परिचय
यह पता लगाना कि आपको अपने अनुप्रयोगों के प्रदर्शन, विश्वसनीयता और स्केलिंग आवश्यकताओं से मेल खाने के लिए किस प्रकार की डेटाबेस अवसंरचना की आवश्यकता है, एक कठिन कार्य हो सकता है। आपके डेटाबेस टोपोलॉजी के लिए आपके द्वारा किए गए विकल्प इस बात को प्रभावित कर सकते हैं कि आपका संपूर्ण एप्लिकेशन स्टैक विभिन्न प्रकार के उपयोग के प्रति कैसे प्रतिक्रिया करता है और यह किन विफलता परिदृश्यों के लिए जिम्मेदार हो सकता है। इस वजह से, अपने विकल्पों को समझना और एक सूचित निर्णय लेना महत्वपूर्ण है जो आपके लक्ष्यों के अनुरूप हो।
आपके सभी बुनियादी ढांचे की जरूरतों को संभालने के लिए एक ही डेटाबेस से अधिक जटिल सिस्टम तक जाने के कई अलग-अलग तरीके हैं। इसके साथ ही, विचार करने के लिए कई ट्रेड-ऑफ़ हैं।
इस गाइड में, हम रिलेशनल डेटाबेस इन्फ्रास्ट्रक्चर के लिए कुछ सबसे सामान्य पैटर्न पेश करेंगे और वे विभिन्न उपयोग पैटर्न के साथ कैसे संरेखित होंगे। हम प्रत्येक कॉन्फ़िगरेशन द्वारा प्रदान किए जाने वाले लाभों के साथ-साथ कुछ कमियों के बारे में भी जानेंगे जिनका आपको ध्यान रखना चाहिए। हम आपके समग्र संचालन जटिलता पर विभिन्न निर्णयों के प्रभाव के बारे में भी बात करेंगे। एक बार जब आप समाप्त कर लेते हैं, तो आपको इस बारे में बेहतर निर्णय लेने में सक्षम होना चाहिए कि आपकी वर्तमान आवश्यकताओं के लिए कौन से डिज़ाइन सबसे उपयुक्त हैं और आपकी ज़रूरतों में परिवर्तन के रूप में आप किन विकल्पों के साथ प्रयोग करना चाहेंगे।
लंबवत स्केलिंग
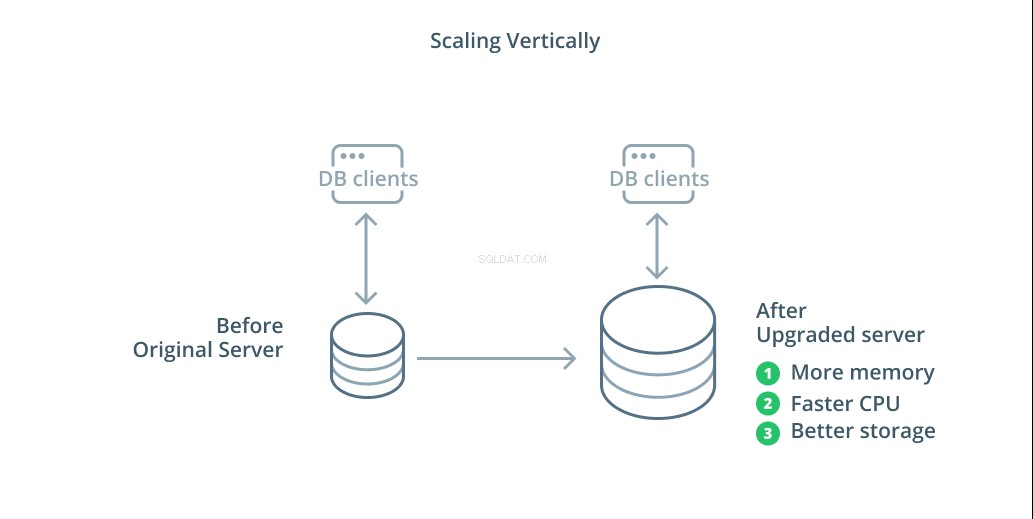
डेटाबेस सिस्टम को स्केल करने का सबसे सरल तरीका वर्टिकल स्केलिंग है। लंबवत स्केलिंग , जिसे बढ़ाना . भी कहा जाता है , का अर्थ है आपके डेटाबेस को प्रबंधित करने वाले सर्वर में क्षमता जोड़ना। प्रसंस्करण शक्ति, स्मृति आवंटन, या भंडारण क्षमता को बढ़ाकर, आप प्रदर्शन और मात्रा को बढ़ा सकते हैं जिसे एक डेटाबेस सिस्टम समग्र रूप से सिस्टम की जटिलता को बढ़ाए बिना संभाल सकता है।
एक सामान्य नियम के रूप में, अपने डेटाबेस को बढ़ाना एक अच्छा पहला कदम है क्योंकि यह आपके बुनियादी ढांचे की टोपोलॉजी को प्रभावित किए बिना आपके डेटाबेस की क्षमताओं को बढ़ाता है। स्केलिंग अप आमतौर पर काफी सरल भी है, क्योंकि एक बड़ी क्षमता वाली मशीन को एक प्रतिकृति अनुयायी के रूप में तब तक कॉन्फ़िगर किया जा सकता है जब तक कि इसे सिंक्रनाइज़ नहीं किया जाता है और फिर इसे नया प्राथमिक सर्वर बनाने के लिए एक विफलता को ट्रिगर किया जा सकता है।
हालाँकि, स्केलिंग की अपनी सीमाएँ हैं क्योंकि संसाधनों की मात्रा जो एक मशीन को यथोचित रूप से आवंटित की जा सकती है, सीमित है। यह विफलता के एकल बिंदु का भी प्रतिनिधित्व करता है यदि कोई प्रतिकृति अनुयायियों को समस्या होने पर लेने के लिए कॉन्फ़िगर नहीं किया गया है। इन चिंताओं को कुछ अन्य स्केलिंग विकल्पों द्वारा संबोधित किया जाता है।
कमांड क्वेरी रिस्पांसिबिलिटी सेग्रीगेशन (CQRS) और रीड-ओनली रेप्लिकाएं
अपने डेटाबेस इन्फ्रास्ट्रक्चर को स्केल करने का दूसरा प्राथमिक तरीका स्केल आउट करना है। स्केलिंग आउट इसका मतलब है कि एक सर्वर की क्षमता बढ़ाने के बजाय, आप एक विशिष्ट आवश्यकता को पूरा करने के लिए समर्पित सर्वरों की संख्या में वृद्धि करते हैं। इसलिए आप अपने बुनियादी ढांचे में अतिरिक्त मशीनें जोड़कर क्षमता जोड़ते हैं।
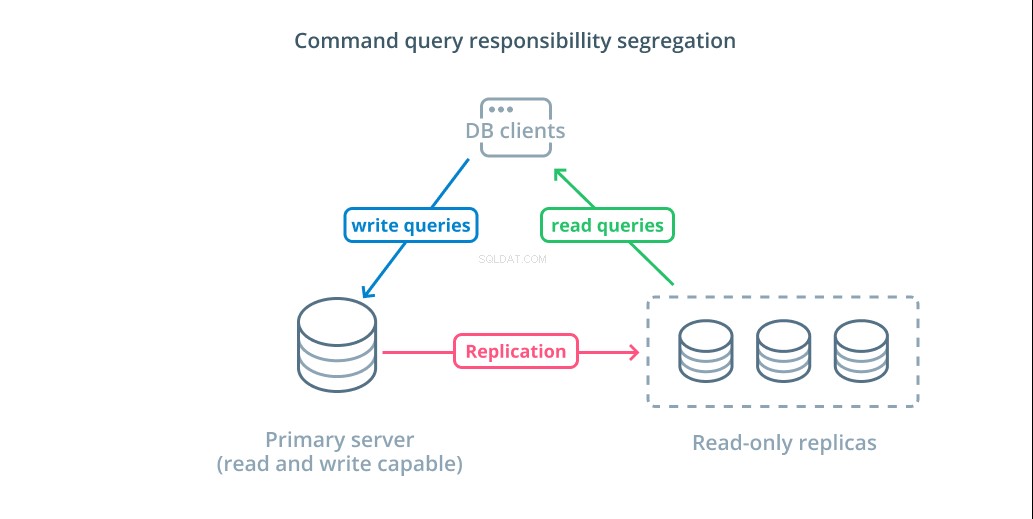
कमांड क्वेरी जिम्मेदारी अलगाव (CQRS) एक शब्द है जिसका उपयोग उन प्रश्नों को अलग करने के लिए तर्क जोड़ने का वर्णन करने के लिए किया जाता है जो डेटा को उत्परिवर्तित करते हैं (क्वेरी लिखते हैं) जो नहीं करते हैं (क्वेरी पढ़ें)। यह आपको इन विभिन्न श्रेणियों के अनुरोधों को लोड वितरित करने में सहायता के लिए विभिन्न होस्टों को रूट करने की अनुमति देता है।
इस डिज़ाइन का लाभ उठाने के लिए सबसे बुनियादी ढांचा एक प्राथमिक सर्वर है जो पढ़ने और लिखने के प्रश्नों को स्वीकार कर सकता है जो प्राथमिक सर्वर के बाद एक या अधिक प्रतिकृति सर्वर के साथ संयुक्त रूप से पढ़ने योग्य प्रश्नों को स्वीकार कर सकता है। यह डिज़ाइन एप्लिकेशन उपयोग पैटर्न के लिए उपयुक्त है जो पढ़ने-भारी हैं, क्योंकि पढ़ने के संचालन को किसी भी डेटाबेस सर्वर द्वारा नियंत्रित किया जा सकता है।
इसके अतिरिक्त, यह सिस्टम आपके आर्किटेक्चर को कुछ अतिरेक प्रदान करता है क्योंकि यदि कोई सर्वर डाउन हो जाता है तो सिस्टम अभी भी कार्य करेगा। यदि कोई अनुयायी नीचे चला जाता है, तो पढ़ने के अनुरोधों को अन्य सर्वरों पर भेजा जा सकता है। यदि प्राथमिक सर्वर नीचे चला जाता है, तो प्रतिकृति अनुयायियों में से एक को लिखित प्रश्नों को स्वीकार करने के लिए पदोन्नत किया जा सकता है।
बहु-प्राथमिक प्रतिकृति
केवल-पढ़ने के लिए प्रतिकृतियों के साथ CQRS का उपयोग करने से आपको अधिक संख्या में पढ़ने के अनुरोधों को संबोधित करने में मदद मिलती है, यह आपके बुनियादी ढांचे के लेखन प्रदर्शन को महत्वपूर्ण रूप से प्रभावित नहीं करता है। आपके आर्किटेक्चर को लिखने की संख्या बढ़ाने के लिए, आपको यह विचार करने की आवश्यकता है कि क्या आप एक बहु-प्राथमिक प्रतिकृति डिज़ाइन को अपना सकते हैं।
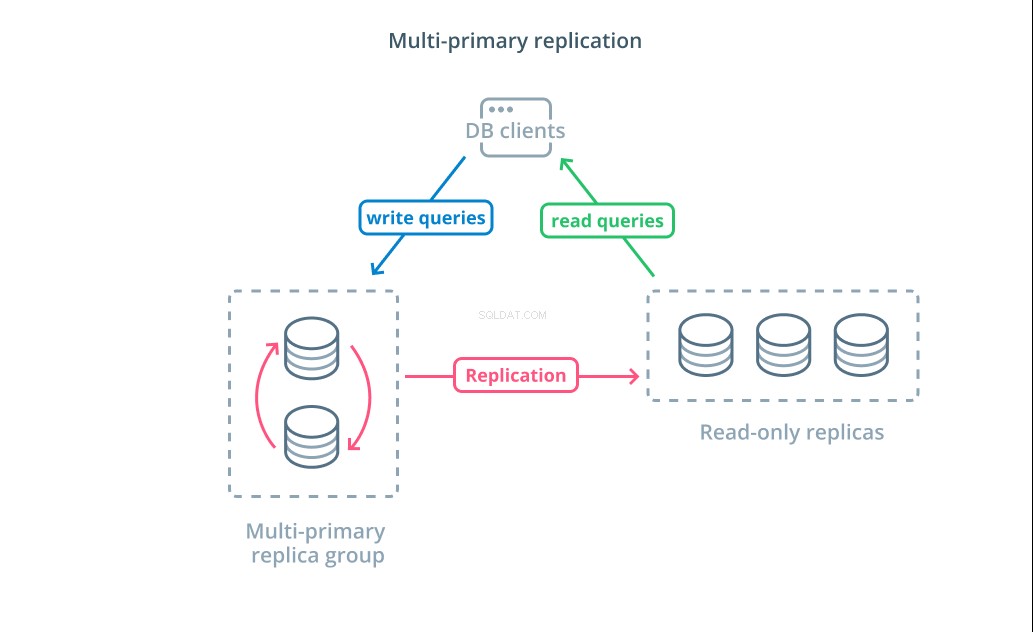
बहु-प्राथमिक प्रतिकृति प्रतिकृति का एक रूप है जहां एकाधिक सर्वर लेखन अनुरोध स्वीकार कर सकते हैं। कुछ सिस्टम कॉन्फ़िगर किए गए हैं ताकि कोई भी सर्वर लिखने के अनुरोधों को संसाधित कर सके, जबकि अन्य को इस तरह से डिज़ाइन किया गया है कि प्राथमिक सर्वर हैंडल का एक मुख्य समूह केवल-पढ़ने के लिए अनुयायियों की एक बड़ी संख्या के साथ लिखता है। कार्यान्वयन के बावजूद, बहु-प्राथमिक प्रतिकृति उन सर्वरों की संख्या को बढ़ाती है जो प्रश्नों को लिखने के लिए जिम्मेदार हैं।
हालांकि यह डिज़ाइन शुरू में आदर्श लगता है, लेकिन कुछ प्रमुख चुनौतियाँ हैं जो इसे व्यापक रूप से अपनाए गए पैटर्न से रोकती हैं। जबकि कई सर्वर लिखने के अनुरोधों को संभाल सकते हैं, फिर भी उन्हें अपने सर्वर के बीच परिवर्तनों को दोहराने और डेटा परिवर्तनों में विरोधों को हल करने के लिए समन्वय करना होगा। यह या तो लंबे समय तक प्रतिक्रिया समय का कारण बन सकता है क्योंकि संघर्षों पर बातचीत की जाती है या असंगत डेटा की संभावना होती है।
प्रत्येक प्रणाली इन चुनौतियों से निपटने के लिए अपना दृष्टिकोण चुनती है। यह CAP प्रमेय . का प्रदर्शन है — एक बयान जो वितरित सिस्टम में संगति, उपलब्धता और विभाजन सहिष्णुता के बीच परस्पर क्रिया का वर्णन करता है — क्रिया में। कुछ सिस्टम उपलब्धता को बनाए रखने के लिए कमजोर स्थिरता गारंटी प्रदान करते हैं, जबकि अन्य डेटाबेस परिवर्तनों को स्वीकार करने से इनकार करते हैं यदि उनके साथी लेखन के समय लेनदेन का समन्वय नहीं कर सकते हैं। विभिन्न कार्यान्वयनों के बीच निर्णय लेते समय आपकी आवश्यकताओं के लिए सबसे उपयुक्त दृष्टिकोण चुनना एक महत्वपूर्ण कारक है।
क्वेरी कैशिंग पढ़ें
केवल-पढ़ने के लिए प्रतिकृतियों का उपयोग करते समय उपलब्ध डेटाबेस को बढ़ाने का एक तरीका है जो पढ़ने के अनुरोधों का जवाब दे सकता है, यह जटिल पठन संचालन के मूल क्वेरी प्रदर्शन में सुधार नहीं करता है। हर बार अनुरोध किए जाने पर सर्वरों में से एक से रीड ऑपरेशन निष्पादित करने की अपेक्षा की जाती है, भले ही परिणाम पिछले लुकअप के समान हों।
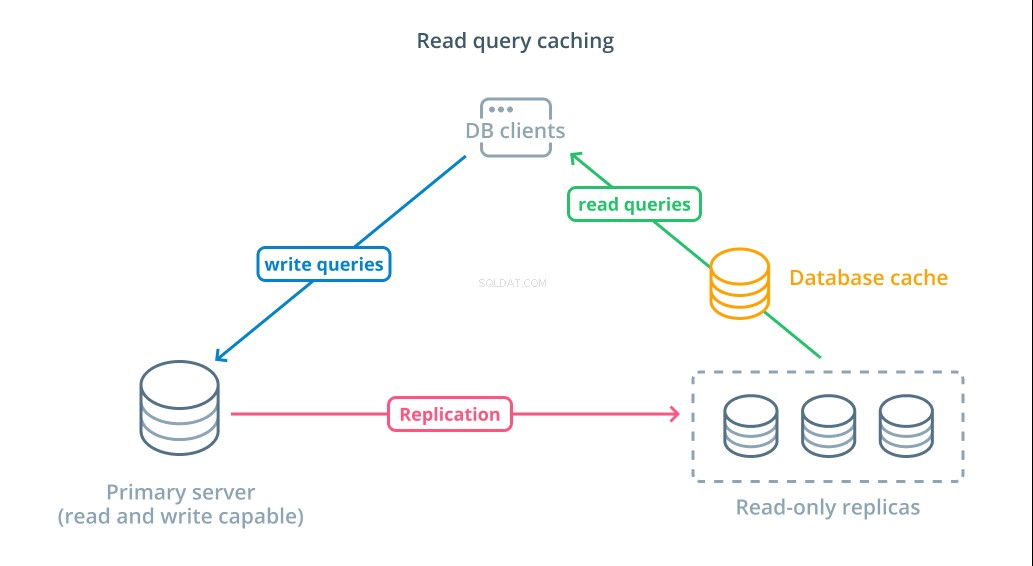
प्रतिक्रिया समय कम करने के लिए, एक क्वेरी कैशिंग पढ़ें परत पेश की जा सकती है। अपने डेटाबेस क्लाइंट और डेटाबेस के बीच कैश जोड़ने से सामान्य अनुरोधों के लिए क्वेरी समय में काफी कमी आ सकती है। एप्लिकेशन कैश से परिणामों को पढ़ने का अनुरोध कर सकता है और उपलब्ध होने पर उन्हें लगभग तुरंत प्राप्त कर सकता है। उन मामलों के लिए जहां परिणाम कैश में नहीं मिलते हैं, उन्हें डेटाबेस से ही प्राप्त किया जाता है और अगली बार कैश में जोड़ा जाता है।
इस तरह से कैशिंग को कॉन्फ़िगर करना उन परिदृश्यों के लिए अविश्वसनीय रूप से कुशल है जहां हर बार अनुरोध किए जाने पर डेटा के बदलने की संभावना नहीं होती है। यह महंगी पठन क्वेरी के लिए विशेष रूप से सहायक है जो कई तालिकाओं से परामर्श करती है और जटिल जुड़ने के संचालन को शामिल करती है। इन परिणामों को एक बार निष्पादित किया जा सकता है और फिर भविष्य के प्रश्नों के लिए सहेजा जा सकता है।
ऐसे मामलों में जहां डेटा अधिक तेज़ी से बदल रहा है, एक पठन कैश लगभग उतनी मदद नहीं कर सकता है। कॉन्फ़िगर किए गए व्यवहार के आधार पर, कैश इन स्थितियों में पुराने डेटा को वापस करने का जोखिम उठाता है और बदलते समय कैश से पुराने डेटा को निकालने के लिए विचारशील कैश अमान्यकरण रणनीतियों को लागू किया जाना चाहिए।
डेटा शार्डिंग
अब तक, हमने जिन डिज़ाइनों पर चर्चा की है, उनमें डेटाबेस घटकों को इस आधार पर विभाजित किया गया है कि वे लिखने के अनुरोधों का जवाब देते हैं या नहीं। हालांकि, जिम्मेदारी को विभाजित करने का दूसरा तरीका वास्तविक डेटा सेट को कई भागों में विभाजित करना है।
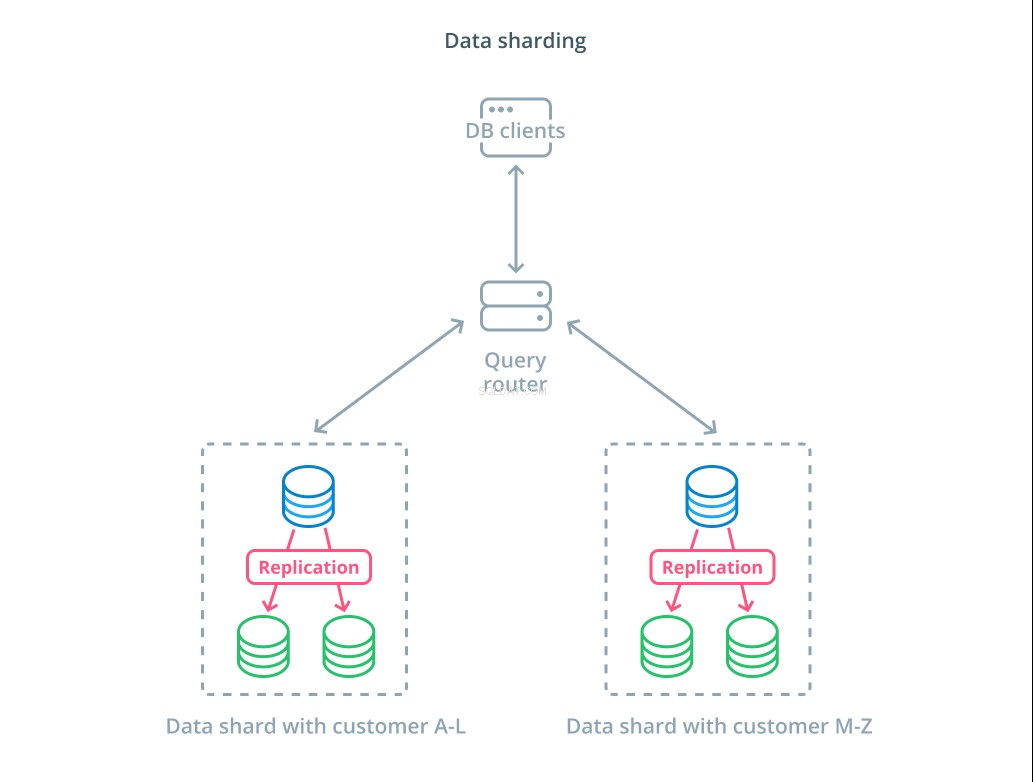
साझा करना विभिन्न मशीनों में उनके प्रबंधन को वितरित करने के लिए तार्किक डेटा को छोटे उपसमुच्चय में तोड़ने की प्रक्रिया है। प्रत्येक डेटाबेस सर्वर केवल डेटा के एक हिस्से को संभालता है और एक रूटिंग मैकेनिक पेश किया जाता है जो समझता है कि कौन सी मशीनें डेटा के टुकड़ों के लिए जिम्मेदार हैं।
आमतौर पर, उन परिदृश्यों में शार्डिंग की जाती है जहां एक बार में पूरे डेटासेट पर काम करना अनावश्यक या असामान्य होता है। डेटासेट को एक विशिष्ट कुंजी के लिए प्रत्येक रिकॉर्ड के मान के आधार पर खंडित किया जाता है, जिसे शार्डिंग कुंजी के रूप में जाना जाता है। . उदाहरण के लिए, आप ग्राहकों के स्थान के आधार पर डेटा को मैन्युअल रूप से शार्प कर सकते हैं। आप हैशिंग एल्गोरिथम का उपयोग करके स्वचालित रूप से शार्प भी कर सकते हैं यह निर्धारित करने के लिए कि कौन से नोड्स को किन कुंजियों को संभालना चाहिए। यह आपके सिस्टम को उन मामलों में असंतुलित वितरण से बचने में मदद कर सकता है जहां शार्प कीस्पेस असमान रूप से वितरित किया जाता है।
शेयरिंग डेटा सिस्टम में काफी जटिलता का परिचय देता है और सभी परिदृश्यों के लिए उपयुक्त नहीं है। कई शार्क के साथ इंटरैक्ट करने वाले संचालन को महत्वपूर्ण प्रदर्शन दंड भुगतना होगा क्योंकि वे प्रत्येक सदस्य से परिणाम प्राप्त करते हैं। यह समग्र प्रश्नों के लिए हो सकता है या यदि विशिष्ट शार्प कुंजी समय से पहले ज्ञात नहीं है। इसके अतिरिक्त, शार्प का असमान आवंटन भी अक्षमताओं और बाधाओं का कारण बन सकता है जिन्हें संपूर्ण डेटा सेट के वितरण को पुनर्संतुलित करके ठीक करने की आवश्यकता होती है।
विकेंद्रीकृत कार्यात्मक डेटा प्रबंधन
डेटासेट के मानों को कई खंडों में विभाजित करने के बजाय, कई मामलों में, विभिन्न कार्यात्मक उद्देश्यों के लिए अलग-अलग डेटाबेस का उपयोग करना अधिक समझ में आता है। उदाहरण के लिए, यदि आपके पास एक खाता सेवा और एक उत्पाद सेवा है, तो प्रत्येक चिंता के साथ मेल खाने वाले समर्पित डेटाबेस होने से आपको अलग-अलग घटकों को स्वतंत्र रूप से मापने में मदद मिल सकती है।
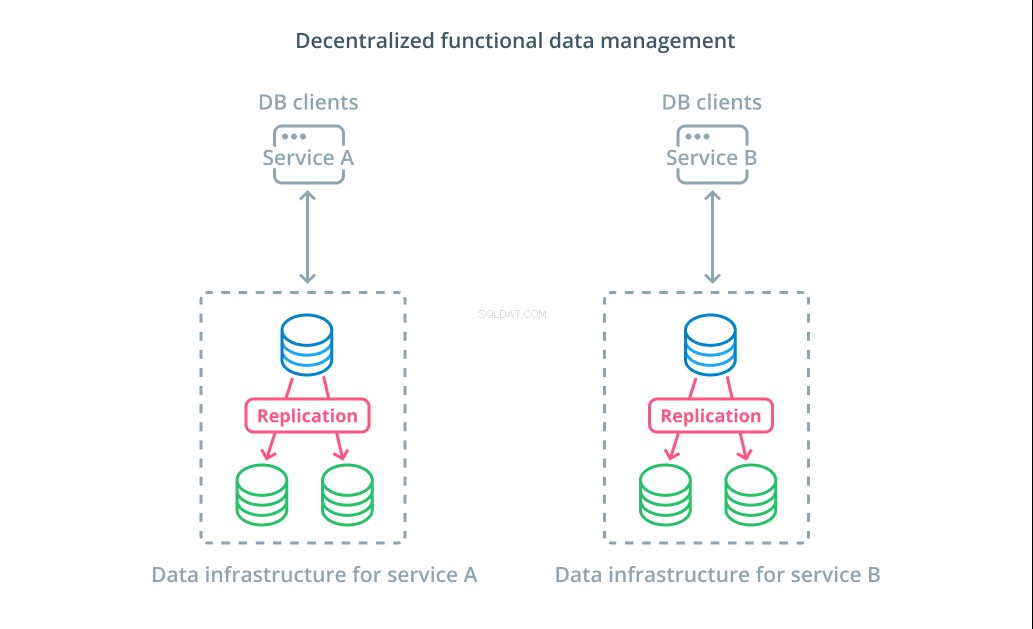
कार्यात्मक डेटा प्रबंधन आपको अपने डेटाबेस के बुनियादी ढांचे को तोड़ने और अपने ग्राहकों की जरूरतों के अनुसार प्रत्येक भाग का प्रबंधन करने की अनुमति देता है। जो भी रणनीति सबसे अधिक समझ में आती है उसका उपयोग करके प्रत्येक कार्यात्मक भाग को बढ़ाया जा सकता है। यह आपको डेटाबेस स्कीमा को डिज़ाइन करने और इसे किसी ऐसे स्थान पर परिनियोजित करने की अनुमति देता है जो पूरे संगठन की सेवा करने की आवश्यकता के बजाय किसी विशिष्ट उपयोग के मामले के पैटर्न से सबसे अच्छा मेल खाता है।
कई संगठनों के लिए, इस रणनीति के महत्वपूर्ण लाभ हैं जो वास्तविक प्रणालियों के गुणों से परे हैं। डेटा प्रबंधन का विकेंद्रीकरण छोटी टीमों को अन्य पक्षों के साथ परिवर्तनों के समन्वय के बिना अपने स्वयं के डेटा का स्वामित्व करने की अनुमति दे सकता है। यह माइक्रोसर्विस-ओरिएंटेड एप्लिकेशन आर्किटेक्चर द्वारा प्रचारित चिंताओं के केंद्रित पृथक्करण के साथ अच्छी तरह से संरेखित है।
सर्वर रहित डेटाबेस
विभिन्न ट्रेड-ऑफ़ जिनका आपको मूल्यांकन करना चाहिए और उचित स्केलिंग के लिए आपके द्वारा प्रबंधित किए जाने वाले बुनियादी ढांचे की मात्रा कई लोगों के लिए भारी हो सकती है। इस जटिलता को दूर करने का एक विकल्प डेटाबेस सेवाओं का लाभ उठाना है जो आपके लिए बुनियादी ढांचे और पैमाने का प्रबंधन करती हैं।
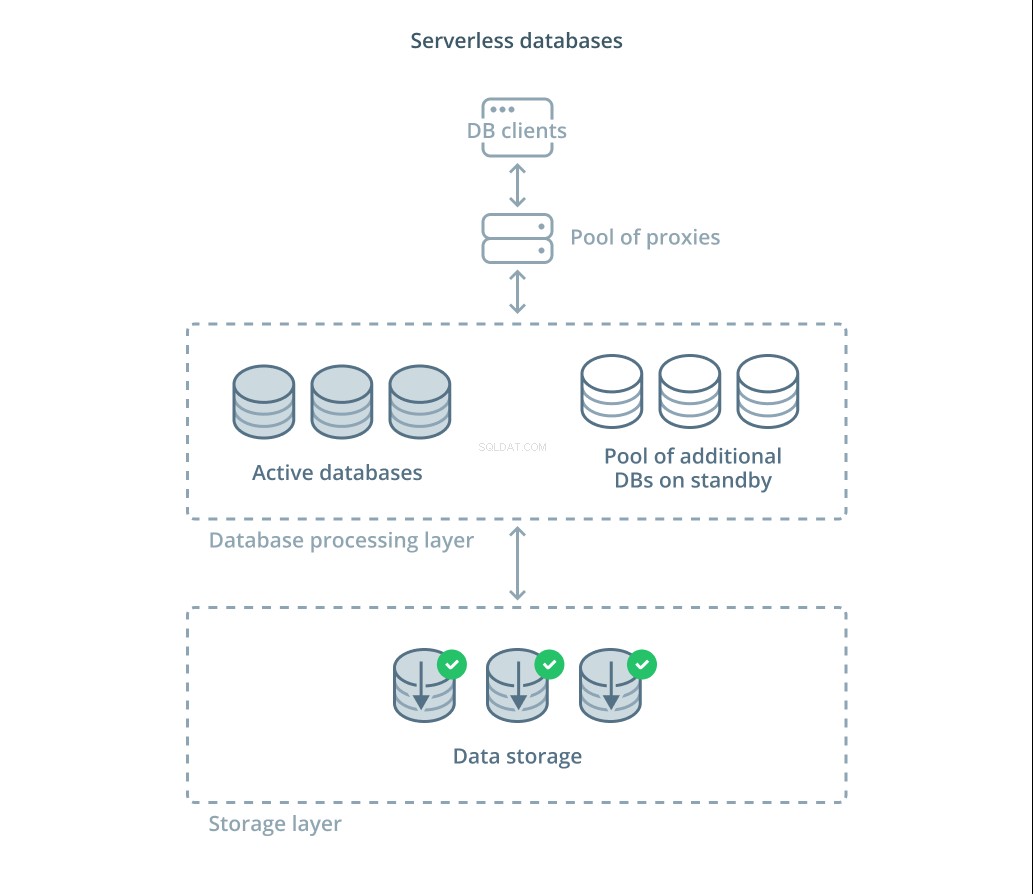
सर्वर रहित डेटाबेस सेवाओं की एक श्रेणी है जो मांग में बदलाव के जवाब में डेटा प्रोसेसिंग से डेटा स्टोरेज को आसानी से संसाधनों को स्केल करने के लिए अलग करती है।
डेटा स्टोरेज लेयर सिस्टम द्वारा प्रबंधित वास्तविक डेटा को बनाए रखने के लिए जिम्मेदार है। इस परत के सामने, डेटासेट के विरुद्ध वास्तविक क्वेरी प्रोसेसिंग को संभालने के लिए स्केलेबल डेटाबेस प्रोसेसिंग इकाइयों का एक स्तर तैनात किया जाता है। किसी भी समय सक्रिय इकाइयों की संख्या सीधे वर्तमान उपयोग से जुड़ी होती है, इसलिए अधिक संसाधनों को मांग के शिखर के रूप में आवंटित किया जाता है और अगर चीजें शांत हो जाती हैं तो प्रसंस्करण इकाइयों को स्टैंडबाय पर वापस कर दिया जाता है।
क्वेरी को रूटिंग प्रॉक्सी के माध्यम से डेटाबेस प्रोसेसर को अग्रेषित किया जाता है जो जानता है कि सक्रिय नोड्स को अनुरोध कैसे अग्रेषित करना है और अतिरिक्त संसाधनों का अनुरोध कब करना है।
सर्वर रहित डेटाबेस में पारंपरिक डेटाबेस सेवाओं के समान कई गुण होते हैं जो ऑटोस्केलिंग सुविधाओं को लागू करते हैं। दोनों मांग के आधार पर क्षमता आवंटित कर सकते हैं। हालाँकि, सर्वर रहित डेटाबेस आपको भंडारण लागत को प्रसंस्करण लागत से अलग करने की अनुमति देते हैं और आवश्यकता न होने पर प्रसंस्करण को शून्य तक बढ़ा सकते हैं। इसके अतिरिक्त सर्वर रहित समाधान पारंपरिक पेशकशों द्वारा पेश किए जाने वाले ऑटो स्केलिंग की तुलना में मांग को पूरा करने के लिए बहुत तेज़ी से बढ़ने में सक्षम होते हैं।
हालांकि सर्वर रहित डेटाबेस कुछ के लिए उपयुक्त हो सकते हैं, वे चांदी की गोली नहीं हैं। ऐसे मामलों में जहां डेटाबेस प्रोसेसर थे . थे शून्य तक घटाया गया, ठंड शुरू होने के कारण फिर से प्रसंस्करण में देरी हो सकती है। इसके अलावा, सर्वर रहित डेटाबेस स्टैक में विभिन्न घटकों के बीच कनेक्शन के माध्यम से मंथन से अतिरिक्त विलंबता हो सकती है।
ऑपरेशन के दृष्टिकोण से सर्वर रहित डेटाबेस प्लेटफॉर्म भी मुश्किल हो सकता है। परिनियोजन और डेटाबेस परिवर्तन के बारे में तर्क करना और निगरानी करना अधिक कठिन हो सकता है। डेटाबेस सिस्टम की गतिशील स्थिति के कारण स्थानीय विकास का वातावरण उत्पादन वातावरण से काफी भिन्न हो सकता है। और अंत में, किसी भी अन्य क्लाउड सेवा की तरह, सर्वर रहित डेटाबेस का उपयोग करना संभावित रूप से आपको विक्रेता लॉक-इन के खतरे में डाल सकता है। सर्वर रहित प्लेटफॉर्म के आसपास डिजाइन करते समय इन ट्रेड-ऑफ को याद रखना महत्वपूर्ण है।
निष्कर्ष
आपके डेटाबेस के बुनियादी ढांचे को डिजाइन, परिनियोजित और प्रबंधित करने के कई तरीके हैं क्योंकि आपकी एप्लिकेशन आवश्यकताएं अधिक गंभीर हो जाती हैं। प्रत्येक समाधान की अपनी ताकत और सीमाएं होती हैं जिन्हें समझना महत्वपूर्ण है जब आप अपने पर्यावरण के लिए उपयुक्त खोजने का प्रयास करते हैं।
डेटाबेस इन्फ्रास्ट्रक्चर आपके डेटा की उपलब्धता, प्रदर्शन और अखंडता को कैसे प्रभावित करता है, इसके बारे में सीखना आपको महंगी गलतियों और कार्यान्वयन से बचने की अनुमति देता है जो आपको आवश्यक गारंटी प्रदान नहीं करते हैं। यदि उपरोक्त में से कोई एक डिज़ाइन आपकी आवश्यकताओं को पूरा नहीं करता है, तो आप अतिरिक्त लाभ प्राप्त करने के लिए विभिन्न दृष्टिकोणों के कुछ तत्वों को संयोजित करने में सक्षम हो सकते हैं।
यदि आप ऊपर दिए गए सामान्य पैटर्न के बारे में अधिक जानना चाहते हैं, तो यहां कुछ अतिरिक्त संसाधन दिए गए हैं जिन्हें आप देखना चाहेंगे:
- बढ़ाना बनाम बढ़ाना
- कमांड क्वेरी जिम्मेदारी अलगाव
- बहु-प्राथमिक प्रतिकृति
- पढ़ने के प्रश्नों को कैशिंग करना
- डेटा साझाकरण
- विकेंद्रीकृत डेटा प्रबंधन
- सर्वर रहित डेटाबेस