TL;DR:mongoengine सभी लौटाए गए सरणियों को dicts में बदलने में उम्र बिता रहा है
इसका परीक्षण करने के लिए मैंने DictField . के साथ एक दस्तावेज़ के साथ एक संग्रह बनाया एक बड़े नेस्टेड के साथ dict . दस्तावेज़ मोटे तौर पर आपकी 5-10MB सीमा में है।
फिर हम timeit.timeit का इस्तेमाल कर सकते हैं
pymongo और mongoengine का उपयोग करके पठन में अंतर की पुष्टि करने के लिए।
फिर हम pycallgraph का उपयोग कर सकते हैं और GraphViz यह देखने के लिए कि mongoengine इतना लंबा क्या ले रहा है।
यहाँ पूरा कोड है:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
और आउटपुट साबित करता है कि पाइमोंगो की तुलना में मोंगोइंजिन बहुत धीमी गति से चल रहा है:
pymongo took 0.87s
mongoengine took 25.81118331072267
परिणामी कॉल ग्राफ़ बहुत स्पष्ट रूप से दिखाता है कि बॉटल नेक कहाँ है:
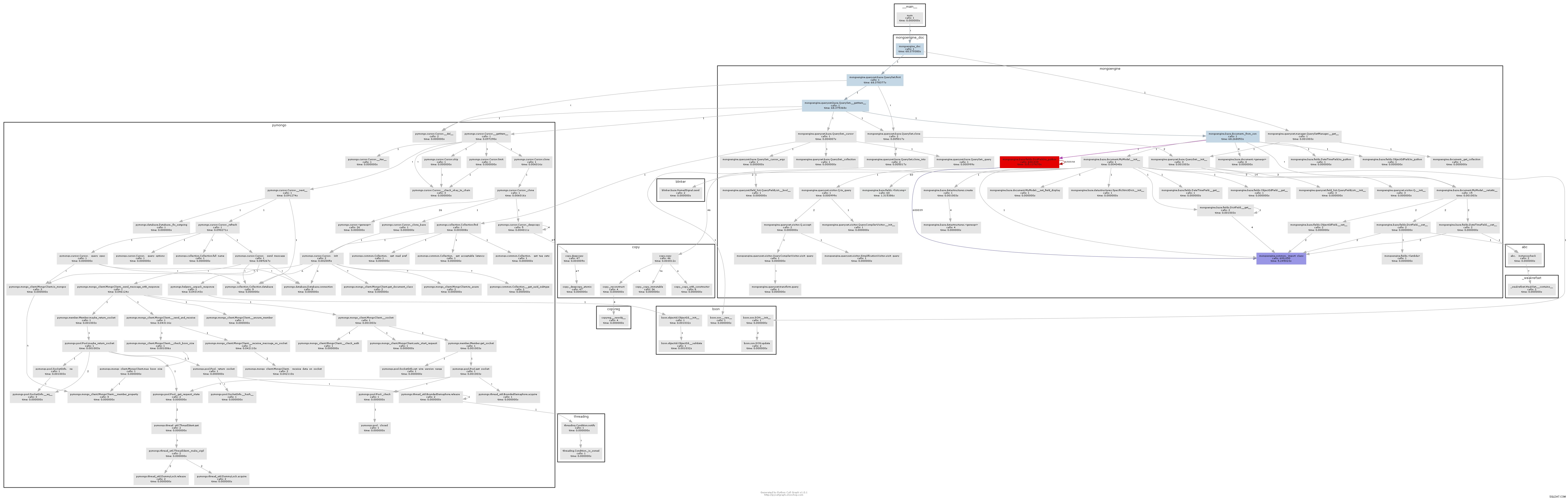
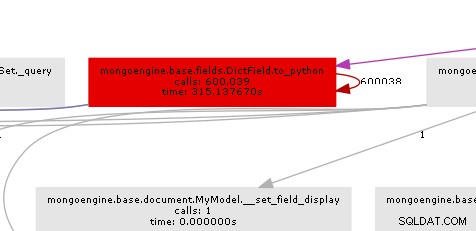
अनिवार्य रूप से mongoengine प्रत्येक DictField . पर to_python विधि को कॉल करेगा कि यह डीबी से वापस हो जाता है। to_python बहुत धीमा है और हमारे उदाहरण में इसे कई बार पागल कहा जा रहा है।
Mongoengine का उपयोग आपके दस्तावेज़ संरचना को अजगर वस्तुओं के लिए सुरुचिपूर्ण ढंग से मैप करने के लिए किया जाता है। यदि आपके पास बहुत बड़े असंरचित दस्तावेज़ हैं (जो mongodb के लिए बहुत अच्छा है) तो mongoengine वास्तव में सही उपकरण नहीं है और आपको केवल pymongo का उपयोग करना चाहिए।
हालांकि, यदि आप संरचना को जानते हैं तो आप EmbeddedDocument . का उपयोग कर सकते हैं mongoengine से थोड़ा बेहतर प्रदर्शन प्राप्त करने के लिए फ़ील्ड। मैंने एक समान लेकिन समकक्ष परीक्षण नहीं चलाया है इस सार में कोड
और आउटपुट है:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
तो आप मोंगोइंजिन को तेज बना सकते हैं लेकिन पाइमोंगो अभी भी बहुत तेज है।
अपडेट करें
यहाँ पाइमोंगो इंटरफ़ेस का एक अच्छा शॉर्टकट एग्रीगेशन फ्रेमवर्क का उपयोग करना है:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]



