
काउचबेस क्या है
काउचबेस सर्वर एक खुला स्रोत, वितरित, JSON दस्तावेज़ डेटाबेस है। यह सब-मिलीसेकंड डेटा ऑपरेशंस के लिए प्रबंधित कैश के साथ स्केल-आउट, की-वैल्यू स्टोर, कुशल प्रश्नों के लिए उद्देश्य-निर्मित इंडेक्सर्स और SQL जैसी क्वेरी को निष्पादित करने के लिए एक शक्तिशाली क्वेरी इंजन को उजागर करता है। मोबाइल और इंटरनेट ऑफ थिंग्स परिवेशों के लिए काउचबेस मूल रूप से डिवाइस पर भी चलता है और सर्वर से सिंक्रनाइज़ेशन का प्रबंधन करता है।
काउचबेस क्यों?
काउचबेस सर्वर एक खुला स्रोत, वितरित, JSON दस्तावेज़ डेटाबेस है। यह सब-मिलीसेकंड डेटा ऑपरेशंस के लिए प्रबंधित कैश के साथ स्केल-आउट, की-वैल्यू स्टोर, कुशल प्रश्नों के लिए उद्देश्य-निर्मित इंडेक्सर्स और SQL जैसी क्वेरी को निष्पादित करने के लिए एक शक्तिशाली क्वेरी इंजन को उजागर करता है। मोबाइल और इंटरनेट ऑफ थिंग्स परिवेशों के लिए काउचबेस मूल रूप से डिवाइस पर भी चलता है और सर्वर से सिंक्रनाइज़ेशन का प्रबंधन करता है।
काउचबेस सर्वर बड़े पैमाने पर इंटरैक्टिव वेब, मोबाइल और आईओटी अनुप्रयोगों के लिए कम विलंबता डेटा प्रबंधन प्रदान करने के लिए विशिष्ट है। काउचबेस सर्वर को जिन सामान्य आवश्यकताओं को पूरा करने के लिए डिज़ाइन किया गया था उनमें शामिल हैं:
- एकीकृत प्रोग्रामिंग इंटरफ़ेस
- क्वेरी
- खोज
- मोबाइल और IoT
- एनालिटिक्स
- कोर डेटाबेस इंजन
- स्केल-आउट आर्किटेक्चर
- मेमोरी-फर्स्ट आर्किटेक्चर
- बड़ा डेटा और SQL एकीकरण
- पूर्ण-स्टैक सुरक्षा
- कंटेनर और क्लाउड परिनियोजन
- उच्च उपलब्धता
कई डेटाबेस इनमें से एक या अधिक आवश्यकताओं को पूरा करने में सक्षम हैं, लेकिन इंटरनेट-स्केल, मिशन महत्वपूर्ण अनुप्रयोगों के साथ उत्पादन में चलते समय ट्रेडऑफ़ की आवश्यकता होती है। उदाहरण के लिए, एक समाधान डेटा मॉडल लचीलापन प्रदान कर सकता है लेकिन अप-टाइम या प्रदर्शन पर प्रभाव के बिना नोड्स को जोड़ने या निकालने की क्षमता का अभाव हो सकता है। एक और समाधान फ्लाई पर डेटा मॉडल को इंडेक्स या बदलने में सक्षम होने के बिना अच्छी लेखन मापनीयता प्रदर्शित कर सकता है। काउचबेस सर्वर को बड़े पैमाने पर प्रदर्शन प्रदान करते हुए उत्पादक डेवलपर और प्रशासन अनुभव प्रदान करने के लिए डिज़ाइन किया गया है, चाहे क्लाउड में, कंटेनर में, ऑन-प्रिमाइसेस या एज डिवाइस पर।
Nosql प्रदर्शन बेंचमार्क
MongoDB, DataStax और Couchbase सर्वर की तुलना करने वाला नया बेंचमार्क काउचबेस को सबसे अधिक स्केलेबल, सर्वश्रेष्ठ प्रदर्शन करने वाले NoSQL डेटाबेस के रूप में प्रदर्शित करता है।
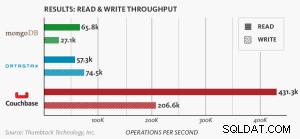
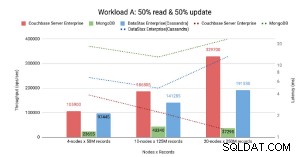
नोड आधारित बेंचमार्क ।
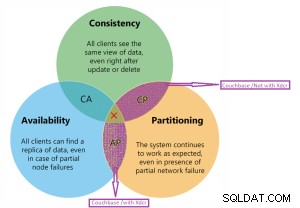
CAP प्रमेय काउचबेस के अनुसार।
कैप प्रमेय
<मजबूत> 
काउचबेस CP और AP डायग्राम पर है।
काउचबेस सीपी और एपी आरेख विवरण।
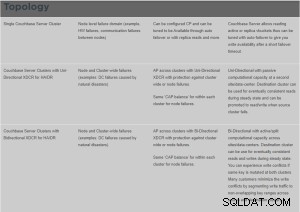
XDCR क्या है?
क्रॉस डेटा सेंटर प्रतिकृति (XDCR) क्लस्टर के बीच डेटा की प्रतिकृति बनाता है:यह डेटा-सेंटर विफलता से सुरक्षा प्रदान करता है, और विश्व स्तर पर वितरित, मिशन-महत्वपूर्ण अनुप्रयोगों के लिए उच्च-प्रदर्शन डेटा-पहुंच भी प्रदान करता है।
XDCR स्रोत क्लस्टर पर एक विशिष्ट बकेट से लक्ष्य क्लस्टर पर एक विशिष्ट बकेट में डेटा की प्रतिकृति बनाता है। स्रोत बकेट से डेटा को डेटाबेस परिवर्तन प्रोटोकॉल का उपयोग करते हुए, स्रोत क्लस्टर पर चल रहे XDCR एजेंट के माध्यम से लक्ष्य बकेट में धकेला जाता है। किसी भी क्लस्टर पर किसी भी बकेट (काउचबेस या एफेमेरल) को एक या अधिक XDCR परिभाषाओं के स्रोत या लक्ष्य के रूप में निर्दिष्ट किया जा सकता है।
क्रॉस डेटा सेंटर प्रतिकृति (एक्सडीसीआर) में एक्सडीसीआर का पूरा वास्तुशिल्प विवरण प्रदान किया गया है। आप इस खंड में प्रदान की गई दिनचर्या को करने से पहले, वहां दी गई जानकारी से खुद को परिचित करना चाह सकते हैं।
Xdcr मूल संरचना;
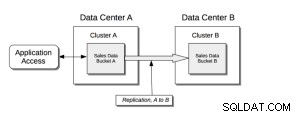
पूर्व-आवश्यकताएं;
- पुष्टि करें कि आपका क्लस्टर ठीक से आकार में है और नई XDCR स्ट्रीम को संभालने में सक्षम है। उदाहरण के लिए, XDCR को प्रति स्ट्रीम 1-2 अतिरिक्त CPU कोर की आवश्यकता होती है और कुछ मामलों में इसके लिए अधिक RAM और नेटवर्क संसाधनों की भी आवश्यकता होगी। यदि क्लस्टर मौजूदा कार्यभार के साथ-साथ नई XDCR स्ट्रीम के लिए ठीक से आकार में नहीं है, तो XDCR सर्वर संसाधनों के लिए प्रतिस्पर्धा कर सकता है और समग्र प्रदर्शन पर नकारात्मक प्रभाव डाल सकता है।
- क्लस्टर कॉन्फ़िगरेशन जानकारी का आदान-प्रदान करने के लिए काउचबेस सर्वर टीसीपी/आईपी पोर्ट 8091 का उपयोग करता है। यदि आप एक समर्पित कनेक्शन या इंटरनेट पर एक गंतव्य क्लस्टर के साथ संचार कर रहे हैं, तो आपको यह सुनिश्चित करना चाहिए कि गंतव्य और स्रोत क्लस्टर में सभी नोड एक दूसरे के साथ पोर्ट 8091 और 8092 पर संचार कर सकते हैं।
संचार पथ द्वारा सूचीबद्ध पोर्ट
| XDCR (क्लस्टर-टू-क्लस्टर) |
|
काउचबेस डिस्क और रैम दोनों में डेटा स्टोर करता है। डिफ़ॉल्ट व्यवहार रैम में संग्रहीत करने के बाद कुछ मनमाने समय (आमतौर पर जल्दी) पर दस्तावेज़ को डिस्क पर लिखना है। यह एक छोटी विंडो छोड़ता है जहां नोड विफलता के परिणामस्वरूप डेटा की हानि हो सकती है।
किसी भी स्थिति में, RAM को लिखने के बाद, दस्तावेज़ अंततः डिस्क पर लिखा जाएगा। काउचबेस एक डिस्क राइट क्यू रखता है जिसे आप मैनेजमेंट कंसोल में मेट्रिक्स रिपोर्ट पेज पर देख सकते हैं। अब, सीबी पूरे क्लस्टर में राइट्स को सिंक्रोनाइज़ करता है, और मेरा मानना है कि काउचबेस द्वारा यह स्वीकार करने से पहले कि राइट हुआ है (उदाहरण के लिए राइट मेथड कॉलर को वापस आने से पहले) एक क्लस्टर में एक राइट को सिंक्रोनाइज़ किया जाएगा।
यदि आपके पास उपलब्ध RAM से अधिक दस्तावेज़ हैं, तो त्वरित पुनर्प्राप्ति के लिए केवल सबसे अधिक बार एक्सेस किए जाने वाले दस्तावेज़ RAM में संग्रहीत किए जाएंगे, अन्य सभी को डिस्क पर "बेदखल" किया जाएगा।
सलाह;
जब स्रोत में बकेट का आकार 200 gb से घटकर 10 gb हो गया, तो प्रतिकृति काफी तेज हो गई। दूसरे शब्दों में, यदि बकेट का आकार अधिक है और सभी डेटा रैम में है, तो मैंने देखा है कि प्रतिकृति में 10 सेकंड का अंतर था।
स्रोत और लक्ष्य में समान लिनक्स सेटिंग और समान संसाधन हैं। यह सिर्फ सलाह है।
उत्पाद बकेट निवासी %100 होना चाहिए। क्योंकि प्रतिकृति गति महत्वपूर्ण है।
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
सलाह;
मेरा सुझाव है कि स्रोत और लक्ष्य एक ही सेटिंग हों और उनके पास समान संसाधन हों।
ये बकेट सेटिंग, क्लस्टर सेटिंग, सीपीयू, मेमोरी, डिस्क क्वालिटी आदि हैं।
Xdcr प्रतिकृति सिर्फ डेटा प्रतिकृति है। प्रतिकृति से पहले, आपको बकेट मेटाडेटा बनाना होगा।
यदि आप चाहते हैं, तो आप उपयोगकर्ता, अनुक्रमणिका, दृश्य, घटना आदि बनाते हैं।
अतिरिक्त जानकारी के रूप में;
आप सामुदायिक संस्करण पर xdcr प्रतिकृति बना सकते हैं।
आप एंटरप्राइज़ संस्करण पर xdcr प्रतिकृति बना सकते हैं। इसके लिए अतिरिक्त लाइसेंस की आवश्यकता है। यदि आप एक उत्पाद के रूप में स्टैंडबाय का उपयोग नहीं करते हैं, तो यह उच्च शुल्क नहीं है।
XDCR के लिए काउचबेस के अन्य कनेक्टर; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
काउचबेस प्रबंधन WEB UI, REST API और CLI के माध्यम से किया जा सकता है। विशेष रूप से, वेब यूजर इंटरफेस उपयोग करने के लिए बहुत सरल और सीधा है। आप यूजर इंटरफेस के माध्यम से कई परिचालन लेनदेन और पूछताछ कर सकते हैं।
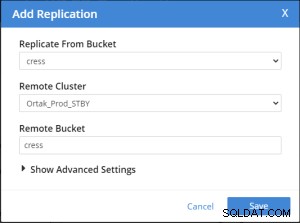
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Xdcr क्लस्टर सेटिंग्स के लिए मेमोरी सेटिंग्स सर्वर मेमोरी वैल्यू के अनुसार दी जाती हैं।
सर्वर मेमोरी के लिए फ्री साइज होना चाहिए।
Xdcr को उत्पाद क्लस्टर में अतिरिक्त मेमोरी की आवश्यकता है।
एक से अधिक काउचबेस बकेट प्रतिकृति संभव है।
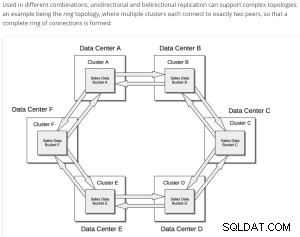
उदाहरण XDCR प्रतिकृति सरल ऑपरेशन;
काउचबेस होमपेज पर Xdcr टैब चयनित।

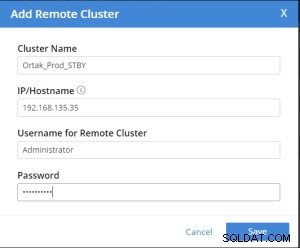
रिमोट क्लस्टर जोड़ें टैब चयनित xdcr टैब पर चुना गया है।

दूरस्थ क्लस्टर जोड़ें ऑपरेशन निम्नलिखित किया जाता है।
प्रतिकृति जोड़ें टैब चयनित xdcr टैब पर चयनित है।
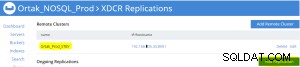
बकेट जोड़ें प्रतिकृति ऑपरेशन निम्नलिखित किया जाता है।
xdcr प्रदर्शन के लिए सर्वश्रेष्ठ पैरामीटर। लेकिन इसे आपके सिस्टम के लिए फिर से सेट किया जा सकता है।

स्रोत (उत्पाद) के xdcr टैब पर प्रतिकृति स्थिति
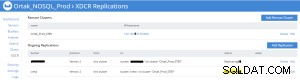
बकेट प्रतिकृति सांख्यिकी
प्रतिकृति प्रदर्शन लक्ष्य पर;

स्रोत पर प्रतिकृति प्रदर्शन;

संदर्भ;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
फतह जेनकाली - काउचबेस सर्टिफिकेशन





