यह मेरे नए यूट्यूब वीडियो का लिखित संस्करण है ️
इस Redis ट्यूटोरियल में, आप Redis के बारे में जानेंगे और कैसे Redis को जटिल अनुप्रयोगों के लिए प्राथमिक डेटाबेस के रूप में उपयोग किया जा सकता है जिसमें डेटा को कई स्वरूपों में संग्रहीत करने की आवश्यकता होती है।
सिंहावलोकन 📝
- Redis क्या है और इसके उपयोग साथ ही यह आधुनिक जटिल माइक्रोसर्विस अनुप्रयोगों के लिए उपयुक्त क्यों है?
- Redis अपने मॉड्यूल . के माध्यम से विभिन्न उद्देश्यों के लिए एकाधिक डेटा प्रारूपों को संग्रहीत करने का समर्थन कैसे करता है ?
- इन-मेमोरी डेटाबेस के रूप में Redis कैसे डेटा को बनाए रख सकता है और डेटा हानि से पुनर्प्राप्त कर सकता है ?
- कैसे Redis को स्केल और दोहराने के लिए ?
- आखिरकार चूंकि माइक्रोसर्विस चलाने के लिए सबसे लोकप्रिय प्लेटफार्मों में से एक कुबेरनेट्स है और चूंकि कुबेरनेट्स में स्टेटफुल एप्लिकेशन चलाना थोड़ा चुनौतीपूर्ण है, इसलिए हम देखेंगे कि आप आसानी से कुबेरनेट्स में रेडिस कैसे चला सकते हैं
रेडिस क्या है?
<ब्लॉकक्वॉट>रेडिस का अर्थ है पुनः मोटे dic s कभी
Redis एक इन-मेमोरी डेटाबेस है . इसलिए कई लोगों ने इसे अन्य डेटाबेस के शीर्ष पर कैश के रूप में उपयोग किया है एप्लिकेशन प्रदर्शन में सुधार करने के लिए।
हालांकि, बहुत से लोग यह नहीं जानते हैं कि Redis एक पूर्ण विकसित प्राथमिक डेटाबेस है जिसका उपयोग जटिल अनुप्रयोगों के लिए कई डेटा स्वरूपों को संग्रहीत और बनाए रखने के लिए किया जा सकता है।
तो चलिए उसके लिए उपयोग के मामले देखते हैं।
मल्टी-मॉडल डेटाबेस क्यों?
आइए एक माइक्रोसर्विस एप्लिकेशन के लिए एक सामान्य सेटअप को देखें।
मान लें कि हमारे पास लाखों उपयोगकर्ताओं के साथ एक जटिल सोशल मीडिया एप्लिकेशन है। इसके लिए हमें अलग-अलग डेटा फॉर्मेट को अलग-अलग डेटाबेस में स्टोर करने की आवश्यकता हो सकती है:
- संबंधपरक डेटाबेस , Mysql की तरह, हमारे डेटा को स्टोर करने के लिए
- लोचदार खोज तेज़ खोज और फ़िल्टरिंग के लिए
- ग्राफ़ डेटाबेस उपयोगकर्ताओं के कनेक्शन का प्रतिनिधित्व करने के लिए
- दस्तावेज़ डेटाबेस , MongoDB की तरह हमारे उपयोगकर्ताओं द्वारा प्रतिदिन साझा की जाने वाली मीडिया सामग्री को संग्रहीत करने के लिए
- कैश सेवा एप्लिकेशन के बेहतर प्रदर्शन के लिए
यह स्पष्ट है कि यह काफी जटिल सेटअप है।
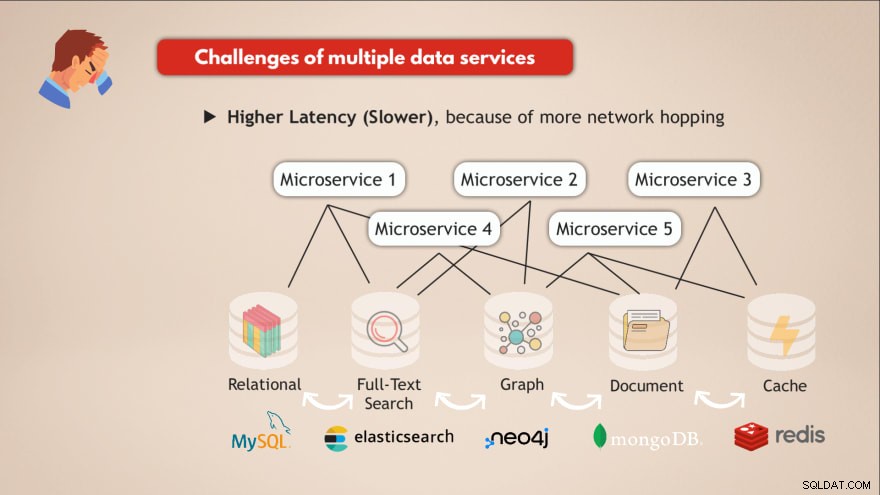
एकाधिक डेटा सेवाओं के होने की चुनौतियाँ
- ❌ प्रत्येक डेटा सेवा को परिनियोजित और बनाए रखने की आवश्यकता है
- ❌ प्रत्येक डेटा सेवा के लिए आवश्यक जानकारी
- ❌ विभिन्न स्केलिंग और बुनियादी ढांचे की आवश्यकताएं
- ❌ इन सभी विभिन्न डीबी के साथ इंटरैक्ट करने के लिए अधिक जटिल एप्लिकेशन कोड
- ❌ अधिक नेटवर्क हॉपिंग के कारण उच्च विलंबता (धीमा),
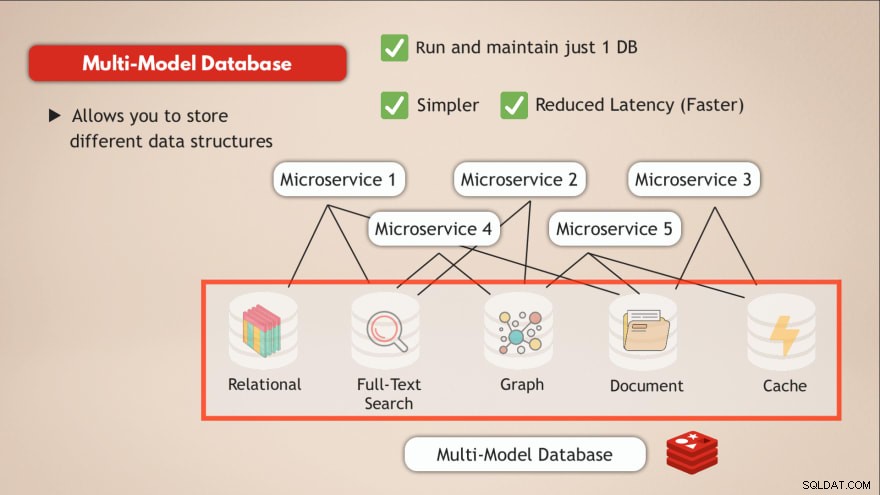
एक बहु-मॉडल डेटाबेस होना
बहु-मॉडल डेटाबेस की तुलना में आप इनमें से अधिकांश चुनौतियों का समाधान करते हैं। सबसे पहले आप केवल 1 डेटा सेवा चलाएं और बनाए रखें . तो आपके एप्लिकेशन को भी एक डेटा स्टोर से बात करने की आवश्यकता है और उस डेटा सेवा के लिए केवल एक प्रोग्रामेटिक इंटरफ़ेस की आवश्यकता है।
इसके अलावा, एकल डेटा एंडपॉइंट पर जाकर और कई आंतरिक नेटवर्क हब को समाप्त करने से विलंबता कम हो जाएगी।
इसलिए रेडिस जैसा एक डेटाबेस होना, जो आपको विभिन्न प्रकार के डेटा को स्टोर करने की अनुमति देता है या मूल रूप से आपको एक में कई प्रकार के डेटाबेस रखने की अनुमति देता है और साथ ही कैश के रूप में कार्य करने से ऐसी चुनौतियों का समाधान होता है।
- ✅ केवल 1 डेटाबेस चलाएं और बनाए रखें
- ✅ सरल
- ✅ कम विलंबता (तेज़)
रेडिस कैसे काम करता है?
रेडिस मॉड्यूल मैं
जिस तरह से यह काम करता है वह यह है कि आपके पास Redis Core है, जो एक महत्वपूर्ण मूल्य स्टोर है जो पहले से ही कई प्रकार के डेटा को संग्रहीत करने का समर्थन करता है और फिर आप उस कोर को विभिन्न डेटा प्रकारों के लिए मॉड्यूल के साथ विस्तारित कर सकते हैं , जो आपके आवेदन को विभिन्न उद्देश्यों के लिए चाहिए। तो उदाहरण के लिए ग्राफ़ डेटा संग्रहण के लिए लोचदार खोज या रेडिस ग्राफ़ जैसी खोज कार्यक्षमता के लिए RediSearch और इसी तरह:

और इसके बारे में एक बड़ी बात यह है कि यह मॉड्यूलर है . इसलिए इन विभिन्न प्रकार की डेटाबेस कार्यक्षमताओं को एक डेटाबेस में कसकर एकीकृत नहीं किया जाता है, बल्कि आप अपने एप्लिकेशन के लिए आवश्यक डेटा सेवा कार्यक्षमता को चुन सकते हैं और चुन सकते हैं और फिर मूल रूप से उस मॉड्यूल को जोड़ सकते हैं।
आउट-ऑफ़-द-बॉक्स कैश ️
बेशक प्राथमिक डेटाबेस के रूप में रेडिस का उपयोग करते समय आपको अतिरिक्त कैश की आवश्यकता नहीं होती है, क्योंकि आपके पास रेडिस के साथ स्वचालित रूप से बॉक्स से बाहर हो जाता है। इसका मतलब है कि आपके आवेदन में फिर से कम जटिलता है, क्योंकि आपको कैश को पॉप्युलेट करने और अमान्य करने के लिए तर्क को लागू करने की आवश्यकता नहीं है।
रेडिस तेज है मैं
इन-मेमोरी (डेटा को रैम में स्टोर किया जाता है) डेटाबेस के रूप में, रेडिस सुपर फास्ट और परफॉर्मेंट है, जो निश्चित रूप से एप्लिकेशन को तेज बनाता है।
लेकिन इस समय आप सोच रहे होंगे:
इन-मेमोरी डेटाबेस डेटा को कैसे बनाए रख सकता है?
Redis डेटा को कैसे बनाए रख सकता है और डेटा हानि से कैसे उबर सकता है?
यदि रेडिस प्रक्रिया या सर्वर जिस पर रेडिस चल रहा है, विफल हो जाता है, तो मेमोरी में सभी डेटा सही हो जाता है? तो डेटा कैसे बना रहता है और मूल रूप से मैं कैसे आश्वस्त हो सकता हूं कि मेरा डेटा सुरक्षित है?
Redis की प्रतिकृति बनाना?
ठीक है, डेटा बैकअप लेने का सबसे आसान तरीका है Redis को दोहराना . इसलिए यदि रेडिस मास्टर इंस्टेंस नीचे चला जाता है, तो प्रतिकृतियां अभी भी चल रही हैं और सभी डेटा हैं। इसलिए यदि आपके पास प्रतिकृति रेडिस है, तो प्रतिकृतियों में डेटा होगा।
लेकिन निश्चित रूप से यदि सभी रेडिस इंस्टेंस नीचे जाते हैं तो आप डेटा खो देंगे, क्योंकि कोई प्रतिकृति शेष नहीं रहेगी। 🤯तो हमें वास्तविक दृढ़ता की आवश्यकता है .
स्नैपशॉट और AOF
डेटा को बनाए रखने और डेटा को सुरक्षित रखने के लिए रेडिस के पास कई तंत्र हैं।
स्नैपशॉट
पहला:स्नैपशॉट, जिसे आप समय, अनुरोधों की संख्या आदि के आधार पर कॉन्फ़िगर कर सकते हैं। इसलिए आपके डेटा के स्नैपशॉट डिस्क पर संग्रहीत किए जाएंगे , जिसका उपयोग आप अपने डेटा को पुनर्प्राप्त करने के लिए कर सकते हैं यदि संपूर्ण Redis डेटाबेस चला गया है।
लेकिन ध्यान दें कि आप डेटा के अंतिम मिनटों को खो देंगे , क्योंकि आप आमतौर पर अपनी आवश्यकताओं के आधार पर हर पांच मिनट या एक घंटे में स्नैपशॉट लेते हैं।
AOF
तो एक विकल्प के रूप में Redis AOF . नामक किसी चीज़ का उपयोग करता है , जिसका अर्थ है A ppend O केवल F इले.
इस मामले में हर परिवर्तन लगातार दृढ़ता के लिए डिस्क में सहेजा जाता है . और रेडिस को पुनरारंभ करते समय या आउटेज के बाद, रेडिस राज्य के पुनर्निर्माण के लिए केवल संलग्न फ़ाइल लॉग को फिर से चलाएगा।
तो एओएफ अधिक टिकाऊ है , लेकिन स्नैपशॉट की तुलना में धीमा हो सकता है।
<ब्लॉकक्वॉट>सर्वश्रेष्ठ विकल्प :AOF और स्नैपशॉट दोनों के संयोजन का उपयोग करें, जहां AOF मेमोरी से डिस्क पर लगातार डेटा बना रहा है और डेटा स्थिति को बचाने के लिए आपके पास नियमित स्नैपशॉट हैं यदि आपको इसे पुनर्प्राप्त करने की आवश्यकता है:

Redis डेटाबेस को कैसे स्केल करें?
मान लें कि मेरा 1 रेडिस इंस्टेंस मेमोरी से बाहर हो गया है, इसलिए डेटा मेमोरी में रखने के लिए बहुत बड़ा हो जाता है या रेडिस एक अड़चन बन जाता है और किसी भी अधिक अनुरोध को संभाल नहीं सकता है। ऐसे में मैं क्षमता और स्मृति आकार कैसे बढ़ाऊं मेरे रेडिस डेटाबेस के लिए?
उसके लिए हमारे पास कई विकल्प हैं:
1. क्लस्टरिंग
सबसे पहले, रेडिस क्लस्टरिंग . का समर्थन करता है . इसका मतलब है कि आपके पास एक प्राथमिक या मास्टर रेडिस इंस्टेंस हो सकता है, जिसका उपयोग डेटा को पढ़ने और लिखने के लिए किया जा सकता है और डेटा को पढ़ने के लिए आपके पास उस प्राथमिक इंस्टेंस की कई प्रतिकृतियां हो सकती हैं :
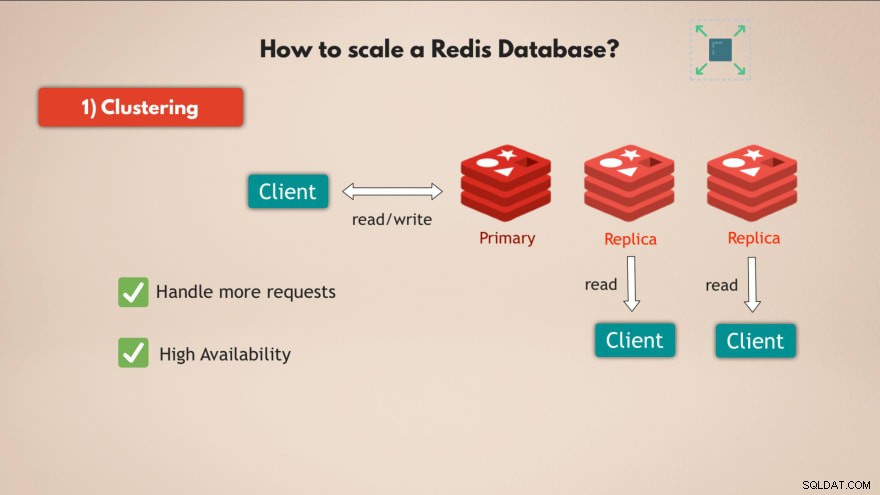
इस तरह आप अधिक अनुरोधों को संभालने के लिए Redis को स्केल कर सकते हैं और इसके अतिरिक्त उच्च उपलब्धता में वृद्धि . कर सकते हैं आपके डेटाबेस का, क्योंकि यदि मास्टर विफल हो जाता है तो 1 प्रतिकृतियां ले सकती हैं और आपका रेडिस डेटाबेस मूल रूप से बिना किसी समस्या के कार्य करना जारी रख सकता है।
2. साझा करना
वैसे यह काफी अच्छा लगता है, लेकिन क्या होगा अगर
- आपका डेटासेट एक सर्वर पर मेमोरी में फ़िट होने के लिए बहुत बड़ा हो जाता है .
- साथ ही हमने डेटाबेस में रीड्स को स्केल किया है, इसलिए सभी अनुरोध जो मूल रूप से केवल डेटा को क्वेरी करते हैं। लेकिन हमारा मास्टर इंस्टेंस अभी भी अकेला है और अभी भी सभी लेखन को संभालना है ।
तो यहाँ समाधान क्या है?
उसके लिए हम शार्डिंग . की अवधारणा का उपयोग करते हैं , जो डेटाबेस में एक सामान्य अवधारणा है और जिसे Redis भी समर्थन करता है।
<ब्लॉकक्वॉट>तो शार्डिंग मूल रूप से इसका मतलब है कि आप अपना पूरा डेटा सेट लें और उसे छोटे-छोटे हिस्सों या डेटा के सबसेट में विभाजित करें , जहां प्रत्येक शार्क डेटा के अपने सबसेट के लिए जिम्मेदार होती है।
तो इसका मतलब है कि एक मास्टर इंस्टेंस होने के बजाय जो पूरे डेटा सेट में सभी लेखन को संभालता है, आप इसे 4 शार्क में विभाजित कर सकते हैं, उनमें से प्रत्येक डेटा के सबसेट को पढ़ने और लिखने के लिए जिम्मेदार है .
और प्रत्येक शार्क को कम मेमोरी क्षमता की भी आवश्यकता होती है , क्योंकि उनके पास सिर्फ एक चौथाई डेटा है। इसका मतलब है कि आप छोटे नोड्स पर शार्क वितरित और चला सकते हैं और मूल रूप से अपने क्लस्टर को क्षैतिज रूप से स्केल कर सकते हैं:
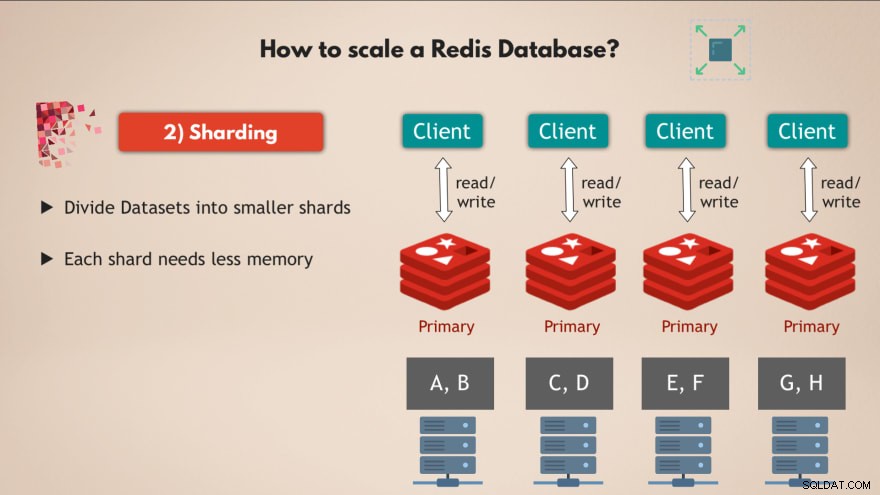
इसलिए एकाधिक नोड having होना , जो एकाधिक प्रतिकृतियां run चलाते हैं रेडिस के जो सभी शार्डेड . हैं आपको एक बहुत अच्छा प्रदर्शन करने वाला अत्यधिक उपलब्ध रेडिस डेटाबेस देता है जो बिना किसी बाधा के बहुत अधिक अनुरोधों को संभाल सकता है 👍
और विषय...
पिछले 2 विषयों और परिदृश्यों के लिए नीचे मेरा वीडियो देखें:
- ऐप्लिकेशन जिन्हें अधिक उपलब्धता और प्रदर्शन की आवश्यकता होती है अनेक भौगोलिक स्थानों में
- माइक्रोसर्विस चलाने का नया मानक कुबेरनेट्स प्लेटफॉर्म है, इसलिए कुबेरनेट्स में रेडिस चलाना एक बहुत ही रोचक और सामान्य उपयोग का मामला है
पूरा वीडियो यहां उपलब्ध है:
आशा है कि यह आप में से कुछ के लिए उपयोगी और दिलचस्प था!
मुझे लाइक, शेयर और फॉलो करें 😍 अधिक सामग्री के लिए:
- इंस्टाग्राम - परदे के पीछे की कई चीजें पोस्ट करना
- निजी एफबी समूह
- लिंक्डइन



