खैर, SARS-CoV-2 कोरोनावायरस के प्रसार का विश्लेषण करना मेरे सपनों का उपयोग मामला नहीं था . लेकिन SAP HANA XSA लेख के साथ Ferry Djaja के ट्रैकिंग कोरोनवायरस COVID-19 नियर रियल टाइम के जवाबों के आधार पर मैंने अपने दो ग्रोज़ी को भी जोड़ने का फैसला किया।
[20-03-30 को अपडेट किया गया स्रोत डेटा के परिवर्तित लिंक के साथ; और नए डेटा ग्रैन्युलैरिटी पर आधारित नया मैप आउटपुट। आपकी टिप्पणी के लिए धन्यवाद डगलस माल्टबी!]
अपने ब्लॉग पोस्ट में, फेरी ने जॉन्स हॉपकिन्स यूनिवर्सिटी द्वारा प्रतिदिन अपडेट की जाने वाली CSV फ़ाइलों से डेटा खींचने के लिए SAP HANA XSA में जावास्क्रिप्ट का उपयोग किया।
मैं आपको दिखाना चाहता हूं कि आप कोड की कुछ पंक्तियों का उपयोग करके इन फ़ाइलों को SAP HANA में कैसे खींच और लोड कर सकते हैं मशीन लर्निंग के लिए एसएपी हाना पायथन क्लाइंट एपीआई के लिए धन्यवाद (hana_ml पैकेज)।
कुछ लोग मानचित्र पर अंत में विज़ुअलाइज़ेशन के साथ भ्रमित थे - कृपया ध्यान दें कि यह लेख विभिन्न घटकों को जोड़ने वाले तकनीकी उपयोग के मामले पर केंद्रित है, न कि कोरोनावायरस डेटा का गहन विश्लेषण करने पर।
पायथन वातावरण प्राप्त करें, उदा। जुपिटर
मैं उसके लिए डॉकर कंटेनर में जुपिटर का उपयोग करूंगा। कृपया मेरी पिछली पोस्ट पर एक नज़र डालें कंटेनरों को समझना (भाग 05):होस्ट और कंटेनरों के बीच साझा की गई फ़ाइलें यदि आप इसे शुरू करने के तरीके से परिचित नहीं हैं। साथ ही आप नीचे दिए गए सभी चरणों को किसी भी अन्य पायथन वातावरण से कर सकते हैं।
तो, मेरे पास मेरा कंटेनर है myjupyter01 दौड़ना। जैसा कि पिछले ब्लॉग में बताया गया है, मैं Jupyter UI से जुड़ा हूं।
इंस्टॉल करें hana_ml
डॉकर हब रजिस्ट्री से उपयोग की गई जुपिटर छवि jupyter/minimal-notebook थी . इसमें पहले से ही कुछ लोकप्रिय डेटा प्रोसेसिंग पैकेज शामिल हैं, जैसे pandas ।
लेकिन इसके अतिरिक्त, मुझे hana_ml स्थापित करने की आवश्यकता है , जो - अपने वर्तमान संस्करण 1.0.8 में - PyPI रिपॉजिटरी पर उपलब्ध है:https://pypi.org/project/hana-ml/।
इंस्टालेशन को चलाने के लिए कमांड है python -m pip install hana_ml , लेकिन क्योंकि मैं इसे Python3 कर्नेल के साथ Jupyter नोटबुक से चला रहा हूं, मुझे इसे ! के साथ चलाने की आवश्यकता है शुरुआत में:
!python -m pip install hana_ml
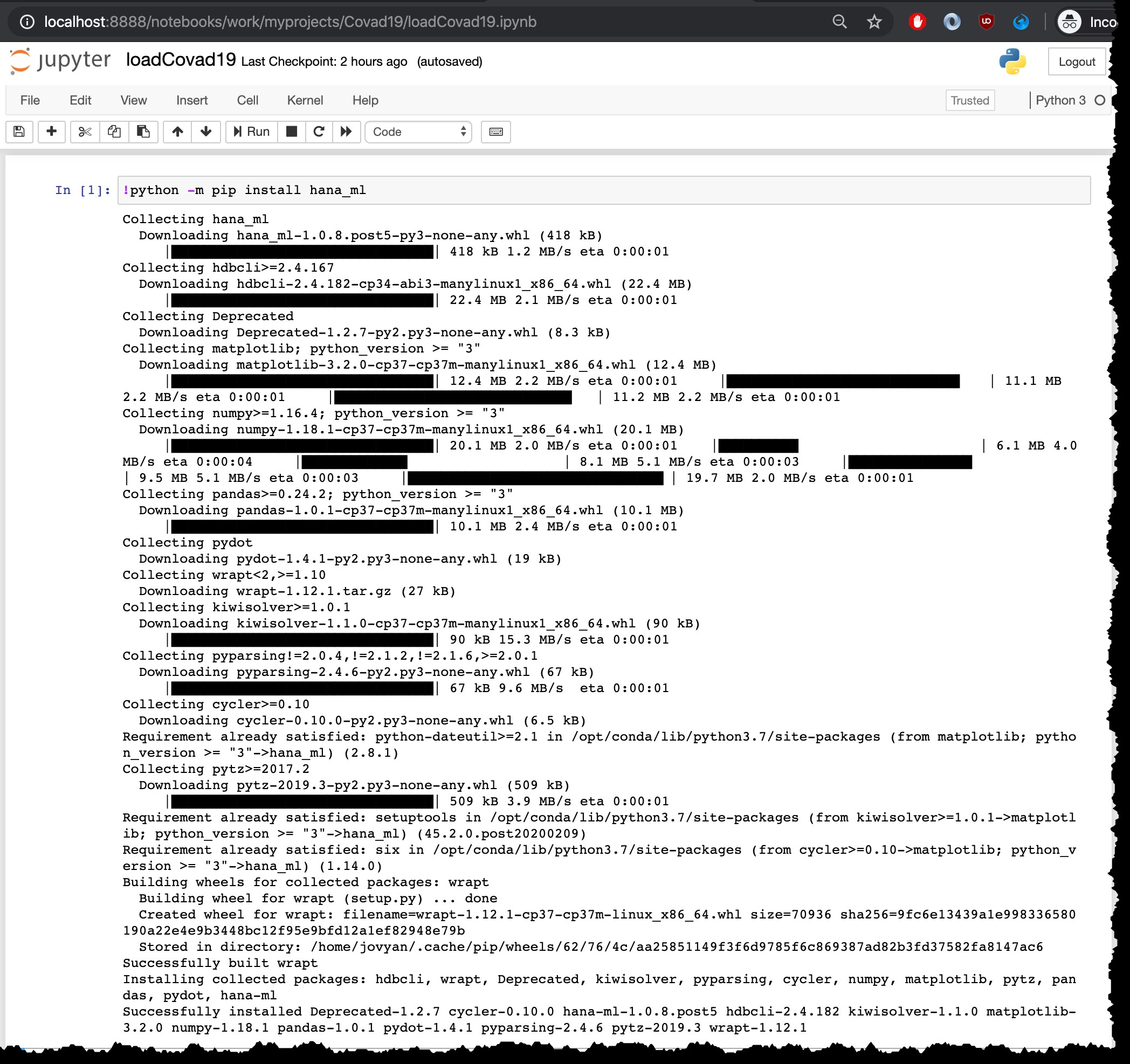
जाहिर है, यह इंस्टॉलेशन स्टेप केवल एक बार करना होगा। इसे उसी कंटेनर में फिर से चलाने की आवश्यकता नहीं है उदा। नवीनतम फ़ाइलें पुनः लोड करते समय।
pandas का उपयोग करें डेटा के साथ फ़ाइलें आयात करने के लिए
आइए उन्हीं तीन फाइलों को आयात करें (confirmed , deaths , recovered ) https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series से जैसे फेरी ने अपने उदाहरण में इस्तेमाल किया।
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
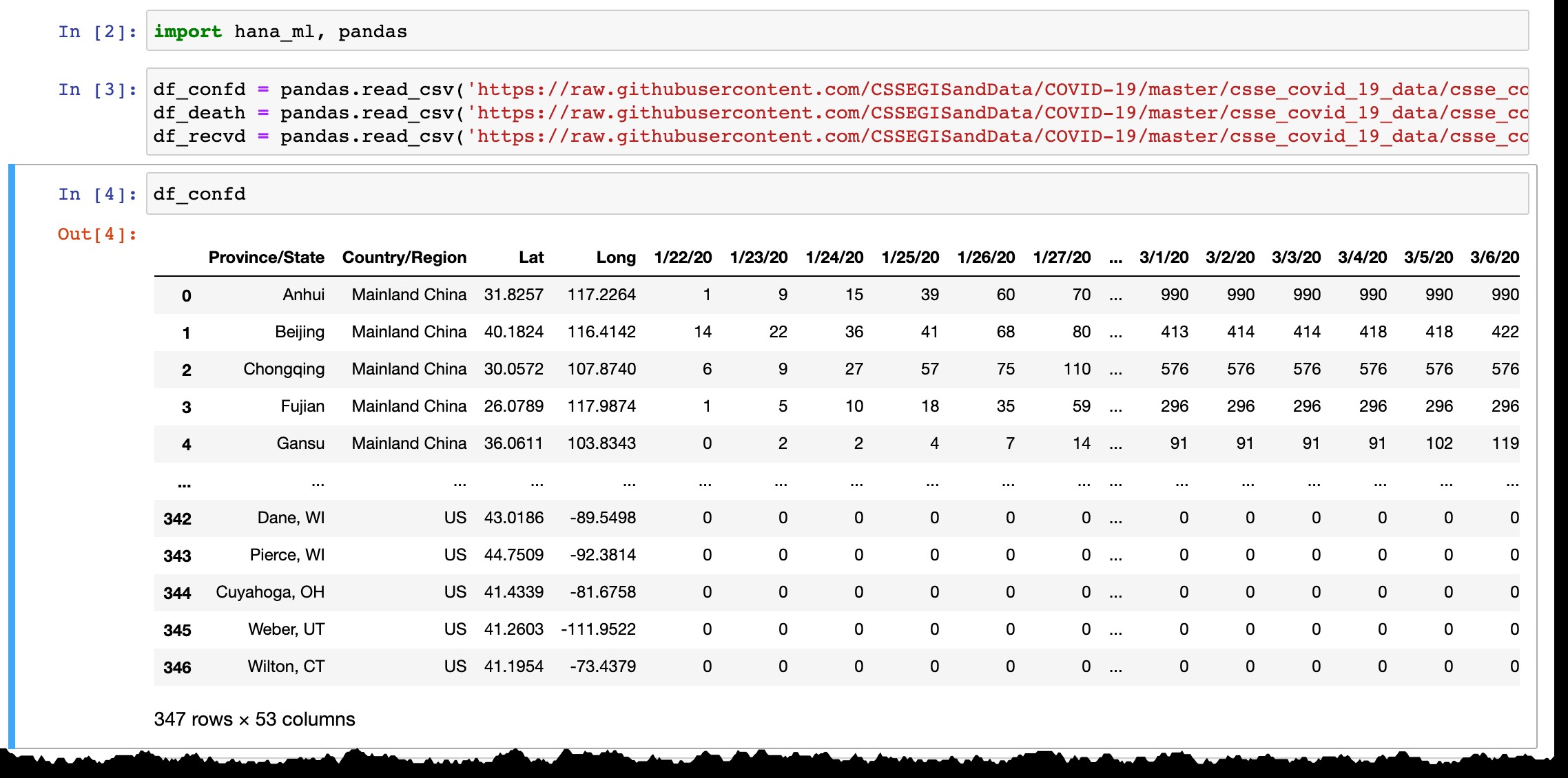
जैसा कि आप पंडों के डेटाफ्रेम के पूर्वावलोकन से देख सकते हैं, यह केवल पुष्टि किए गए मामलों वाले देशों या प्रांतों को सूचीबद्ध करता है, और हर दिन नया कॉलम पिछले दिन के नवीनतम डेटा के साथ जोड़ा जाता है। नए क्षेत्र में पहले मामले की पुष्टि होने पर लाइनें जोड़ी जाती हैं।
pandas का उपयोग करें डेटा फ़्रेम को पुनः प्रारूपित करने के लिए
सैप हाना में डेटा जारी रखने से पहले, आइए:
- आखिरी तारीख को छोड़कर सभी तारीख कॉलम हटाएं,
- वास्तविक तिथि से अंतिम कॉलम का नाम बदलें (जैसे आज का
3/10/20करने के लिएconfirmed)।
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
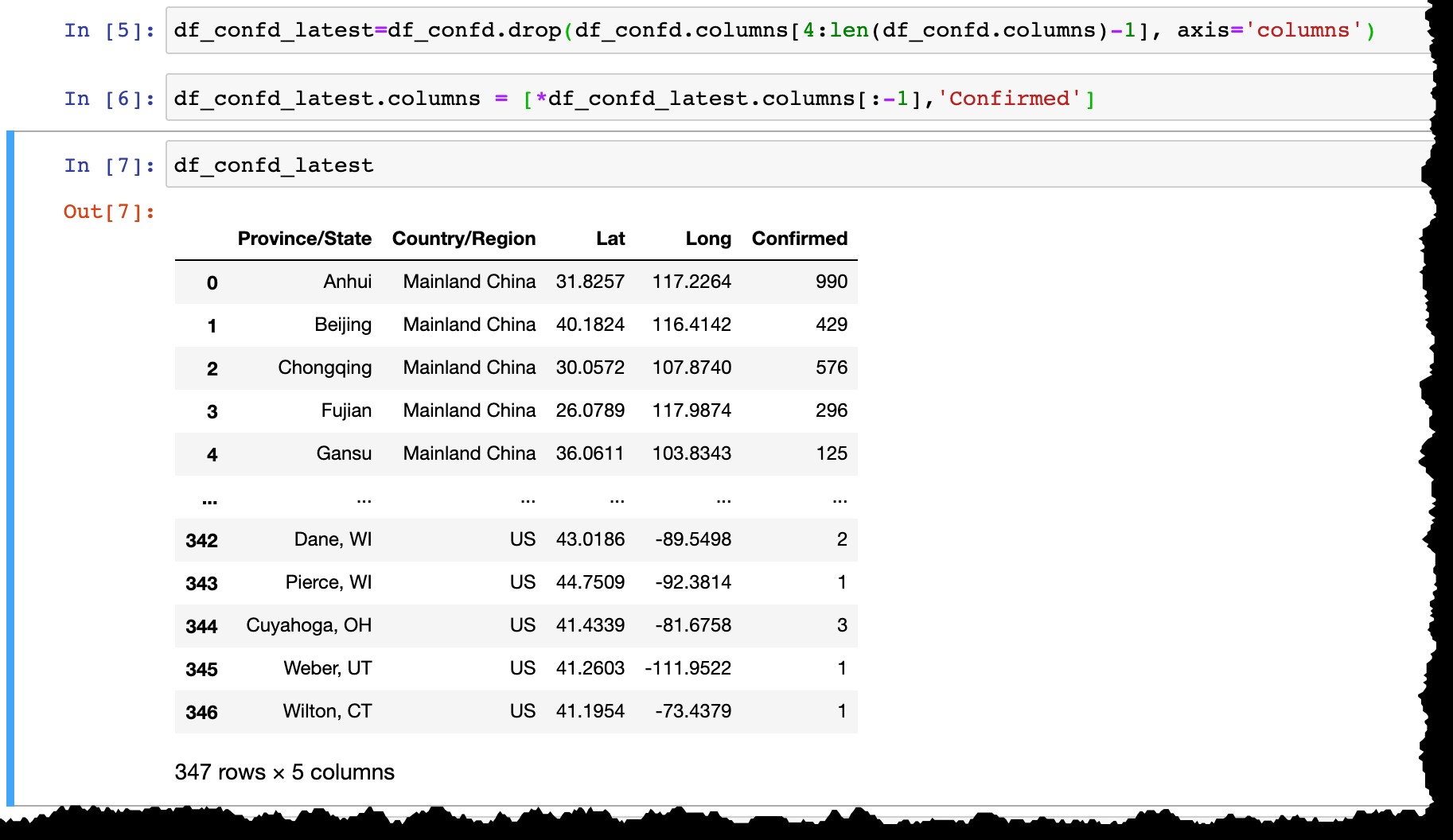
hana_ml का उपयोग करें SAP हाना तालिका में डेटा बनाए रखने के लिए
अब मुझे उपयोगकर्ता hanaml . के साथ एसएपी हाना एक्सप्रेस के अपने उदाहरण से कनेक्ट करने दें जो वहां पहले से मौजूद है...
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
...और पंडों के डेटाफ्रेम को कन्वर्ट करें df_confd_latest एक हाना डेटाफ़्रेम में hdf_confd ।
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
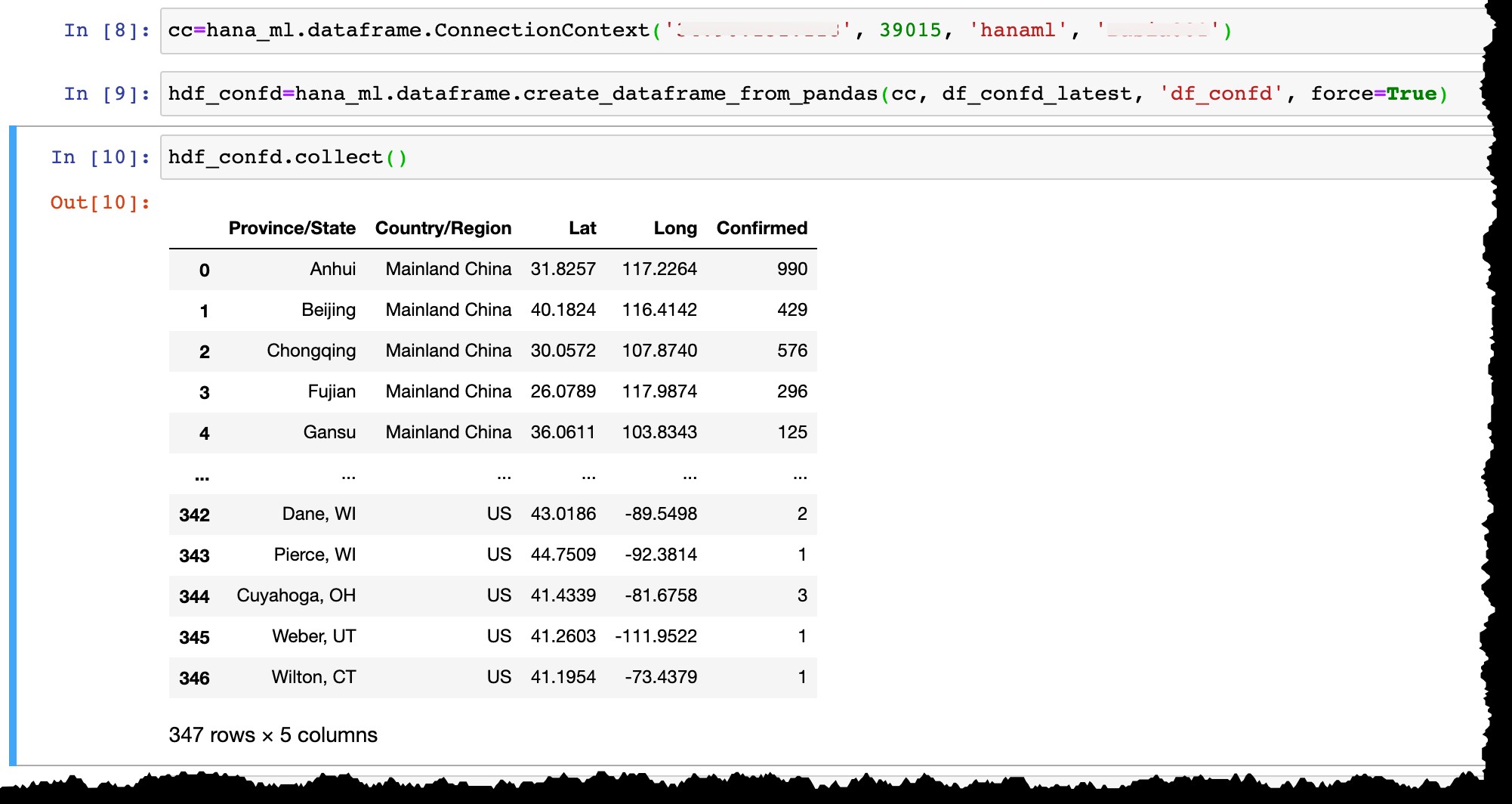
हाना डेटाफ़्रेम बन जाने के बाद:
- हाना में एक भौतिक स्तंभ तालिका बनाई जाती है और पांडा डेटाफ़्रेम से डेटा वहां डाला जाता है,
- हाना डेटाफ़्रेम
hdf_confdपायथन में आपके लैपटॉप में कोई डेटा स्टोर नहीं होता है, लेकिन केवल एक टेबलHANAML.df_confdकी ओर इशारा करता है एसएपी हाना सर्वर मेमोरी में, और हाना डेटाफ्रेम पर सभी पायथन संचालन सर्वर और क्लाइंट के बीच डेटा को स्थानांतरित किए बिना हाना डीबी में भौतिक रूप से निष्पादित होते हैं, - किसी भी ऑपरेशन के परिणाम को प्रदर्शित करने के लिए, हमें
collect(). लागू करने की आवश्यकता है हाना डेटाफ़्रेम को पंडों में बदलने की विधि (और परिणामस्वरूप हाना डीबी सर्वर से स्थानीय क्लाइंट तक डेटा लाने के लिए)।
SAP HANA में डेटा जांचने के लिए DBeaver का उपयोग करें…
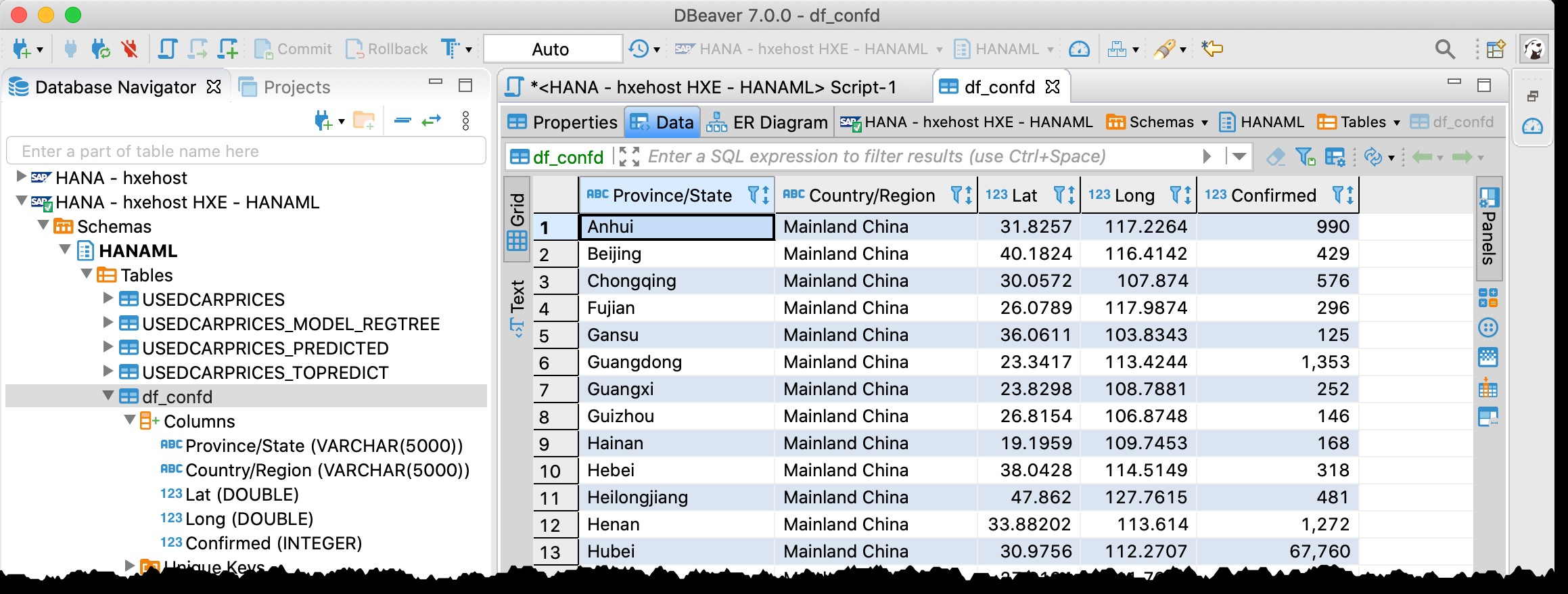
आप मुझे याद कर सकते हैं कि मैं पहले से ही डीबीवर का उपयोग कर रहा हूं - एसएपी हाना का समर्थन करने वाला मुफ्त डेटाबेस टूल - मेरी पिछली पोस्ट "जियोआर्ट विद सैप हाना और डीबीवर" में।
मैं इसे अब फिर से उपयोग कर रहा हूं, और वास्तव में मुझे तालिका मिल सकती है df_confd स्कीमा में HANAML स्रोत पांडा डेटाफ़्रेम से सभी डेटा के साथ।
...और स्थानिक पूर्वावलोकन करें
चूंकि तालिका में अक्षांश और देशांतर कॉलम हैं, इसलिए मैं स्थानिक डेटा पूर्वावलोकन का उपयोग करके निम्नलिखित SQL के साथ सीधे DBeaver से प्रभावित देशों/राज्यों की कल्पना कर सकता हूं।
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
मुझे मैप प्रोजेक्शन को EPSG:4326 . में बदलना था इन बिंदुओं को मानचित्र पर लाने के लिए। और जब मैं किसी भी बिंदु पर क्लिक करता हूं तो डीबीवर मुझे बाकी रिकॉर्ड डेटा दिखाता है।
[नीचे 2020-03-11 का पुराना स्क्रीनशॉट है, जो उदा. उस समय इस्तेमाल किया गया यूएस डेटा]
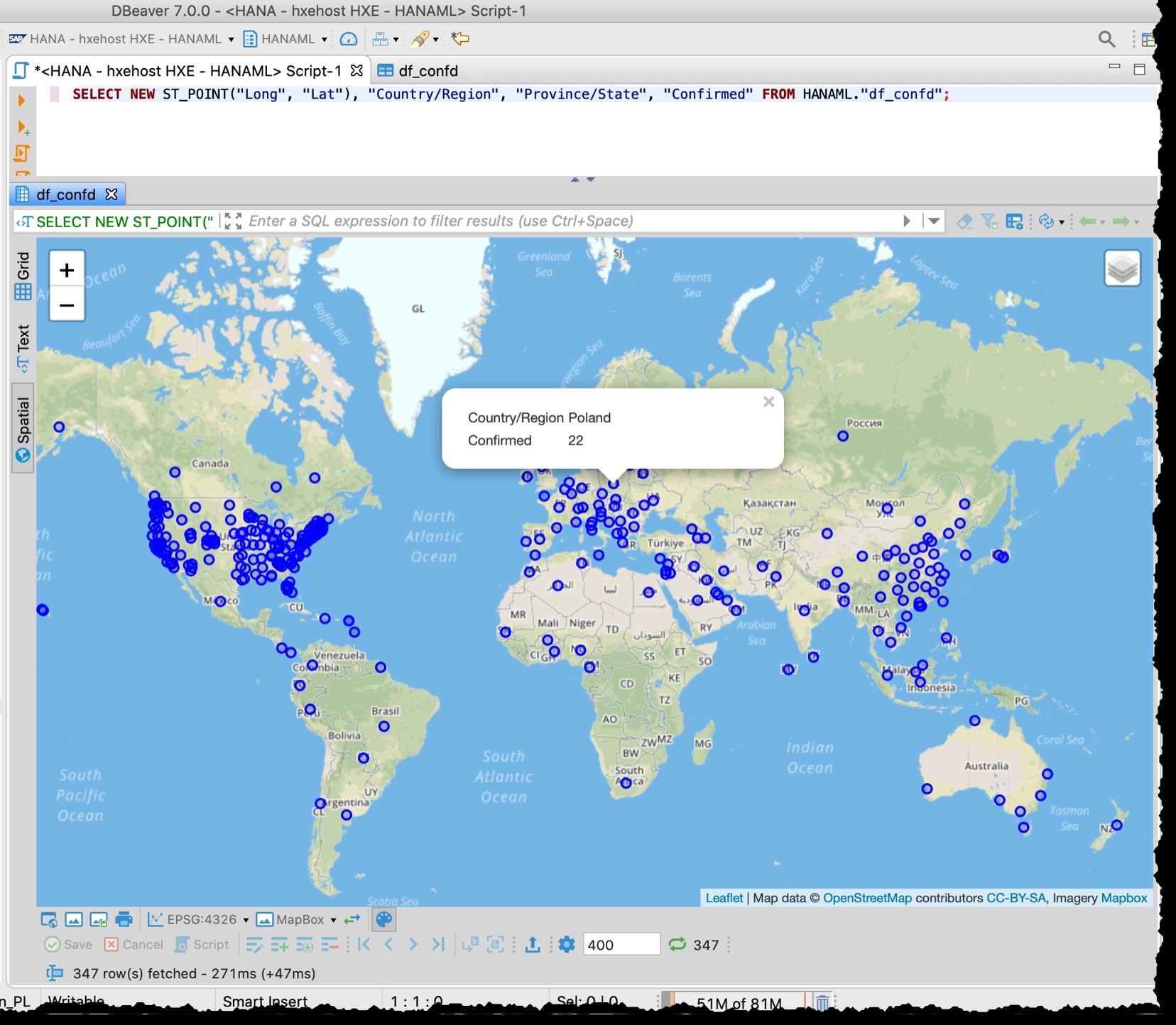
DBeaver स्थानिक पूर्वावलोकन एक पूर्ण विकसित भू-स्थानिक दृश्य अन्वेषण उपकरण नहीं है। फिर भी यह प्रभावित देशों/क्षेत्रों को देखने के लिए पर्याप्त है (स्रोत फ़ाइलों में विवरण के आधार पर)।
क्या आपको hana_ml के बारे में और जानने में दिलचस्पी होनी चाहिए ...
... तो मैं निश्चित रूप से हैंड्स-ऑन ट्यूटोरियल की जांच करने की अनुशंसा करता हूं:एंड्रियास फोर्स्टर द्वारा पायथन के साथ एसएपी हाना को मशीन लर्निंग पुश-डाउन।
कोडजैम इवेंट्स के लिए हाना एमएल नए "एडवांस्ड एनालिटिक्स विद सैप हाना" विषय का हिस्सा है। दुर्भाग्य से कोरोनावायरस की स्थिति के कारण, हमें इस महीने बर्न में जैकब फ्लेमन द्वारा आयोजित पहला कार्यक्रम रद्द करना पड़ा। इवेलिना पक्का द्वारा 27 मई को केटोवाइस में एक और आयोजन किया जाता है:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417। उम्मीद है, उस समय तक स्थिति सामान्य हो जाएगी, और हमें इसे भी रद्द करने की आवश्यकता नहीं होगी।