इस लेख में हम एक वास्तविक . के लिए एक स्क्रैपर बनाने जा रहे हैं फ्रीलांस गिग जहां क्लाइंट चाहता है कि एक पायथन प्रोग्राम नए प्रश्नों (प्रश्न शीर्षक और URL) को हथियाने के लिए स्टैक ओवरफ्लो से डेटा को परिमार्जन करे। तब स्क्रैप किए गए डेटा को MongoDB में संग्रहीत किया जाना चाहिए। यह ध्यान देने योग्य है कि स्टैक ओवरफ्लो में एक एपीआई है, जिसका उपयोग सटीक तक पहुंचने के लिए किया जा सकता है एक ही डेटा। हालांकि, ग्राहक एक खुरचनी चाहता था, इसलिए उसे जो मिला वह एक खुरचनी है।
निःशुल्क बोनस: पूर्ण स्रोत कोड के साथ Python + MongoDB प्रोजेक्ट कंकाल डाउनलोड करने के लिए यहां क्लिक करें जो आपको दिखाता है कि Python से MongoDB तक कैसे पहुंचें।
अपडेट:
- 01/03/2014 - मकड़ी को फिर से तैयार किया। धन्यवाद, @kissgyorgy.
- 02/18/2015 - भाग 2 जोड़ा गया।
- 09/06/2015 - स्क्रेपी और पाइमोंगो के नवीनतम संस्करण में अपडेट किया गया - चीयर्स!
हमेशा की तरह, साइट के उपयोग/सेवा की शर्तों की समीक्षा करना सुनिश्चित करें और robots.txt का सम्मान करें। किसी भी स्क्रैपिंग कार्य को शुरू करने से पहले फाइल करें। कम समय में कई अनुरोधों के साथ साइट पर बाढ़ न लाकर नैतिक स्क्रैपिंग प्रथाओं का पालन करना सुनिश्चित करें। आपके द्वारा स्क्रैप की गई किसी भी साइट के साथ ऐसा व्यवहार करें जैसे कि वह आपकी अपनी हो ।
इंस्टॉलेशन
MongoDB में डेटा संग्रहीत करने के लिए हमें PyMongo (v3.0.3) के साथ स्क्रेपी लाइब्रेरी (v1.0.3) की आवश्यकता है। आपको MongoDB भी इंस्टॉल करना होगा (कवर नहीं)।
स्क्रैपी
यदि आप OSX या Linux का फ्लेवर चला रहे हैं, तो pip के साथ Scrapy इंस्टॉल करें (आपके virtualenv सक्रिय होने के साथ):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
यदि आप विंडोज मशीन पर हैं, तो आपको कई निर्भरताएं मैन्युअल रूप से स्थापित करने की आवश्यकता होगी। विस्तृत निर्देशों के साथ-साथ मेरे द्वारा बनाए गए इस Youtube वीडियो के लिए कृपया आधिकारिक दस्तावेज़ देखें।
एक बार स्क्रेपी सेटअप हो जाने पर, इस कमांड को पायथन शेल में चलाकर अपने इंस्टॉलेशन को सत्यापित करें:
>>>>>> import scrapy
>>>
अगर आपको कोई त्रुटि नहीं मिलती है तो आप जा सकते हैं!
पायमोंगो
इसके बाद, PyMongo को pip के साथ इंस्टॉल करें:
$ pip install pymongo
$ pip freeze > requirements.txt
अब हम क्रॉलर बनाना शुरू कर सकते हैं।
स्क्रैपी प्रोजेक्ट
आइए एक नया स्क्रेपी प्रोजेक्ट शुरू करें:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
यह कई फ़ाइलें और फ़ोल्डर बनाता है जिसमें एक बुनियादी बॉयलरप्लेट शामिल होता है ताकि आप जल्दी से शुरू कर सकें:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
डेटा निर्दिष्ट करें
items.py फ़ाइल का उपयोग उस डेटा के भंडारण "कंटेनर" को परिभाषित करने के लिए किया जाता है जिसे हम स्क्रैप करने की योजना बनाते हैं।
StackItem() Item . से वर्ग इनहेरिट करता है (दस्तावेज़), जिसमें मूल रूप से कई पूर्व-निर्धारित वस्तुएं हैं जिन्हें स्क्रेपी ने हमारे लिए पहले ही बना लिया है:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
आइए कुछ आइटम जोड़ें जिन्हें हम वास्तव में एकत्र करना चाहते हैं। प्रत्येक प्रश्न के लिए क्लाइंट को शीर्षक और URL की आवश्यकता होती है। तो, अपडेट करें items.py इस तरह:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
मकड़ी बनाएं
stack_spider.py called नामक फ़ाइल बनाएं "मकड़ियों" निर्देशिका में। यह वह जगह है जहां जादू होता है - उदाहरण के लिए, जहां हम स्क्रेपी को बताएंगे कि सटीक कैसे खोजा जाए हम जिस डेटा की तलाश कर रहे हैं। जैसा कि आप कल्पना कर सकते हैं, यह विशिष्ट है प्रत्येक व्यक्तिगत वेब पेज पर जिसे आप स्क्रैप करना चाहते हैं।
स्क्रेपी के Spider . से विरासत में मिले वर्ग को परिभाषित करके प्रारंभ करें और फिर आवश्यकतानुसार विशेषताएँ जोड़ना:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
पहले कुछ चर स्व-व्याख्यात्मक हैं (दस्तावेज़):
nameमकड़ी के नाम को परिभाषित करता है।allowed_domainsमकड़ी के क्रॉल करने के लिए अनुमत डोमेन के लिए आधार-यूआरएल शामिल हैं।start_urlsमकड़ी के लिए क्रॉलिंग शुरू करने के लिए URL की एक सूची है। बाद के सभी URL उस डेटा से शुरू होंगे जो स्पाइडरstart_urlsमें URLS से डाउनलोड करता है। ।
XPath चयनकर्ता
इसके बाद, स्क्रेपी एक वेबसाइट से डेटा निकालने के लिए XPath चयनकर्ताओं का उपयोग करता है। दूसरे शब्दों में, हम दिए गए XPath के आधार पर HTML डेटा के कुछ हिस्सों का चयन कर सकते हैं। जैसा कि स्क्रेपी के दस्तावेज़ीकरण में कहा गया है, "XPath XML दस्तावेज़ों में नोड्स का चयन करने के लिए एक भाषा है, जिसका उपयोग HTML के साथ भी किया जा सकता है।"
आप Chrome के डेवलपर टूल का उपयोग करके आसानी से एक विशिष्ट Xpath ढूंढ सकते हैं। बस एक विशिष्ट HTML तत्व का निरीक्षण करें, XPath की प्रतिलिपि बनाएँ, और फिर (आवश्यकतानुसार) ट्वीक करें:
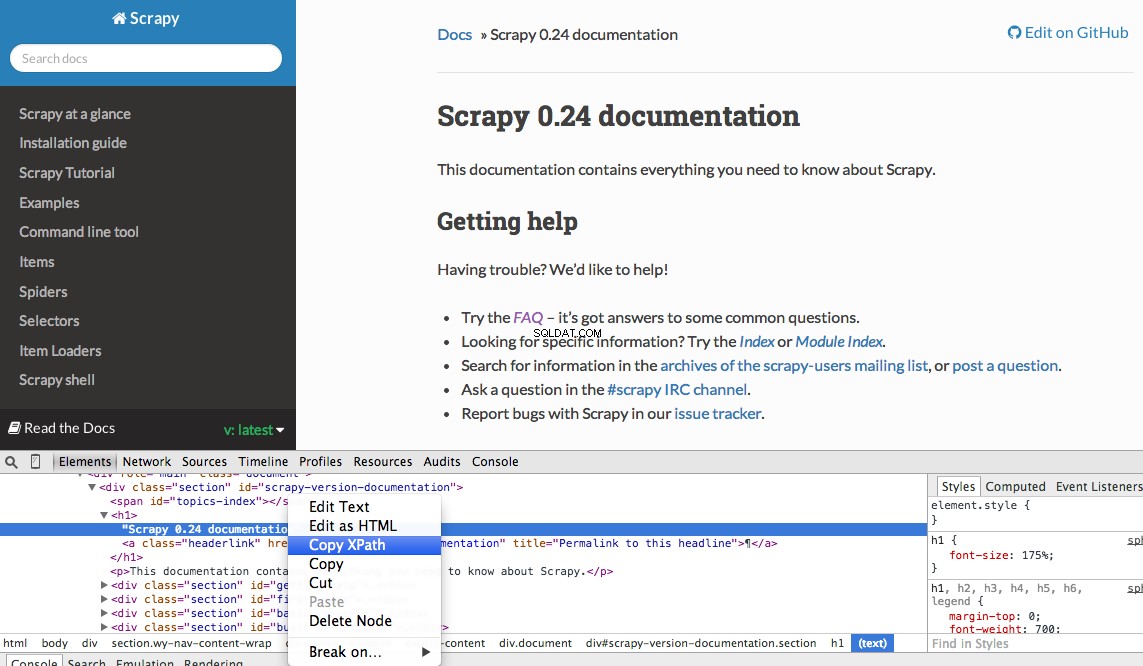
डेवलपर टूल आपको $x . का उपयोग करके JavaScript कंसोल में XPath चयनकर्ताओं का परीक्षण करने की क्षमता भी देता है - यानी, $x("//img") :
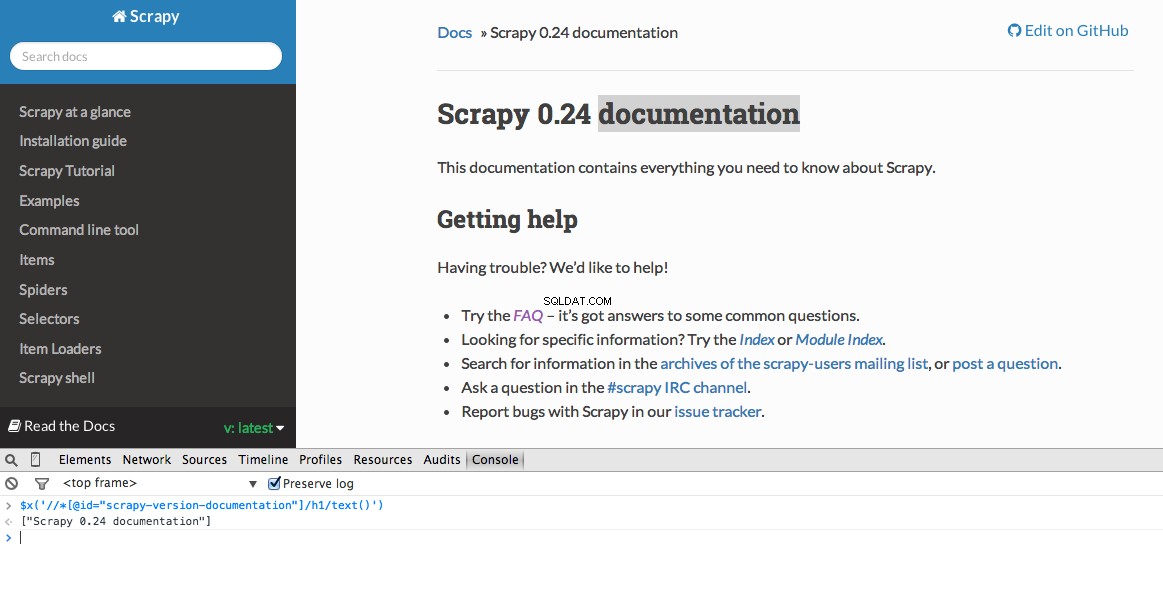
फिर से, हम मूल रूप से स्क्रेपी को बताते हैं कि परिभाषित XPath के आधार पर जानकारी की तलाश कहाँ से शुरू करें। आइए क्रोम में स्टैक ओवरफ्लो साइट पर नेविगेट करें और XPath चयनकर्ता खोजें।
पहले प्रश्न पर राइट क्लिक करें और "इंस्पेक्ट एलिमेंट" चुनें:
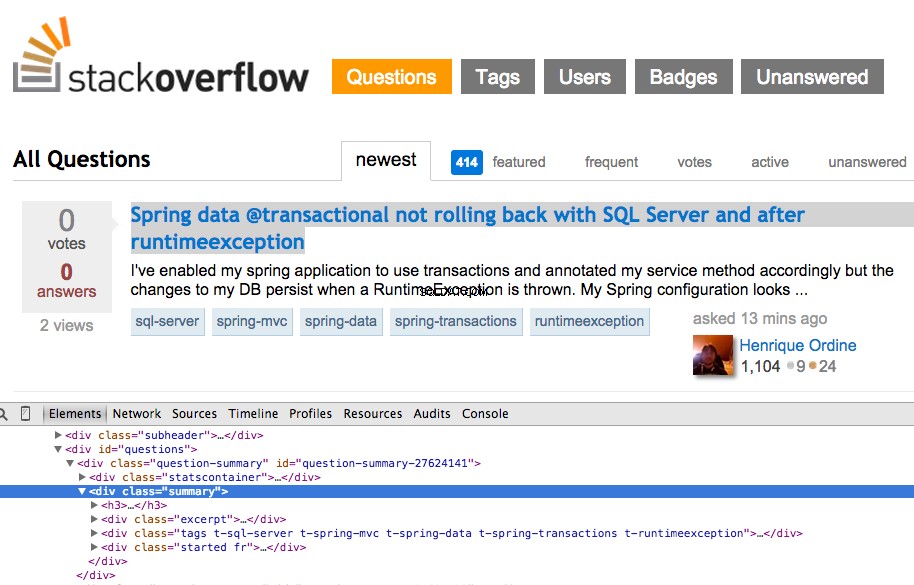
अब <div class="summary"> . के लिए XPath लें , //*[@id="question-summary-27624141"]/div[2] , और फिर JavaScript कंसोल में इसका परीक्षण करें:
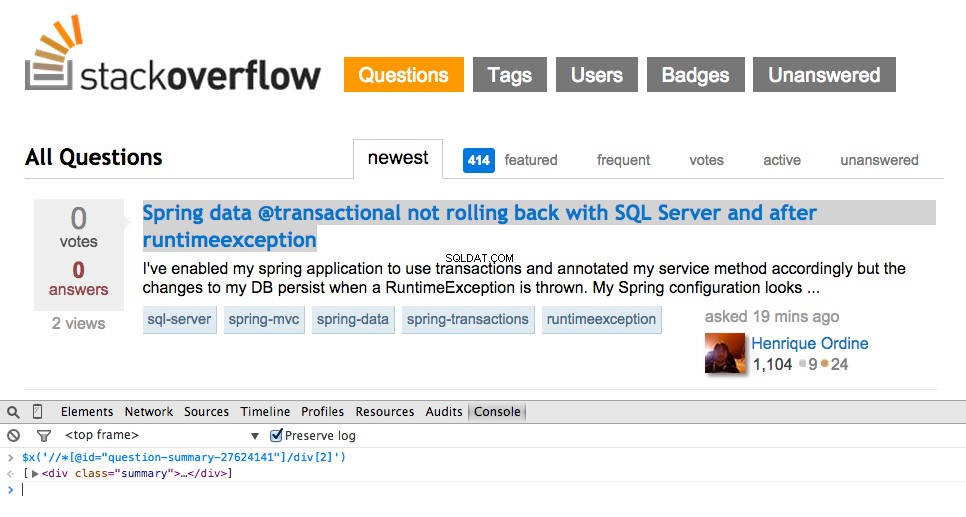
जैसा कि आप बता सकते हैं, यह केवल उस एक . का चयन करता है प्रश्न। इसलिए हमें सभी . को हथियाने के लिए XPath को बदलना होगा प्रशन। कोई विचार? यह आसान है://div[@class="summary"]/h3 . इसका क्या मतलब है? अनिवार्य रूप से, यह XPath कहता है:सभी को पकड़ो <h3> तत्व जो एक <div> . के बच्चे हैं जिसका एक वर्ग है summary . JavaScript कंसोल में इस XPath का परीक्षण करें।
ध्यान दें कि हम कैसे क्रोम डेवलपर टूल्स से वास्तविक XPath आउटपुट का उपयोग नहीं कर रहे हैं। ज्यादातर मामलों में, आउटपुट सिर्फ एक तरफ सहायक होता है, जो आम तौर पर आपको काम कर रहे XPath को खोजने के लिए सही दिशा में इंगित करता है।
आइए अब stack_spider.py को अपडेट करें स्क्रिप्ट:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
डेटा निकालें
हमें अभी भी अपने इच्छित डेटा को पार्स और स्क्रैप करने की आवश्यकता है, जो <div class="summary"><h3> के अंतर्गत आता है . फिर से, stack_spider.py को अपडेट करें इस तरह:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
स्क्रेपी स्टैक ट्रेस के साथ, आपको 50 प्रश्न शीर्षक और URL आउटपुट दिखाई देने चाहिए। आप इस छोटे से आदेश के साथ एक JSON फ़ाइल में आउटपुट प्रस्तुत कर सकते हैं:
$ scrapy crawl stack -o items.json -t json
हमने अब अपने स्पाइडर को अपने डेटा के आधार पर लागू किया है जिसे हम मांग रहे हैं। अब हमें स्क्रैप किए गए डेटा को MongoDB में संग्रहीत करने की आवश्यकता है।
डेटा को MongoDB में स्टोर करें
हर बार जब कोई आइटम लौटाया जाता है, तो हम डेटा को मान्य करना चाहते हैं और फिर इसे एक मोंगो संग्रह में जोड़ना चाहते हैं।
प्रारंभिक चरण डेटाबेस बनाना है जिसे हम अपने सभी क्रॉल किए गए डेटा को सहेजने के लिए उपयोग करने की योजना बना रहे हैं। सेटिंग्स.pyखोलें और पाइपलाइन निर्दिष्ट करें और डेटाबेस सेटिंग्स जोड़ें:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
पाइपलाइन प्रबंधन
हमने अपने स्पाइडर को HTML को क्रॉल और पार्स करने के लिए सेट किया है, और हमने अपनी डेटाबेस सेटिंग्स सेट की हैं। अब हमें pipelines.py . में पाइपलाइन के माध्यम से दोनों को एक साथ जोड़ना होगा ।
डेटाबेस से कनेक्ट करें
सबसे पहले, डेटाबेस से वास्तव में कनेक्ट करने के लिए एक विधि को परिभाषित करते हैं:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
यहां, हम एक क्लास बनाते हैं, MongoDBPipeline() , और हमारे पास Mongo सेटिंग्स को परिभाषित करके और फिर डेटाबेस से कनेक्ट करके क्लास को इनिशियलाइज़ करने के लिए एक कंस्ट्रक्टर फ़ंक्शन है।
डेटा संसाधित करें
इसके बाद, हमें पार्स किए गए डेटा को संसाधित करने के लिए एक विधि को परिभाषित करने की आवश्यकता है:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
हम डेटाबेस से एक कनेक्शन स्थापित करते हैं, डेटा को अनपैक करते हैं, और फिर इसे डेटाबेस में सहेजते हैं। अब हम फिर से परीक्षण कर सकते हैं!
परीक्षा
फिर से, "स्टैक" डायरेक्टरी में निम्न कमांड चलाएँ:
$ scrapy crawl stack
नोट :सुनिश्चित करें कि आपके पास Mongo daemon - mongod . है - एक अलग टर्मिनल विंडो में चल रहा है।
हुर्रे! हमने अपने क्रॉल किए गए डेटा को डेटाबेस में सफलतापूर्वक संग्रहीत कर लिया है:
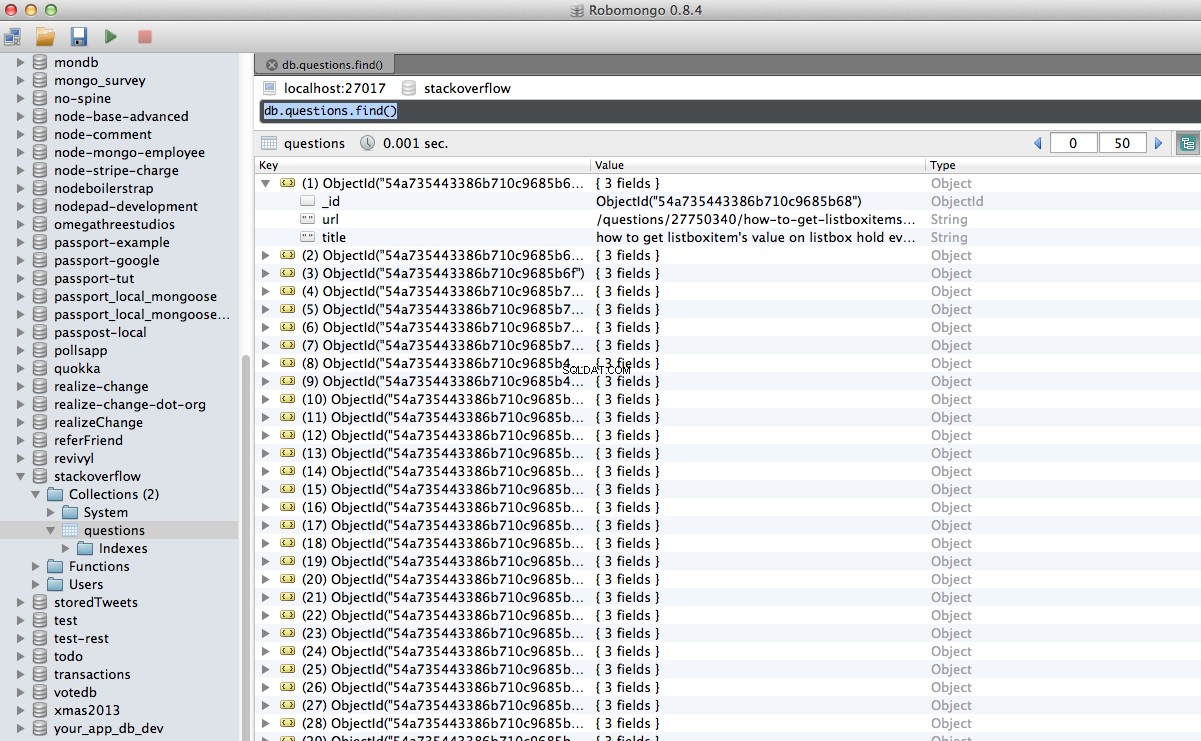
निष्कर्ष
वेब पेज को क्रॉल और स्क्रैप करने के लिए स्क्रैपी का उपयोग करने का यह एक बहुत ही सरल उदाहरण है। वास्तविक फ्रीलांस प्रोजेक्ट के लिए स्क्रिप्ट को पेजिनेशन लिंक का अनुसरण करने और CrawlSpider का उपयोग करके प्रत्येक पृष्ठ को परिमार्जन करने की आवश्यकता थी। (दस्तावेज़), जो लागू करने के लिए सुपर आसान है। इसे अपने आप लागू करने का प्रयास करें, और त्वरित कोड समीक्षा के लिए जीथब रिपोजिटरी के लिंक के साथ नीचे एक टिप्पणी छोड़ दें।
मदद की ज़रूरत है? इस स्क्रिप्ट से शुरू करें, जो लगभग पूरी हो चुकी है। फिर पूर्ण समाधान के लिए भाग 2 देखें!
निःशुल्क बोनस: पूर्ण स्रोत कोड के साथ Python + MongoDB प्रोजेक्ट कंकाल डाउनलोड करने के लिए यहां क्लिक करें जो आपको दिखाता है कि Python से MongoDB तक कैसे पहुंचें।
आप संपूर्ण स्रोत कोड को Github रिपॉजिटरी से डाउनलोड कर सकते हैं। प्रश्नों के साथ नीचे कमेंट करें। पढ़ने के लिए धन्यवाद!



