SELECT DISTINCT ON (1)
t.id, d.address, d.id
FROM data_table t
JOIN dictionary d ON replace(d.address, ' ', '')
LIKE (replace(t.address, ' ', '') || '%')
ORDER BY t.id, d.address, d.id
(ORDER BY प्रश्न अपडेट के बाद अपडेट किया गया।) बिना ORDER BY . के यह एक मनमाना मैच चुन रहा है।
इस संबंधित उत्तर में तकनीक के लिए स्पष्टीकरण:
प्रत्येक समूह द्वारा समूह में पहली पंक्ति का चयन करें?
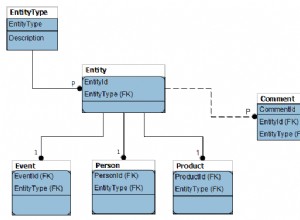
आपके शब्दकोश पर एक कार्यात्मक अनुक्रमणिका इसे तेज़ बना देगी :
CREATE INDEX dictionary_address_text_pattern_ops_idx
ON dictionary (replace(address, ' ', '') text_pattern_ops);
इसके लिए और स्पष्टीकरण मैंने पूर्ववर्ती प्रश्न को दिए गए उत्तर में दिया है। ।
कोई बहस कर सकता है कि क्या यह आपको "सर्वश्रेष्ठ" मैच देता है। एक विकल्प ट्रिग्राम इंडेक्स के साथ एक समानता मैच होगा। आपके अंतिम प्रश्न में मैंने जो लिंक जोड़े हैं उनमें से पहले का विवरण।