अपाचे HBase में संग्रहीत डेटा का बैकअप लेने के लिए उपलब्ध तंत्र का अवलोकन प्राप्त करें, और विभिन्न डेटा पुनर्प्राप्ति/विफलता परिदृश्यों की स्थिति में उस डेटा को कैसे पुनर्स्थापित करें
महत्वपूर्ण व्यावसायिक प्रणालियों में HBase को अधिक अपनाने और एकीकरण के साथ, कई उद्यमों को अपने HBase समूहों के लिए मजबूत बैकअप और डिजास्टर रिकवरी (BDR) रणनीतियों का निर्माण करके इस महत्वपूर्ण व्यावसायिक संपत्ति की रक्षा करने की आवश्यकता है। डेटा के संभावित पेटाबाइट्स को जल्दी और आसानी से बैकअप और पुनर्स्थापित करने के लिए यह कठिन लग सकता है, HBase और Apache Hadoop पारिस्थितिकी तंत्र इसे पूरा करने के लिए कई अंतर्निहित तंत्र प्रदान करते हैं।
इस पोस्ट में, आपको HBase में संग्रहीत डेटा का बैकअप लेने के लिए उपलब्ध तंत्र का एक उच्च-स्तरीय अवलोकन मिलेगा, और विभिन्न डेटा पुनर्प्राप्ति / विफलता परिदृश्यों की स्थिति में उस डेटा को कैसे पुनर्स्थापित किया जाए। इस पोस्ट को पढ़ने के बाद, आप एक शिक्षित निर्णय लेने में सक्षम होना चाहिए जिस पर आपकी व्यावसायिक आवश्यकताओं के लिए बीडीआर रणनीति सर्वोत्तम है। आपको प्रत्येक तंत्र के पेशेवरों, विपक्षों और प्रदर्शन प्रभावों को भी समझना चाहिए। (यहां विवरण CDH 4.3.0/HBase 0.94.6 और बाद के संस्करण पर लागू होता है।)
नोट:इस लेखन के समय, Cloudera Enterprise 4 HDFS और हाइव मेटास्टोर के लिए Cloudera BDR 1.0 के माध्यम से व्यक्तिगत रूप से लाइसेंस प्राप्त सुविधा के रूप में उत्पादन-तैयार बैकअप और आपदा पुनर्प्राप्ति कार्यक्षमता प्रदान करता है। HBase उस GA रिलीज़ में शामिल नहीं है; इसलिए, इस ब्लॉग में वर्णित विभिन्न तंत्रों की आवश्यकता है। (क्लौडेरा एंटरप्राइज 5, वर्तमान में बीटा में है, क्लाउडेरा बीडीआर के माध्यम से HBase स्नैपशॉट प्रबंधन प्रदान करता है।)
बैकअप
HBase एक लॉग-स्ट्रक्चर्ड मर्ज-ट्री डिस्ट्रीब्यूटेड डेटा स्टोर है जिसमें डेटा सटीकता, स्थिरता, वर्जनिंग आदि को सुनिश्चित करने के लिए जटिल आंतरिक तंत्र हैं। तो दुनिया में आप इस डेटा की लगातार बैकअप कॉपी कैसे प्राप्त कर सकते हैं जो HDFS पर HFiles और राइट-अहेड-लॉग्स (WALs) के संयोजन में और दर्जनों क्षेत्रीय सर्वरों पर मेमोरी में रहता है?
आइए कम से कम विघटनकारी, सबसे छोटे डेटा फ़ुटप्रिंट, कम से कम प्रदर्शन-प्रभावशाली तंत्र के साथ शुरू करें और सबसे विघटनकारी, फोर्कलिफ्ट-शैली वाले टूल तक अपना काम करें:
- स्नैपशॉट
- प्रतिकृति
- निर्यात करें
- कॉपीटेबल
- एचटेबल एपीआई
- HDFS डेटा का ऑफ़लाइन बैकअप
निम्न तालिका इन दृष्टिकोणों की शीघ्रता से तुलना करने के लिए एक सिंहावलोकन प्रदान करती है, जिसका मैं नीचे विस्तार से वर्णन करूंगा।
| प्रदर्शन प्रभाव | डेटा फ़ुटप्रिंट | डाउनटाइम | वृद्धिशील बैकअप | कार्यान्वयन में आसानी | मीन टाइम टू रिकवरी (MTTR) | |
| स्नैपशॉट | न्यूनतम | छोटा | संक्षिप्त (केवल पुनर्स्थापना पर) | नहीं | आसान | सेकंड |
| प्रतिकृति | न्यूनतम | बड़ा | कोई नहीं | आंतरिक | मध्यम | सेकंड |
| निर्यात करें | उच्च | बड़ा | कोई नहीं | हां | आसान | उच्च |
| कॉपीटेबल | उच्च | बड़ा | कोई नहीं | हां | आसान | उच्च |
| एपीआई | मध्यम | बड़ा | कोई नहीं | हां | मुश्किल | आप पर निर्भर |
| मैनुअल | लागू नहीं | बड़ा | लंबा | नहीं | मध्यम | उच्च |
स्नैपशॉट
CDH 4.3.0 के अनुसार, HBase स्नैपशॉट पूरी तरह कार्यात्मक हैं, सुविधा संपन्न हैं, और उनके निर्माण के दौरान क्लस्टर डाउनटाइम की आवश्यकता नहीं है। मेरे सहयोगी माटेओ बर्टोज़ज़ी ने अपने ब्लॉग प्रविष्टि और बाद में गहरे गोता लगाने में स्नैपशॉट को बहुत अच्छी तरह से कवर किया। यहां मैं केवल एक उच्च-स्तरीय अवलोकन प्रदान करूंगा।
HDFS पर आपकी तालिका की संग्रहण फ़ाइलों के लिए UNIX हार्ड लिंक के बराबर बनाकर स्नैपशॉट बस आपकी तालिका के लिए समय में एक क्षण को कैप्चर करते हैं (चित्र 1)। ये स्नैपशॉट सेकंड के भीतर पूर्ण हो जाते हैं, क्लस्टर पर लगभग कोई प्रदर्शन ओवरहेड नहीं रखते हैं, और एक छोटा डेटा फ़ुटप्रिंट बनाते हैं। आपका डेटा बिल्कुल भी डुप्लिकेट नहीं है, लेकिन केवल छोटी मेटाडेटा फ़ाइलों में सूचीबद्ध है, जो सिस्टम को उस पल में वापस रोल करने की अनुमति देता है जब आपको उस स्नैपशॉट को पुनर्स्थापित करने की आवश्यकता होती है।
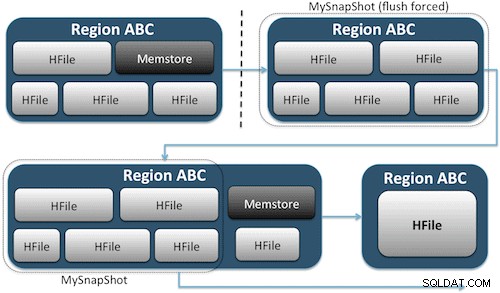
तालिका का स्नैपशॉट बनाना HBase शेल से इस कमांड को चलाने जितना आसान है:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
यह आदेश जारी करने के बाद, आपको एचडीएफएस में /hbase/.snapshot/myTable (CDH4) या /hbase/.hbase-snapshots (अपाचे 0.94.6.1) में स्थित कुछ छोटी डेटा फ़ाइलें मिलेंगी जिनमें आपके स्नैपशॉट को पुनर्स्थापित करने के लिए आवश्यक जानकारी शामिल है . पुनर्स्थापित करना शेल से इन आदेशों को जारी करने जितना आसान है:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
नोट:जैसा कि आप देख सकते हैं, स्नैपशॉट को पुनर्स्थापित करने के लिए एक संक्षिप्त आउटेज की आवश्यकता होती है क्योंकि तालिका ऑफ़लाइन होनी चाहिए। पुनर्स्थापित स्नैपशॉट लेने के बाद जोड़ा/अपडेट किया गया कोई भी डेटा नष्ट हो जाएगा।
यदि आपकी व्यावसायिक आवश्यकताएं ऐसी हैं कि आपके पास अपने डेटा का ऑफसाइट बैकअप होना चाहिए, तो आप अपने स्थानीय एचडीएफएस क्लस्टर या अपनी पसंद के रिमोट एचडीएफएस क्लस्टर में टेबल के डेटा को डुप्लिकेट करने के लिए एक्सपोर्ट स्नैपशॉट कमांड का उपयोग कर सकते हैं।
स्नैपशॉट हर बार आपकी तालिका की पूरी छवि होते हैं; वर्तमान में कोई वृद्धिशील स्नैपशॉट कार्यक्षमता उपलब्ध नहीं है।
HBase प्रतिकृति
HBase प्रतिकृति एक और बहुत कम ओवरहेड बैकअप उपकरण है। (मेरे सहयोगी हिमांशु वशिष्ठ इस ब्लॉग पोस्ट में प्रतिकृति को विस्तार से शामिल करते हैं।) संक्षेप में, प्रतिकृति को कॉलम-पारिवारिक स्तर पर परिभाषित किया जा सकता है, पृष्ठभूमि में काम करता है, और प्रतिकृति श्रृंखला में समूहों के बीच सभी संपादनों को सिंक में रखता है।
प्रतिकृति के तीन तरीके हैं:मास्टर-> गुलाम, मास्टर <-> मास्टर और चक्रीय। यह दृष्टिकोण आपको किसी भी डेटा केंद्र से डेटा अंतर्ग्रहण करने के लिए लचीलापन देता है और यह सुनिश्चित करता है कि यह अन्य डेटा केंद्रों में उस तालिका की सभी प्रतियों में दोहराया जाए। एक डेटा केंद्र में एक भयावह आउटेज की स्थिति में, क्लाइंट एप्लिकेशन को DNS टूल का उपयोग करने वाले डेटा के लिए एक वैकल्पिक स्थान पर पुनर्निर्देशित किया जा सकता है।
प्रतिकृति एक मजबूत, दोष-सहिष्णु प्रक्रिया है जो "अंतिम स्थिरता" प्रदान करती है, जिसका अर्थ है कि किसी भी समय, तालिका में हाल के संपादन उस तालिका की सभी प्रतिकृतियों में उपलब्ध नहीं हो सकते हैं, लेकिन अंततः वहां पहुंचने की गारंटी है।
नोट:मौजूदा तालिकाओं के लिए, आपको इस पोस्ट में वर्णित अन्य माध्यमों में से किसी एक के माध्यम से पहले स्रोत तालिका को गंतव्य तालिका में मैन्युअल रूप से कॉपी करना होगा। आपके द्वारा इसे सक्षम करने के बाद ही प्रतिकृति केवल नए लेखन/संपादन पर कार्य करती है।

(अपाचे के प्रतिकृति पृष्ठ से)
निर्यात करें
HBase का एक्सपोर्ट टूल एक बिल्ट-इन HBase यूटिलिटी है जो एक HBase टेबल से डेटा को HDFS डायरेक्टरी में प्लेन सीक्वेंसफाइल्स में आसानी से एक्सपोर्ट करने में सक्षम बनाता है। यह एक MapReduce जॉब बनाता है जो आपके क्लस्टर में HBase API कॉल की एक श्रृंखला बनाता है, और एक-एक करके, निर्दिष्ट तालिका से डेटा की प्रत्येक पंक्ति प्राप्त करता है और उस डेटा को आपकी निर्दिष्ट HDFS निर्देशिका में लिखता है। यह टूल आपके क्लस्टर के लिए अधिक प्रदर्शन-गहन है क्योंकि यह MapReduce और HBase क्लाइंट API का उपयोग करता है, लेकिन यह सुविधा संपन्न है और संस्करण या दिनांक सीमा के अनुसार डेटा फ़िल्टर करने का समर्थन करता है - जिससे वृद्धिशील बैकअप सक्षम होता है।
यहाँ कमांड का एक नमूना इसके सरलतम रूप में दिया गया है:
hbase org.apache.hadoop.hbase.mapreduce.Export
एक बार जब आपकी तालिका निर्यात हो जाती है, तो आप परिणामी डेटा फ़ाइलों को अपनी इच्छानुसार कहीं भी कॉपी कर सकते हैं (जैसे ऑफ़साइट/ऑफ़-क्लस्टर संग्रहण)। आप कमांड के आउटपुट स्थान के रूप में एक दूरस्थ एचडीएफएस क्लस्टर/निर्देशिका भी निर्दिष्ट कर सकते हैं, और निर्यात सीधे दूरस्थ क्लस्टर में सामग्री लिख देगा। कृपया ध्यान दें कि यह दृष्टिकोण निर्यात के लेखन पथ में एक नेटवर्क तत्व पेश करेगा, इसलिए आपको पुष्टि करनी चाहिए कि दूरस्थ क्लस्टर से आपका नेटवर्क कनेक्शन विश्वसनीय और तेज़ है।
कॉपीटेबल
जॉन हसीह की ब्लॉग प्रविष्टि में कॉपीटेबल उपयोगिता को अच्छी तरह से कवर किया गया है, लेकिन मैं यहां मूल बातें संक्षेप में बताऊंगा। निर्यात के समान, CopyTable एक MapReduce कार्य बनाता है जो स्रोत तालिका से पढ़ने के लिए HBase API का उपयोग करता है। मुख्य अंतर यह है कि CopyTable अपने आउटपुट को सीधे HBase में एक गंतव्य तालिका में लिखता है, जो आपके स्रोत क्लस्टर या दूरस्थ क्लस्टर पर स्थानीय हो सकता है।
कमांड के सरलतम रूप का एक उदाहरण है:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
यह कमांड "टेस्ट" नाम की एक टेबल की सामग्री को "टेस्टकॉपी" नामक एक ही क्लस्टर में एक टेबल पर कॉपी करेगा।
ध्यान दें कि कॉपीटेबल के लिए एक महत्वपूर्ण प्रदर्शन ओवरहेड है जिसमें यह डेटा, पंक्ति-दर-पंक्ति को गंतव्य तालिका में लिखने के लिए अलग-अलग "पुट" का उपयोग करता है। यदि आपकी तालिका बहुत बड़ी है, तो कॉपीटेबल गंतव्य क्षेत्र के सर्वर पर मेमस्टोर को भरने का कारण बन सकता है, जिसके लिए मेमस्टोर फ्लश की आवश्यकता होती है जो अंततः संघनन, कचरा संग्रह, और इसी तरह की ओर ले जाएगा।
इसके अलावा, आपको HBase पर MapReduce चलाने के प्रदर्शन प्रभावों को ध्यान में रखना चाहिए। बड़े डेटा सेट के साथ, वह दृष्टिकोण आदर्श नहीं हो सकता है।
HTable API (जैसे एक कस्टम जावा एप्लिकेशन)
जैसा कि Hadoop के मामले में हमेशा होता है, आप हमेशा अपना स्वयं का कस्टम एप्लिकेशन लिख सकते हैं जो सार्वजनिक API का उपयोग करता है और तालिका को सीधे क्वेरी करता है। आप उस ढांचे के वितरित बैच प्रसंस्करण लाभों का उपयोग करने के लिए, या अपने स्वयं के डिज़ाइन के किसी अन्य माध्यम के माध्यम से MapReduce नौकरियों के माध्यम से ऐसा कर सकते हैं। हालांकि, इस दृष्टिकोण के लिए Hadoop विकास और सभी API और आपके उत्पादन क्लस्टर में उनका उपयोग करने के प्रदर्शन प्रभाव की गहरी समझ की आवश्यकता है।
कच्चे HDFS डेटा का ऑफ़लाइन बैकअप
सबसे क्रूर-बल बैकअप तंत्र - सबसे विघटनकारी भी - में सबसे बड़ा डेटा पदचिह्न शामिल है। आप अपने HBase क्लस्टर को सफाई से बंद कर सकते हैं और अपने HDFS क्लस्टर में /hbase में रहने वाले सभी डेटा और निर्देशिका संरचनाओं को मैन्युअल रूप से कॉपी कर सकते हैं। चूंकि HBase डाउन है, यह सुनिश्चित करेगा कि सभी डेटा HDFS में HFiles के लिए बने रहे और आपको डेटा की एक सटीक प्रति प्राप्त होगी। हालांकि, वृद्धिशील बैकअप प्राप्त करना लगभग असंभव होगा क्योंकि आप यह पता लगाने में सक्षम नहीं होंगे कि भविष्य के बैकअप का प्रयास करते समय कौन सा डेटा बदल गया है या जोड़ा गया है।
यह नोट करना भी महत्वपूर्ण है कि आपके डेटा को पुनर्स्थापित करने के लिए ऑफ़लाइन मेटा मरम्मत की आवश्यकता होगी क्योंकि .META. तालिका में पुनर्स्थापना के समय संभावित रूप से अमान्य जानकारी होगी। इस दृष्टिकोण के लिए एक तेज़ विश्वसनीय नेटवर्क की भी आवश्यकता होती है ताकि डेटा को ऑफ़साइट स्थानांतरित किया जा सके और यदि आवश्यक हो तो इसे बाद में पुनर्स्थापित किया जा सके।
इन कारणों से, Cloudera HBase बैकअप के लिए इस दृष्टिकोण को अत्यधिक हतोत्साहित करता है।
आपदा रिकवरी
HBase को मूल अतिरेक के साथ एक अत्यंत दोष-सहिष्णु वितरित प्रणाली के रूप में डिज़ाइन किया गया है, यह मानते हुए कि हार्डवेयर अक्सर विफल हो जाएगा। HBase में डिजास्टर रिकवरी आमतौर पर कई रूपों में आती है:
- डेटा केंद्र स्तर पर विनाशकारी विफलता, बैकअप स्थान पर विफलता की आवश्यकता है
- उपयोगकर्ता की त्रुटि या आकस्मिक विलोपन के कारण आपके डेटा की पिछली प्रति को पुनर्स्थापित करने की आवश्यकता है
- ऑडिटिंग उद्देश्यों के लिए आपके डेटा की पॉइंट-इन-टाइम कॉपी को पुनर्स्थापित करने की क्षमता
किसी भी आपदा वसूली योजना की तरह, व्यावसायिक आवश्यकताएं इस बात को संचालित करेंगी कि योजना कैसे तैयार की जाती है और इसमें कितना पैसा निवेश करना है। एक बार जब आप अपनी पसंद का बैकअप स्थापित कर लेते हैं, तो आवश्यक पुनर्प्राप्ति के प्रकार के आधार पर पुनर्स्थापना विभिन्न रूपों में होती है:
- बैकअप क्लस्टर में विफलता
- तालिका आयात करें/स्नैपशॉट पुनर्स्थापित करें
- बैकअप स्थान पर HBase रूट निर्देशिका को इंगित करें
यदि आपकी बैकअप कार्यनीति ऐसी है कि आपने अपने HBase डेटा को किसी भिन्न डेटा केंद्र के बैकअप क्लस्टर में दोहराया है, तो इसे विफल करना आपके अंतिम-उपयोगकर्ता एप्लिकेशन को DNS तकनीकों के साथ बैकअप क्लस्टर की ओर इंगित करने जितना आसान है।
हालांकि, ध्यान रखें कि यदि आप आउटेज अवधि के दौरान डेटा को अपने बैकअप क्लस्टर में लिखने की अनुमति देने की योजना बना रहे हैं, तो आपको यह सुनिश्चित करना होगा कि आउटेज समाप्त होने पर डेटा प्राथमिक क्लस्टर में वापस आ जाए। मास्टर-टू-मास्टर या चक्रीय प्रतिकृति आपके लिए इस प्रक्रिया को स्वचालित रूप से संभाल लेगी, लेकिन मास्टर-स्लेव प्रतिकृति योजना आपके मास्टर क्लस्टर को सिंक से बाहर कर देगी, आउटेज के बाद मैन्युअल हस्तक्षेप की आवश्यकता होगी।
पहले वर्णित निर्यात सुविधा के साथ, एक संबंधित आयात उपकरण है जो निर्यात द्वारा पूर्व में बैकअप किए गए डेटा को ले सकता है और इसे HBase तालिका में पुनर्स्थापित कर सकता है। निर्यात पर लागू होने वाले समान प्रदर्शन निहितार्थ आयात के साथ भी काम करते हैं। अगर आपकी बैकअप योजना में स्नैपशॉट लेना शामिल है, तो अपने डेटा की पिछली कॉपी पर वापस लौटना उस स्नैपशॉट को पुनर्स्थापित करने जितना आसान है।
आप hbase-site.xml में केवल hbase.root.dir गुण को संशोधित करके और इसे अपनी /hbase निर्देशिका की बैकअप प्रतिलिपि की ओर इंगित करके किसी आपदा से उबर सकते हैं यदि आपने HDFS डेटा संरचनाओं की ब्रूट-फ़ोर्स ऑफ़लाइन प्रतिलिपि की थी . हालाँकि, यह पुनर्स्थापना विकल्पों के लिए सबसे कम वांछनीय है क्योंकि जब आप संपूर्ण डेटा संरचना को अपने उत्पादन क्लस्टर में वापस कॉपी करते हैं, और जैसा कि पहले उल्लेख किया गया है, .META को विस्तारित आउटेज की आवश्यकता होती है। सिंक से बाहर हो सकता है।
निष्कर्ष
संक्षेप में, किसी प्रकार के नुकसान या आउटेज के बाद डेटा पुनर्प्राप्त करने के लिए एक अच्छी तरह से डिज़ाइन की गई बीडीआर योजना की आवश्यकता होती है। मैं अत्यधिक अनुशंसा करता हूं कि आप अपटाइम, डेटा सटीकता/उपलब्धता और आपदा पुनर्प्राप्ति के लिए अपनी व्यावसायिक आवश्यकताओं को अच्छी तरह से समझें। अपनी व्यावसायिक आवश्यकताओं के बारे में विस्तृत जानकारी के साथ, आप ध्यान से उन उपकरणों का चयन कर सकते हैं जो उन आवश्यकताओं को सर्वोत्तम रूप से पूरा करते हैं।
हालाँकि, टूल का चयन केवल शुरुआत है। आपको अपनी बीडीआर रणनीति के बड़े पैमाने पर परीक्षण चलाने चाहिए ताकि यह सुनिश्चित हो सके कि यह आपके बुनियादी ढांचे में कार्यात्मक रूप से काम करता है, आपकी व्यावसायिक जरूरतों को पूरा करता है, और यह कि आपकी संचालन टीम एक आउटेज होने से पहले आवश्यक कदमों से बहुत परिचित हैं और आप कठिन तरीके का पता लगाते हैं आपकी बीडीआर योजना काम नहीं करेगी।
यदि आप इस विषय पर टिप्पणी करना या आगे चर्चा करना चाहते हैं, तो HBase के लिए हमारे सामुदायिक फ़ोरम का उपयोग करें।
आगे पढ़ना:
- जॉन हसीह की स्ट्रैटा + हडूप वर्ल्ड 2012 प्रस्तुति
- HBase:निश्चित मार्गदर्शिका (लार्स जॉर्ज)
- HBase इन एक्शन (निक दिमिदुक/अमनदीप खुराना)



