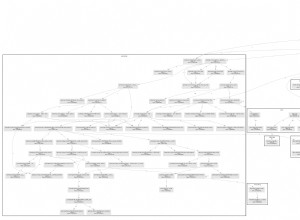
यह एकत्रीकरण वांछित परिणाम देता है।
db.posts.aggregate( [
{ $match: { updatedAt: { $gte: 1549786260000 } } },
{ $facet: {
FALSE: [
{ $match: { toggle: false } },
{ $unwind : "$interests" },
{ $group : { _id : { iid: "$interests", pid: "$publisher" }, count: { $sum : 1 } } },
],
TRUE: [
{ $match: { toggle: true, status: "INACTIVE" } },
{ $unwind : "$interests" },
{ $group : { _id : { iid: "$interests", pid: "$publisher" }, count: { $sum : -1 } } },
]
} },
{ $project: { result: { $concatArrays: [ "$FALSE", "$TRUE" ] } } },
{ $unwind: "$result" },
{ $replaceRoot: { newRoot: "$result" } },
{ $group : { _id : "$_id", count: { $sum : "$count" } } },
{ $project:{ _id: 0, iid: "$_id.iid", pid: "$_id.pid", count: 1 } }
] )
[जोड़ें संपादित करें]
प्रश्न पोस्ट से इनपुट डेटा का उपयोग कर क्वेरी से आउटपुट:
{ "count" : 1, "iid" : "INT123", "pid" : "P789" }
{ "count" : 1, "iid" : "INT123", "pid" : "P123" }
{ "count" : 0, "iid" : "INT789", "pid" : "P789" }
{ "count" : 1, "iid" : "INT456", "pid" : "P789" }
इस क्वेरी को अलग-अलग दृष्टिकोण (कोड) के साथ एक ही परिणाम मिलता है:
db.posts.aggregate( [
{
$match: { updatedAt: { $gte: 1549786260000 } }
},
{
$unwind : "$interests"
},
{
$group : {
_id : {
iid: "$interests",
pid: "$publisher"
},
count: {
$sum: {
$switch: {
branches: [
{ case: { $eq: [ "$toggle", false ] },
then: 1 },
{ case: { $and: [ { $eq: [ "$toggle", true] }, { $eq: [ "$status", "INACTIVE" ] } ] },
then: -1 }
]
}
}
}
}
},
{
$project:{
_id: 0,
iid: "$_id.iid",
pid: "$_id.pid",
count: 1
}
}
] )
[संपादित करें 3 जोड़ें]
नोट:
पहलू क्वेरी दस्तावेज़ों के एक ही सेट पर दो पहलुओं (TRUE और FALSE) को चलाती है; यह समानांतर में चल रहे दो प्रश्नों की तरह है। लेकिन, वांछित आउटपुट प्राप्त करने के लिए पाइपलाइन के नीचे दस्तावेजों को आकार देने के लिए कोड के कुछ दोहराव के साथ-साथ अतिरिक्त चरण भी हैं।
दूसरी क्वेरी कोड दोहराव से बचाती है, और एकत्रीकरण पाइपलाइन में बहुत कम चरण होते हैं। इससे फर्क पड़ेगा जब प्रदर्शन के संदर्भ में इनपुट डेटासेट में बड़ी संख्या में दस्तावेज़ संसाधित करने के लिए होते हैं। सामान्य तौर पर, कम चरणों का अर्थ है दस्तावेज़ों की कम पुनरावृत्तियों (एक चरण के रूप में उन दस्तावेज़ों को स्कैन करना होता है जो पिछले चरण से आउटपुट होते हैं)।