बेंचमार्क उन गतिविधियों में से एक है जो डेटाबेस व्यवस्थापक करते हैं। आप उन्हें यह देखने के लिए चलाते हैं कि आपका हार्डवेयर कैसा व्यवहार करता है, आप उन्हें यह देखने के लिए चलाते हैं कि आपका एप्लिकेशन और डेटाबेस दबाव में एक साथ कैसे काम करते हैं। आप उन्हें कई अलग-अलग स्थितियों में चलाते हैं। आइए उनके बारे में थोड़ी बात करते हैं, आपको किन चुनौतियों का सामना करना पड़ेगा, किन मुद्दों से आपको बचना चाहिए।
बेंचमार्क के प्रकार
हर बेंचमार्क अलग होता है। वे विभिन्न उद्देश्यों की पूर्ति करते हैं और जब आप किसी एक को चलाने की योजना बनाते हैं तो इसे ध्यान में रखा जाना चाहिए। सामान्य तौर पर, आप दो मुख्य प्रकार के बेंचमार्क परिभाषित कर सकते हैं:सिंथेटिक बेंचमार्क और, इसे "वास्तविक दुनिया" बेंचमार्क कहते हैं।
सिंथेटिक बेंचमार्क आमतौर पर ऐसे उपकरण होते हैं जो किसी प्रकार के कार्यभार का अनुकरण करते हैं। यह एक OLTP कार्यभार हो सकता है जैसे Sysbench के मामले में, यह कुछ "मानक" बेंचमार्क हो सकता है जैसा कि TPC-C या TPC-H में होता है। आमतौर पर विचार यह है कि ऐसा बेंचमार्क किसी प्रकार के कार्यभार का अनुकरण करता है और यह उपयोगी हो सकता है यदि आपका वास्तविक दुनिया का कार्यभार उसी पैटर्न का पालन करने वाला है। इसका उपयोग यह निर्धारित करने के लिए भी किया जा सकता है कि किसी दिए गए प्रकार के वर्कलोड के तहत आपका हार्डवेयर और डेटाबेस कॉन्फ़िगरेशन का मिश्रण एक साथ कैसे काम करता है। सिंथेटिक बेंचमार्क के फायदे काफी स्पष्ट हैं। आप उन्हें हर जगह चला सकते हैं, वे किसी विशेष सेटअप या स्कीमा डिज़ाइन पर निर्भर नहीं करते हैं। ठीक है, वे करते हैं लेकिन वे खाली डेटाबेस सर्वर से सब कुछ सेट करने के लिए टूल के साथ आते हैं। मुख्य नकारात्मक पक्ष यह है कि यह आपका कार्यभार नहीं है। यदि आप Sysbench का उपयोग करके OLTP परीक्षण चलाने जा रहे हैं तो आपको यह ध्यान रखना होगा कि आपका आवेदन कभी भी Sysbench नहीं होगा। यह OLTP वर्कलोड भी चला सकता है लेकिन क्वेरी मिक्स अलग होगा। कभी भी, किसी भी परिस्थिति में सिंथेटिक बेंचमार्क आपको यह नहीं बताएगा कि किसी दिए गए हार्डवेयर/कॉन्फ़िगरेशन मिश्रण पर आपका एप्लिकेशन कैसा व्यवहार करेगा।
स्पेक्ट्रम के दूसरे छोर पर, जिसे हम "वास्तविक दुनिया" बेंचमार्क कहते हैं। हमारे यहां इसका मतलब एक बेंचमार्क है जो डेटा सेट और आपके एप्लिकेशन से संबंधित प्रश्नों का उपयोग करता है। इसमें हमेशा पूर्ण डेटा सेट और पूर्ण क्वेरी मिश्रण नहीं होता है। आप अपने एप्लिकेशन के कुछ हिस्सों पर ध्यान केंद्रित करना चाह सकते हैं, लेकिन इसके पीछे मुख्य विचार यह है कि आप एप्लिकेशन, हार्डवेयर और डेटाबेस कॉन्फ़िगरेशन के बीच सामान्य रूप से या किसी विशेष पहलू में सटीक इंटरैक्शन को समझना चाहते हैं।
जैसा कि हमने ऊपर उल्लेख किया है, हमारे पास दो मुख्य, विभिन्न प्रकार के बेंचमार्क हैं लेकिन, फिर भी, उनमें कुछ सामान्य चीजें हैं जिन पर आपको बेंचमार्क चलाने का प्रयास करते समय विचार करना होगा।
-
तय करें कि आप क्या परीक्षण करना चाहते हैं
सबसे पहले, बेंचमार्क चलाने के लिए बेंचमार्किंग करना व्यर्थ है। इसे वास्तव में कुछ हासिल करने के लिए डिज़ाइन किया जाना है। आप बेंचमार्क रन से क्या हासिल करना चाहते हैं? क्या आप प्रश्नों को ट्यून करना चाहते हैं? क्या आप कॉन्फ़िगरेशन को ट्वीक करना चाहते हैं? क्या आप अपने स्टैक की मापनीयता का आकलन करना चाहते हैं? क्या आप अपने स्टैक को अधिक भार के लिए तैयार करना चाहते हैं? क्या आप किसी नए प्रोजेक्ट के लिए सामान्य कॉन्फ़िगरेशन ट्वीकिंग करना चाहते हैं? क्या आप अपने हार्डवेयर के लिए सर्वोत्तम सेटिंग्स निर्धारित करना चाहते हैं? वे उद्देश्यों के उदाहरण हैं जिन्हें आप पूरा करना चाहते हैं। इनमें से प्रत्येक को एक अलग दृष्टिकोण और अलग बेंचमार्क सेटअप की आवश्यकता होगी।
-
एक बार में एक बदलाव करें
आप जो भी परीक्षण और सुधार कर रहे हैं, यह अत्यंत महत्वपूर्ण है कि आप एक समय में केवल एक कॉन्फ़िगरेशन परिवर्तन करेंगे। यह वास्तव में आलोचनात्मक है। बेंचमार्क का उद्देश्य आपको प्रदर्शन के बारे में कुछ जानकारी देना है। प्रश्न प्रति सेकंड, विलंबता, 99 प्रतिशत, यह सब आपको बताता है कि आप कितनी तेजी से प्रश्नों को निष्पादित कर सकते हैं और कार्यभार कितना स्थिर और अनुमानित है। यह बताना आसान है कि आपके द्वारा कॉन्फ़िगरेशन, हार्डवेयर या क्वेरी मिक्स में किए गए परिवर्तन से कुछ भी बदलता है या नहीं:बेंचमार्क से मीट्रिक अलग दिखाई देंगे। बात यह है कि, यदि आप एक ही समय में कुछ बदलाव करते हैं, तो यह बताने का कोई तरीका नहीं है कि समग्र परिणाम के लिए कौन जिम्मेदार है। यह इससे भी आगे जा सकता है। मान लें कि आपने डेटाबेस कॉन्फ़िगरेशन में दो मान बदल दिए हैं। मान ए और बी। समग्र सुधार 20% है, जो केवल एक कॉन्फ़िगरेशन परिवर्तन के लिए काफी अच्छा है। हुड के तहत, हालांकि, मूल्य ए में परिवर्तन से 30% का सुधार हुआ जबकि मूल्य बी में अतिरिक्त परिवर्तन ने इसे वापस 20% पर सेट कर दिया। एक ही समय में कई परिवर्तनों के साथ आप केवल उनके सामान्य प्रभाव को देख सकते हैं, यह आपके द्वारा किए गए प्रत्येक परिवर्तन के परिणाम को ठीक से निर्धारित करने का तरीका नहीं है। निश्चित रूप से, यह आपके द्वारा बेंचमार्क चलाने में लगने वाले समय को काफी बढ़ा देता है लेकिन ऐसा ही है।
-
एकाधिक बेंचमार्क रन बनाएं
कंप्यूटर अपने आप में जटिल सिस्टम हैं। उनके पास कई घटक हैं जो एक दूसरे के साथ बातचीत करते हैं:मेमोरी, सीपीयू, डिस्क, नेटवर्किंग। तो चलिए इस वर्चुअलाइजेशन, कंटेनराइजेशन में जोड़ते हैं। फिर सॉफ्टवेयर - ऑपरेटिंग सिस्टम, एप्लिकेशन, डेटाबेस। तत्वों की परत दर परत परत-दर-परत परत-दर-परत जो किसी तरह परस्पर क्रिया करती है। इसके व्यवहार की भविष्यवाणी करना आसान नहीं है। ठीक है, आप कह सकते हैं कि ऐसी जटिल प्रणालियों के व्यवहार की सटीक भविष्यवाणी करना लगभग असंभव है। यही कारण है कि निष्कर्ष निकालने के लिए एक बेंचमार्क रन चलाना पर्याप्त नहीं है। क्या होगा यदि, अनजाने में आपके लिए, कोई तत्व, जो आप परीक्षण करना चाहते हैं उससे पूरी तरह से असंबंधित है, समग्र प्रदर्शन को प्रभावित करता है? उसी होस्ट पर स्थित दूसरे VM पर उच्च भार। कोई अन्य सर्वर नेटवर्क पर बैकअप स्ट्रीमिंग कर रहा है। यह अस्थायी रूप से प्रदर्शन को प्रभावित कर सकता है और बेंचमार्क परिणामों को तिरछा कर सकता है। यदि आप केवल एक बेंचमार्क रन निष्पादित करते हैं, तो आप गलत परिणामों के साथ समाप्त होंगे। यही कारण है कि सबसे अच्छा अभ्यास एक बेंचमार्क के कई पास निष्पादित करना है और फिर सबसे धीमी और सबसे तेज़ को हटा देना है, दूसरों का औसत।
-
एक तस्वीर हजारों शब्दों के बराबर होती है
खैर, यह बेंचमार्किंग का काफी सटीक वर्णन है। यदि संभव हो तो हमेशा रेखांकन उत्पन्न करें। आदर्श रूप से, बेंचमार्क के दौरान जितनी बार आप कर सकते हैं मेट्रिक्स को ट्रैक करें। अधिकांश मामलों के लिए एक सेकंड की ग्रैन्युलैरिटी पर्याप्त होनी चाहिए। हजारों शब्द लिखने से बचने के लिए, हम इस उदाहरण को शामिल करेंगे। आपको क्या लगता है कि अधिक उपयोगी है? बेंचमार्क आउटपुट का यह सेट जो 10 पासों में से प्रत्येक के लिए औसत QPS का प्रतिनिधित्व करता है, प्रत्येक पास में 600 सेकंड लगते हैं
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
या यह प्लॉट:
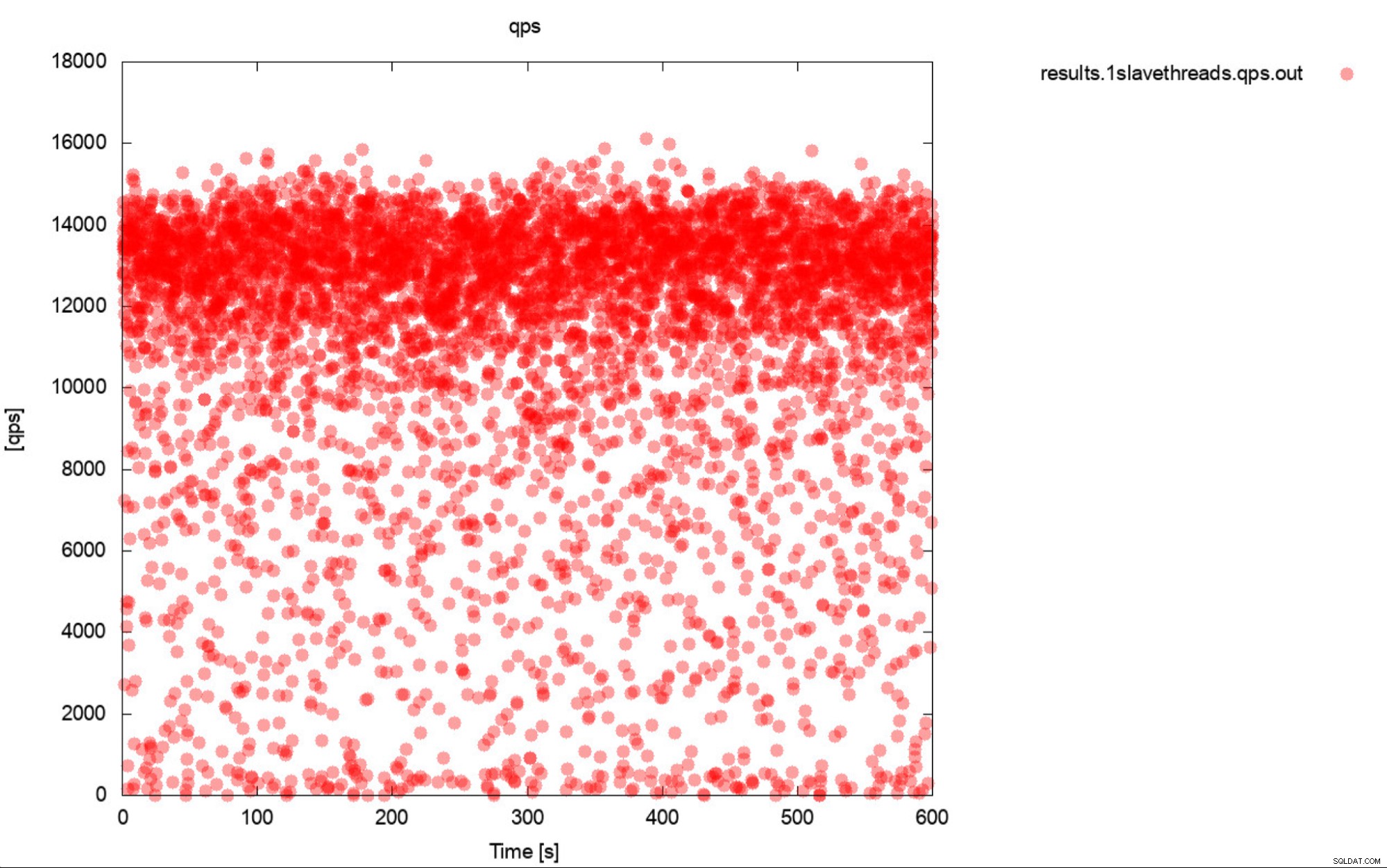
औसत QPS 11k है लेकिन वास्तविकता यह है कि प्रदर्शन सभी जगह है जगह, जिसमें एक सेकंड के भीतर निष्पादित 0 प्रश्नों के लिए डिप्स शामिल हैं, और यह निश्चित रूप से कुछ ऐसा है जिसे आप काम करना चाहते हैं और उत्पादन प्रणालियों में सुधार करना चाहते हैं।
-
प्रश्न प्रति सेकेंड सबसे महत्वपूर्ण मीट्रिक नहीं हैं
आप सोच सकते हैं कि प्रति सेकंड क्वेरी प्रदर्शन की पवित्र कब्र है क्योंकि यह दर्शाता है कि एक डेटाबेस एक सेकंड के भीतर कितने प्रश्नों को निष्पादित कर सकता है। सच्चाई यह है कि यह सबसे महत्वपूर्ण मीट्रिक नहीं है, खासकर अगर हम बेंचमार्क से औसत आउटपुट के बारे में बात कर रहे हैं। क्यूपीएस थ्रूपुट का प्रतिनिधित्व करता है लेकिन यह विलंबता को अनदेखा करता है। आप बड़ी मात्रा में प्रश्नों को आगे बढ़ाने का प्रयास कर सकते हैं लेकिन फिर आप उनके परिणाम वापस आने की प्रतीक्षा कर सकते हैं। यह वह नहीं है जो उपयोगकर्ता एप्लिकेशन से अपेक्षा करते हैं। उपयोगकर्ता स्थिर प्रदर्शन की अपेक्षा करते हैं। जरूरी नहीं कि यह तेजी से धधकता हो, लेकिन जब किसी क्रिया को पूरा होने में एक सेकंड का समय लगता है, तो हम यह अपेक्षा करते हैं कि उस क्रिया को करने में हमेशा 1 सेकंड का समय लगेगा। यदि किसी कारणवश इसमें अधिक समय लगने लगे तो मनुष्य को चिंता होने लगती है। यही मुख्य कारण है कि हम विलंबता को प्राथमिकता देते हैं, विशेष रूप से इसका P99 (99 वाँ प्रतिशत) अधिक विश्वसनीय मीट्रिक के रूप में। विलंबता हमें बताती है कि डेटाबेस से परिणाम के लिए आवेदन को कितने समय तक इंतजार करना पड़ा। P99 हमें विलंबता बताता है कि 99% प्रश्नों की तुलना में कम है। मान लें कि हमारे पास 100ms का P99 है, इसका मतलब है कि 99% क्वेरीज़ के परिणाम 100ms से धीमे नहीं होते हैं। यदि हम P99 विलंबता को कम देखते हैं, तो इसका अर्थ है कि लगभग सभी प्रश्न तेजी से लौट रहे हैं और स्थिर, पूर्वानुमेय तरीके से प्रदर्शन करते हैं। यह कुछ ऐसा है जिसे हमारे उपयोगकर्ता देखना चाहते हैं।
-
निष्कर्ष निकालने से पहले समझें कि क्या हो रहा है
इस संक्षिप्त ब्लॉग में हमारे पास अंतिम बिंदु है लेकिन हम कहेंगे कि यह सबसे महत्वपूर्ण है। बेंचमार्क के दौरान आपको अलग-अलग अजीब और अप्रत्याशित परिणाम और व्यवहार दिखाई देंगे। इससे भी बदतर, आप बहुत मानक, दोहराव वाले लेकिन फिर भी त्रुटिपूर्ण परिणाम देख सकते हैं। उनमें से अधिकांश को डेटाबेस या हार्डवेयर के व्यवहार के लिए ट्रैक किया जा सकता है। यह वास्तव में महत्वपूर्ण है - इससे पहले कि आप परिणाम को हल्के में लें, आपको व्यवहार की व्याख्या करने और जो हुआ उसका वर्णन करने में सक्षम होना चाहिए। हम जानते हैं कि यह आसान नहीं है और हम जानते हैं कि इसके लिए वास्तव में डेटाबेस-विशिष्ट ज्ञान की आवश्यकता होती है, विशेष रूप से डेटाबेस आंतरिक से संबंधित ज्ञान। हम जानते हैं कि वास्तविक दुनिया में लोग आमतौर पर इससे परेशान नहीं होते हैं, वे केवल कुछ परिणाम प्राप्त करना चाहते हैं। बात यह है, विशेष रूप से उन मामलों के लिए जहां आप कॉन्फ़िगरेशन या हार्डवेयर ट्वीक के माध्यम से प्रदर्शन में सुधार करने का प्रयास कर रहे हैं, यह समझना कि हुड के नीचे क्या हुआ, आपको उचित तरीका चुनने की अनुमति मिलती है जिसमें आपकी ट्यूनिंग आगे बढ़नी चाहिए। यह यह बताना भी संभव बनाता है कि निष्पादित किए गए बेंचमार्क का कोई अर्थ हो सकता है या नहीं। क्या हम वास्तव में सही तत्व का परीक्षण कर रहे हैं? एक उदाहरण नेटवर्क पर निष्पादित परीक्षण होगा (क्योंकि आप बेंचमार्क टूल के लिए डेटाबेस नोड के स्थानीय सीपीयू कोर का उपयोग नहीं करना चाहेंगे)। यह काफी संभावना है कि नेटवर्क ही और सॉफ्टिरक सीपीयू लोड सीमित कारक होगा, जिस तरह से आप सीपीयू संतृप्ति जैसी "अपेक्षित" बाधाओं को हिट करेंगे। यदि आप अपने पर्यावरण और उसके व्यवहार से अवगत नहीं हैं, तो आप अपने नेटवर्क के प्रदर्शन को बड़ी मात्रा में डेटा स्थानांतरित करने के लिए मापेंगे, न कि सीपीयू के प्रदर्शन के बारे में।
जैसा कि आप देख सकते हैं, बेंचमार्किंग करना सबसे आसान काम नहीं है, जो कुछ हो रहा है उसके बारे में आपके पास जागरूकता का स्तर होना चाहिए, आप जो करने जा रहे हैं उसके लिए आपके पास एक उचित योजना होनी चाहिए और आप क्या परीक्षण करना चाहते हैं? इस ब्लॉग के अगले भाग में हम कुछ वास्तविक दुनिया के परीक्षण मामलों के बारे में जानेंगे। क्या गलत हो सकता है, हम किन मुद्दों का सामना करेंगे और उनसे कैसे निपटें।