सबसे पहले, आइए इस पर विचार करें कि GridFS क्या है? वास्तव में है। और एक शुरुआत के रूप में, संदर्भित मैन्युअल पृष्ठ से पढ़ने दें:
तो उस रास्ते से बाहर, और यह आपके उपयोग का मामला भी हो सकता है। लेकिन यहां सीखने का सबक यह है कि GridFS स्वचालित रूप से . नहीं है फ़ाइलों को संग्रहीत करने के लिए "गो-टू" विधि।
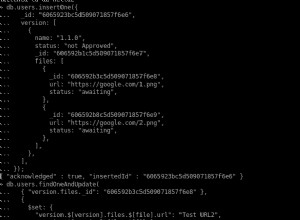
आपके मामले (और अन्य) में यहां जो हुआ है वह "चालक स्तर" विनिर्देश के कारण है कि यह है (और MongoDB स्वयं नहीं . करता है मैजिक यहां), आपकी "फाइलें" दो संग्रहों में "विभाजित" हो गई हैं। एक संग्रह सामग्री के मुख्य संदर्भ के लिए, और दूसरा डेटा के "भाग" के लिए।
आपकी समस्या (और अन्य), यह है कि अब आप "हिस्सा" को पीछे छोड़ने में कामयाब रहे हैं कि "मुख्य" संदर्भ हटा दिया गया है। तो बड़ी संख्या के साथ, अनाथों से कैसे छुटकारा पाया जाए।
आपका वर्तमान पठन "लूप और तुलना" कहता है, और चूंकि MongoDB जोड़ता नहीं है , तो वास्तव में कोई अन्य उत्तर नहीं है। लेकिन कुछ चीजें हैं जो मदद कर सकती हैं।
तो एक विशाल $nin run चलाने के बजाय , इसे तोड़ने के लिए कुछ अलग चीजें करने का प्रयास करें। उदाहरण के लिए, उल्टे क्रम पर काम करने पर विचार करें:
db.fs.chunks.aggregate([
{ "$group": { "_id": "$files_id" } },
{ "$limit": 5000 }
])
तो आप वहां जो कर रहे हैं वह विशिष्ट . हो रहा है "files_id" मान (fs.files . के संदर्भ के रूप में) ), सभी प्रविष्टियों में से, आपकी 5000 प्रविष्टियों के साथ शुरू करने के लिए। फिर निश्चित रूप से आप लूपिंग पर वापस आ गए हैं, fs.files . की जाँच कर रहे हैं मेल खाने वाले _id . के लिए . अगर कुछ नहीं मिलता है, तो निकालें आपके "खंड" से "files_id" से मेल खाने वाले दस्तावेज़।
लेकिन वह केवल 5000 था, इसलिए रखें आखिरी उस सेट में आईडी मिली, क्योंकि अब आप फिर से वही एग्रीगेट स्टेटमेंट चलाने जा रहे हैं, लेकिन अलग तरीके से:
db.fs.chunks.aggregate([
{ "$match": { "files_id": { "$gte": last_id } } },
{ "$group": { "_id": "$files_id" } },
{ "$limit": 5000 }
])
तो यह काम करता है क्योंकि ObjectId मान हैं मोनोटोनिक
या "हमेशा बढ़ रहा है"। तो सभी नया प्रविष्टियां हमेशा इससे अधिक होती हैं अंतिम। फिर आप उन मानों को फिर से एक लूप में ले जा सकते हैं और वही हटा सकते हैं जहां नहीं मिला।
क्या यह "हमेशा के लिए ले जाएगा"। खैर हां . आप शायद रोजगार db.eval()
इसके लिए, लेकिन पढ़ें दस्तावेज़ीकरण। लेकिन कुल मिलाकर, यह वह कीमत है जिसका भुगतान आप दो . का उपयोग करने के लिए करते हैं संग्रह।
शुरुआत से। GridFS कल्पना डिज़ाइन . है इस तरह क्योंकि यह विशेष रूप से करना चाहता है 16MB सीमा के आसपास काम करें। लेकिन अगर वह नहीं है अपनी सीमा, फिर सवाल करें क्यों आप GridFS का उपयोग कर रहे हैं पहले स्थान पर।
MongoDB में कोई समस्या नहीं है किसी दिए गए बीएसओएन दस्तावेज़ के किसी भी तत्व के भीतर "बाइनरी" डेटा संग्रहीत करना। तो आपको जरूरत नहीं है GridFS का उपयोग करने के लिए सिर्फ फाइलों को स्टोर करने के लिए। और अगर आपने ऐसा किया होता, तो सभी आपके अपडेट पूरी तरह से "परमाणु" होंगे, क्योंकि वे केवल एक . पर कार्य करते हैं एक . में दस्तावेज़ एक बार में संग्रह।
चूंकि GridFS
जानबूझकर दस्तावेज़ों को संग्रह में विभाजित करता है, तो यदि आप इसका उपयोग करते हैं, तो आप दर्द के साथ जीते हैं। इसलिए अगर आपको ज़रूरत हो . तो इसका इस्तेमाल करें यह, लेकिन यदि आप नहीं . करते हैं , तो बस BinData स्टोर करें एक सामान्य क्षेत्र के रूप में, और ये समस्याएं दूर हो जाती हैं।
लेकिन कम से कम आपके पास सब कुछ स्मृति में लोड करने से बेहतर तरीका है।