सभी प्रोग्राम डेटा को एक या दूसरे रूप में संसाधित करते हैं, और कई को उस डेटा को एक आमंत्रण से दूसरे में सहेजने और पुनर्प्राप्त करने में सक्षम होने की आवश्यकता होती है। Python, SQLite, और SQLAlchemy आपके प्रोग्राम को डेटाबेस कार्यक्षमता प्रदान करते हैं, जिससे आप डेटाबेस सर्वर की आवश्यकता के बिना डेटा को एक फ़ाइल में संग्रहीत कर सकते हैं।
आप सीएसवी, जेएसओएन, एक्सएमएल और यहां तक कि कस्टम प्रारूपों सहित किसी भी प्रारूप में फ्लैट फाइलों का उपयोग करके समान परिणाम प्राप्त कर सकते हैं। फ़्लैट फ़ाइलें अक्सर मानव-पठनीय पाठ फ़ाइलें होती हैं—हालाँकि वे बाइनरी डेटा भी हो सकती हैं—एक संरचना के साथ जिसे कंप्यूटर प्रोग्राम द्वारा पार्स किया जा सकता है। नीचे, आप डेटा संग्रहण और हेरफेर के लिए SQL डेटाबेस और फ़्लैट फ़ाइलों का उपयोग करके एक्सप्लोर करेंगे और यह तय करेंगे कि आपके प्रोग्राम के लिए कौन सा तरीका सही है।
इस ट्यूटोरियल में, आप इसका उपयोग करना सीखेंगे:
- फ्लैट फ़ाइलें डेटा संग्रहण के लिए
- एसक्यूएल लगातार डेटा तक पहुंच में सुधार करने के लिए
- SQLite डेटा संग्रहण के लिए
- SQLAlchemy डेटा के साथ पायथन ऑब्जेक्ट के रूप में काम करने के लिए
आप नीचे दिए गए लिंक पर क्लिक करके इस ट्यूटोरियल में दिखाई देने वाले सभी कोड और डेटा प्राप्त कर सकते हैं:
नमूना कोड डाउनलोड करें: इस ट्यूटोरियल में SQLite और SQLAlchemy के साथ डेटा प्रबंधन के बारे में जानने के लिए आप जिस कोड का उपयोग करेंगे, उसे प्राप्त करने के लिए यहां क्लिक करें।
डेटा संग्रहण के लिए फ़्लैट फ़ाइलों का उपयोग करना
एक फ्लैट फ़ाइल एक फ़ाइल है जिसमें कोई आंतरिक पदानुक्रम नहीं है और आमतौर पर बाहरी फ़ाइलों का कोई संदर्भ नहीं है। फ़्लैट फ़ाइलों में मानव-पठनीय वर्ण होते हैं और डेटा बनाने और पढ़ने के लिए बहुत उपयोगी होते हैं। क्योंकि उन्हें निश्चित फ़ील्ड चौड़ाई का उपयोग नहीं करना पड़ता है, फ्लैट फाइलें अक्सर अन्य संरचनाओं का उपयोग करती हैं ताकि प्रोग्राम के लिए टेक्स्ट को पार्स करना संभव हो सके।
उदाहरण के लिए, कॉमा सेपरेटेड वैल्यू (सीएसवी) फाइलें सादे टेक्स्ट की लाइनें हैं जिसमें कॉमा कैरेक्टर डेटा तत्वों को अलग करता है। पाठ की प्रत्येक पंक्ति डेटा की एक पंक्ति का प्रतिनिधित्व करती है, और प्रत्येक अल्पविराम से अलग किया गया मान उस पंक्ति के भीतर एक फ़ील्ड है। अल्पविराम वर्ण सीमांकक डेटा मानों के बीच की सीमा को इंगित करता है।
पायथन फाइलों को पढ़ने और सहेजने में उत्कृष्टता प्राप्त करता है। पायथन के साथ डेटा फ़ाइलों को पढ़ने में सक्षम होने से आप किसी एप्लिकेशन को बाद में फिर से चलाने पर एक उपयोगी स्थिति में पुनर्स्थापित कर सकते हैं। किसी फ़ाइल में डेटा सहेजने में सक्षम होने के कारण आप प्रोग्राम से जानकारी उन उपयोगकर्ताओं और साइटों के बीच साझा कर सकते हैं जहां एप्लिकेशन चलता है।
इससे पहले कि कोई प्रोग्राम किसी डेटा फ़ाइल को पढ़ सके, उसे डेटा को समझने में सक्षम होना चाहिए। आमतौर पर, इसका मतलब है कि डेटा फ़ाइल में कुछ संरचना होनी चाहिए जिसका उपयोग एप्लिकेशन फ़ाइल में टेक्स्ट को पढ़ने और पार्स करने के लिए कर सके।
नीचे एक CSV फ़ाइल है जिसका नाम author_book_publisher.csv . है , इस ट्यूटोरियल में पहले उदाहरण प्रोग्राम द्वारा उपयोग किया गया:
first_name,last_name,title,publisher
Isaac,Asimov,Foundation,Random House
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Tom,Clancy,The Hunt For Red October,Berkley
Tom,Clancy,Patriot Games,Simon & Schuster
Stephen,King,It,Random House
Stephen,King,It,Penguin Random House
Stephen,King,Dead Zone,Random House
Stephen,King,The Shining,Penguin Random House
John,Le Carre,"Tinker, Tailor, Soldier, Spy: A George Smiley Novel",Berkley
Alex,Michaelides,The Silent Patient,Simon & Schuster
Carol,Shaben,Into The Abyss,Simon & Schuster
पहली पंक्ति फ़ील्ड की अल्पविराम से अलग की गई सूची प्रदान करती है, जो कि शेष पंक्तियों में आने वाले डेटा के लिए स्तंभ नाम हैं। शेष पंक्तियों में डेटा होता है, प्रत्येक पंक्ति एकल रिकॉर्ड का प्रतिनिधित्व करती है।
नोट: हालांकि लेखक, किताबें और प्रकाशक सभी वास्तविक हैं, किताबों और प्रकाशकों के बीच संबंध काल्पनिक हैं और इस ट्यूटोरियल के लिए बनाए गए हैं।
इसके बाद, आप अपने डेटा के साथ काम करने के लिए उपरोक्त CSV जैसी फ़्लैट फ़ाइलों का उपयोग करने के कुछ फायदे और नुकसान पर एक नज़र डालेंगे।
फ्लैट फ़ाइलों के लाभ
फ्लैट फाइलों में डेटा के साथ काम करना प्रबंधनीय है और इसे लागू करना आसान है। डेटा को मानव-पठनीय प्रारूप में रखना न केवल टेक्स्ट एडिटर के साथ डेटा फ़ाइल बनाने के लिए बल्कि डेटा की जांच करने और किसी भी विसंगतियों या समस्याओं की तलाश करने के लिए भी सहायक होता है।
कई एप्लिकेशन फ़ाइल द्वारा उत्पन्न डेटा के फ्लैट-फ़ाइल संस्करणों को निर्यात कर सकते हैं। उदाहरण के लिए, एक्सेल एक स्प्रैडशीट में और उससे CSV फ़ाइल आयात या निर्यात कर सकता है। यदि आप डेटा साझा करना चाहते हैं, तो फ़्लैट फ़ाइलों को स्व-निहित और हस्तांतरणीय होने का लाभ भी मिलता है।
लगभग हर प्रोग्रामिंग भाषा में ऐसे उपकरण और पुस्तकालय होते हैं जो CSV फ़ाइलों के साथ काम करना आसान बनाते हैं। पायथन में बिल्ट-इन csv है मॉड्यूल और शक्तिशाली पांडा मॉड्यूल उपलब्ध है, जो CSV फ़ाइलों के साथ काम करना एक शक्तिशाली समाधान बनाता है।
फ्लैट फ़ाइलों के नुकसान
जैसे-जैसे डेटा बड़ा होता जाता है, फ्लैट फाइलों के साथ काम करने के फायदे कम होने लगते हैं। बड़ी फ़ाइलें अभी भी मानव-पठनीय हैं, लेकिन डेटा बनाने या समस्याओं को देखने के लिए उन्हें संपादित करना अधिक कठिन कार्य हो जाता है। यदि आपका एप्लिकेशन फ़ाइल में डेटा को बदल देगा, तो एक समाधान यह होगा कि पूरी फ़ाइल को मेमोरी में पढ़ें, परिवर्तन करें, और डेटा को दूसरी फ़ाइल में लिखें।
फ्लैट फ़ाइलों का उपयोग करने में एक और समस्या यह है कि आपको फ़ाइल सिंटैक्स के भीतर अपने डेटा के कुछ हिस्सों और एप्लिकेशन प्रोग्राम के बीच किसी भी संबंध को स्पष्ट रूप से बनाने और बनाए रखने की आवश्यकता होगी। इसके अतिरिक्त, आपको उन संबंधों का उपयोग करने के लिए अपने एप्लिकेशन में कोड जेनरेट करना होगा।
एक अंतिम जटिलता यह है कि जिन लोगों के साथ आप अपनी डेटा फ़ाइल साझा करना चाहते हैं, उन्हें भी डेटा में आपके द्वारा बनाए गए संरचनाओं और संबंधों के बारे में जानने और उन पर कार्य करने की आवश्यकता होगी। जानकारी तक पहुँचने के लिए, उन उपयोगकर्ताओं को न केवल डेटा की संरचना बल्कि उस तक पहुँचने के लिए आवश्यक प्रोग्रामिंग टूल को भी समझना होगा।
फ्लैट फ़ाइल उदाहरण
उदाहरण प्रोग्राम examples/example_1/main.py author_book_publisher.csv . का उपयोग करता है इसमें डेटा और संबंध प्राप्त करने के लिए फ़ाइल। यह CSV फ़ाइल लेखकों, उनके द्वारा प्रकाशित पुस्तकों और प्रत्येक पुस्तक के प्रकाशकों की सूची बनाए रखती है।
नोट: उदाहरणों में प्रयुक्त डेटा फ़ाइलें project/data . में उपलब्ध हैं निर्देशिका। project/build_data . में एक प्रोग्राम फ़ाइल भी है निर्देशिका जो डेटा उत्पन्न करती है। यदि आप डेटा बदलते हैं और किसी ज्ञात स्थिति में वापस जाना चाहते हैं तो यह एप्लिकेशन उपयोगी है।
इस अनुभाग में और पूरे ट्यूटोरियल में उपयोग की गई डेटा फ़ाइलों तक पहुँच प्राप्त करने के लिए, नीचे दिए गए लिंक पर क्लिक करें:
नमूना कोड डाउनलोड करें: इस ट्यूटोरियल में SQLite और SQLAlchemy के साथ डेटा प्रबंधन के बारे में जानने के लिए आप जिस कोड का उपयोग करेंगे, उसे प्राप्त करने के लिए यहां क्लिक करें।
ऊपर प्रस्तुत सीएसवी फ़ाइल एक बहुत छोटी डेटा फ़ाइल है जिसमें केवल कुछ लेखक, पुस्तकें और प्रकाशक शामिल हैं। आपको डेटा के बारे में कुछ बातों पर भी ध्यान देना चाहिए:
-
लेखक स्टीफ़न किंग और टॉम क्लैंसी एक से अधिक बार दिखाई देते हैं क्योंकि उनके द्वारा प्रकाशित की गई कई पुस्तकें डेटा में दर्शायी जाती हैं।
-
लेखक स्टीफ़न किंग और पर्ल बक की एक ही पुस्तक एक से अधिक प्रकाशकों द्वारा प्रकाशित की गई है।
ये डुप्लीकेट डेटा फ़ील्ड डेटा के अन्य भागों के बीच संबंध बनाते हैं। एक लेखक कई किताबें लिख सकता है, और एक प्रकाशक कई लेखकों के साथ काम कर सकता है। लेखक और प्रकाशक अलग-अलग पुस्तकों के साथ संबंध साझा करते हैं।
author_book_publisher.csv में संबंध फ़ाइल को उन फ़ील्ड द्वारा दर्शाया जाता है जो डेटा फ़ाइल की विभिन्न पंक्तियों में कई बार दिखाई देती हैं। इस डेटा अतिरेक के कारण, डेटा एक से अधिक द्वि-आयामी तालिका का प्रतिनिधित्व करता है। जब आप SQLite डेटाबेस फ़ाइल बनाने के लिए फ़ाइल का उपयोग करते हैं तो आप इसे और अधिक देखेंगे।
उदाहरण प्रोग्राम examples/example_1/main.py author_book_publisher.csv में एम्बेड किए गए संबंधों का उपयोग करता है कुछ डेटा उत्पन्न करने के लिए फ़ाइल। यह पहले लेखकों की एक सूची और प्रत्येक ने लिखी गई पुस्तकों की संख्या प्रस्तुत करता है। इसके बाद यह प्रकाशकों की सूची और उन लेखकों की संख्या दिखाता है जिनके लिए प्रत्येक ने पुस्तकें प्रकाशित की हैं।
यह treelib . का भी उपयोग करता है लेखकों, पुस्तकों और प्रकाशकों के ट्री पदानुक्रम को प्रदर्शित करने के लिए मॉड्यूल।
अंत में, यह डेटा में एक नई किताब जोड़ता है और नई किताब के साथ ट्री पदानुक्रम को फिर से प्रदर्शित करता है। यह रहा main() इस कार्यक्रम के लिए प्रवेश-बिंदु समारोह:
1def main():
2 """The main entry point of the program"""
3 # Get the resources for the program
4 with resources.path(
5 "project.data", "author_book_publisher.csv"
6 ) as filepath:
7 data = get_data(filepath)
8
9 # Get the number of books printed by each publisher
10 books_by_publisher = get_books_by_publisher(data, ascending=False)
11 for publisher, total_books in books_by_publisher.items():
12 print(f"Publisher: {publisher}, total books: {total_books}")
13 print()
14
15 # Get the number of authors each publisher publishes
16 authors_by_publisher = get_authors_by_publisher(data, ascending=False)
17 for publisher, total_authors in authors_by_publisher.items():
18 print(f"Publisher: {publisher}, total authors: {total_authors}")
19 print()
20
21 # Output hierarchical authors data
22 output_author_hierarchy(data)
23
24 # Add a new book to the data structure
25 data = add_new_book(
26 data,
27 author_name="Stephen King",
28 book_title="The Stand",
29 publisher_name="Random House",
30 )
31
32 # Output the updated hierarchical authors data
33 output_author_hierarchy(data)
उपरोक्त पायथन कोड निम्नलिखित कदम उठाता है:
- पंक्ति 4 से 7
author_book_publisher.csvपढ़ें एक पांडा डेटाफ़्रेम में फ़ाइल करें। - पंक्ति 10 से 13 प्रत्येक प्रकाशक द्वारा प्रकाशित पुस्तकों की संख्या मुद्रित करें।
- पंक्ति 16 से 19 प्रत्येक प्रकाशक से जुड़े लेखकों की संख्या प्रिंट करें।
- पंक्ति 22 पुस्तक डेटा को लेखकों द्वारा क्रमबद्ध एक पदानुक्रम के रूप में आउटपुट करता है।
- पंक्ति 25 से 30 स्मृति संरचना में एक नई पुस्तक जोड़ें।
- पंक्ति 33 पुस्तक डेटा को नई जोड़ी गई पुस्तक सहित लेखकों द्वारा क्रमबद्ध एक पदानुक्रम के रूप में आउटपुट करता है।
इस प्रोग्राम को चलाने से निम्न आउटपुट उत्पन्न होता है:
$ python main.py
Publisher: Simon & Schuster, total books: 4
Publisher: Random House, total books: 4
Publisher: Penguin Random House, total books: 2
Publisher: Berkley, total books: 2
Publisher: Simon & Schuster, total authors: 4
Publisher: Random House, total authors: 3
Publisher: Berkley, total authors: 2
Publisher: Penguin Random House, total authors: 1
Authors
├── Alex Michaelides
│ └── The Silent Patient
│ └── Simon & Schuster
├── Carol Shaben
│ └── Into The Abyss
│ └── Simon & Schuster
├── Isaac Asimov
│ └── Foundation
│ └── Random House
├── John Le Carre
│ └── Tinker, Tailor, Soldier, Spy: A George Smiley Novel
│ └── Berkley
├── Pearl Buck
│ └── The Good Earth
│ ├── Random House
│ └── Simon & Schuster
├── Stephen King
│ ├── Dead Zone
│ │ └── Random House
│ ├── It
│ │ ├── Penguin Random House
│ │ └── Random House
│ └── The Shining
│ └── Penguin Random House
└── Tom Clancy
├── Patriot Games
│ └── Simon & Schuster
└── The Hunt For Red October
└── Berkley
स्टीफ़न किंग के द स्टैंड . को जोड़ने के साथ, उपरोक्त लेखक पदानुक्रम को आउटपुट में दो बार प्रस्तुत किया गया है रैंडम हाउस द्वारा प्रकाशित। उपरोक्त वास्तविक आउटपुट को संपादित किया गया है और स्थान बचाने के लिए केवल पहला पदानुक्रम आउटपुट दिखाता है।
main() अधिकांश कार्य करने के लिए अन्य कार्यों को कॉल करता है। पहला फ़ंक्शन जिसे वह कॉल करता है वह है get_data() :
def get_data(filepath):
"""Get book data from the csv file"""
return pd.read_csv(filepath)
यह फ़ंक्शन CSV फ़ाइल के फ़ाइल पथ में ले जाता है और इसे पांडा डेटाफ़्रेम में पढ़ने के लिए पांडा का उपयोग करता है, जिसे वह फिर कॉलर को वापस भेज देता है। इस फ़ंक्शन का रिटर्न मान प्रोग्राम बनाने वाले अन्य कार्यों के लिए पारित डेटा संरचना बन जाता है।
get_books_by_publisher() प्रत्येक प्रकाशक द्वारा प्रकाशित पुस्तकों की संख्या की गणना करता है। परिणामी पांडा श्रृंखला प्रकाशक द्वारा समूहबद्ध करने के लिए पांडा ग्रुपबी कार्यक्षमता का उपयोग करती है और फिर ascending के आधार पर क्रमबद्ध करती है झंडा:
def get_books_by_publisher(data, ascending=True):
"""Return the number of books by each publisher as a pandas series"""
return data.groupby("publisher").size().sort_values(ascending=ascending)
get_authors_by_publisher() अनिवार्य रूप से पिछले फ़ंक्शन के समान ही काम करता है, लेकिन लेखकों के लिए:
def get_authors_by_publisher(data, ascending=True):
"""Returns the number of authors by each publisher as a pandas series"""
return (
data.assign(name=data.first_name.str.cat(data.last_name, sep=" "))
.groupby("publisher")
.nunique()
.loc[:, "name"]
.sort_values(ascending=ascending)
)
add_new_book() पांडा DataFrame में एक नई किताब बनाता है। कोड यह देखने के लिए जांचता है कि लेखक, पुस्तक या प्रकाशक पहले से मौजूद है या नहीं। यदि नहीं, तो यह एक नई किताब बनाता है और इसे पांडा डेटाफ़्रेम में जोड़ता है:
def add_new_book(data, author_name, book_title, publisher_name):
"""Adds a new book to the system"""
# Does the book exist?
first_name, _, last_name = author_name.partition(" ")
if any(
(data.first_name == first_name)
& (data.last_name == last_name)
& (data.title == book_title)
& (data.publisher == publisher_name)
):
return data
# Add the new book
return data.append(
{
"first_name": first_name,
"last_name": last_name,
"title": book_title,
"publisher": publisher_name,
},
ignore_index=True,
)
output_author_hierarchy() नेस्टेड का उपयोग करता है for डेटा संरचना के स्तरों के माध्यम से पुनरावृति करने के लिए लूप। इसके बाद यह treelib . का उपयोग करता है लेखकों, उनके द्वारा प्रकाशित पुस्तकों और उन पुस्तकों को प्रकाशित करने वाले प्रकाशकों की एक श्रेणीबद्ध सूची को आउटपुट करने के लिए मॉड्यूल:
def output_author_hierarchy(data):
"""Output the data as a hierarchy list of authors"""
authors = data.assign(
name=data.first_name.str.cat(data.last_name, sep=" ")
)
authors_tree = Tree()
authors_tree.create_node("Authors", "authors")
for author, books in authors.groupby("name"):
authors_tree.create_node(author, author, parent="authors")
for book, publishers in books.groupby("title")["publisher"]:
book_id = f"{author}:{book}"
authors_tree.create_node(book, book_id, parent=author)
for publisher in publishers:
authors_tree.create_node(publisher, parent=book_id)
# Output the hierarchical authors data
authors_tree.show()
यह एप्लिकेशन अच्छी तरह से काम करता है और पांडा मॉड्यूल के साथ आपके लिए उपलब्ध शक्ति को दिखाता है। मॉड्यूल CSV फ़ाइल पढ़ने और डेटा के साथ इंटरैक्ट करने के लिए उत्कृष्ट कार्यक्षमता प्रदान करता है।
आइए उस डेटा के साथ इंटरैक्ट करने के लिए लेखक और प्रकाशन डेटा के एक SQLite डेटाबेस संस्करण, और SQLAlchemy का उपयोग करके एक समान रूप से कार्य करने वाले प्रोग्राम को आगे बढ़ाएं और बनाएं।
डेटा बनाए रखने के लिए SQLite का उपयोग करना
जैसा कि आपने पहले देखा, author_book_publisher.csv में अनावश्यक डेटा है फ़ाइल। उदाहरण के लिए, पर्ल बक की द गुड अर्थ . के बारे में सभी जानकारी दो बार सूचीबद्ध है क्योंकि दो अलग-अलग प्रकाशकों ने पुस्तक प्रकाशित की है।
कल्पना करें कि क्या इस डेटा फ़ाइल में लेखक का पता और फ़ोन नंबर, प्रकाशन दिनांक और पुस्तकों के लिए ISBN, या पते, फ़ोन नंबर, और शायद प्रकाशकों के लिए वार्षिक आय जैसे अधिक संबंधित डेटा होते हैं। यह डेटा लेखक, पुस्तक, या प्रकाशक जैसे प्रत्येक रूट डेटा आइटम के लिए डुप्लिकेट किया जाएगा।
इस तरह से डेटा बनाना संभव है, लेकिन यह असाधारण रूप से बोझिल होगा। इस डेटा फ़ाइल को चालू रखने में आने वाली समस्याओं के बारे में सोचें। क्या होगा अगर स्टीफन किंग अपना नाम बदलना चाहते हैं? आपको उसके नाम वाले कई रिकॉर्ड अपडेट करने होंगे और सुनिश्चित करना होगा कि कोई टाइपो तो नहीं है।
डेटा दोहराव से भी बदतर डेटा में अन्य संबंधों को जोड़ने की जटिलता होगी। क्या होगा यदि आपने लेखकों के लिए फ़ोन नंबर जोड़ने का निर्णय लिया है, और उनके पास घर, काम, मोबाइल, और शायद अधिक के लिए फ़ोन नंबर हैं? प्रत्येक नया संबंध जिसे आप किसी रूट आइटम के लिए जोड़ना चाहते हैं, रिकॉर्ड की संख्या को उस नए संबंध में आइटम की संख्या से गुणा करेगा।
यह समस्या एक कारण है कि डेटाबेस सिस्टम में संबंध मौजूद हैं। डेटाबेस इंजीनियरिंग में एक महत्वपूर्ण विषय है डेटाबेस सामान्यीकरण , या अतिरेक को कम करने और अखंडता को बढ़ाने के लिए डेटा को अलग करने की प्रक्रिया। जब एक डेटाबेस संरचना को नए प्रकार के डेटा के साथ विस्तारित किया जाता है, तो इसे पहले से सामान्यीकृत करने से मौजूदा संरचना में बदलाव कम से कम हो जाते हैं।
SQLite डेटाबेस पायथन में उपलब्ध है, और SQLite होम पेज के अनुसार, यह संयुक्त रूप से अन्य सभी डेटाबेस सिस्टम की तुलना में अधिक उपयोग किया जाता है। यह एक पूर्ण विशेषताओं वाला रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS) प्रदान करता है जो सभी डेटाबेस कार्यक्षमता को बनाए रखने के लिए एकल फ़ाइल के साथ काम करता है।
इसे कार्य करने के लिए एक अलग डेटाबेस सर्वर की आवश्यकता नहीं होने का भी लाभ है। डेटाबेस फ़ाइल स्वरूप क्रॉस-प्लेटफ़ॉर्म है और SQLite का समर्थन करने वाली किसी भी प्रोग्रामिंग भाषा के लिए सुलभ है।
यह सब दिलचस्प जानकारी है, लेकिन डेटा भंडारण के लिए फ्लैट फाइलों के उपयोग के लिए यह कैसे प्रासंगिक है? आपको नीचे पता चलेगा!
डेटाबेस संरचना बनाना
author_book_publisher.csv . प्राप्त करने के लिए पाशविक बल दृष्टिकोण SQLite डेटाबेस में डेटा CSV फ़ाइल की संरचना से मेल खाने वाली एकल तालिका बनाना होगा। ऐसा करने से SQLite की बहुत सी शक्ति की उपेक्षा हो जाएगी।
संबंधपरक डेटाबेस संरचित डेटा को तालिकाओं में संग्रहीत करने और उन तालिकाओं के बीच संबंध स्थापित करने का एक तरीका प्रदान करें। वे आमतौर पर संरचित क्वेरी भाषा (एसक्यूएल) का उपयोग डेटा के साथ बातचीत करने के प्राथमिक तरीके के रूप में करते हैं। यह RDBMS जो प्रदान करता है उसका एक ओवरसिम्प्लीफिकेशन है, लेकिन यह इस ट्यूटोरियल के उद्देश्यों के लिए पर्याप्त है।
SQLite डेटाबेस SQL का उपयोग करके डेटा तालिका के साथ सहभागिता करने के लिए सहायता प्रदान करता है। SQLite डेटाबेस फ़ाइल में न केवल डेटा होता है, बल्कि डेटा के साथ इंटरैक्ट करने का एक मानकीकृत तरीका भी होता है। यह समर्थन फ़ाइल में अंतर्निहित है, जिसका अर्थ है कि कोई भी प्रोग्रामिंग भाषा जो SQLite फ़ाइल का उपयोग कर सकती है, उसके साथ कार्य करने के लिए SQL का भी उपयोग कर सकती है।
SQL के साथ डेटाबेस के साथ सहभागिता
SQL एक घोषणात्मक भाषा है डेटाबेस में निहित डेटा को बनाने, प्रबंधित करने और क्वेरी करने के लिए उपयोग किया जाता है। एक घोषणात्मक भाषा क्या . का वर्णन करती है कैसे . के बजाय पूरा किया जाना है इसे पूरा किया जाना चाहिए। जब आप डेटाबेस टेबल बनाना शुरू करेंगे तो आपको SQL स्टेटमेंट के उदाहरण बाद में दिखाई देंगे।
SQL के साथ डेटाबेस की संरचना करना
SQL में शक्ति का लाभ उठाने के लिए, आपको author_book_publisher.csv में डेटा के लिए कुछ डेटाबेस सामान्यीकरण लागू करने की आवश्यकता होगी। फ़ाइल। ऐसा करने के लिए, आप लेखकों, पुस्तकों और प्रकाशकों को अलग-अलग डेटाबेस तालिकाओं में अलग कर देंगे।
वैचारिक रूप से, डेटा को दो-आयामी तालिका संरचनाओं में डेटाबेस में संग्रहीत किया जाता है। प्रत्येक तालिका में रिकॉर्ड . की पंक्तियाँ होती हैं , और प्रत्येक रिकॉर्ड में कॉलम, या फ़ील्ड . होते हैं , डेटा युक्त।
फ़ील्ड में निहित डेटा पूर्व-निर्धारित प्रकार का होता है, जिसमें टेक्स्ट, पूर्णांक, फ़्लोट और बहुत कुछ शामिल होता है। सीएसवी फाइलें अलग हैं क्योंकि सभी फ़ील्ड टेक्स्ट हैं और उन्हें एक डेटा प्रकार असाइन करने के लिए प्रोग्राम द्वारा पार्स किया जाना चाहिए।
तालिका के प्रत्येक रिकॉर्ड में एक प्राथमिक कुंजी होती है रिकॉर्ड को एक विशिष्ट पहचानकर्ता देने के लिए परिभाषित किया गया है। प्राथमिक कुंजी एक पायथन शब्दकोश में कुंजी के समान है। डेटाबेस इंजन अक्सर प्राथमिक कुंजी को डेटाबेस तालिका में डाले गए प्रत्येक रिकॉर्ड के लिए वृद्धिशील पूर्णांक मान के रूप में उत्पन्न करता है।
हालांकि प्राथमिक कुंजी अक्सर डेटाबेस इंजन द्वारा स्वचालित रूप से उत्पन्न होती है, यह होना जरूरी नहीं है। यदि किसी फ़ील्ड में संग्रहीत डेटा उस फ़ील्ड में तालिका के अन्य सभी डेटा में अद्वितीय है, तो यह प्राथमिक कुंजी हो सकती है। उदाहरण के लिए, पुस्तकों के बारे में डेटा वाली तालिका प्राथमिक कुंजी के रूप में पुस्तक के ISBN का उपयोग कर सकती है।
एसक्यूएल के साथ टेबल बनाना
यहां बताया गया है कि आप SQL स्टेटमेंट का उपयोग करके CSV फ़ाइल में लेखकों, पुस्तकों और प्रकाशकों का प्रतिनिधित्व करने वाली तीन तालिकाएँ कैसे बना सकते हैं:
CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR,
last_name VARCHAR
);
CREATE TABLE book (
book_id INTEGER NOT NULL PRIMARY KEY,
author_id INTEGER REFERENCES author,
title VARCHAR
);
CREATE TABLE publisher (
publisher_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR
);
ध्यान दें कि कोई फ़ाइल संचालन नहीं है, कोई चर नहीं बनाया गया है, और उन्हें धारण करने के लिए कोई संरचना नहीं है। बयान केवल वांछित परिणाम का वर्णन करते हैं:विशेष विशेषताओं के साथ एक तालिका का निर्माण। डेटाबेस इंजन यह निर्धारित करता है कि यह कैसे करना है।
एक बार जब आप author_book_publisher.csv के लेखक डेटा के साथ इस तालिका को बना और भर देते हैं फ़ाइल, आप इसे SQL कथनों का उपयोग करके एक्सेस कर सकते हैं। निम्नलिखित कथन (जिसे क्वेरी . भी कहा जाता है) ) वाइल्डकार्ड वर्ण का उपयोग करता है (* ) author . में सभी डेटा प्राप्त करने के लिए तालिका और इसे आउटपुट करें:
SELECT * FROM author;
आप sqlite3 . का उपयोग कर सकते हैं author_book_publisher.db . के साथ इंटरैक्ट करने के लिए कमांड-लाइन टूल project/data में डेटाबेस फ़ाइल निर्देशिका:
$ sqlite3 author_book_publisher.db
एक बार जब SQLite कमांड-लाइन टूल डेटाबेस के साथ चल रहा हो, तो आप SQL कमांड दर्ज कर सकते हैं। यहाँ उपरोक्त SQL कमांड और उसका आउटपुट है, उसके बाद .q प्रोग्राम से बाहर निकलने का आदेश:
sqlite> SELECT * FROM author;
1|Isaac|Asimov
2|Pearl|Buck
3|Tom|Clancy
4|Stephen|King
5|John|Le Carre
6|Alex|Michaelides
7|Carol|Shaben
sqlite> .q
ध्यान दें कि प्रत्येक लेखक तालिका में केवल एक बार मौजूद होता है। CSV फ़ाइल के विपरीत, जिसमें कुछ लेखकों के लिए कई प्रविष्टियाँ थीं, यहाँ प्रति लेखक केवल एक अद्वितीय रिकॉर्ड आवश्यक है।
एसक्यूएल के साथ डेटाबेस को बनाए रखना
SQL नए डेटा को सम्मिलित करके और मौजूदा डेटा को अपडेट या हटाकर मौजूदा डेटाबेस और तालिकाओं के साथ काम करने के तरीके प्रदान करता है। author में एक नया लेखक डालने के लिए SQL कथन का उदाहरण यहां दिया गया है तालिका:
INSERT INTO author
(first_name, last_name)
VALUES ('Paul', 'Mendez');
यह SQL कथन 'Paul . मान सम्मिलित करता है ' और 'Mendez ' संबंधित कॉलम में first_name और last_name author . के टेबल।
ध्यान दें कि author_id कॉलम निर्दिष्ट नहीं है। चूंकि वह कॉलम प्राथमिक कुंजी है, डेटाबेस इंजन मान उत्पन्न करता है और इसे कथन निष्पादन के भाग के रूप में सम्मिलित करता है।
डेटाबेस तालिका में अभिलेखों को अद्यतन करना एक सरल प्रक्रिया है। उदाहरण के लिए, मान लीजिए कि स्टीफन किंग अपने कलम नाम रिचर्ड बैचमैन से जाना जाना चाहते थे। डेटाबेस रिकॉर्ड को अपडेट करने के लिए यहां एक SQL स्टेटमेंट दिया गया है:
UPDATE author
SET first_name = 'Richard', last_name = 'Bachman'
WHERE first_name = 'Stephen' AND last_name = 'King';
SQL कथन 'Stephen King' . के लिए एकल रिकॉर्ड का पता लगाता है सशर्त कथन का उपयोग करना WHERE first_name = 'Stephen' AND last_name = 'King' और फिर first_name . को अपडेट करता है और last_name नए मूल्यों के साथ क्षेत्र। SQL बराबर चिह्न का उपयोग करता है (= ) तुलना ऑपरेटर और असाइनमेंट ऑपरेटर दोनों के रूप में।
आप डेटाबेस से रिकॉर्ड भी हटा सकते हैं। author . से किसी रिकॉर्ड को हटाने के लिए SQL कथन का उदाहरण यहां दिया गया है तालिका:
DELETE FROM author
WHERE first_name = 'Paul'
AND last_name = 'Mendez';
यह SQL कथन author . से एक पंक्ति को हटाता है तालिका जहां first_name 'Paul' . के बराबर है और last_name 'Mendez' . के बराबर है .
रिकॉर्ड हटाते समय सावधान रहें! आपके द्वारा निर्धारित शर्तें यथासंभव विशिष्ट होनी चाहिए। एक शर्त जो बहुत व्यापक है, आपके इरादे से अधिक रिकॉर्ड हटाने का कारण बन सकती है। उदाहरण के लिए, यदि शर्त केवल first_name = 'Paul' . लाइन पर आधारित थी , तो पॉल के पहले नाम वाले सभी लेखकों को डेटाबेस से हटा दिया जाएगा।
नोट: रिकॉर्ड के आकस्मिक विलोपन से बचने के लिए, कई एप्लिकेशन विलोपन की बिल्कुल भी अनुमति नहीं देते हैं। इसके बजाय, रिकॉर्ड में यह इंगित करने के लिए एक और कॉलम है कि यह उपयोग में है या नहीं। इस कॉलम का नाम active हो सकता है और इसमें एक मान होता है जो या तो सही या गलत का मूल्यांकन करता है, यह दर्शाता है कि डेटाबेस को क्वेरी करते समय रिकॉर्ड को शामिल किया जाना चाहिए या नहीं।
उदाहरण के लिए, नीचे दी गई SQL क्वेरी some_table . में सभी सक्रिय रिकॉर्ड के लिए सभी कॉलम प्राप्त करेगी :
SELECT
*
FROM some_table
WHERE active = 1;
SQLite में बूलियन डेटा प्रकार नहीं है, इसलिए active कॉलम 0 . के मान के साथ एक पूर्णांक द्वारा दर्शाया गया है या 1 रिकॉर्ड की स्थिति को इंगित करने के लिए। अन्य डेटाबेस सिस्टम में मूल बूलियन डेटा प्रकार हो भी सकते हैं और नहीं भी।
सीधे कोड में SQL स्टेटमेंट का उपयोग करके पायथन में डेटाबेस एप्लिकेशन बनाना पूरी तरह से संभव है। ऐसा करने से एप्लिकेशन में डेटा सूचियों की सूची या शब्दकोशों की सूची के रूप में वापस आ जाता है।
डेटाबेस में क्वेरी द्वारा लौटाए गए डेटा के साथ काम करने के लिए कच्चे SQL का उपयोग करना पूरी तरह से स्वीकार्य तरीका है। हालाँकि, ऐसा करने के बजाय, आप डेटाबेस के साथ काम करने के लिए सीधे SQLAlchemy का उपयोग करने जा रहे हैं।
रिश्ते बनाना
डेटाबेस सिस्टम की एक अन्य विशेषता जो आपको डेटा दृढ़ता और पुनर्प्राप्ति से भी अधिक शक्तिशाली और उपयोगी लग सकती है, वह है रिलेशनशिप . संबंधों का समर्थन करने वाले डेटाबेस आपको डेटा को कई तालिकाओं में विभाजित करने और उनके बीच संबंध स्थापित करने की अनुमति देते हैं।
author_book_publisher.csv . में डेटा फ़ाइल डेटा को डुप्लिकेट करके डेटा और संबंधों का प्रतिनिधित्व करती है। एक डेटाबेस डेटा को तीन तालिकाओं में विभाजित करके इसे संभालता है—author , book , और publisher —और उनके बीच संबंध स्थापित करना।
सीएसवी फ़ाइल में एक ही स्थान पर सभी डेटा प्राप्त करने के बाद, आप इसे एकाधिक तालिकाओं में क्यों तोड़ना चाहेंगे? क्या इसे फिर से बनाने और वापस एक साथ रखने के लिए और अधिक काम नहीं होगा? यह एक हद तक सही है, लेकिन डेटा को तोड़ने और SQL का उपयोग करके इसे वापस एक साथ रखने के फायदे आपको जीत सकते हैं!
एक-से-अनेक संबंध
एक एक से अनेक संबंध उस ग्राहक की तरह होता है जो ऑनलाइन सामान मंगवाता है। एक ग्राहक के पास कई ऑर्डर हो सकते हैं, लेकिन प्रत्येक ऑर्डर एक ग्राहक का होता है। author_book_publisher.db डेटाबेस का लेखकों और पुस्तकों के रूप में एक-से-अनेक संबंध है। प्रत्येक लेखक कई पुस्तकें लिख सकता है, लेकिन प्रत्येक पुस्तक एक लेखक द्वारा लिखी जाती है।
जैसा कि आपने ऊपर तालिका निर्माण में देखा, इन अलग-अलग संस्थाओं का कार्यान्वयन प्रत्येक को एक डेटाबेस तालिका में रखना है, एक लेखकों के लिए और एक पुस्तकों के लिए। लेकिन इन दो तालिकाओं के बीच एक-से-कई संबंध कैसे लागू होते हैं?
याद रखें, डेटाबेस में प्रत्येक तालिका में उस तालिका के लिए प्राथमिक कुंजी के रूप में निर्दिष्ट फ़ील्ड होता है। उपरोक्त प्रत्येक तालिका में इस पैटर्न का उपयोग करके नामित प्राथमिक कुंजी फ़ील्ड है:<table name>_id ।
book ऊपर दिखाई गई तालिका में एक फ़ील्ड है, author_id , जो author . का संदर्भ देता है टेबल। author_id फ़ील्ड इस तरह दिखने वाले लेखकों और पुस्तकों के बीच एक-से-अनेक संबंध स्थापित करता है:

ऊपर दिया गया आरेख एक साधारण इकाई-संबंध आरेख (ईआरडी) है जिसे जेटब्रेन डेटाग्रिप एप्लिकेशन के साथ बनाया गया है जिसमें टेबल author दिखाया गया है। और book उनके संबंधित प्राथमिक कुंजी और डेटा फ़ील्ड वाले बॉक्स के रूप में। दो ग्राफिकल आइटम रिश्ते के बारे में जानकारी जोड़ते हैं:
-
छोटे पीले और नीले रंग के कुंजी चिह्न तालिका के लिए क्रमशः प्राथमिक और विदेशी कुंजी इंगित करें।
-
तीर जोड़ने वाला
bookauthor. के लिएauthor_id. के आधार पर तालिकाओं के बीच संबंध को इंगित करता हैbookमें विदेशी कुंजी टेबल।
जब आप book . में कोई नई पुस्तक जोड़ते हैं तालिका, डेटा में एक author_id शामिल है author . में मौजूदा लेखक के लिए मान टेबल। इस तरह, एक लेखक द्वारा लिखी गई सभी पुस्तकों का उस अद्वितीय लेखक के साथ एक लुकअप संबंध होता है।
अब जब आपके पास लेखकों और पुस्तकों के लिए अलग-अलग टेबल हैं, तो आप उनके बीच संबंधों का उपयोग कैसे करते हैं? SQL उस चीज़ का समर्थन करता है जिसे JOIN कहा जाता है ऑपरेशन, जिसका उपयोग आप डेटाबेस को यह बताने के लिए कर सकते हैं कि दो या दो से अधिक तालिकाओं को कैसे जोड़ा जाए।
नीचे दी गई SQL क्वेरी author से जुड़ती है और book SQLite कमांड-लाइन एप्लिकेशन का उपयोग करके एक साथ तालिका:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> b.title AS book_title
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Foundation
Pearl Buck|The Good Earth
Tom Clancy|The Hunt For Red October
Tom Clancy|Patriot Games
Stephen King|It
Stephen King|Dead Zone
Stephen King|The Shining
John Le Carre|Tinker, Tailor, Soldier, Spy: A George Smiley Novel
Alex Michaelides|The Silent Patient
Carol Shaben|Into The Abyss
उपरोक्त SQL क्वेरी दोनों के बीच स्थापित संबंधों का उपयोग करके तालिकाओं में शामिल होकर लेखक और पुस्तक तालिका दोनों से जानकारी एकत्र करती है। SQL स्ट्रिंग संयोजन लेखक का पूरा नाम उपनाम author_name . को निर्दिष्ट करता है . क्वेरी द्वारा एकत्र किए गए डेटा को last_name . द्वारा आरोही क्रम में क्रमबद्ध किया जाता है फ़ील्ड.
SQL कथन में ध्यान देने योग्य कुछ बातें हैं। सबसे पहले, लेखकों को उनके पूरे नामों से एक ही कॉलम में प्रस्तुत किया जाता है और उनके अंतिम नामों द्वारा क्रमबद्ध किया जाता है। साथ ही, एक-से-अनेक संबंध के कारण लेखक कई बार आउटपुट में दिखाई देते हैं। डेटाबेस में लिखी गई प्रत्येक पुस्तक के लिए एक लेखक का नाम दोहराया जाता है।
लेखकों और पुस्तकों के लिए अलग-अलग तालिकाएँ बनाकर और उनके बीच संबंध स्थापित करके, आपने डेटा में अतिरेक को कम कर दिया है। अब आपको केवल एक लेखक के डेटा को एक ही स्थान पर संपादित करना है, और वह परिवर्तन डेटा तक पहुँचने वाली किसी भी SQL क्वेरी में दिखाई देता है।
अनेक-से-अनेक संबंध
अनेक-से-अनेक author_book_publisher.db में संबंध मौजूद हैं लेखकों और प्रकाशकों के साथ-साथ पुस्तकों और प्रकाशकों के बीच डेटाबेस। एक लेखक कई प्रकाशकों के साथ काम कर सकता है, और एक प्रकाशक कई लेखकों के साथ काम कर सकता है। इसी तरह, एक किताब को कई प्रकाशक प्रकाशित कर सकते हैं, और एक प्रकाशक कई किताबें प्रकाशित कर सकता है।
डेटाबेस में इस स्थिति को संभालना एक-से-कई संबंधों की तुलना में अधिक शामिल है क्योंकि संबंध दोनों तरह से चलते हैं। Many-to-many relationships are created by an association table acting as a bridge between the two related tables.
The association table contains at least two foreign key fields, which are the primary keys of each of the two associated tables. This SQL statement creates the association table relating the author and publisher tables:
CREATE TABLE author_publisher (
author_id INTEGER REFERENCES author,
publisher_id INTEGER REFERENCES publisher
);
The SQL statements create a new author_publisher table referencing the primary keys of the existing author and publisher tables. The author_publisher table is an association table establishing relationships between an author and a publisher.
Because the relationship is between two primary keys, there’s no need to create a primary key for the association table itself. The combination of the two related keys creates a unique identifier for a row of data.
As before, you use the JOIN keyword to connect two tables together. Connecting the author table to the publisher table is a two-step process:
JOINtheauthortable with theauthor_publisherटेबल।JOINtheauthor_publishertable with thepublishertable.
The author_publisher association table provides the bridge through which the JOIN connects the two tables. Here’s an example SQL query returning a list of authors and the publishers publishing their books:
1sqlite> SELECT
2 ...> a.first_name || ' ' || a.last_name AS author_name,
3 ...> p.name AS publisher_name
4 ...> FROM author a
5 ...> JOIN author_publisher ap ON ap.author_id = a.author_id
6 ...> JOIN publisher p ON p.publisher_id = ap.publisher_id
7 ...> ORDER BY a.last_name ASC;
8Isaac Asimov|Random House
9Pearl Buck|Random House
10Pearl Buck|Simon & Schuster
11Tom Clancy|Berkley
12Tom Clancy|Simon & Schuster
13Stephen King|Random House
14Stephen King|Penguin Random House
15John Le Carre|Berkley
16Alex Michaelides|Simon & Schuster
17Carol Shaben|Simon & Schuster
The statements above perform the following actions:
-
Line 1 starts a
SELECTstatement to get data from the database. -
Line 2 selects the first and last name from the
authortable using theaalias for theauthortable and concatenates them together with a space character. -
Line 3 selects the publisher’s name aliased to
publisher_name। -
Line 4 uses the
authortable as the first source from which to retrieve data and assigns it to the aliasa। -
Line 5 is the first step of the process outlined above for connecting the
authortable to thepublisherटेबल। It uses the aliasapfor theauthor_publisherassociation table and performs aJOINoperation to connect theap.author_idforeign key reference to thea.author_idprimary key in theauthortable. -
Line 6 is the second step in the two-step process mentioned above. It uses the alias
pfor thepublishertable and performs aJOINoperation to relate theap.publisher_idforeign key reference to thep.publisher_idprimary key in thepublishertable. -
Line 7 sorts the data by the author’s last name in ascending alphabetical order and ends the SQL query.
-
Lines 8 to 17 are the output of the SQL query.
Note that the data in the source author and publisher tables are normalized, with no data duplication. Yet the returned results have duplicated data where necessary to answer the SQL query.
The SQL query above demonstrates how to make use of a relationship using the SQL JOIN keyword, but the resulting data is a partial re-creation of the author_book_publisher.csv CSV data. What’s the win for having done the work of creating a database to separate the data?
Here’s another SQL query to show a little bit of the power of SQL and the database engine:
1sqlite> SELECT
2 ...> a.first_name || ' ' || a.last_name AS author_name,
3 ...> COUNT(b.title) AS total_books
4 ...> FROM author a
5 ...> JOIN book b ON b.author_id = a.author_id
6 ...> GROUP BY author_name
7 ...> ORDER BY total_books DESC, a.last_name ASC;
8Stephen King|3
9Tom Clancy|2
10Isaac Asimov|1
11Pearl Buck|1
12John Le Carre|1
13Alex Michaelides|1
14Carol Shaben|1
The SQL query above returns the list of authors and the number of books they’ve written. The list is sorted first by the number of books in descending order, then by the author’s name in alphabetical order:
-
Line 1 begins the SQL query with the
SELECTkeyword. -
Line 2 selects the author’s first and last names, separated by a space character, and creates the alias
author_name। -
Line 3 counts the number of books written by each author, which will be used later by the
ORDER BYclause to sort the list. -
Line 4 selects the
authortable to get data from and creates theaalias. -
Line 5 connects to the related
booktable through aJOINto theauthor_idand creates thebalias for thebooktable. -
Line 6 generates the aggregated author and total number of books data by using the
GROUP BYkeyword.GROUP BYis what groups eachauthor_nameand controls what books are tallied byCOUNT()for that author. -
Line 7 sorts the output first by number of books in descending order, then by the author’s last name in ascending alphabetical order.
-
Lines 8 to 14 are the output of the SQL query.
In the above example, you take advantage of SQL to perform aggregation calculations and sort the results into a useful order. Having the database perform calculations based on its built-in data organization ability is usually faster than performing the same kinds of calculations on raw data sets in Python. SQL offers the advantages of using set theory embedded in RDBMS databases.
Entity Relationship Diagrams
An entity-relationship diagram (ERD) is a visual depiction of an entity-relationship model for a database or part of a database. The author_book_publisher.db SQLite database is small enough that the entire database can be visualized by the diagram shown below:

This diagram presents the table structures in the database and the relationships between them. Each box represents a table and contains the fields defined in the table, with the primary key indicated first if it exists.
The arrows show the relationships between the tables connecting a foreign key field in one table to a field, often the primary key, in another table. The table book_publisher has two arrows, one connecting it to the book table and another connecting it to the publisher टेबल। The arrow indicates the many-to-many relationship between the book and publisher tables. The author_publisher table provides the same relationship between author and publisher ।
Working With SQLAlchemy and Python Objects
SQLAlchemy is a powerful database access tool kit for Python, with its object-relational mapper (ORM) being one of its most famous components, and the one discussed and used here.
When you’re working in an object-oriented language like Python, it’s often useful to think in terms of objects. It’s possible to map the results returned by SQL queries to objects, but doing so works against the grain of how the database works. Sticking with the scalar results provided by SQL works against the grain of how Python developers work. This problem is known as object-relational impedance mismatch.
The ORM provided by SQLAlchemy sits between the SQLite database and your Python program and transforms the data flow between the database engine and Python objects. SQLAlchemy allows you to think in terms of objects and still retain the powerful features of a database engine.
The Model
One of the fundamental elements to enable connecting SQLAlchemy to a database is creating a model . The model is a Python class defining the data mapping between the Python objects returned as a result of a database query and the underlying database tables.
The entity-relationship diagram displayed earlier shows boxes connected with arrows. The boxes are the tables built with the SQL commands and are what the Python classes will model. The arrows are the relationships between the tables.
The models are Python classes inheriting from an SQLAlchemy Base कक्षा। The Base class provides the interface operations between instances of the model and the database table.
Below is the models.py file that creates the models to represent the author_book_publisher.db database:
1from sqlalchemy import Column, Integer, String, ForeignKey, Table
2from sqlalchemy.orm import relationship, backref
3from sqlalchemy.ext.declarative import declarative_base
4
5Base = declarative_base()
6
7author_publisher = Table(
8 "author_publisher",
9 Base.metadata,
10 Column("author_id", Integer, ForeignKey("author.author_id")),
11 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
12)
13
14book_publisher = Table(
15 "book_publisher",
16 Base.metadata,
17 Column("book_id", Integer, ForeignKey("book.book_id")),
18 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
19)
20
21class Author(Base):
22 __tablename__ = "author"
23 author_id = Column(Integer, primary_key=True)
24 first_name = Column(String)
25 last_name = Column(String)
26 books = relationship("Book", backref=backref("author"))
27 publishers = relationship(
28 "Publisher", secondary=author_publisher, back_populates="authors"
29 )
30
31class Book(Base):
32 __tablename__ = "book"
33 book_id = Column(Integer, primary_key=True)
34 author_id = Column(Integer, ForeignKey("author.author_id"))
35 title = Column(String)
36 publishers = relationship(
37 "Publisher", secondary=book_publisher, back_populates="books"
38 )
39
40class Publisher(Base):
41 __tablename__ = "publisher"
42 publisher_id = Column(Integer, primary_key=True)
43 name = Column(String)
44 authors = relationship(
45 "Author", secondary=author_publisher, back_populates="publishers"
46 )
47 books = relationship(
48 "Book", secondary=book_publisher, back_populates="publishers"
49 )
Here’s what’s going on in this module:
-
Line 1 imports the
Column,Integer,String,ForeignKey, andTableclasses from SQLAlchemy, which are used to help define the model attributes. -
Line 2 imports the
relationship()andbackrefobjects, which are used to create the relationships between objects. -
Line 3 imports the
declarative_baseobject, which connects the database engine to the SQLAlchemy functionality of the models. -
Line 5 creates the
Baseclass, which is what all models inherit from and how they get SQLAlchemy ORM functionality. -
Lines 7 to 12 create the
author_publisherassociation table model. -
Lines 14 to 19 create the
book_publisherassociation table model. -
Lines 21 to 29 define the
Authorclass model to theauthordatabase table. -
Lines 31 to 38 define the
Bookclass model to thebookdatabase table. -
Lines 40 to 49 define the
Publisherclass model to thepublisherdatabase table.
The description above shows the mapping of the five tables in the author_book_publisher.db डेटाबेस। But it glosses over some SQLAlchemy ORM features, including Table , ForeignKey , relationship() , and backref . Let’s get into those now.
Table Creates Associations
author_publisher and book_publisher are both instances of the Table class that create the many-to-many association tables used between the author and publisher tables and the book and publisher tables, respectively.
The SQLAlchemy Table class creates a unique instance of an ORM mapped table within the database. The first parameter is the table name as defined in the database, and the second is Base.metadata , which provides the connection between the SQLAlchemy functionality and the database engine.
The rest of the parameters are instances of the Column class defining the table fields by name, their type, and in the example above, an instance of a ForeignKey ।
ForeignKey Creates a Connection
The SQLAlchemy ForeignKey class defines a dependency between two Column fields in different tables. A ForeignKey is how you make SQLAlchemy aware of the relationships between tables. For example, this line from the author_publisher instance creation establishes a foreign key relationship:
Column("author_id", Integer, ForeignKey("author.author_id"))
The statement above tells SQLAlchemy that there’s a column in the author_publisher table named author_id . The type of that column is Integer , and author_id is a foreign key related to the primary key in the author table.
Having both author_id and publisher_id defined in the author_publisher Table instance creates the connection from the author table to the publisher table and vice versa, establishing a many-to-many relationship.
relationship() Establishes a Collection
Having a ForeignKey defines the existence of the relationship between tables but not the collection of books an author can have. Take a look at this line in the Author class definition:
books = relationship("Book", backref=backref("author"))
The code above defines a parent-child collection. The books attribute being plural (which is not a requirement, just a convention) is an indication that it’s a collection.
The first parameter to relationship() , the class name Book (which is not the table name book ), is the class to which the books attribute is related. The relationship informs SQLAlchemy that there’s a relationship between the Author and Book classes. SQLAlchemy will find the relationship in the Book class definition:
author_id = Column(Integer, ForeignKey("author.author_id"))
SQLAlchemy recognizes that this is the ForeignKey connection point between the two classes. You’ll get to the backref parameter in relationship() in a moment.
The other relationship in Author is to the Publisher कक्षा। This is created with the following statement in the Author class definition:
publishers = relationship(
"Publisher", secondary=author_publisher, back_populates="authors"
)
Like books , the attribute publishers indicates a collection of publishers associated with an author. The first parameter, "Publisher" , informs SQLAlchemy what the related class is. The second and third parameters are secondary=author_publisher and back_populates="authors" :
-
secondarytells SQLAlchemy that the relationship to thePublisherclass is through a secondary table, which is theauthor_publisherassociation table created earlier inmodels.py. Thesecondaryparameter makes SQLAlchemy find thepublisher_idForeignKeydefined in theauthor_publisherassociation table. -
back_populatesis a convenience configuration telling SQLAlchemy that there’s a complementary collection in thePublisherclass calledauthors।
backref Mirrors Attributes
The backref parameter of the books collection relationship() creates an author attribute for each Book उदाहरण। This attribute refers to the parent Author that the Book instance is related to.
For example, if you executed the following Python code, then a Book instance would be returned from the SQLAlchemy query. The Book instance has attributes that can be used to print out information about the book:
book = session.query(Book).filter_by(Book.title == "The Stand").one_or_none()
print(f"Authors name: {book.author.first_name} {book.author.last_name}")
The existence of the author attribute in the Book above is because of the backref definition. A backref can be very handy to have when you need to refer to the parent and all you have is a child instance.
Queries Answer Questions
You can make a basic query like SELECT * FROM author; in SQLAlchemy like this:
results = session.query(Author).all()
The session is an SQLAlchemy object used to communicate with SQLite in the Python example programs. Here, you tell the session you want to execute a query against the Author model and return all records.
At this point, the advantages of using SQLAlchemy instead of plain SQL might not be obvious, especially considering the setup required to create the models representing the database. The results returned by the query is where the magic happens. Instead of getting back a list of lists of scalar data, you’ll get back a list of instances of Author objects with attributes matching the column names you defined.
The books and publishers collections maintained by SQLAlchemy create a hierarchical list of authors and the books they’ve written as well as the publishers who’ve published them.
Behind the scenes, SQLAlchemy turns the object and method calls into SQL statements to execute against the SQLite database engine. SQLAlchemy transforms the data returned by SQL queries into Python objects.
With SQLAlchemy, you can perform the more complex aggregation query shown earlier for the list of authors and the number of books they’ve written like this:
author_book_totals = (
session.query(
Author.first_name,
Author.last_name,
func.count(Book.title).label("book_total")
)
.join(Book)
.group_by(Author.last_name)
.order_by(desc("book_total"))
.all()
)
The query above gets the author’s first and last name, along with a count of the number of books that the author has written. The aggregating count used by the group_by clause is based on the author’s last name. Finally, the results are sorted in descending order based on the aggregated and aliased book_total ।
Example Program
The example program examples/example_2/main.py has the same functionality as examples/example_1/main.py but uses SQLAlchemy exclusively to interface with the author_book_publisher.db SQLite database. The program is broken up into the main() function and the functions it calls:
1def main():
2 """Main entry point of program"""
3 # Connect to the database using SQLAlchemy
4 with resources.path(
5 "project.data", "author_book_publisher.db"
6 ) as sqlite_filepath:
7 engine = create_engine(f"sqlite:///{sqlite_filepath}")
8 Session = sessionmaker()
9 Session.configure(bind=engine)
10 session = Session()
11
12 # Get the number of books printed by each publisher
13 books_by_publisher = get_books_by_publishers(session, ascending=False)
14 for row in books_by_publisher:
15 print(f"Publisher: {row.name}, total books: {row.total_books}")
16 print()
17
18 # Get the number of authors each publisher publishes
19 authors_by_publisher = get_authors_by_publishers(session)
20 for row in authors_by_publisher:
21 print(f"Publisher: {row.name}, total authors: {row.total_authors}")
22 print()
23
24 # Output hierarchical author data
25 authors = get_authors(session)
26 output_author_hierarchy(authors)
27
28 # Add a new book
29 add_new_book(
30 session,
31 author_name="Stephen King",
32 book_title="The Stand",
33 publisher_name="Random House",
34 )
35 # Output the updated hierarchical author data
36 authors = get_authors(session)
37 output_author_hierarchy(authors)
This program is a modified version of examples/example_1/main.py . Let’s go over the differences:
-
Lines 4 to 7 first initialize the
sqlite_filepathvariable to the database file path. Then they create theenginevariable to communicate with SQLite and theauthor_book_publisher.dbdatabase file, which is SQLAlchemy’s access point to the database. -
Line 8 creates the
Sessionclass from the SQLAlchemy’ssessionmaker()। -
Line 9 binds the
Sessionto the engine created in line 8. -
Line 10 creates the
sessioninstance, which is used by the program to communicate with SQLAlchemy.
The rest of the function is similar, except for the replacement of data with session as the first parameter to all the functions called by main() ।
get_books_by_publisher() has been refactored to use SQLAlchemy and the models you defined earlier to get the data requested:
1def get_books_by_publishers(session, ascending=True):
2 """Get a list of publishers and the number of books they've published"""
3 if not isinstance(ascending, bool):
4 raise ValueError(f"Sorting value invalid: {ascending}")
5
6 direction = asc if ascending else desc
7
8 return (
9 session.query(
10 Publisher.name, func.count(Book.title).label("total_books")
11 )
12 .join(Publisher.books)
13 .group_by(Publisher.name)
14 .order_by(direction("total_books"))
15 )
Here’s what the new function, get_books_by_publishers() , is doing:
-
Line 6 creates the
directionvariable and sets it equal to the SQLAlchemydescorascfunction depending on the value of theascendingपैरामीटर। -
Lines 9 to 11 query the
Publishertable for data to return, which in this case arePublisher.nameand the aggregate total ofBookobjects associated with an author, aliased tototal_books। -
Line 12 joins to the
Publisher.booksसंग्रह। -
Line 13 aggregates the book counts by the
Publisher.nameattribute. -
Line 14 sorts the output by the book counts according to the operator defined by
direction। -
Line 15 closes the object, executes the query, and returns the results to the caller.
All the above code expresses what is wanted rather than how it’s to be retrieved. Now instead of using SQL to describe what’s wanted, you’re using Python objects and methods. What’s returned is a list of Python objects instead of a list of tuples of data.
get_authors_by_publisher() has also been modified to work exclusively with SQLAlchemy. Its functionality is very similar to the previous function, so a function description is omitted:
def get_authors_by_publishers(session, ascending=True):
"""Get a list of publishers and the number of authors they've published"""
if not isinstance(ascending, bool):
raise ValueError(f"Sorting value invalid: {ascending}")
direction = asc if ascending else desc
return (
session.query(
Publisher.name,
func.count(Author.first_name).label("total_authors"),
)
.join(Publisher.authors)
.group_by(Publisher.name)
.order_by(direction("total_authors"))
)
get_authors() has been added to get a list of authors sorted by their last names. The result of this query is a list of Author objects containing a collection of books. The Author objects already contain hierarchical data, so the results don’t have to be reformatted:
def get_authors(session):
"""Get a list of author objects sorted by last name"""
return session.query(Author).order_by(Author.last_name).all()
Like its previous version, add_new_book() is relatively complex but straightforward to understand. It determines if a book with the same title, author, and publisher exists in the database already.
If the search query finds an exact match, then the function returns. If no book matches the exact search criteria, then it searches to see if the author has written a book using the passed in title. This code exists to prevent duplicate books from being created in the database.
If no matching book exists, and the author hasn’t written one with the same title, then a new book is created. The function then retrieves or creates an author and publisher. Once instances of the Book , Author and Publisher exist, the relationships between them are created, and the resulting information is saved to the database:
1def add_new_book(session, author_name, book_title, publisher_name):
2 """Adds a new book to the system"""
3 # Get the author's first and last names
4 first_name, _, last_name = author_name.partition(" ")
5
6 # Check if book exists
7 book = (
8 session.query(Book)
9 .join(Author)
10 .filter(Book.title == book_title)
11 .filter(
12 and_(
13 Author.first_name == first_name, Author.last_name == last_name
14 )
15 )
16 .filter(Book.publishers.any(Publisher.name == publisher_name))
17 .one_or_none()
18 )
19 # Does the book by the author and publisher already exist?
20 if book is not None:
21 return
22
23 # Get the book by the author
24 book = (
25 session.query(Book)
26 .join(Author)
27 .filter(Book.title == book_title)
28 .filter(
29 and_(
30 Author.first_name == first_name, Author.last_name == last_name
31 )
32 )
33 .one_or_none()
34 )
35 # Create the new book if needed
36 if book is None:
37 book = Book(title=book_title)
38
39 # Get the author
40 author = (
41 session.query(Author)
42 .filter(
43 and_(
44 Author.first_name == first_name, Author.last_name == last_name
45 )
46 )
47 .one_or_none()
48 )
49 # Do we need to create the author?
50 if author is None:
51 author = Author(first_name=first_name, last_name=last_name)
52 session.add(author)
53
54 # Get the publisher
55 publisher = (
56 session.query(Publisher)
57 .filter(Publisher.name == publisher_name)
58 .one_or_none()
59 )
60 # Do we need to create the publisher?
61 if publisher is None:
62 publisher = Publisher(name=publisher_name)
63 session.add(publisher)
64
65 # Initialize the book relationships
66 book.author = author
67 book.publishers.append(publisher)
68 session.add(book)
69
70 # Commit to the database
71 session.commit()
The code above is relatively long. Let’s break the functionality down to manageable sections:
-
Lines 7 to 18 set the
bookvariable to an instance of aBookif a book with the same title, author, and publisher is found. Otherwise, they setbooktoNone। -
Lines 20 and 21 determine if the book already exists and return if it does.
-
Lines 24 to 37 set the
bookvariable to an instance of aBookif a book with the same title and author is found. Otherwise, they create a newBookउदाहरण। -
Lines 40 to 52 set the
authorvariable to an existing author, if found, or create a newAuthorinstance based on the passed-in author name. -
Lines 55 to 63 set the
publishervariable to an existing publisher, if found, or create a newPublisherinstance based on the passed-in publisher name. -
Line 66 sets the
book.authorinstance to theauthorउदाहरण। This creates the relationship between the author and the book, which SQLAlchemy will create in the database when the session is committed. -
Line 67 adds the
publisherinstance to thebook.publishersसंग्रह। This creates the many-to-many relationship between thebookandpublishertables. SQLAlchemy will create references in the tables as well as in thebook_publisherassociation table that connects the two. -
Line 68 adds the
Bookinstance to the session, making it part of the session’s unit of work. -
Line 71 commits all the creations and updates to the database.
There are a few things to take note of here. First, there’s is no mention of the author_publisher or book_publisher association tables in either the queries or the creations and updates. Because of the work you did in models.py setting up the relationships, SQLAlchemy can handle connecting objects together and keeping those tables in sync during creations and updates.
Second, all the creations and updates happen within the context of the session वस्तु। None of that activity is touching the database. Only when the session.commit() statement executes does the session then go through its unit of work and commit that work to the database.
For example, if a new Book instance is created (as in line 37 above), then the book has its attributes initialized except for the book_id primary key and author_id foreign key. Because no database activity has happened yet, the book_id is unknown, and nothing was done in the instantiation of book to give it an author_id ।
When session.commit() is executed, one of the things it will do is insert book into the database, at which point the database will create the book_id primary key. The session will then initialize the book.book_id value with the primary key value created by the database engine.
session.commit() is also aware of the insertion of the Book instance in the author.books संग्रह। The author object’s author_id primary key will be added to the Book instance appended to the author.books collection as the author_id foreign key.
Providing Access to Multiple Users
To this point, you’ve seen how to use pandas, SQLite, and SQLAlchemy to access the same data in different ways. For the relatively straightforward use case of the author, book, and publisher data, it could still be a toss-up whether you should use a database.
One deciding factor when choosing between using a flat file or a database is data and relationship complexity. If the data for each entity is complicated and contains many relationships between the entities, then creating and maintaining it in a flat file might become more difficult.
Another factor to consider is whether you want to share the data between multiple users. The solution to this problem might be as simple as using a sneakernet to physically move data between users. Moving data files around this way has the advantage of ease of use, but the data can quickly get out of sync when changes are made.
The problem of keeping the data consistent for all users becomes even more difficult if the users are remote and want to access the data across networks. Even when you’re limited to a single language like Python and using pandas to access the data, network file locking isn’t sufficient to ensure the data doesn’t get corrupted.
Providing the data through a server application and a user interface alleviates this problem. The server is the only application that needs file-level access to the database. By using a database, the server can take advantage of SQL to access the data using a consistent interface no matter what programming language the server uses.
The last example program demonstrates this by providing a web application and user interface to the Chinook sample SQLite database. Peter Stark generously maintains the Chinook database as part of the SQLite Tutorial site. If you’d like to learn more about SQLite and SQL in general, then the site is a great resource.
The Chinook database provides artist, music, and playlist information along the lines of a simplified Spotify. The database is part of the example code project in the project/data folder.
Using Flask With Python, SQLite, and SQLAlchemy
The examples/example_3/chinook_server.py program creates a Flask application that you can interact with using a browser. The application makes use of the following technologies:
-
Flask Blueprint is part of Flask and provides a good way to follow the separation of concerns design principle and create distinct modules to contain functionality.
-
Flask SQLAlchemy is an extension for Flask that adds support for SQLAlchemy in your web applications.
-
Flask_Bootstrap4 packages the Bootstrap front-end tool kit, integrating it with your Flask web applications.
-
Flask_WTF extends Flask with WTForms, giving your web applications a useful way to generate and validate web forms.
-
python_dotenv is a Python module that an application uses to read environment variables from a file and keep sensitive information out of program code.
Though not necessary for this example, a .env file holds the environment variables for the application. The .env file exists to contain sensitive information like passwords, which you should keep out of your code files. However, the content of the project .env file is shown below since it doesn’t contain any sensitive data:
SECRET_KEY = "you-will-never-guess"
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLAlCHEMY_ECHO = False
DEBUG = True
The example application is fairly large, and only some of it is relevant to this tutorial. For this reason, examining and learning from the code is left as an exercise for the reader. That said, you can take a look at an animated screen capture of the application below, followed by the HTML that renders the home page and the Python Flask route that provides the dynamic data.
Here’s the application in action, navigating through various menus and features:
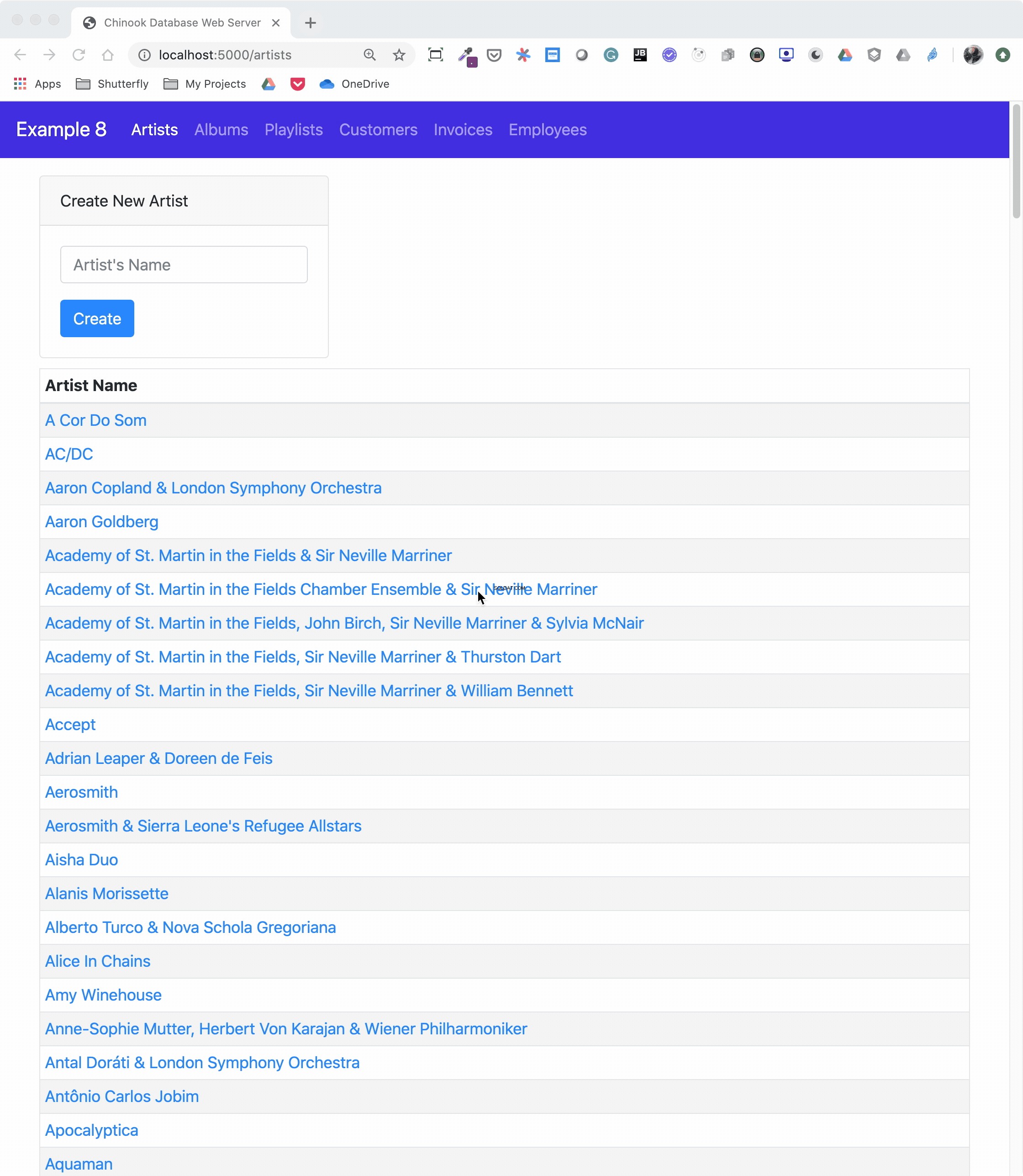
The animated screen capture starts on the application home page, styled using Bootstrap 4. The page displays the artists in the database, sorted in ascending order. The remainder of the screen capture presents the results of clicking on the displayed links or navigating around the application from the top-level menu.
Here’s the Jinja2 HTML template that generates the home page of the application:
1{% extends "base.html" %}
2
3{% block content %}
4<div class="container-fluid">
5 <div class="m-4">
6 <div class="card" style="width: 18rem;">
7 <div class="card-header">Create New Artist</div>
8 <div class="card-body">
9 <form method="POST" action="{{url_for('artists_bp.artists')}}">
10 {{ form.csrf_token }}
11 {{ render_field(form.name, placeholder=form.name.label.text) }}
12 <button type="submit" class="btn btn-primary">Create</button>
13 </form>
14 </div>
15 </div>
16 <table class="table table-striped table-bordered table-hover table-sm">
17 <caption>List of Artists</caption>
18 <thead>
19 <tr>
20 <th>Artist Name</th>
21 </tr>
22 </thead>
23 <tbody>
24 {% for artist in artists %}
25 <tr>
26 <td>
27 <a href="{{url_for('albums_bp.albums', artist_id=artist.artist_id)}}">
28 {{ artist.name }}
29 </a>
30 </td>
31 </tr>
32 {% endfor %}
33 </tbody>
34 </table>
35 </div>
36</div>
37{% endblock %}
Here’s what’s going on in this Jinja2 template code:
-
Line 1 uses Jinja2 template inheritance to build this template from the
base.htmltemplate. Thebase.htmltemplate contains all the HTML5 boilerplate code as well as the Bootstrap navigation bar consistent across all pages of the site. -
Lines 3 to 37 contain the block content of the page, which is incorporated into the Jinja2 macro of the same name in the
base.htmlbase template. -
Lines 9 to 13 render the form to create a new artist. This uses the features of Flask-WTF to generate the form.
-
Lines 24 to 32 create a
forloop that renders the table of artist names. -
Lines 27 to 29 render the artist name as a link to the artist’s album page showing the songs associated with a particular artist.
Here’s the Python route that renders the page:
1from flask import Blueprint, render_template, redirect, url_for
2from flask_wtf import FlaskForm
3from wtforms import StringField
4from wtforms.validators import InputRequired, ValidationError
5from app import db
6from app.models import Artist
7
8# Set up the blueprint
9artists_bp = Blueprint(
10 "artists_bp", __name__, template_folder="templates", static_folder="static"
11)
12
13def does_artist_exist(form, field):
14 artist = (
15 db.session.query(Artist)
16 .filter(Artist.name == field.data)
17 .one_or_none()
18 )
19 if artist is not None:
20 raise ValidationError("Artist already exists", field.data)
21
22class CreateArtistForm(FlaskForm):
23 name = StringField(
24 label="Artist's Name", validators=[InputRequired(), does_artist_exist]
25 )
26
27@artists_bp.route("/")
28@artists_bp.route("/artists", methods=["GET", "POST"])
29def artists():
30 form = CreateArtistForm()
31
32 # Is the form valid?
33 if form.validate_on_submit():
34 # Create new artist
35 artist = Artist(name=form.name.data)
36 db.session.add(artist)
37 db.session.commit()
38 return redirect(url_for("artists_bp.artists"))
39
40 artists = db.session.query(Artist).order_by(Artist.name).all()
41 return render_template("artists.html", artists=artists, form=form,)
Let’s go over what the above code is doing:
-
Lines 1 to 6 import all the modules necessary to render the page and initialize forms with data from the database.
-
Lines 9 to 11 create the blueprint for the artists page.
-
Lines 13 to 20 create a custom validator function for the Flask-WTF forms to make sure a request to create a new artist doesn’t conflict with an already existing artist.
-
Lines 22 to 25 create the form class to handle the artist form rendered in the browser and provide validation of the form field inputs.
-
Lines 27 to 28 connect two routes to the
artists()function they decorate. -
Line 30 creates an instance of the
CreateArtistForm()कक्षा। -
Line 33 determines if the page was requested through the HTTP methods GET or POST (submit). If it was a POST, then it also validates the fields of the form and informs the user if the fields are invalid.
-
Lines 35 to 37 create a new artist object, add it to the SQLAlchemy session, and commit the artist object to the database, persisting it.
-
Line 38 redirects back to the artists page, which will be rerendered with the newly created artist.
-
Line 40 runs an SQLAlchemy query to get all the artists in the database and sort them by
Artist.name। -
Line 41 renders the artists page if the HTTP request method was a GET.
You can see that a great deal of functionality is created by a reasonably small amount of code.
Creating a REST API Server
You can also create a web server providing a REST API. This kind of server offers URL endpoints responding with data, often in JSON format. A server providing REST API endpoints can be used by JavaScript single-page web applications through the use of AJAX HTTP requests.
Flask is an excellent tool for creating REST applications. For a multi-part series of tutorials about using Flask, Connexion, and SQLAlchemy to create REST applications, check out Python REST APIs With Flask, Connexion, and SQLAlchemy.
If you’re a fan of Django and are interested in creating REST APIs, then check out Django Rest Framework – An Introduction and Create a Super Basic REST API with Django Tastypie.
नोट: It’s reasonable to ask if SQLite is the right choice as the database backend to a web application. The SQLite website states that SQLite is a good choice for sites that serve around 100,000 hits per day. If your site gets more daily hits, the first thing to say is congratulations!
Beyond that, if you’ve implemented your website with SQLAlchemy, then it’s possible to move the data from SQLite to another database such as MySQL or PostgreSQL. For a comparison of SQLite, MySQL, and PostgreSQL that will help you make decisions about which one will serve your application best, check out Introduction to Python SQL Libraries.
It’s well worth considering SQLite for your Python application, no matter what it is. Using a database gives your application versatility, and it might create surprising opportunities to add additional features.
Conclusion
You’ve covered a lot of ground in this tutorial about databases, SQLite, SQL, and SQLAlchemy! You’ve used these tools to move data contained in flat files to an SQLite database, access the data with SQL and SQLAlchemy, and provide that data through a web server.
In this tutorial, you’ve learned:
- Why an SQLite database can be a compelling alternative to flat-file data storage
- How to normalize data to reduce data redundancy and increase data integrity
- How to use SQLAlchemy to work with databases in an object-oriented manner
- How to build a web application to serve a database to multiple users
Working with databases is a powerful abstraction for working with data that adds significant functionality to your Python programs and allows you to ask interesting questions of your data.
You can get all of the code and data you saw in this tutorial at the link below:
Download the sample code: Click here to get the code you’ll use to learn about data management with SQLite and SQLAlchemy in this tutorial.
Further Reading
This tutorial is an introduction to using databases, SQL, and SQLAlchemy, but there’s much more to learn about these subjects. These are powerful, sophisticated tools that no single tutorial can cover adequately. Here are some resources for additional information to expand your skills:
-
If your application will expose the database to users, then avoiding SQL injection attacks is an important skill. For more information, check out Preventing SQL Injection Attacks With Python.
-
Providing web access to a database is common in web-based single-page applications. To learn how, check out Python REST APIs With Flask, Connexion, and SQLAlchemy – Part 2.
-
Preparing for data engineering job interviews gives you a leg up in your career. To get started, check out Data Engineer Interview Questions With Python.
-
Migrating data and being able to roll back using Flask with Postgres and SQLAlchemy is an integral part of the Software Development Life Cycle (SDLC). You can learn more about it by checking out Flask by Example – Setting up Postgres, SQLAlchemy, and Alembic.