलान करते समय एक वर्तनी परीक्षक आमतौर पर किसी काम का नहीं होता है। ध्वनि द्वारा मिलान इस कार्यात्मक अंतर को भरता है। यह आज के प्रोग्रामिंग ट्यूटोरियल का विषय है:मेटाफ़ोन का उपयोग करके पायथन के साथ ध्वनियों को कैसे क्वेरी करें।
साउंडेक्स क्या है?
साउंडेक्स 20 वीं शताब्दी की शुरुआत में अमेरिकी जनगणना के लिए एक साधन के रूप में विकसित किया गया था कि वे कैसे ध्वनि के आधार पर नामों से मेल खाते हैं। इसके बाद विभिन्न फोन कंपनियों द्वारा ग्राहकों के नामों का मिलान करने के लिए इसका इस्तेमाल किया गया। यह अमेरिकी अंग्रेजी वर्तनी और उच्चारण तक सीमित होने के बावजूद आज तक ध्वन्यात्मक डेटा मिलान के लिए उपयोग किया जा रहा है। यह अंग्रेजी अक्षरों तक ही सीमित है। अधिकांश RDBMS, जैसे SQL सर्वर और Oracle, MySQL और इसके वेरिएंट के साथ, एक Soundex फ़ंक्शन को लागू करते हैं और, इसकी सीमाओं के बावजूद, इसका उपयोग कई गैर-अंग्रेज़ी शब्दों से मेल खाने के लिए किया जाता है।
डबल मेटाफोन क्या है?
मेटाफ़ोन एल्गोरिथ्म 1990 में विकसित किया गया था और यह साउंडेक्स की कुछ सीमाओं को पार करता है। 2000 में, एक बेहतर फॉलो-ऑन, डबल मेटाफ़ोन , विकसित किया गया था। डबल मेटाफ़ोन एक प्राथमिक और द्वितीयक मान देता है जो दो तरीकों से मेल खाता है एक शब्द का उच्चारण किया जा सकता है। आज तक यह एल्गोरिथम बेहतर ओपन-सोर्स ध्वन्यात्मक एल्गोरिदम में से एक है। मेटाफोन 3 को 2009 में डबल मेटाफोन में सुधार के रूप में जारी किया गया था, लेकिन यह एक व्यावसायिक उत्पाद है।
दुर्भाग्य से, ऊपर उल्लिखित कई प्रमुख आरडीबीएमएस डबल मेटाफोन लागू नहीं करते हैं, और अधिकांश प्रमुख स्क्रिप्टिंग भाषाएं डबल मेटाफ़ोन का समर्थित कार्यान्वयन प्रदान नहीं करती हैं। हालांकि, पायथन एक ऐसा मॉड्यूल प्रदान करता है जो डबल मेटाफोन लागू करता है।
इस पायथन प्रोग्रामिंग ट्यूटोरियल में प्रस्तुत उदाहरण मारियाडीबी संस्करण 10.5.12 और पायथन 3.9.2 का उपयोग करते हैं, दोनों काली/डेबियन लिनक्स पर चल रहे हैं।
पायथन में डबल मेटाफोन कैसे जोड़ें
किसी भी पायथन मॉड्यूल की तरह, डबल मेटाफोन को स्थापित करने के लिए पाइप टूल का उपयोग किया जा सकता है। सिंटैक्स आपके पायथन इंस्टॉलेशन पर निर्भर करता है। एक सामान्य डबल मेटाफ़ोन इंस्टॉल निम्न उदाहरण जैसा दिखता है:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
ध्यान दें, कि अतिरिक्त पूंजीकरण जानबूझकर किया गया है। निम्नलिखित कोड पायथन में डबल मेटाफोन का उपयोग करने का एक उदाहरण है:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
उपरोक्त पायथन लिपि आपके एकीकृत विकास वातावरण (आईडीई) या कोड संपादक में चलने पर निम्नलिखित आउटपुट देती है:
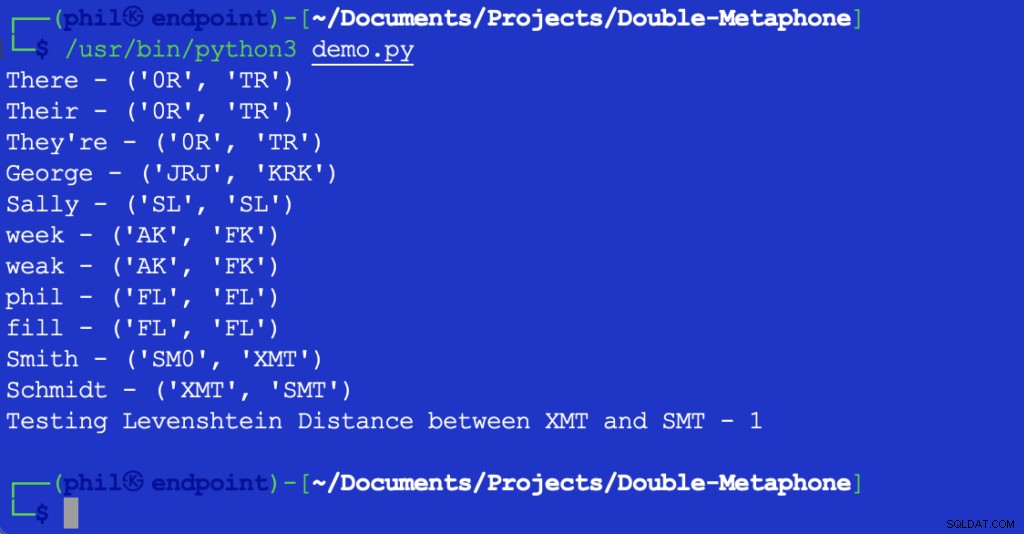
चित्र 1 - डेमो स्क्रिप्ट का आउटपुट
जैसा कि यहां देखा जा सकता है, प्रत्येक शब्द का प्राथमिक और द्वितीयक दोनों ध्वन्यात्मक मूल्य होता है। वे शब्द जो प्राथमिक या द्वितीयक दोनों मानों से मेल खाते हों, ध्वन्यात्मक मेल कहलाते हैं। ऐसे शब्द जो कम से कम एक ध्वन्यात्मक मान साझा करते हैं, या जो किसी भी ध्वन्यात्मक मूल्य में वर्णों के पहले जोड़े को साझा करते हैं, उन्हें ध्वन्यात्मक रूप से एक दूसरे के निकट कहा जाता है।
अधिकांश प्रदर्शित अक्षर उनके अंग्रेजी उच्चारण के अनुरूप हैं। X KS . के अनुरूप हो सकता है , एसएच , या सी . 0 वें . से मेल खाती है द . में ध्वनि या वहां . स्वरों का मिलान केवल शब्द के आरंभ में ही किया जाता है। क्षेत्रीय लहजे में अनगिनत अंतर के कारण, यह कहना संभव नहीं है कि शब्द एक समान सटीक मिलान हो सकते हैं, भले ही उनके समान ध्वन्यात्मक मान हों।
पायथन के साथ ध्वन्यात्मक मूल्यों की तुलना करना
ऐसे कई ऑनलाइन संसाधन हैं जो डबल मेटाफ़ोन एल्गोरिथम के पूर्ण कामकाज का वर्णन कर सकते हैं; हालांकि, इसका उपयोग करने के लिए यह आवश्यक नहीं है क्योंकि हम तुलना . में अधिक रुचि रखते हैं परिकलित मान, मानों की गणना करने में हमारी रुचि से अधिक है। जैसा कि पहले कहा गया है, यदि दो शब्दों के बीच कम से कम एक मान समान है, तो यह कहा जा सकता है कि ये मान ध्वन्यात्मक मिलान हैं। , और ध्वन्यात्मक मान जो समान . हैं ध्वन्यात्मक रूप से करीब हैं ।
निरपेक्ष मूल्यों की तुलना करना आसान है, लेकिन समान होने के लिए तार कैसे निर्धारित किए जा सकते हैं? हालांकि ऐसी कोई तकनीकी सीमाएं नहीं हैं जो आपको बहु-शब्द स्ट्रिंग्स की तुलना करने से रोकती हैं, ये तुलनाएं आमतौर पर अविश्वसनीय होती हैं। एकल शब्दों की तुलना करने के लिए बने रहें।
लेवेनशेटिन दूरियां क्या हैं?
लेवेनशेटिन दूरी दो स्ट्रिंग्स के बीच एकल वर्णों की संख्या है जिसे एक स्ट्रिंग में बदला जाना चाहिए ताकि यह दूसरी स्ट्रिंग से मेल खा सके। तारों की एक जोड़ी जिसमें कम लेवेनशेटिन दूरी होती है, एक दूसरे के समान होती है जो तारों की एक जोड़ी की तुलना में अधिक होती है जिसमें उच्च लेवेनशेटिन दूरी होती है। लेवेनशेटिन दूरी हैमिंग दूरी . के समान है , लेकिन बाद वाला समान लंबाई के स्ट्रिंग्स तक सीमित है, क्योंकि डबल मेटाफ़ोन ध्वन्यात्मक मान लंबाई में भिन्न हो सकते हैं, लेवेनशेटिन दूरी का उपयोग करके इनकी तुलना करना अधिक समझ में आता है।
पायथन लेवेनशेटिन डिस्टेंस लाइब्रेरी
पायथन मॉड्यूल के माध्यम से लेवेनशेटिन दूरी गणना का समर्थन करने के लिए पायथन को बढ़ाया जा सकता है:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
ध्यान दें, जैसा कि DoubleMetaphone . की स्थापना के साथ होता है ऊपर, पाइप . को कॉल का सिंटैक्स भिन्न हो सकते हैं। पाइथन-लेवेनशेटिन मॉड्यूल लेवेनशेटिन दूरी की गणना की तुलना में कहीं अधिक कार्यक्षमता प्रदान करता है।
नीचे दिया गया कोड पायथन में लेवेनशेटिन दूरी गणना के लिए एक परीक्षण दिखाता है:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
इस स्क्रिप्ट को निष्पादित करने से निम्न आउटपुट प्राप्त होता है:
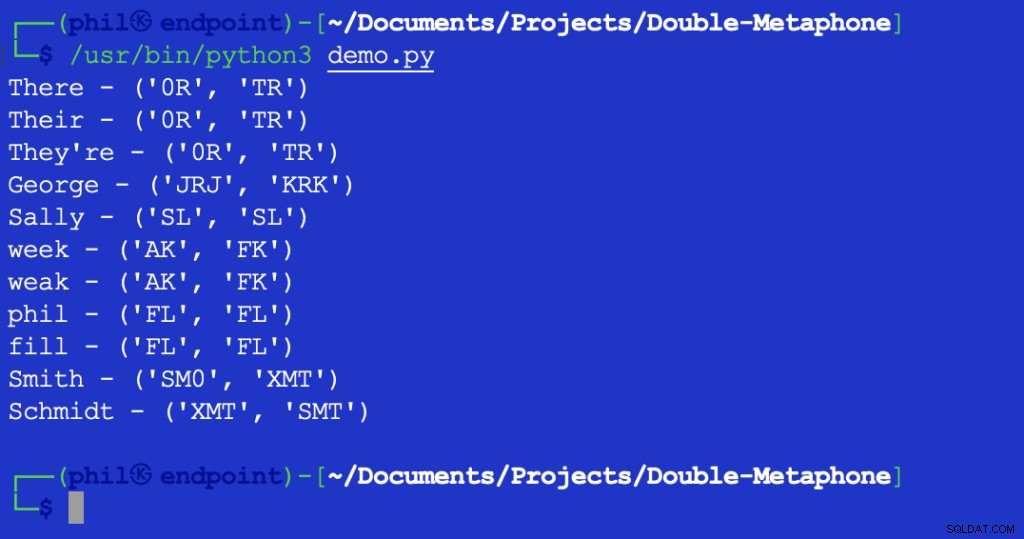
चित्र 2 - लेवेनशेटिन दूरी परीक्षण का आउटपुट
1 . का लौटाया गया मान इंगित करता है कि XMT . के बीच एक वर्ण है और श्रीमती वह अलग बात है। इस मामले में, यह दोनों स्ट्रिंग्स में पहला वर्ण है।
पायथन में डबल मेटाफ़ोन की तुलना करना
जो कुछ भी है वह ध्वन्यात्मक तुलनाओं के सभी-और-अंत नहीं है। यह ऐसी तुलना करने के कई तरीकों में से एक है। किन्हीं दो दिए गए स्ट्रिंग्स की ध्वन्यात्मक मंहगाई की प्रभावी रूप से तुलना करने के लिए, एक स्ट्रिंग के प्रत्येक डबल मेटाफ़ोन ध्वन्यात्मक मान की तुलना दूसरे स्ट्रिंग के संबंधित डबल मेटाफ़ोन फ़ोनेटिक मान से की जानी चाहिए। चूंकि किसी दिए गए स्ट्रिंग के दोनों ध्वन्यात्मक मूल्यों को समान वजन दिया जाता है, तो इन तुलना मूल्यों का औसत ध्वन्यात्मक निकटता का एक अच्छा अनुमान देगा:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
कहां:
- DM1(1) :स्ट्रिंग 1 का पहला डबल मेटाफ़ोन मान,
- DM1(2) :स्ट्रिंग 1 का दूसरा डबल मेटाफ़ोन मान
- DM2(1) :स्ट्रिंग 2 का पहला डबल मेटाफ़ोन मान
- DM2(2) :स्ट्रिंग 2 का दूसरा डबल मेटाफ़ोन मान
- पीएन :ध्वन्यात्मक निकटता, कम मूल्यों के साथ उच्च मूल्यों के निकट होने के साथ। एक शून्य मान ध्वन्यात्मक समानता को इंगित करता है। इसके लिए उच्चतम मान सबसे छोटी स्ट्रिंग में अक्षरों की संख्या है।
श्मिट (XMT, SMT) . जैसे मामलों में यह फ़ॉर्मूला टूट जाता है और स्मिथ (SM0, XMT) जहां पहली स्ट्रिंग का पहला ध्वन्यात्मक मान दूसरे स्ट्रिंग के दूसरे ध्वन्यात्मक मान से मेल खाता है। ऐसी स्थितियों में, दोनों श्मिट और स्मिथ साझा मूल्य के कारण ध्वन्यात्मक रूप से समान माना जा सकता है। मंहगाई फ़ंक्शन के लिए कोड उपरोक्त सूत्र को तभी लागू करना चाहिए जब सभी चार ध्वन्यात्मक मान भिन्न हों। अलग-अलग लंबाई के तारों की तुलना करते समय सूत्र में कमजोरियां भी होती हैं।
ध्यान दें, अलग-अलग लंबाई के तारों की तुलना करने के लिए कोई एकमात्र प्रभावी तरीका नहीं है, भले ही स्ट्रिंग लंबाई में अंतर में दो स्ट्रिंग कारकों के बीच लेवेनशेटिन दूरी की गणना की जा रही हो। एक संभावित समाधान यह होगा कि दोनों स्ट्रिंग्स की तुलना दो स्ट्रिंग्स में से छोटी स्ट्रिंग्स की लंबाई तक करें।
नीचे एक उदाहरण कोड स्निपेट है जो कुछ परीक्षण नमूनों के साथ ऊपर दिए गए कोड को लागू करता है:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
नमूना पायथन कोड निम्नलिखित आउटपुट देता है:
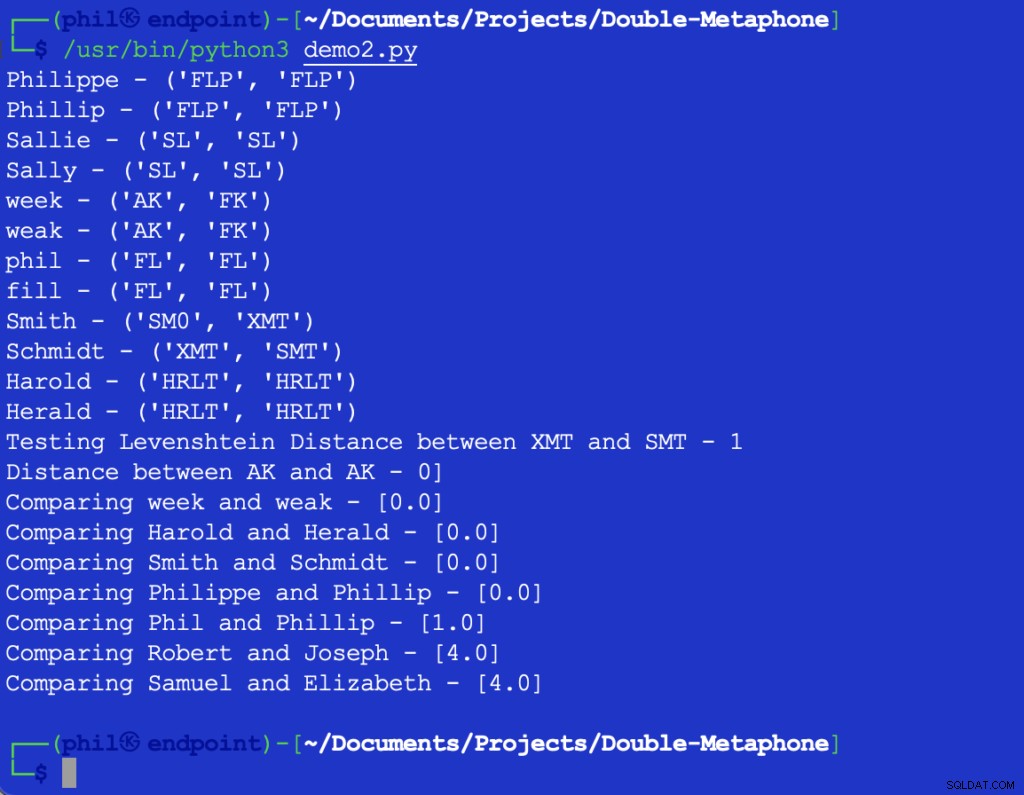
चित्र 3 - मंहगाई एल्गोरिथम का आउटपुट
नमूना सेट सामान्य प्रवृत्ति की पुष्टि करता है कि शब्दों में जितना अधिक अंतर होगा, निकटता का आउटपुट उतना ही अधिक होगा। समारोह।
पायथन में डेटाबेस एकीकरण
उपरोक्त कोड किसी दिए गए RDBMS और एक डबल मेटाफ़ोन कार्यान्वयन के बीच कार्यात्मक अंतर का उल्लंघन करता है। इसके ऊपर, महंगाई . को लागू करके पायथन में फ़ंक्शन, इसे बदलना आसान हो जाता है यदि एक अलग तुलना एल्गोरिदम को प्राथमिकता दी जाए।
निम्नलिखित MySQL/MariaDB तालिका पर विचार करें:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
अधिकांश डेटाबेस-संचालित अनुप्रयोगों में, मिडलवेयर डेटा को प्रबंधित करने के लिए SQL स्टेटमेंट बनाता है, जिसमें इसे सम्मिलित करना भी शामिल है। निम्नलिखित कोड इस तालिका में कुछ नमूना नाम सम्मिलित करेगा, लेकिन व्यवहार में, वेब या डेस्कटॉप एप्लिकेशन से कोई भी कोड जो इस तरह का डेटा एकत्र करता है, वही काम कर सकता है।
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
इस कोड को चलाने से कुछ भी प्रिंट नहीं होता है, लेकिन यह अगली सूची के उपयोग के लिए डेटाबेस में परीक्षण तालिका को पॉप्युलेट करता है। तालिका को सीधे MySQL क्लाइंट में क्वेरी करने से यह सत्यापित हो सकता है कि ऊपर दिया गया कोड काम कर रहा है:
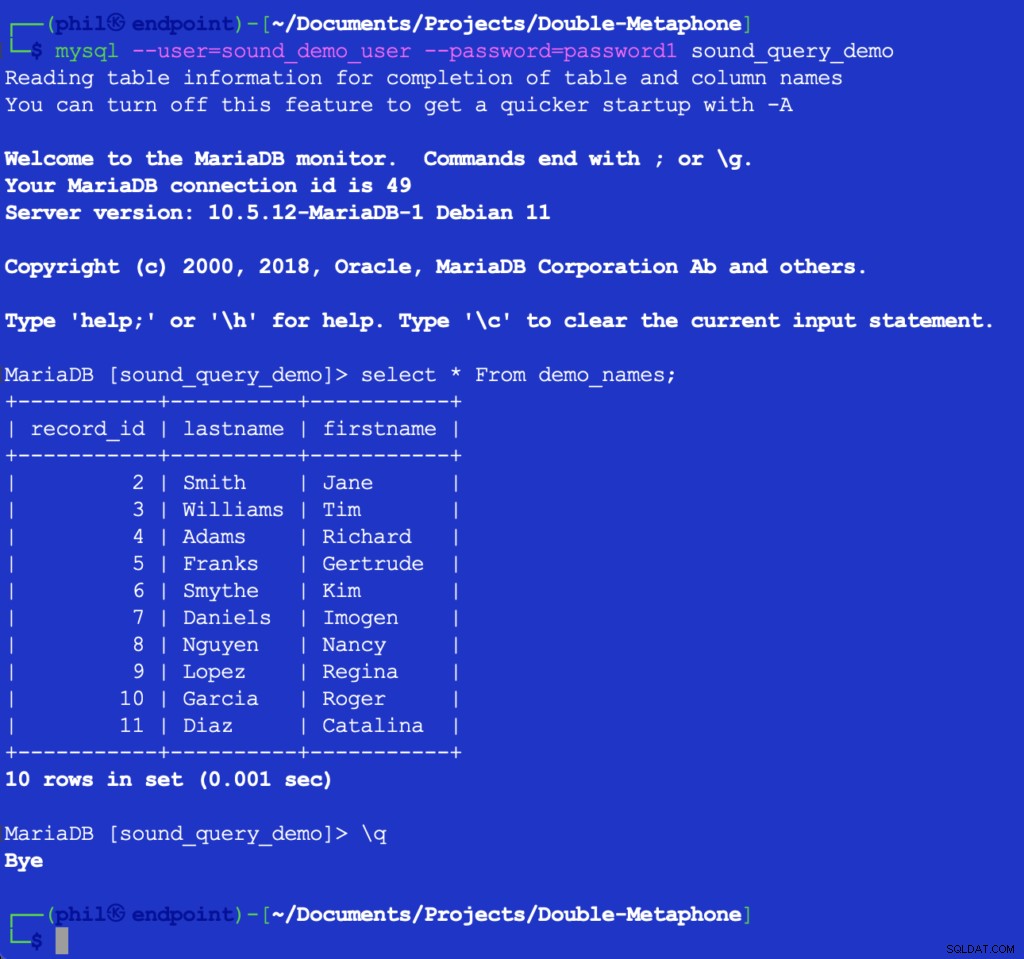
चित्र 4- सम्मिलित तालिका डेटा
नीचे दिया गया कोड उपरोक्त तालिका डेटा में कुछ तुलना डेटा फीड करेगा और इसके खिलाफ एक मंहगाई तुलना करेगा:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
इस कोड को चलाने से हमें नीचे आउटपुट मिलता है:
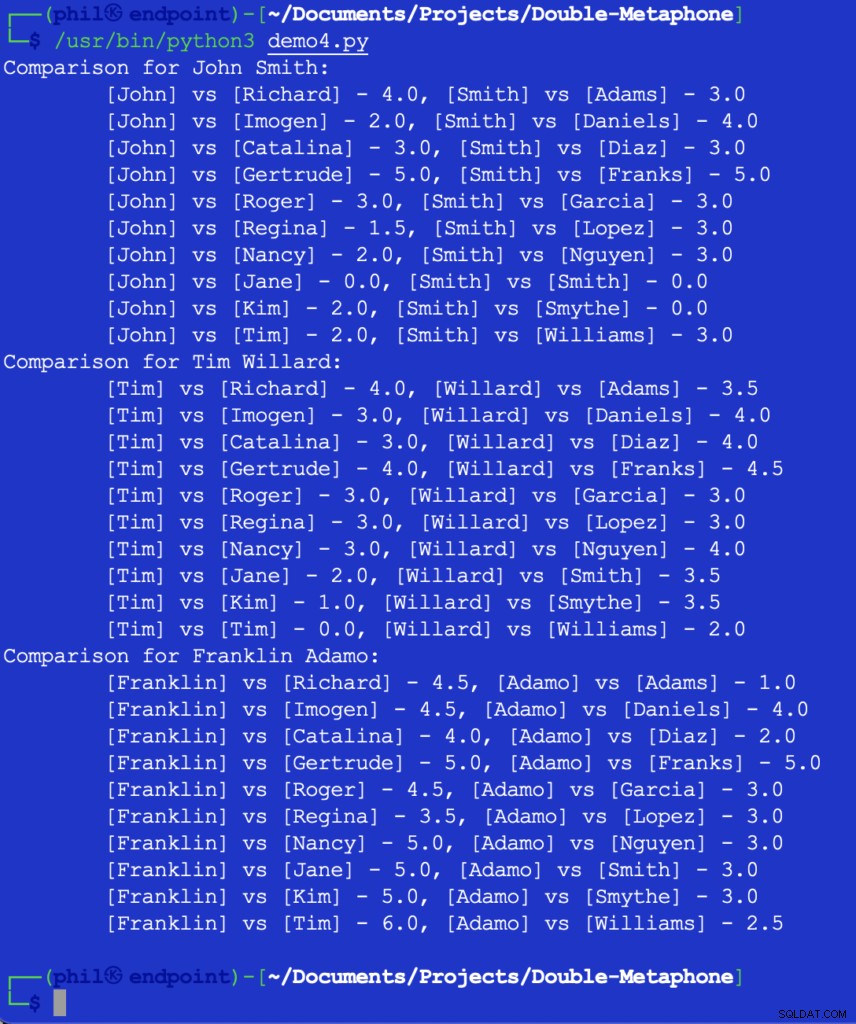
चित्र 5 - मंहगाई तुलना के परिणाम
इस बिंदु पर, यह तय करने के लिए डेवलपर पर निर्भर होगा कि उपयोगी तुलना के लिए थ्रेसहोल्ड क्या होगा। ऊपर दी गई कुछ संख्याएं अप्रत्याशित या आश्चर्यजनक लग सकती हैं, लेकिन कोड में एक संभावित जोड़ IF हो सकता है 2 . से अधिक किसी भी तुलना मान को फ़िल्टर करने के लिए कथन ।
यह ध्यान देने योग्य हो सकता है कि ध्वन्यात्मक मान स्वयं डेटाबेस में संग्रहीत नहीं होते हैं। ऐसा इसलिए है क्योंकि उनकी गणना पायथन कोड के हिस्से के रूप में की जाती है और इन्हें कहीं भी स्टोर करने की वास्तविक आवश्यकता नहीं है क्योंकि प्रोग्राम से बाहर निकलने पर उन्हें छोड़ दिया जाता है, हालांकि, एक डेवलपर डेटाबेस में इन्हें संग्रहीत करने और फिर तुलना को लागू करने में मूल्य पा सकता है। डेटाबेस के भीतर एक संग्रहीत कार्यविधि कार्य करता है। हालांकि, इसका एक प्रमुख पहलू कोड पोर्टेबिलिटी का नुकसान है।
पायथन के साथ ध्वनि द्वारा डेटा क्वेरी करने पर अंतिम विचार
ध्वनि द्वारा डेटा की तुलना करने से "प्यार" या ध्यान नहीं मिलता है जो छवि विश्लेषण द्वारा डेटा की तुलना कर सकता है, लेकिन यदि किसी एप्लिकेशन को कई भाषाओं में शब्दों के कई समान-ध्वनि वाले वेरिएंट से निपटना पड़ता है, तो यह महत्वपूर्ण रूप से उपयोगी हो सकता है। औजार। इस प्रकार के विश्लेषण की एक उपयोगी विशेषता यह है कि इन उपकरणों का उपयोग करने के लिए एक डेवलपर को भाषाविज्ञान या ध्वन्यात्मक विशेषज्ञ होने की आवश्यकता नहीं है। इस तरह के डेटा की तुलना कैसे की जा सकती है, इसे परिभाषित करने में डेवलपर के पास बहुत लचीलापन है; तुलनाओं को एप्लिकेशन या व्यावसायिक तर्क आवश्यकताओं के आधार पर बदला जा सकता है।
उम्मीद है, अध्ययन के इस क्षेत्र को अनुसंधान क्षेत्र में अधिक ध्यान मिलेगा और आगे और अधिक सक्षम और मजबूत विश्लेषण उपकरण होंगे।