एक डेटाबेस की दक्षता न केवल सबसे महत्वपूर्ण मापदंडों को ठीक करने पर निर्भर करती है, बल्कि संबंधित संग्रह में उपयुक्त डेटा प्रस्तुति के लिए भी आगे जाती है। हाल ही में, मैंने एक प्रोजेक्ट पर काम किया जिसने एक सोशल चैट एप्लिकेशन विकसित किया, और कुछ दिनों के परीक्षण के बाद, हमने डेटाबेस से डेटा प्राप्त करते समय कुछ अंतराल देखा। हमारे पास इतने सारे उपयोगकर्ता नहीं थे, इसलिए हमने मूल कारणों तक पहुंचने के लिए डेटाबेस पैरामीटर ट्यूनिंग और हमारे प्रश्नों पर ध्यान केंद्रित करने से इंकार कर दिया।
हमारे आश्चर्य के लिए, हमने महसूस किया कि हमारी डेटा संरचना पूरी तरह से उपयुक्त नहीं थी क्योंकि हमारे पास कुछ विशिष्ट जानकारी प्राप्त करने के लिए 1 से अधिक पढ़ने के अनुरोध थे।
एप्लिकेशन अनुभागों को कैसे रखा जाता है, इसका वैचारिक मॉडल डेटाबेस संग्रह संरचना पर निर्भर करता है। उदाहरण के लिए, यदि आप किसी सामाजिक ऐप में लॉग इन करते हैं, तो डेटाबेस प्रस्तुति से दर्शाए गए एप्लिकेशन डिज़ाइन के अनुसार डेटा को विभिन्न अनुभागों में फीड किया जाता है।
संक्षेप में, एक अच्छी तरह से डिज़ाइन किए गए डेटाबेस के लिए, स्कीमा संरचना और संग्रह संबंध इसकी बेहतर गति और अखंडता की दिशा में महत्वपूर्ण चीजें हैं जैसा कि हम निम्नलिखित अनुभागों में देखेंगे।
हम उन कारकों पर चर्चा करेंगे जिन पर आपको अपना डेटा मॉडलिंग करते समय विचार करना चाहिए।
डेटा मॉडलिंग क्या है
डेटा मॉडलिंग आम तौर पर डेटाबेस में डेटा आइटम का विश्लेषण है और वे उस डेटाबेस के भीतर अन्य ऑब्जेक्ट्स से कैसे संबंधित हैं।
उदाहरण के लिए मोंगोडीबी में, हमारे पास उपयोगकर्ता संग्रह और प्रोफ़ाइल संग्रह हो सकता है। उपयोगकर्ता संग्रह किसी दिए गए एप्लिकेशन के लिए उपयोगकर्ताओं के नाम सूचीबद्ध करता है जबकि प्रोफ़ाइल संग्रह प्रत्येक उपयोगकर्ता के लिए प्रोफ़ाइल सेटिंग्स को कैप्चर करता है।
डेटा मॉडलिंग में, हमें प्रत्येक उपयोगकर्ता को संवाददाता प्रोफ़ाइल से जोड़ने के लिए एक संबंध तैयार करने की आवश्यकता होती है। संक्षेप में, डेटा मॉडलिंग ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग के लिए आर्किटेक्चर आधार बनाने के अलावा डेटाबेस डिज़ाइन में मौलिक कदम है। यह इस बात का भी सुराग देता है कि विकास की प्रगति के दौरान भौतिक अनुप्रयोग कैसा दिखेगा। एक एप्लिकेशन-डेटाबेस एकीकरण आर्किटेक्चर को नीचे के रूप में चित्रित किया जा सकता है।
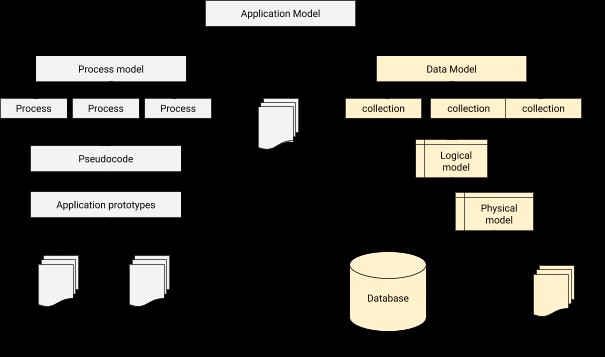
MongoDB में डेटा मॉडलिंग की प्रक्रिया
डेटा मॉडलिंग बेहतर डेटाबेस प्रदर्शन के साथ आता है, लेकिन कुछ बातों की कीमत पर इसमें शामिल हैं:
- डेटा पुनर्प्राप्ति पैटर्न
- आवेदन की आवश्यकताओं को संतुलित करना जैसे:प्रश्न, अपडेट और डेटा प्रोसेसिंग
- चुने गए डेटाबेस इंजन की प्रदर्शन विशेषताएं
- डेटा की अंतर्निहित संरचना ही
MongoDB दस्तावेज़ संरचना
MongoDB में दस्तावेज़ डेटा के दिए गए सेट के लिए किस तकनीक को लागू करने के निर्णय लेने में एक प्रमुख भूमिका निभाते हैं। डेटा के बीच आम तौर पर दो संबंध होते हैं, जो इस प्रकार हैं:
- एम्बेडेड डेटा
- संदर्भ डेटा
एम्बेडेड डेटा
इस मामले में, संबंधित डेटा को एक दस्तावेज़ के भीतर या तो फ़ील्ड मान या दस्तावेज़ के भीतर एक सरणी के रूप में संग्रहीत किया जाता है। इस दृष्टिकोण का मुख्य लाभ यह है कि डेटा को असामान्य किया जाता है और इसलिए एकल डेटाबेस ऑपरेशन में संबंधित डेटा में हेरफेर करने का अवसर प्रदान करता है। नतीजतन, यह उस दर में सुधार करता है जिस पर सीआरयूडी संचालन किया जाता है, इसलिए कम प्रश्नों की आवश्यकता होती है। आइए नीचे एक दस्तावेज़ के उदाहरण पर विचार करें:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}डेटा के इस सेट में, हमारे पास एक छात्र है जिसका नाम और कुछ अन्य अतिरिक्त जानकारी है। सेटिंग फ़ील्ड को किसी ऑब्जेक्ट के साथ एम्बेड किया गया है और आगे स्थान स्थान फ़ील्ड को अक्षांश और देशांतर कॉन्फ़िगरेशन वाले ऑब्जेक्ट के साथ भी एम्बेड किया गया है। इस छात्र का सारा डेटा एक ही दस्तावेज़ में समाहित किया गया है। अगर हमें इस छात्र के लिए सभी जानकारी प्राप्त करने की आवश्यकता है तो हम इसे चलाते हैं:
db.students.findOne({StudentName : "George Beckonn"})एम्बेडिंग की ताकत
- बढ़ी हुई डेटा पहुंच गति:डेटा तक पहुंच की बेहतर दर के लिए, एम्बेड करना सबसे अच्छा विकल्प है क्योंकि एक एकल क्वेरी ऑपरेशन केवल एक डेटाबेस लुक-अप के साथ निर्दिष्ट दस्तावेज़ के भीतर डेटा में हेरफेर कर सकता है।
- कम डेटा असंगति:संचालन के दौरान, यदि कुछ गलत हो जाता है (उदाहरण के लिए नेटवर्क डिस्कनेक्ट या बिजली की विफलता) तो केवल कुछ ही दस्तावेज़ प्रभावित हो सकते हैं क्योंकि मानदंड अक्सर एक दस्तावेज़ का चयन करते हैं।
- सीआरयूडी संचालन में कमी। कहने का तात्पर्य यह है कि, पठन संचालन वास्तव में लिखने से अधिक होगा। इसके अलावा, एकल परमाणु लेखन ऑपरेशन में संबंधित डेटा को अपडेट करना संभव है। यानी उपरोक्त डेटा के लिए, हम फोन नंबर को अपडेट कर सकते हैं और इस एकल ऑपरेशन के साथ दूरी भी बढ़ा सकते हैं:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
एम्बेडिंग की कमजोरियां
- प्रतिबंधित दस्तावेज़ आकार। MongoDB में सभी दस्तावेज़ 16 मेगाबाइट के BSON आकार तक सीमित हैं। इसलिए, एम्बेडेड डेटा के साथ समग्र दस्तावेज़ आकार इस सीमा को पार नहीं करना चाहिए। अन्यथा, कुछ स्टोरेज इंजन जैसे MMAPv1 के लिए, डेटा बढ़ सकता है और खराब लेखन प्रदर्शन के परिणामस्वरूप डेटा विखंडन हो सकता है।
- डेटा डुप्लीकेशन:एक ही डेटा की कई कॉपी कॉपी किए गए डेटा को क्वेरी करना कठिन बना देती हैं और एम्बेड किए गए दस्तावेज़ों को फ़िल्टर करने में अधिक समय लग सकता है, इसलिए एम्बेडिंग के मुख्य लाभ से आगे निकल जाते हैं।
डॉट नोटेशन
डॉट नोटेशन प्रोग्रामिंग भाग में एम्बेडेड डेटा की पहचान करने वाली विशेषता है। इसका उपयोग एम्बेडेड फ़ील्ड या सरणी के तत्वों तक पहुंचने के लिए किया जाता है। उपरोक्त नमूना डेटा में, हम उस छात्र की जानकारी वापस कर सकते हैं जिसका स्थान "दूतावास" है, इस क्वेरी के साथ डॉट नोटेशन का उपयोग कर सकते हैं।
db.users.find({'Settings.location': 'Embassy'})संदर्भ डेटा
इस मामले में डेटा संबंध संबंधित डेटा अलग-अलग दस्तावेज़ों में संग्रहीत है, लेकिन इन संबंधित दस्तावेज़ों के लिए कुछ संदर्भ लिंक जारी किए जाते हैं। उपरोक्त नमूना डेटा के लिए हम इसे इस तरह से फिर से बना सकते हैं कि:
उपयोगकर्ता दस्तावेज़
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}सेटिंग दस्तावेज़
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}2 अलग-अलग दस्तावेज़ हैं, लेकिन वे _id और id फ़ील्ड के लिए समान मान से जुड़े हुए हैं। डेटा मॉडल इस प्रकार सामान्यीकृत है। हालांकि, हमारे लिए संबंधित दस्तावेज़ से जानकारी तक पहुंचने के लिए हमें अतिरिक्त प्रश्न जारी करने की आवश्यकता है और इसके परिणामस्वरूप निष्पादन समय में वृद्धि हुई है। उदाहरण के लिए, यदि हम पेरेंटफोन और संबंधित दूरी सेटिंग्स को अपडेट करना चाहते हैं तो हमारे पास कम से कम 3 प्रश्न होंगे अर्थात
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})संदर्भ की ताकत
- डेटा संगति। प्रत्येक दस्तावेज़ के लिए, एक विहित प्रपत्र बनाए रखा जाता है इसलिए डेटा असंगति की संभावना बहुत कम होती है।
- डेटा अखंडता में सुधार। सामान्यीकरण के कारण, ऑपरेशन की अवधि की परवाह किए बिना डेटा को अपडेट करना आसान है और इसलिए बिना किसी भ्रम के हर दस्तावेज़ के लिए सही डेटा सुनिश्चित करें।
- कैश उपयोग में सुधार। अक्सर एक्सेस किए गए कैननिकल दस्तावेज़ों को कैश में संग्रहीत किया जाता है, न कि एम्बेडेड दस्तावेज़ों के लिए जिन्हें कुछ बार एक्सेस किया जाता है।
- कुशल हार्डवेयर उपयोग। एम्बेडिंग के विपरीत, जिसके परिणामस्वरूप दस्तावेज़ में वृद्धि हो सकती है, संदर्भित करने से दस्तावेज़ वृद्धि को बढ़ावा नहीं मिलता है और इस प्रकार डिस्क और रैम का उपयोग कम हो जाता है।
- विशेष रूप से उप-दस्तावेजों के एक बड़े सेट के साथ बेहतर लचीलापन।
- तेज़ लिखते हैं।
संदर्भ की कमजोरियां
- एकाधिक लुकअप:चूंकि हमें मापदंड से मेल खाने वाले कई दस्तावेज़ों को देखना होता है, इसलिए डिस्क से पुनर्प्राप्त करते समय पढ़ने का समय बढ़ जाता है। इसके अलावा, इसका परिणाम कैश मिस हो सकता है।
- कुछ ऑपरेशन को प्राप्त करने के लिए कई प्रश्न जारी किए जाते हैं इसलिए सामान्यीकृत डेटा मॉडल को एक विशिष्ट ऑपरेशन को पूरा करने के लिए सर्वर पर अधिक राउंड ट्रिप की आवश्यकता होती है।
डेटा सामान्यीकरण
डेटा सामान्यीकरण, डेटा अखंडता में सुधार और डेटा अतिरेक की घटनाओं को कम करने के लिए कुछ सामान्य रूपों के अनुसार एक डेटाबेस के पुनर्गठन को संदर्भित करता है।
डेटा मॉडलिंग दो प्रमुख सामान्यीकरण तकनीकों के इर्द-गिर्द घूमती है:
-
सामान्यीकृत डेटा मॉडल
जैसा कि संदर्भ डेटा में लागू किया जाता है, सामान्यीकरण डेटा को नए संग्रहों के बीच संदर्भों के साथ कई संग्रहों में विभाजित करता है। अन्य संग्रह के लिए एक एकल दस्तावेज़ अद्यतन जारी किया जाएगा और मिलान दस्तावेज़ के अनुसार लागू किया जाएगा। यह एक कुशल डेटा अपडेट प्रतिनिधित्व प्रदान करता है और आमतौर पर डेटा के लिए उपयोग किया जाता है जो अक्सर बदलता रहता है।
-
असामान्यीकृत डेटा मॉडल
डेटा में एम्बेडेड दस्तावेज़ होते हैं जिससे रीड ऑपरेशंस काफी कुशल हो जाते हैं। हालाँकि, यह अधिक डिस्क स्थान के उपयोग से जुड़ा है और सिंक में रखने में भी कठिनाइयाँ हैं। डीनोर्मलाइज़ेशन अवधारणा को उन उप-दस्तावेज़ों पर अच्छी तरह से लागू किया जा सकता है जिनका डेटा अक्सर नहीं बदलता है।
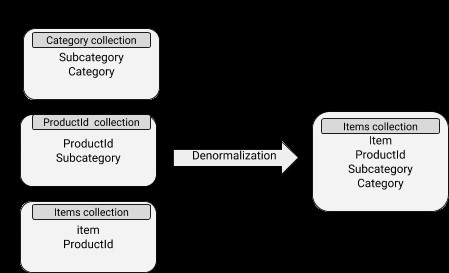
MongoDB स्कीमा
एक स्कीमा मूल रूप से फ़ील्ड का एक उल्लिखित कंकाल है और डेटा प्रकार प्रत्येक फ़ील्ड को डेटा के दिए गए सेट के लिए रखना चाहिए। SQL दृष्टिकोण को ध्यान में रखते हुए, सभी पंक्तियों को समान कॉलम के लिए डिज़ाइन किया गया है और प्रत्येक कॉलम में परिभाषित डेटा प्रकार होना चाहिए। हालांकि, मोंगोडीबी में, हमारे पास डिफ़ॉल्ट रूप से एक लचीली स्कीमा है जो सभी दस्तावेजों के लिए समान अनुरूपता नहीं रखती है।
लचीली स्कीमा
MongoDB में एक लचीली स्कीमा परिभाषित करती है कि दस्तावेज़ों में एक ही फ़ील्ड या डेटा प्रकार होना आवश्यक नहीं है, क्योंकि एक फ़ील्ड संग्रह के भीतर दस्तावेज़ों में भिन्न हो सकती है। इस अवधारणा के साथ मुख्य लाभ यह है कि कोई भी नए फ़ील्ड जोड़ सकता है, मौजूदा को हटा सकता है या फ़ील्ड मानों को एक नए प्रकार में बदल सकता है और इसलिए दस्तावेज़ को एक नई संरचना में अपडेट कर सकता है।
उदाहरण के लिए हमारे पास ये 2 दस्तावेज़ एक ही संग्रह में हो सकते हैं:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}पहले दस्तावेज़ में, हमारे पास आयु फ़ील्ड है जबकि दूसरे दस्तावेज़ में कोई आयु फ़ील्ड नहीं है। इसके अलावा, पेरेंटफ़ोन फ़ील्ड के लिए डेटा प्रकार एक संख्या है जबकि दूसरे दस्तावेज़ में इसे गलत पर सेट किया गया है जो एक बूलियन प्रकार है।
स्कीमा लचीलेपन से किसी ऑब्जेक्ट पर दस्तावेज़ों की मैपिंग की सुविधा मिलती है और प्रत्येक दस्तावेज़ प्रतिनिधित्व वाली इकाई के डेटा फ़ील्ड से मेल खा सकता है।
कठोर स्कीमा
जितना हमने कहा है कि ये दस्तावेज़ एक दूसरे से भिन्न हो सकते हैं, कभी-कभी आप एक कठोर स्कीमा बनाने का निर्णय ले सकते हैं। एक कठोर स्कीमा परिभाषित करेगा कि संग्रह में सभी दस्तावेज़ समान संरचना साझा करेंगे और यह आपको सम्मिलित और अद्यतन संचालन के दौरान डेटा अखंडता में सुधार के तरीके के रूप में कुछ दस्तावेज़ सत्यापन नियमों को सेट करने का एक बेहतर मौका देगा।
स्कीमा डेटा प्रकार
MongoDB के लिए कुछ सर्वर ड्राइवरों का उपयोग करते समय जैसे कि mongoose, कुछ प्रदान किए गए डेटा प्रकार होते हैं जो आपको डेटा सत्यापन करने में सक्षम बनाते हैं। बुनियादी डेटा प्रकार हैं:
- स्ट्रिंग
- संख्या
- बूलियन
- तारीख
- बफर
- ऑब्जेक्ट आईडी
- सरणी
- मिश्रित
- दशमलव128
- मानचित्र
नीचे नमूना स्कीमा पर एक नज़र डालें
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});उदाहरण उपयोग के मामले
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);स्कीमा सत्यापन
जितना अधिक आप एप्लिकेशन पक्ष से डेटा सत्यापन कर सकते हैं, सर्वर के अंत से भी सत्यापन करना हमेशा अच्छा अभ्यास होता है। हम इसे स्कीमा सत्यापन नियमों को लागू करके प्राप्त करते हैं।
ये नियम सम्मिलन और अद्यतन संचालन के दौरान लागू होते हैं। उन्हें सामान्य रूप से निर्माण प्रक्रिया के दौरान संग्रह के आधार पर घोषित किया जाता है। हालाँकि, आप सत्यापनकर्ता विकल्पों के साथ कोलमॉड कमांड का उपयोग करके मौजूदा संग्रह में दस्तावेज़ सत्यापन नियम भी जोड़ सकते हैं लेकिन ये नियम मौजूदा दस्तावेज़ों पर तब तक लागू नहीं होते हैं जब तक कि उन पर कोई अपडेट लागू नहीं हो जाता।
इसी तरह, db.createCollection() कमांड का उपयोग करके एक नया संग्रह बनाते समय आप सत्यापनकर्ता विकल्प जारी कर सकते हैं। विद्यार्थियों के लिए संग्रह बनाते समय इस उदाहरण पर एक नज़र डालें। संस्करण 3.6 से, MongoDB JSON स्कीमा सत्यापन का समर्थन करता है, इसलिए आपको केवल $jsonSchema ऑपरेटर का उपयोग करने की आवश्यकता है।
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})इस स्कीमा डिज़ाइन में, यदि हम एक नया दस्तावेज़ सम्मिलित करने का प्रयास करते हैं जैसे:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})कॉलबैक फ़ंक्शन नीचे दी गई त्रुटि लौटाएगा, क्योंकि कुछ उल्लंघन किए गए सत्यापन नियमों जैसे कि आपूर्ति वर्ष मान निर्दिष्ट सीमा के भीतर नहीं है।
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})इसके अलावा, आप $where, $text, near और $nearSphere, यानी:
को छोड़कर क्वेरी ऑपरेटर का उपयोग करके अपने सत्यापन विकल्प में क्वेरी एक्सप्रेशन जोड़ सकते हैं।db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )स्कीमा सत्यापन स्तर
जैसा कि पहले उल्लेख किया गया है, सामान्य रूप से लेखन कार्यों के लिए सत्यापन जारी किया जाता है।
हालाँकि, सत्यापन पहले से मौजूद दस्तावेज़ों पर भी लागू किया जा सकता है।
सत्यापन के 3 स्तर हैं:
- सख्त:यह डिफ़ॉल्ट MongoDB सत्यापन स्तर है और यह सभी प्रविष्टियों और अद्यतनों के लिए सत्यापन नियम लागू करता है।
- मध्यम:सत्यापन नियम सम्मिलन, अद्यतन और पहले से मौजूद दस्तावेज़ों पर लागू होते हैं जो केवल सत्यापन मानदंड को पूरा करते हैं।
- बंद:यह स्तर किसी दिए गए स्कीमा के लिए सत्यापन नियमों को शून्य पर सेट करता है इसलिए दस्तावेज़ों का कोई सत्यापन नहीं किया जाएगा।
उदाहरण:
आइए नीचे दिए गए डेटा को क्लाइंट संग्रह में डालें।
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]यदि हम निम्न का उपयोग करके मध्यम सत्यापन स्तर लागू करते हैं:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )सत्यापन नियम केवल 1 के _id वाले दस्तावेज़ पर लागू होंगे क्योंकि यह सभी मानदंडों से मेल खाएगा।
दूसरे दस्तावेज़ के लिए, चूंकि सत्यापन नियम जारी किए गए मानदंडों के अनुरूप नहीं हैं, इसलिए दस्तावेज़ को मान्य नहीं किया जाएगा।
स्कीमा सत्यापन कार्रवाइयां
दस्तावेजों पर सत्यापन करने के बाद, कुछ ऐसे हो सकते हैं जो सत्यापन नियमों का उल्लंघन कर सकते हैं। ऐसा होने पर हमेशा कार्रवाई प्रदान करने की आवश्यकता होती है।
MongoDB दो कार्य प्रदान करता है जो सत्यापन नियमों को विफल करने वाले दस्तावेज़ों को जारी किए जा सकते हैं:
- त्रुटि:यह डिफ़ॉल्ट MongoDB क्रिया है, जो सत्यापन मानदंड का उल्लंघन करने की स्थिति में किसी भी प्रविष्टि या अद्यतन को अस्वीकार कर देती है।
-
चेतावनी:यह क्रिया MongoDB लॉग में उल्लंघन को रिकॉर्ड करेगी, लेकिन इन्सर्ट या अपडेट ऑपरेशन को पूरा करने की अनुमति देती है। उदाहरण के लिए:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })अगर हम इस तरह से कोई दस्तावेज़ डालने का प्रयास करते हैं:
db.students.insert( { name: "Amanda", status: "Updated" } );इस तथ्य की परवाह किए बिना कि यह स्कीमा डिज़ाइन में एक आवश्यक फ़ील्ड है, GPA गायब है, लेकिन चूंकि सत्यापन कार्रवाई को चेतावनी के लिए सेट किया गया है, दस्तावेज़ सहेजा जाएगा और MongoDB लॉग में एक त्रुटि संदेश रिकॉर्ड किया जाएगा।



