स्पष्टीकरण
FROM . में उप-चयन करें आपके UPDATE का खंड रिटर्न तीन पंक्तियाँ। लेकिन लक्ष्य तालिका में प्रत्येक पंक्ति को केवल एक बार अपडेट किया जा सकता है एक ही UPDATE . में आज्ञा। इसका परिणाम यह होता है कि आपको केवल एक . का प्रभाव दिखाई देता है उन तीन पंक्तियों में से।
या, मैनुअल<के शब्दों में /ए> :
इसके अलावा:अपनी सबक्वायरी "सीटीई" को कॉल न करें। यह कॉमन टेबल एक्सप्रेशन नहीं है ।
उचित UPDATE
UPDATE table_ t
SET value_ = jsonb_set(value_, '{iProps}', sub2.new_prop, false)
FROM (
SELECT id
, jsonb_agg(jsonb_set(prop, '{value, rules}', new_rules, false)
ORDER BY idx1) AS new_prop
FROM (
SELECT t.id, arr1.prop, arr1.idx1
, jsonb_agg(jsonb_set(rule, '{ao,sc}', rule #> '{ao,sc,name}', false)
ORDER BY idx2) AS new_rules
FROM table_ t
, jsonb_array_elements(value_->'iProps') WITH ORDINALITY arr1(prop,idx1)
, jsonb_array_elements(prop->'value'->'rules') WITH ORDINALITY arr2(rule,idx2)
GROUP BY t.id, arr1.prop, arr1.idx1
) sub1
GROUP BY id
) sub2
WHERE t.id = sub2.id;
db<>fiddle यहां
jsonb_set() का इस्तेमाल करें प्रत्येक वस्तु (सरणी तत्व) पर उन्हें वापस एक सरणी में एकत्रित करने से पहले। पहले पत्ती के स्तर पर, और फिर गहरे स्तर पर।
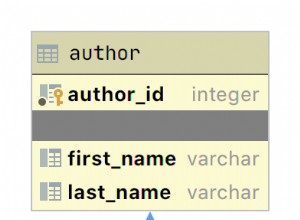
मैंने id जोड़ा PRIMARY KEY . के रूप में मेज पर। पंक्तियों को अलग रखने के लिए हमें कुछ अद्वितीय कॉलम चाहिए।
जोड़ा गया ORDER BY आवश्यकता हो भी सकती है और नहीं भी। मूल आदेश की गारंटी के लिए इसे जोड़ा गया।
बेशक, यदि आपका डेटा नमूना के रूप में नियमित है, तो समर्पित कॉलम के साथ एक रिलेशनल डिज़ाइन एक आसान विकल्प हो सकता है। देखें