ClusterControl 1.6 AWS, Azure और Google Cloud के साथ सख्त एकीकरण के साथ आता है, इसलिए अब नए इंस्टेंस लॉन्च करना और MySQL, MariaDB, MongoDB और PostgreSQL को सीधे ClusterControl यूजर इंटरफेस से तैनात करना संभव है। इस ब्लॉग में, हम आपको दिखाएंगे कि Amazon वेब सेवाओं पर क्लस्टर कैसे परिनियोजित किया जाए।
ध्यान दें कि इस नई सुविधा के लिए क्लस्टरकंट्रोल-क्लाउड called नामक दो मॉड्यूल की आवश्यकता है और क्लस्टरकंट्रोल-क्लड . पहला एक हेल्पर डेमॉन है जो क्लाउड कम्युनिकेशन की सीएमओएन क्षमता को बढ़ाता है, जबकि दूसरा क्लाउड इंस्टेंस पर फाइल अपलोड और डाउनलोड करने के लिए फाइल मैनेजर क्लाइंट है। दोनों पैकेज क्लस्टरकंट्रोल यूआई पैकेज की निर्भरता हैं, जो मौजूद नहीं होने पर स्वचालित रूप से स्थापित हो जाएंगे। विवरण के लिए घटक दस्तावेज़ीकरण पृष्ठ देखें।
क्लाउड क्रेडेंशियल
ClusterControl आपको इंटीग्रेशन (साइड मेन्यू) -> क्लाउड प्रोवाइडर्स:
के तहत अपने क्लाउड क्रेडेंशियल्स को स्टोर और मैनेज करने की अनुमति देता है।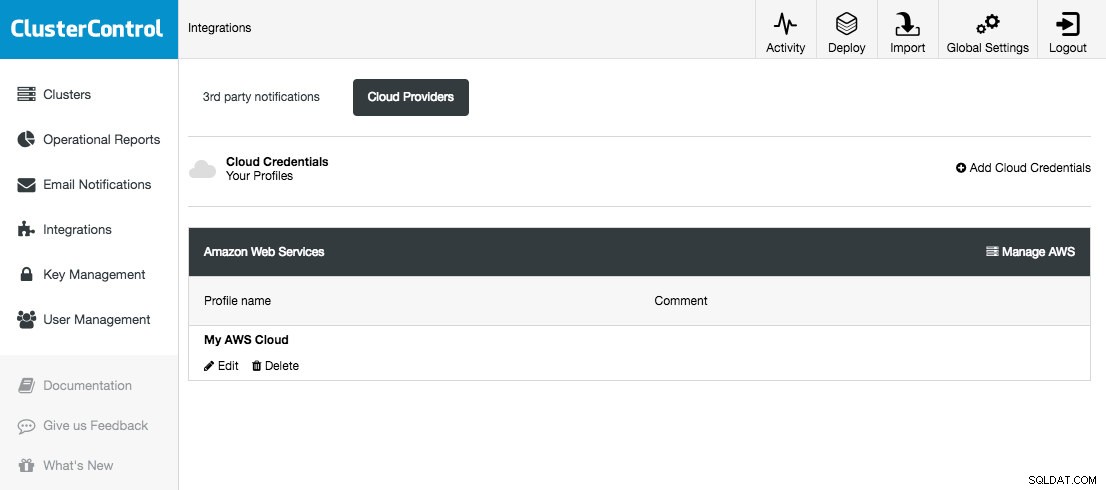
इस रिलीज़ में समर्थित क्लाउड प्लेटफ़ॉर्म Amazon Web Services, Google Cloud Platform और Microsoft Azure हैं। इस पृष्ठ पर, आप नए क्लाउड क्रेडेंशियल जोड़ सकते हैं, मौजूदा को प्रबंधित कर सकते हैं और संसाधनों को प्रबंधित करने के लिए अपने क्लाउड प्लेटफ़ॉर्म से भी कनेक्ट कर सकते हैं।
यहां स्थापित किए गए क्रेडेंशियल का उपयोग निम्न के लिए किया जा सकता है:
- क्लाउड संसाधन प्रबंधित करें
- डेटाबेस को क्लाउड में परिनियोजित करें
- क्लाउड स्टोरेज में बैकअप अपलोड करें
यदि आप "AWS प्रबंधित करें" बटन पर क्लिक करते हैं, तो आपको निम्न दिखाई देगा:
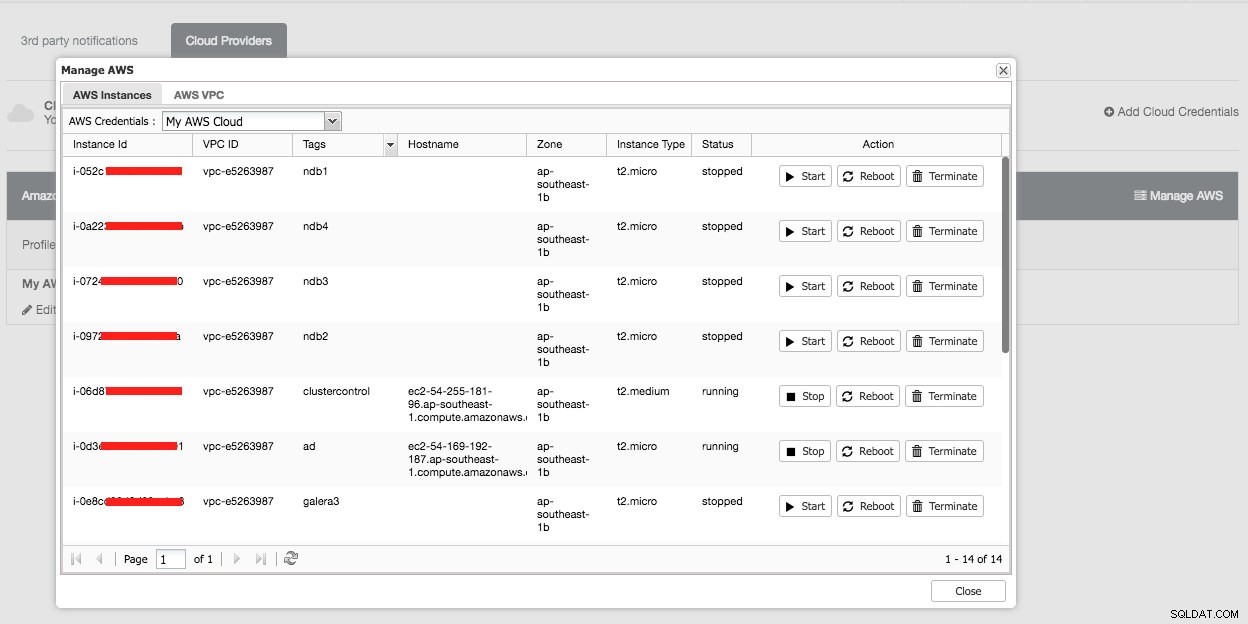
आप अपने क्लाउड इंस्टेंस पर सरल प्रबंधन कार्य कर सकते हैं। आप "एडब्ल्यूएस वीपीसी" टैब के अंतर्गत वीपीसी सेटिंग्स भी देख सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है:
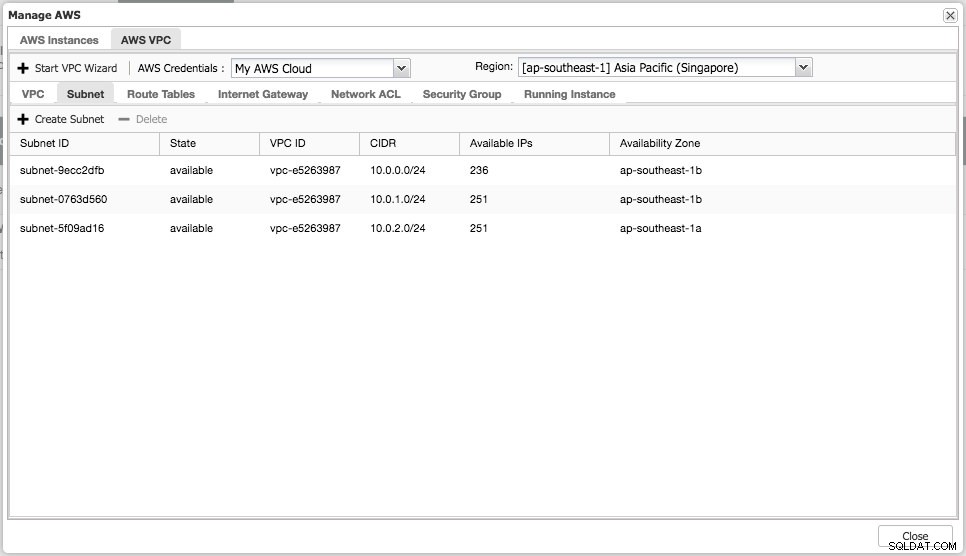
उपरोक्त विशेषताएं संदर्भ के रूप में उपयोगी हैं, खासकर जब आप डेटाबेस परिनियोजन शुरू करने से पहले अपने क्लाउड इंस्टेंस तैयार करते हैं।
क्लाउड पर डेटाबेस परिनियोजन
ClusterControl के पिछले संस्करणों में, क्लाउड पर डेटाबेस परिनियोजन को मानक होस्ट पर परिनियोजन के समान माना जाएगा, जहाँ आपको पहले से क्लाउड इंस्टेंस बनाना था और फिर "डेटाबेस क्लस्टर परिनियोजित करें" विज़ार्ड में इंस्टेंस विवरण और क्रेडेंशियल की आपूर्ति करना था। परिनियोजन प्रक्रिया क्लाउड वातावरण में किसी भी अतिरिक्त कार्यक्षमता और लचीलेपन से अनजान थी, जैसे गतिशील आईपी और होस्टनाम आवंटन, एनएटी-एड सार्वजनिक आईपी पता, भंडारण लोच, आभासी निजी क्लाउड नेटवर्क कॉन्फ़िगरेशन और इसी तरह।
संस्करण 1.6 के साथ, आपको केवल क्लाउड क्रेडेंशियल की आपूर्ति करने की आवश्यकता है, जिसे "क्लाउड प्रदाता" इंटरफ़ेस के माध्यम से प्रबंधित किया जा सकता है और "क्लाउड में परिनियोजन" परिनियोजन विज़ार्ड का पालन करें। ClusterControl UI से, परिनियोजन पर क्लिक करें और आपको निम्नलिखित विकल्पों के साथ प्रस्तुत किया जाएगा:
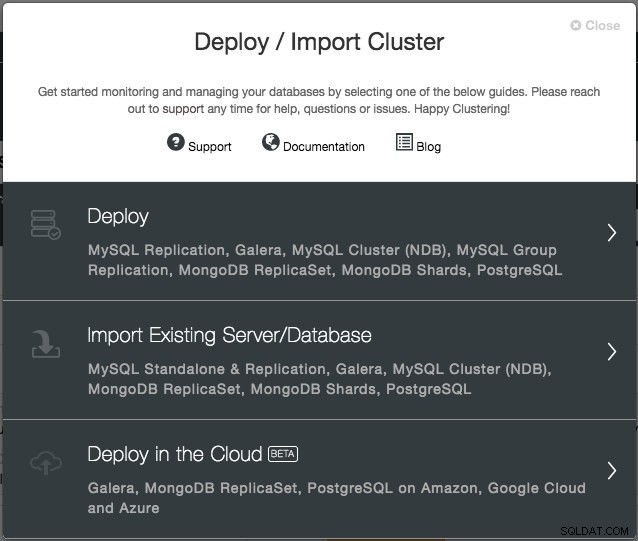
फिलहाल, समर्थित क्लाउड प्रदाता तीन बड़े खिलाड़ी हैं - Amazon Web Service (AWS), Google Cloud और Microsoft Azure। हम भावी रिलीज़ में और अधिक प्रदाताओं को एकीकृत करने जा रहे हैं।
पहले पृष्ठ में, आपको क्लस्टर विवरण विकल्पों के साथ प्रस्तुत किया जाएगा:
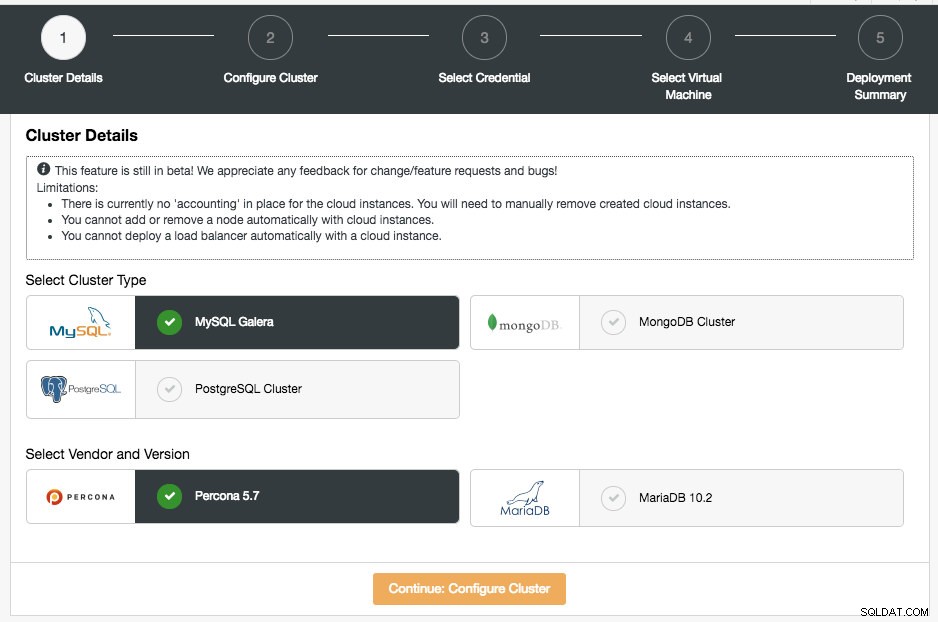
इस खंड में, आपको समर्थित क्लस्टर प्रकार, MySQL गैलेरा क्लस्टर, MongoDB प्रतिकृति सेट या PostgreSQL स्ट्रीमिंग प्रतिकृति का चयन करना होगा। अगला चरण चयनित क्लस्टर प्रकार के लिए समर्थित विक्रेता को चुनना है। फिलहाल, निम्नलिखित विक्रेता और संस्करण समर्थित हैं:
- MySQL Galera Cluster - Percona XtraDB Cluster 5.7, MariaDB 10.2
- MongoDB क्लस्टर - MongoDB, Inc द्वारा MongoDB 3.4 और Percona द्वारा MongoDB 3.4 के लिए Percona सर्वर (केवल प्रतिकृति सेट)।
- PostgreSQL क्लस्टर - PostgreSQL 10.0 (केवल स्ट्रीमिंग प्रतिकृति)।
अगले चरण में, आपको निम्नलिखित संवाद प्रस्तुत किया जाएगा:
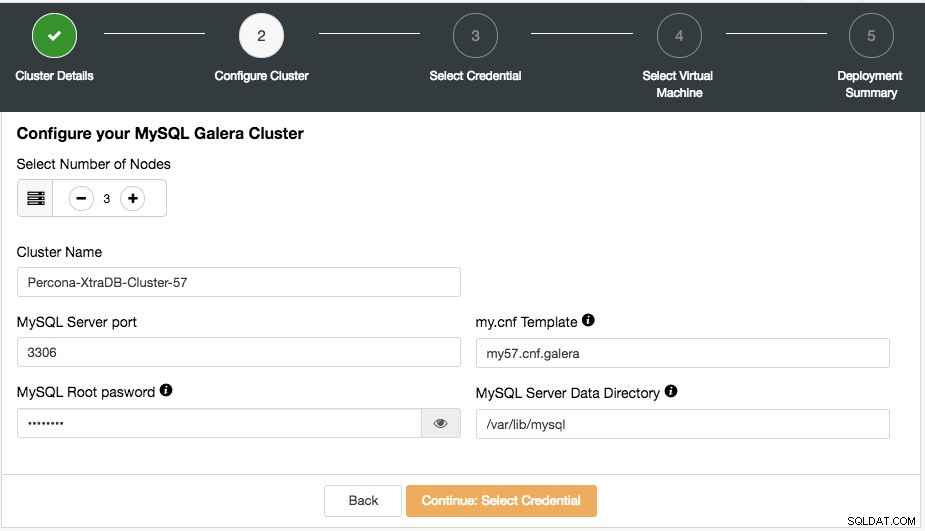
यहां आप अपने अनुसार चयनित क्लस्टर प्रकार को कॉन्फ़िगर कर सकते हैं। नोड्स की संख्या चुनें। क्लस्टर नाम का उपयोग इंस्टेंस टैग के रूप में किया जाएगा, ताकि आप अपने क्लाउड प्रदाता डैशबोर्ड में इस परिनियोजन को आसानी से पहचान सकें। क्लस्टर नाम में किसी स्थान की अनुमति नहीं है। My.cnf टेम्पलेट टेम्पलेट कॉन्फ़िगरेशन फ़ाइल है जिसका उपयोग ClusterControl क्लस्टर को परिनियोजित करने के लिए करेगा। यह ClusterControl होस्ट पर /usr/share/cmon/templates के अंतर्गत अवस्थित होना चाहिए। बाकी क्षेत्र बहुत ही आत्म-व्याख्यात्मक हैं।
अगला संवाद क्लाउड क्रेडेंशियल्स का चयन करना है:
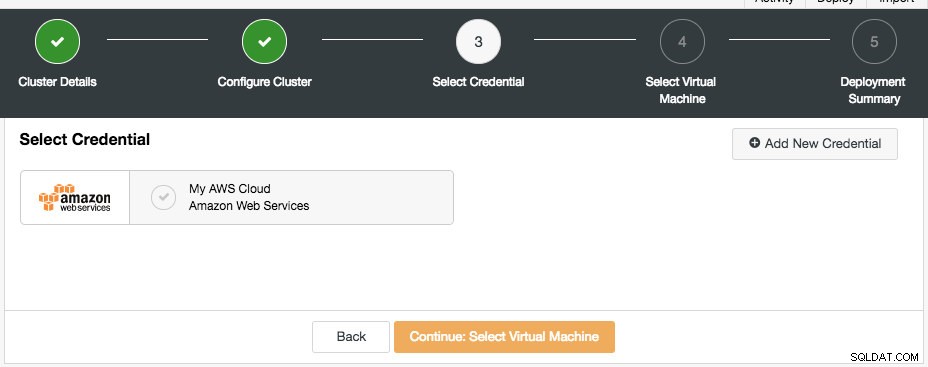
आप मौजूदा क्लाउड क्रेडेंशियल चुन सकते हैं या "नया क्रेडेंशियल जोड़ें" बटन पर क्लिक करके एक नया बना सकते हैं। अगला चरण वर्चुअल मशीन कॉन्फ़िगरेशन चुनना है:
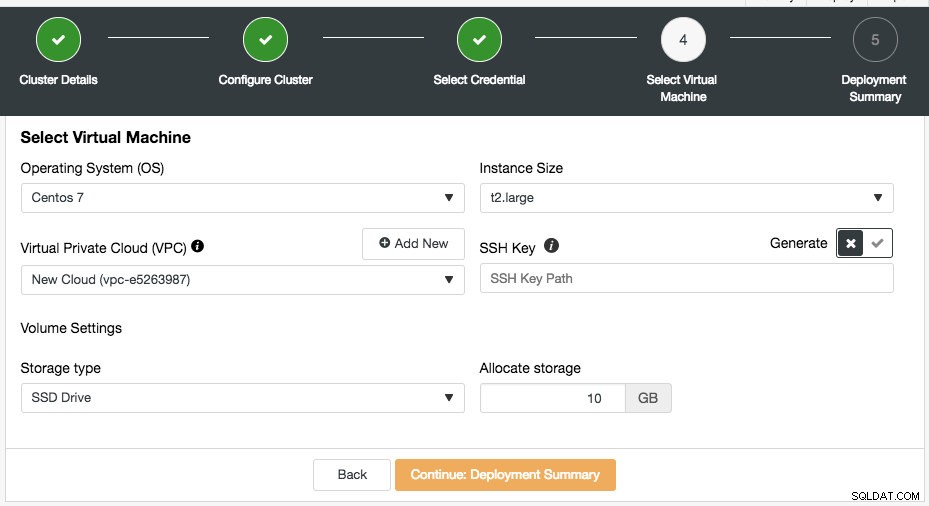
इस चरण की अधिकांश सेटिंग्स क्लाउड प्रदाता से चुने गए क्रेडेंशियल द्वारा गतिशील रूप से पॉप्युलेट की जाती हैं। आप ऑपरेटिंग सिस्टम, इंस्टेंस आकार, वीपीसी सेटिंग, स्टोरेज प्रकार और आकार को कॉन्फ़िगर कर सकते हैं और क्लस्टर कंट्रोल होस्ट पर एसएसएच कुंजी स्थान भी निर्दिष्ट कर सकते हैं। आप विशेष रूप से इन उदाहरणों के लिए ClusterControl को एक नई कुंजी उत्पन्न करने दे सकते हैं। वर्चुअल प्राइवेट क्लाउड के बगल में "नया जोड़ें" बटन पर क्लिक करने पर, आपको एक नया वीपीसी बनाने के लिए एक फॉर्म प्रस्तुत किया जाएगा:
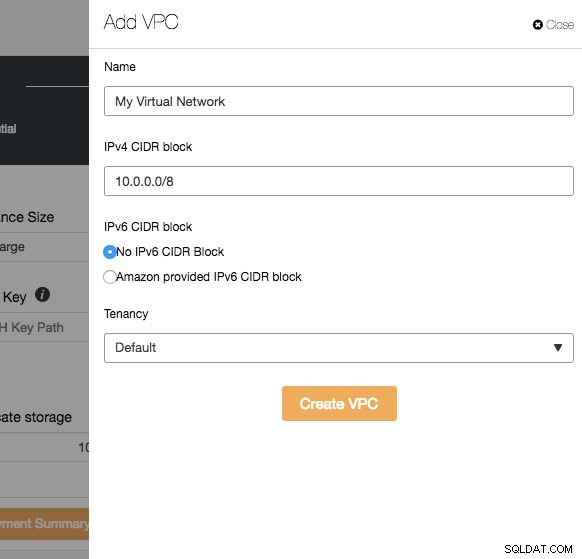
VPC एक तार्किक नेटवर्क इन्फ्रास्ट्रक्चर है जो आपके क्लाउड प्लेटफॉर्म के भीतर है। आप अपने वीपीसी को इसकी आईपी पता श्रेणी को संशोधित करके, सबनेट बनाकर, रूट टेबल, नेटवर्क गेटवे और सुरक्षा सेटिंग्स को कॉन्फ़िगर करके कॉन्फ़िगर कर सकते हैं। अलगाव, सुरक्षा और रूटिंग नियंत्रण के लिए इस नेटवर्क में अपने डेटाबेस के बुनियादी ढांचे को तैनात करने की अनुशंसा की जाती है।
नया VPC बनाते समय, सबनेट के साथ VPC नाम और IPv4 पता ब्लॉक निर्दिष्ट करें। फिर, चुनें कि क्या IPv6 नेटवर्क और किरायेदारी विकल्प का हिस्सा होना चाहिए। फिर आप इस वर्चुअल नेटवर्क का उपयोग अपने डेटाबेस इन्फ्रास्ट्रक्चर के लिए कर सकते हैं।
अंतिम चरण परिनियोजन सारांश है:
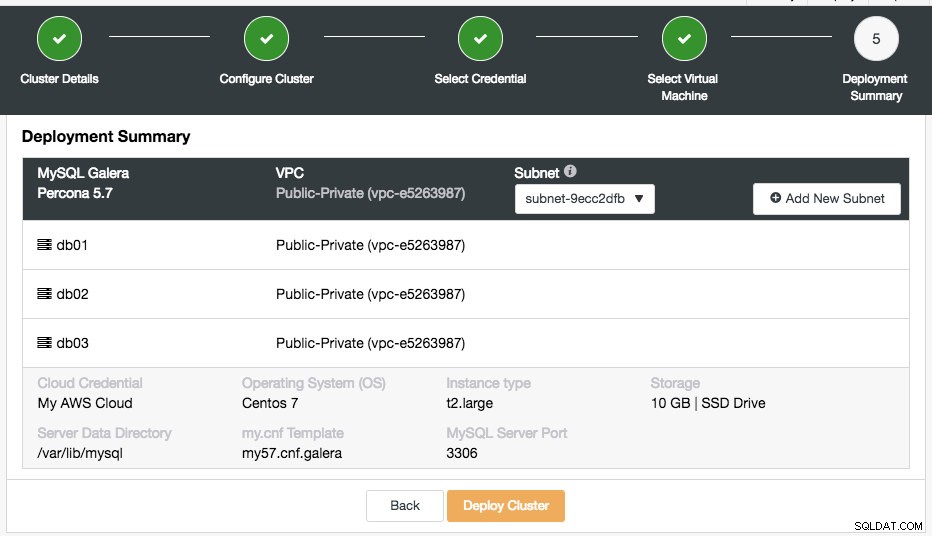
इस चरण में, आपको चुने हुए वर्चुअल नेटवर्क के तहत कौन सा सबनेट चुनना होगा, जिस पर आप डेटाबेस को चलाना चाहते हैं। ध्यान दें कि चुने गए सबनेट में सार्वजनिक IPv4 पता ऑटो-असाइन होना चाहिए। आप "नया सबनेट जोड़ें" बटन पर क्लिक करके इस वीपीसी के तहत एक नया सबनेट भी बना सकते हैं। सत्यापित करें कि क्या सब कुछ सही है और परिनियोजन प्रारंभ करने के लिए "क्लस्टर परिनियोजित करें" बटन दबाएं।
फिर आप गतिविधि पर क्लिक करके प्रगति की निगरानी कर सकते हैं -> नौकरियां -> क्लस्टर बनाएं -> पूर्ण नौकरी विवरण:
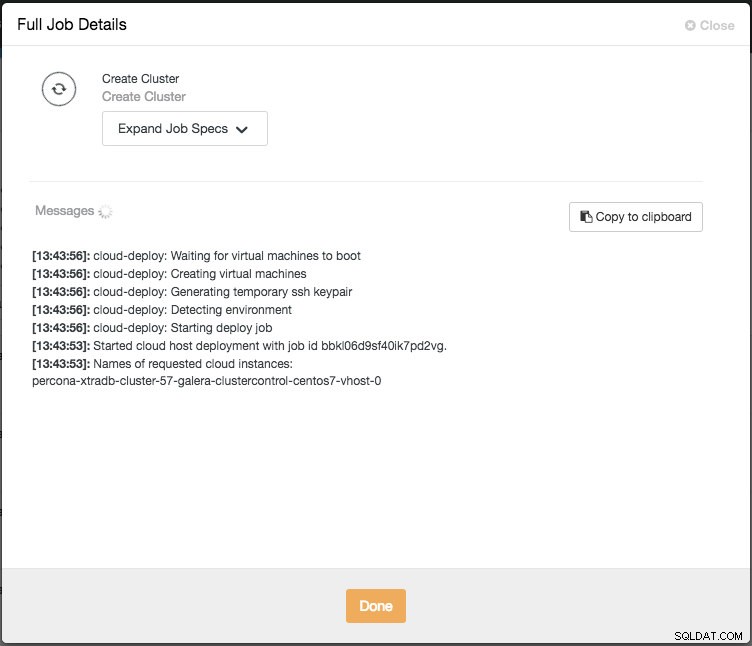
कनेक्शन के आधार पर, इसे पूरा होने में 10 से 20 मिनट लग सकते हैं। एक बार हो जाने के बाद, आपको ClusterControl डैशबोर्ड के अंतर्गत सूचीबद्ध एक नया डेटाबेस क्लस्टर दिखाई देगा। PostgreSQL स्ट्रीमिंग प्रतिकृति क्लस्टर के लिए, परिनियोजन पूर्ण होने के बाद आपको मास्टर और स्लेव IP पते जानने की आवश्यकता हो सकती है। बस नोड्स टैब पर जाएं और आपको बाईं ओर नोड सूची में सार्वजनिक और निजी आईपी पते दिखाई देंगे:
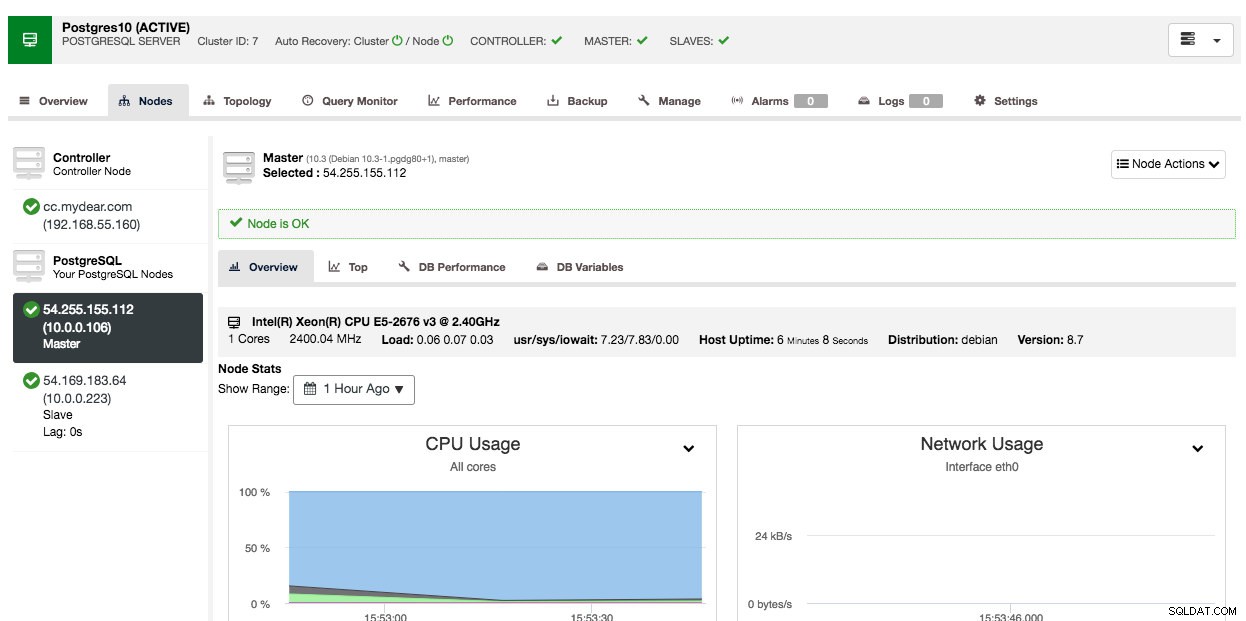
आपका डेटाबेस क्लस्टर अब एडब्ल्यूएस पर परिनियोजित और चल रहा है।
फिलहाल, स्केलिंग अप मानक होस्ट के समान काम करता है, जहां आपको पहले से मैन्युअल रूप से क्लाउड इंस्टेंस बनाने और क्लस्टर कंट्रोल के तहत होस्ट निर्दिष्ट करने की आवश्यकता होती है -> क्लस्टर चुनें -> नोड जोड़ें।
हुड के तहत, परिनियोजन प्रक्रिया निम्न कार्य करती है:
- क्लाउड इंस्टेंस बनाएं
- सुरक्षा समूह और नेटवर्किंग कॉन्फ़िगर करें
- ClusterControl से सभी बनाए गए उदाहरणों के लिए SSH कनेक्टिविटी सत्यापित करें
- हर उदाहरण पर डेटाबेस परिनियोजित करें
- क्लस्टरिंग या प्रतिकृति लिंक कॉन्फ़िगर करें
- ClusterControl में परिनियोजन पंजीकृत करें
बता दें कि यह फीचर अभी बीटा में है। फिर भी, आप एक ही उपयोगकर्ता इंटरफ़ेस से विभिन्न क्लाउड प्रदाताओं में डेटाबेस क्लस्टर को नियंत्रित और प्रबंधित करके अपने विकास और परीक्षण परिवेश को गति देने के लिए इस सुविधा का उपयोग कर सकते हैं।
क्लाउड पर डेटाबेस बैकअप
यह सुविधा ClusterControl 1.5.0 के बाद से मौजूद है, और अब हमने Azure Cloud Storage के लिए समर्थन जोड़ा है। इसका मतलब है कि अब आप सभी तीन प्रमुख क्लाउड प्रदाताओं (AWS, GCP और Azure) पर बनाए गए बैकअप को अपलोड और डाउनलोड कर सकते हैं। बैकअप सफलतापूर्वक बनने के बाद अपलोड प्रक्रिया ठीक होती है (यदि आप "क्लाउड पर बैकअप अपलोड करें" टॉगल करते हैं) या आप बैकअप सूची के क्लाउड आइकन बटन पर मैन्युअल रूप से क्लिक कर सकते हैं:
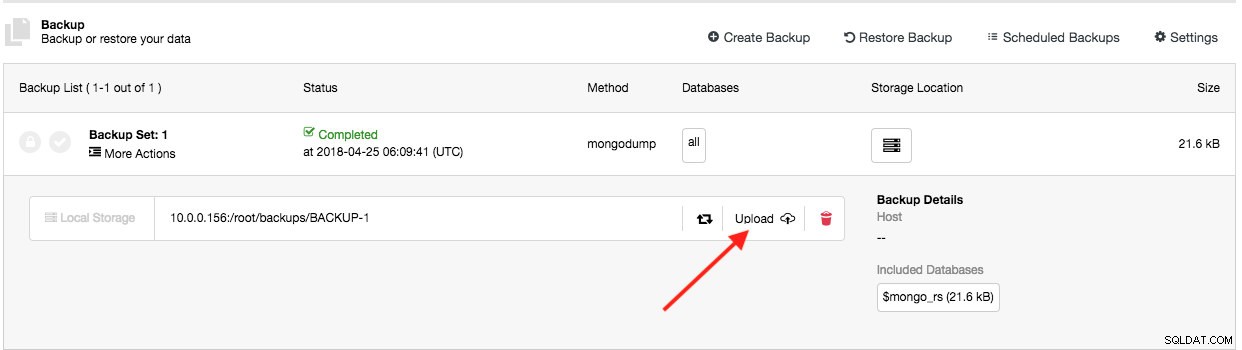
यदि आपने अपना स्थानीय बैकअप संग्रहण खो दिया है, या यदि आपको अपने बैकअप के लिए स्थानीय डिस्क स्थान उपयोग को कम करने की आवश्यकता है, तो आप क्लाउड से बैकअप डाउनलोड और पुनर्स्थापित कर सकते हैं।
वर्तमान सीमाएं
क्लाउड परिनियोजन सुविधा के लिए कुछ ज्ञात सीमाएँ हैं, जैसा कि नीचे बताया गया है:
- वर्तमान में क्लाउड इंस्टेंस के लिए कोई 'अकाउंटिंग' नहीं है। यदि आप डेटाबेस क्लस्टर को हटाते हैं, तो आपको क्लाउड इंस्टेंस को मैन्युअल रूप से निकालना होगा।
- आप क्लाउड इंस्टेंस के साथ नोड को स्वचालित रूप से जोड़ या हटा नहीं सकते हैं।
- आप क्लाउड इंस्टेंस के साथ लोड बैलेंसर को स्वचालित रूप से तैनात नहीं कर सकते।
हमने कई वातावरणों और सेटअपों में इस सुविधा का बड़े पैमाने पर परीक्षण किया है लेकिन हमेशा ऐसे कोने होते हैं जिनसे हम चूक जाते हैं। अधिक जानकारी के लिए, कृपया परिवर्तन लॉग पर एक नज़र डालें।
क्लाउड में हैप्पी क्लस्टरिंग!



