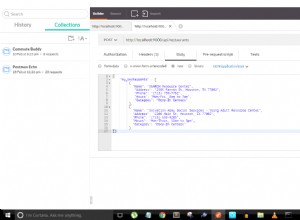
व्याख्या योजना आउटपुट से कुछ प्रमुख बिंदु:
- क्वेरी निम्नलिखित विशेषताओं को संबोधित करती है:
siteId, status, creationDate, reportCount, assignee, parent - विजेता योजना के दो चरण हैं:
- IX_SCAN
creationDate_1_reportCount_1_label_1. का उपयोग करता है , यहcreationDate. पर अनुक्रमित लुकअप का उपयोग करता है औरreportCount56 दस्तावेज़ों की पहचान करने के लिए जिन्हें बाद में FETCH चरण में अग्रेषित किया जाता है - FETCH IX_SCAN चरण से 56 दस्तावेज़ प्राप्त करता है और फिर
siteIdलागू करने के लिए इन दस्तावेज़ों से पूछताछ करता है ,status,assigneeऔरparentफिल्टर। इस पूछताछ के कारण 37 दस्तावेज़ों को छोड़ दिया जाता है जिसके परिणामस्वरूप 19 दस्तावेज़ वापस कर दिए जाते हैं।
- IX_SCAN
इसलिए, आपकी अनुक्रमणिका आपकी क्वेरी में 6 में से केवल 2 विशेषताओं को शामिल करती है और आपकी क्वेरी में शेष 4 विशेषताओं को दस्तावेज़ों की जांच करके लागू किया जाता है। सूचकांक . नहीं . यदि आप चाहते हैं कि इस क्वेरी को पूरी तरह से अनुक्रमित किया जाए तो निम्न अनुक्रमणिका बनाएं:
db.collection.createIndex(
{siteId: 1, status: 1, creationDate: 1, reportCount: 1, assignee: 1, parent: 1}
)
यदि आप इस इंडेक्स के साथ फिर से चलते हैं तो आपको यह पता लगाना चाहिए कि (ए) मोंगोडीबी इस इंडेक्स को चुनता है और (बी) IX_SCAN चरण द्वारा अग्रेषित दस्तावेजों की संख्या आपके खोज कॉल द्वारा लौटाए गए दस्तावेज़ों की संख्या के समान है।
मैं कहता हूँ "ढूंढना चाहिए" क्योंकि यहां अन्य पहलू भी हैं जिसके परिणामस्वरूप मोंगोडीबी एक अलग इंडेक्स चुन सकता है उदा। $nor . का उपयोग और सॉर्ट चरण (creationDate: 1 ) मैं अनुशंसा करता हूं कि इंडेक्स को ट्वीव करें और प्रत्येक ट्वीक के बाद व्याख्या 'चालू' के साथ चलें और executionStats में इन प्रमुख वस्तुओं की तलाश करें। उप दस्तावेज़:
- "nलौटा"
- "totalKeysपरीक्षित"
- "कुल डॉक्स की जांच की गई"
अंगूठे का एक सरल नियम यह है:जितना करीब totalKeysExamined nReturned . के लिए है और करीब totalDocsExamined शून्य पर है ... आपका इंडेक्स कवरेज बेहतर है।
एक सूचकांक की लागत (लेखन समय और सूचकांक भंडारण पर प्रभाव के संदर्भ में) का भी सवाल है, इसलिए मैं आपकी गैर-कार्यात्मक आवश्यकताओं पर विचार करने का सुझाव दूंगा - क्या आपका वांछित बीता हुआ समय पूर्ण सूचकांक कवरेज के बिना प्राप्त किया जा सकता है? यदि नहीं, तो आपको अनुभवजन्य परीक्षण के साथ आगे बढ़ना चाहिए लेकिन explain() के जवाब में अपनी पसंद को बदलने के लिए तैयार रहना चाहिए। आउटपुट आपको बताता है।