आइए 600 डेटासेट, 45k cfiles के साथ postgresl 13 पर परीक्षण डेटा बनाएं।
BEGIN;
CREATE TABLE cfiles (
id SERIAL PRIMARY KEY,
dataset_id INTEGER NOT NULL,
property_values jsonb NOT NULL);
INSERT INTO cfiles (dataset_id,property_values)
SELECT 1+(random()*600)::INTEGER AS did,
('{"Sample Names": ["'||array_to_string(array_agg(DISTINCT prop),'","')||'"]}')::jsonb prop
FROM (
SELECT 1+(random()*45000)::INTEGER AS cid,
'Samp'||(power(random(),2)*30)::INTEGER AS prop
FROM generate_series(1,45000*4)) foo
GROUP BY cid;
COMMIT;
CREATE TABLE datasets ( id INTEGER PRIMARY KEY, name TEXT NOT NULL );
INSERT INTO datasets SELECT n, 'dataset'||n FROM (SELECT DISTINCT dataset_id n FROM cfiles) foo;
CREATE INDEX cfiles_dataset ON cfiles(dataset_id);
VACUUM ANALYZE cfiles;
VACUUM ANALYZE datasets;
आपकी मूल क्वेरी यहां बहुत तेज़ है, लेकिन ऐसा शायद इसलिए है क्योंकि पोस्टग्रेज़ 13 अधिक स्मार्ट है।
Sort (cost=114127.87..114129.37 rows=601 width=46) (actual time=658.943..659.012 rows=601 loops=1)
Sort Key: datasets.name
Sort Method: quicksort Memory: 334kB
-> GroupAggregate (cost=0.57..114100.13 rows=601 width=46) (actual time=13.954..655.916 rows=601 loops=1)
Group Key: datasets.id
-> Nested Loop (cost=0.57..92009.62 rows=4416600 width=46) (actual time=13.373..360.991 rows=163540 loops=1)
-> Merge Join (cost=0.56..3677.61 rows=44166 width=78) (actual time=13.350..113.567 rows=44166 loops=1)
Merge Cond: (cfiles.dataset_id = datasets.id)
-> Index Scan using cfiles_dataset on cfiles (cost=0.29..3078.75 rows=44166 width=68) (actual time=0.015..69.098 rows=44166 loops=1)
-> Index Scan using datasets_pkey on datasets (cost=0.28..45.29 rows=601 width=14) (actual time=0.024..0.580 rows=601 loops=1)
-> Function Scan on jsonb_array_elements_text sn (cost=0.01..1.00 rows=100 width=32) (actual time=0.003..0.004 rows=4 loops=44166)
Execution Time: 661.978 ms
यह क्वेरी पहले एक बड़ी तालिका (cfiles) पढ़ती है और एकत्रीकरण के कारण बहुत कम पंक्तियाँ उत्पन्न करती है। इस प्रकार शामिल होने के लिए पंक्तियों की संख्या कम होने के बाद डेटासेट के साथ जुड़ना तेज़ होगा, पहले नहीं। चलो चलते हैं जो जुड़ते हैं। इसके अलावा मैंने क्रॉस जॉइन से छुटकारा पा लिया जो अनावश्यक है, जब एक सेलेक्ट पोस्टग्रेज में एक सेट-रिटर्निंग फ़ंक्शन होता है जो आप मुफ्त में चाहते हैं।
SELECT dataset_id, d.name, sample_names FROM (
SELECT dataset_id, string_agg(sn, '; ') as sample_names FROM (
SELECT DISTINCT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM cfiles
) f GROUP BY dataset_id
)g JOIN datasets d ON (d.id=g.dataset_id)
ORDER BY d.name;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=536207.44..536207.94 rows=200 width=46) (actual time=264.435..264.502 rows=601 loops=1)
Sort Key: d.name
Sort Method: quicksort Memory: 334kB
-> Hash Join (cost=536188.20..536199.79 rows=200 width=46) (actual time=261.404..261.784 rows=601 loops=1)
Hash Cond: (d.id = cfiles.dataset_id)
-> Seq Scan on datasets d (cost=0.00..10.01 rows=601 width=14) (actual time=0.025..0.124 rows=601 loops=1)
-> Hash (cost=536185.70..536185.70 rows=200 width=36) (actual time=261.361..261.363 rows=601 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 170kB
-> HashAggregate (cost=536181.20..536183.70 rows=200 width=36) (actual time=260.805..261.054 rows=601 loops=1)
Group Key: cfiles.dataset_id
Batches: 1 Memory Usage: 1081kB
-> HashAggregate (cost=409982.82..507586.70 rows=1906300 width=36) (actual time=244.419..253.094 rows=18547 loops=1)
Group Key: cfiles.dataset_id, jsonb_array_elements_text((cfiles.property_values -> 'Sample Names'::text))
Planned Partitions: 4 Batches: 1 Memory Usage: 13329kB
-> ProjectSet (cost=0.00..23530.32 rows=4416600 width=36) (actual time=0.030..159.741 rows=163540 loops=1)
-> Seq Scan on cfiles (cost=0.00..1005.66 rows=44166 width=68) (actual time=0.006..9.588 rows=44166 loops=1)
Planning Time: 0.247 ms
Execution Time: 269.362 ms
वह बेहतर है। लेकिन मुझे आपकी क्वेरी में एक LIMIT दिखाई दे रहा है, जिसका अर्थ है कि आप शायद पेजिनेशन जैसा कुछ कर रहे हैं। इस मामले में केवल संपूर्ण cfiles तालिका के लिए संपूर्ण क्वेरी की गणना करना और फिर LIMIT के कारण अधिकांश परिणामों को फेंकना आवश्यक है, यदि उस बड़ी क्वेरी के परिणाम बदल सकते हैं कि क्या डेटासेट से एक पंक्ति अंतिम परिणाम में शामिल है या नहीं। यदि ऐसा है, तो डेटासेट में पंक्तियाँ जिनमें संगत cfiles नहीं हैं, अंतिम परिणाम में प्रकट नहीं होंगी, जिसका अर्थ है कि cfiles की सामग्री पृष्ठ पर अंक लगाना को प्रभावित करेगी। ठीक है, हम हमेशा धोखा दे सकते हैं:यह जानने के लिए कि क्या डेटासेट से एक पंक्ति को शामिल करना है, केवल यह आवश्यक है कि cfiles की एक पंक्ति उस आईडी के साथ मौजूद हो...
इसलिए, यह जानने के लिए कि अंतिम परिणाम में डेटासेट की कौन सी पंक्तियों को शामिल किया जाएगा, हम इन दो प्रश्नों में से किसी एक का उपयोग कर सकते हैं:
SELECT id FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20;
SELECT dataset_id FROM
(SELECT id AS dataset_id, name AS dataset_name FROM datasets ORDER BY dataset_name) f1
WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = f1.dataset_id )
ORDER BY dataset_name
LIMIT 20;
वे लगभग 2-3 मिलीसेकंड लेते हैं। हम धोखा भी दे सकते हैं:
CREATE INDEX datasets_name_id ON datasets(name,id);
यह इसे लगभग 300 माइक्रोसेकंड तक लाता है। तो, अब हमें डेटासेट_आईडी की सूची मिल गई है जिसका वास्तव में उपयोग किया जाएगा (और फेंका नहीं जाएगा) ताकि हम इसका उपयोग केवल उन पंक्तियों पर बड़े धीमे एकत्रीकरण को करने के लिए कर सकें जो वास्तव में अंतिम परिणाम में होंगे, जिससे बड़ी राशि बचानी चाहिए अनावश्यक काम के...
WITH ds AS (SELECT id AS dataset_id, name AS dataset_name
FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20)
SELECT dataset_id, dataset_name, sample_names FROM (
SELECT dataset_id, string_agg(DISTINCT sn, '; ' ORDER BY sn) as sample_names FROM (
SELECT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM ds JOIN cfiles USING (dataset_id)
) g GROUP BY dataset_id
) h JOIN ds USING (dataset_id)
ORDER BY dataset_name;
इसमें लगभग 30ms लगते हैं, मैंने नमूना_नाम द्वारा ऑर्डर भी दिया था जिसे मैं पहले भूल गया था। यह आपके मामले के लिए काम करना चाहिए। एक महत्वपूर्ण बिंदु यह है कि क्वेरी समय अब टेबल cfiles के आकार पर निर्भर नहीं करता है, क्योंकि यह केवल उन पंक्तियों को संसाधित करेगा जिनकी वास्तव में आवश्यकता है।
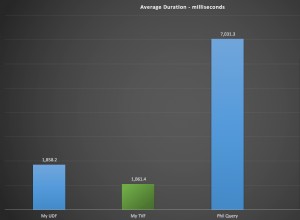
कृपया परिणाम पोस्ट करें;)