डेटाबेस लोड बैलेंसिंग किसी एक सर्वर पर लोड की मात्रा को कम करने के लिए कई डेटाबेस सर्वरों को समवर्ती क्लाइंट अनुरोधों को वितरित करता है। यह आपके डेटाबेस के प्रदर्शन में काफी सुधार कर सकता है। सौभाग्य से, MongoDB डिफ़ॉल्ट रूप से एक ही डेटा को एक साथ पढ़ने और लिखने के लिए कई क्लाइंट के अनुरोधों को संभाल सकता है। यह हर समय डेटा स्थिरता सुनिश्चित करने के लिए कुछ समवर्ती नियंत्रण तंत्र और लॉकिंग प्रोटोकॉल का उपयोग करता है।
इस तरह, MongoDB यह भी सुनिश्चित करता है कि सभी क्लाइंट किसी भी समय डेटा का एक समान दृश्य प्राप्त करें। एकाधिक क्लाइंट से अनुरोधों को संभालने की इस अंतर्निहित सुविधा के कारण, आपको अपने MongoDB सर्वर के शीर्ष पर एक बाहरी लोड बैलेंसर जोड़ने के बारे में चिंता करने की आवश्यकता नहीं है। हालांकि, यदि आप अभी भी लोड संतुलन का उपयोग करके अपने डेटाबेस के प्रदर्शन में सुधार करना चाहते हैं, तो इसे प्राप्त करने के कुछ तरीके यहां दिए गए हैं।
MongoDB वर्टिकल स्केलिंग
सरल शब्दों में, लंबवत स्केलिंग का अर्थ है लोड करने के लिए संभालने के लिए आपके सर्वर में अधिक संसाधन जोड़ना। सभी डेटाबेस सिस्टम की तरह, MongoDB अधिक RAM और IO क्षमता को प्राथमिकता देता है। यह कई सर्वरों पर लोड फैलाए बिना MongoDB प्रदर्शन को बढ़ावा देने का सबसे सरल तरीका है। MongoDB डेटाबेस के वर्टिकल स्केलिंग में आमतौर पर CPU क्षमता या डिस्क क्षमता बढ़ाना और थ्रूपुट (I/O संचालन) बढ़ाना शामिल है। अधिक संसाधन जोड़कर, आपका मोंगो सर्वर कई क्लाइंट के अनुरोधों को संभालने में अधिक सक्षम हो जाता है। इस प्रकार, आपके डेटाबेस के लिए बेहतर लोड संतुलन।
इस दृष्टिकोण का उपयोग करने का नकारात्मक पक्ष किसी एकल प्रणाली में संसाधन जोड़ने की तकनीकी सीमा है। साथ ही, सभी क्लाउड प्रदाताओं के पास नए हार्डवेयर कॉन्फ़िगरेशन जोड़ने की सीमाएं हैं। इस दृष्टिकोण का अन्य नुकसान विफलता का एकल बिंदु है। इस दृष्टिकोण में, आपका सारा डेटा एक ही सिस्टम में संग्रहीत किया जा रहा है, जिससे आपके डेटा का स्थायी नुकसान हो सकता है।
MongoDB क्षैतिज स्केलिंग
क्षैतिज स्केलिंग आपके डेटाबेस को विखंडू में विभाजित करने और उन्हें कई सर्वरों पर संग्रहीत करने के लिए संदर्भित करता है। इस दृष्टिकोण का मुख्य लाभ यह है कि आप शून्य डाउनटाइम के साथ अपने डेटाबेस के प्रदर्शन को बढ़ाने के लिए अतिरिक्त सर्वर जोड़ सकते हैं। MongoDB शार्किंग के माध्यम से क्षैतिज स्केलिंग प्रदान करता है। MongoDB शार्डिंग कई सर्वरों (शार्ड्स) में राइट लोड वितरित करने की अतिरिक्त क्षमता देता है। यहां, प्रत्येक शार्क को एक स्वतंत्र डेटाबेस के रूप में देखा जा सकता है और सभी शार्क के संग्रह को एक बड़े तार्किक डेटाबेस के रूप में देखा जा सकता है। साझाकरण आपके MongoDB को समवर्ती क्लाइंट अनुरोधों को कुशलतापूर्वक संभालने के लिए कई सर्वरों में डेटा वितरित करने में सक्षम बनाता है। इसलिए, यह आपके डेटाबेस के पढ़ने और लिखने के थ्रूपुट को बढ़ाता है।
मोंगोडीबी शेयरिंग
एक शार्ड एक मोंगोड इंस्टेंस या एक प्रतिकृति सेट हो सकता है जो मोंगो शार्डेड डेटाबेस का सबसेट रखता है। आप डेटा और अतिरेक की उच्च उपलब्धता सुनिश्चित करने के लिए शार्प को प्रतिकृति सेट में बदल सकते हैं।
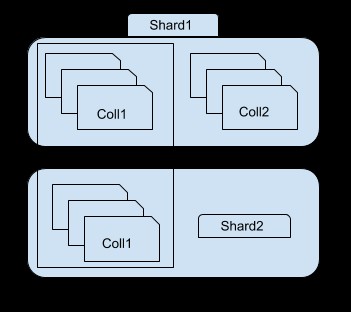
जैसा कि आप ऊपर की छवि में देख सकते हैं, shard 1 में निम्न का एक सबसेट है। संग्रह 1 और संपूर्ण संग्रह 2, जबकि शार्प 2 में संग्रह 1 का केवल अन्य उपसमुच्चय होता है। आप मोंगोस इंस्टेंस का उपयोग करके प्रत्येक शार्ड तक पहुंच सकते हैं। उदाहरण के लिए, यदि आप shard1 इंस्टेंस से कनेक्ट होते हैं, तो आप केवल संग्रह1 के सबसेट को देख/पहुंच सकेंगे।
मोंगोस
Mongos एक क्वेरी राउटर है जो क्लाइंट एप्लिकेशन के लिए शार्प किए गए क्लस्टर तक पहुंच प्रदान करता है। बेहतर लोड संतुलन के लिए आपके पास कई मोंगो उदाहरण हो सकते हैं। उदाहरण के लिए, आपके प्रोडक्शन क्लस्टर में, आपके पास प्रत्येक एप्लिकेशन सर्वर के लिए एक मोंगोस इंस्टेंस हो सकता है। अब यहां आप एक बाहरी लोड बैलेंसर का उपयोग कर सकते हैं, जो आपके एप्लिकेशन सर्वर के अनुरोध को उपयुक्त मोंगोस इंस्टेंस पर पुनर्निर्देशित करेगा। अपने उत्पादन सर्वर में इस तरह के कॉन्फ़िगरेशन जोड़ते समय, सुनिश्चित करें कि किसी भी क्लाइंट से कनेक्शन हमेशा एक ही मोंगोस इंस्टेंस से कनेक्ट होता है क्योंकि कुछ मोंगो संसाधन जैसे कर्सर मोंगोस इंस्टेंस के लिए विशिष्ट होते हैं।
कॉन्फ़िगर सर्वर
कॉन्फ़िगरेशन सर्वर आपके क्लस्टर के बारे में कॉन्फ़िगरेशन सेटिंग्स और मेटाडेटा संग्रहीत करते हैं। MongoDB संस्करण 3.4 से, आपको कॉन्फ़िगरेशन सर्वर को प्रतिकृति सेट के रूप में तैनात करना होगा। यदि आप उत्पादन परिवेश में शार्डिंग सक्षम कर रहे हैं, तो तीन अलग-अलग कॉन्फ़िगरेशन सर्वरों का उपयोग करना अनिवार्य है, प्रत्येक अलग-अलग मशीनों पर।
अपने रेप्लिका सेट क्लस्टर को शार्प किए गए क्लस्टर में बदलने के लिए आप इस गाइड का अनुसरण कर सकते हैं। शार्प्ड प्रोडक्शन क्लस्टर का नमूना उदाहरण यहां दिया गया है:
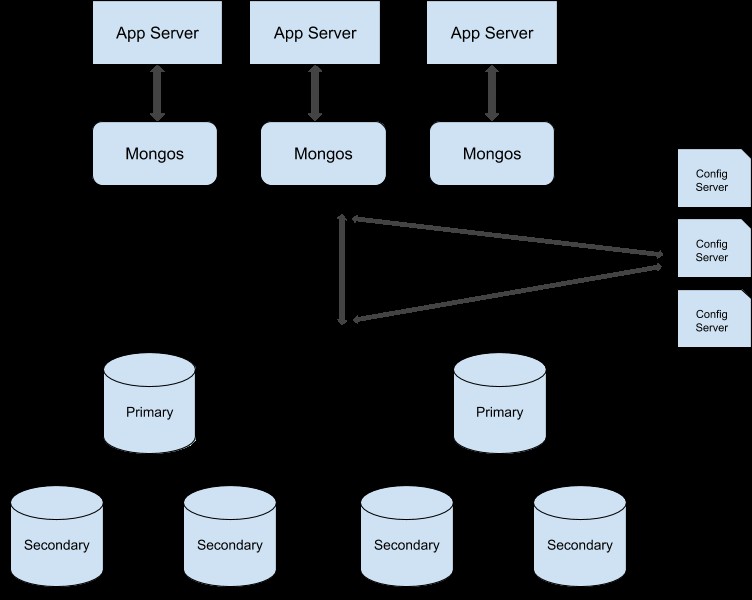
प्रतिकृति का उपयोग करके MongoDB लोड संतुलन
कभी-कभी MongoDB प्रतिकृति का उपयोग क्लाइंट से अधिक ट्रैफ़िक को संभालने और प्राथमिक सर्वर पर लोड को कम करने के लिए किया जा सकता है। ऐसा करने के लिए, आप क्लाइंट को प्राथमिक सर्वर के बजाय सेकेंडरी से पढ़ने का निर्देश दे सकते हैं। यह प्राथमिक सर्वर पर लोड की मात्रा को कम कर सकता है क्योंकि क्लाइंट से आने वाले सभी पठन अनुरोधों को द्वितीयक सर्वर द्वारा नियंत्रित किया जाएगा, और प्राथमिक सर्वर केवल लिखने के अनुरोधों का ध्यान रखेगा।
पठन वरीयता को माध्यमिक पर सेट करने का आदेश निम्नलिखित है:
db.getMongo().setReadPref('secondary')पठन प्रश्नों को संभालने के दौरान आप विशिष्ट सेकेंडरी को लक्षित करने के लिए कुछ टैग भी निर्दिष्ट कर सकते हैं।
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])यहां, MongoDB APAC के रूप में डेटासेंटर टैग मान के साथ द्वितीयक नोड को खोजने का प्रयास करेगा। यदि पाया जाता है, तो मोंगो टैग डेटासेंटर:"एपीएसी" के साथ सभी सेकेंडरी से पढ़ने के अनुरोधों की सेवा करेगा। यदि नहीं मिला, तो मोंगो टैग क्षेत्र के साथ सेकेंडरी खोजने की कोशिश करेगा:"पूर्व"। अगर फिर भी कोई सेकेंडरी नहीं मिला, तो {} डिफ़ॉल्ट केस के रूप में काम करेगा, और मोंगो किसी भी योग्य सेकेंडरी के अनुरोधों को पूरा करेगा।
हालांकि, लोड संतुलन के लिए इस दृष्टिकोण को पढ़ने के थ्रूपुट को बढ़ाने के लिए उपयोग करने की सलाह नहीं दी जाती है। क्योंकि प्राइमरी के अलावा कोई भी रीड प्रेफरेंस मोड प्राइमरी सर्वर पर हाल ही में राइट अपडेट के मामले में पुराना डेटा लौटा सकता है। आमतौर पर, प्राथमिक सर्वर को लिखने के अनुरोधों को संभालने में कुछ समय लगता है और द्वितीयक सर्वर में परिवर्तनों का प्रचार करता है। इस समय के दौरान, यदि कोई उसी डेटा पर रीड ऑपरेशन का अनुरोध करता है, तो सेकेंडरी सर्वर पुराने डेटा को वापस कर देगा क्योंकि यह प्राथमिक सर्वर के साथ सिंक में नहीं है। आप इस दृष्टिकोण का उपयोग कर सकते हैं यदि आपका एप्लिकेशन लिखने के संचालन की तुलना में भारी पढ़ा जाता है।
निष्कर्ष
चूंकि MongoDB समवर्ती अनुरोधों को स्वयं संभाल सकता है, इसलिए आपके MongoDB क्लस्टर में लोड बैलेंसर जोड़ने की कोई आवश्यकता नहीं है। क्लाइंट अनुरोधों को संतुलित करने के लिए, आप या तो लंबवत स्केलिंग या क्षैतिज स्केलिंग चुन सकते हैं क्योंकि आपके पढ़ने और लिखने के संचालन को स्केल करने के लिए सेकेंडरी का उपयोग करना उचित नहीं है। जैसा कि ऊपर चर्चा की गई है, लंबवत स्केलिंग तकनीकी सीमाओं को प्रभावित कर सकती है। इसलिए, यह छोटे पैमाने के अनुप्रयोगों के लिए उपयुक्त है। बड़े अनुप्रयोगों के लिए, शार्डिंग के माध्यम से क्षैतिज स्केलिंग, पढ़ने और लिखने के संचालन को संतुलित करने के लिए सबसे अच्छा तरीका है।



