1.
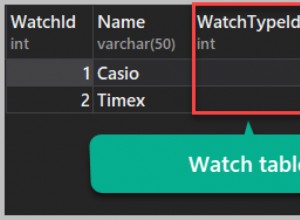
मैंने जो पढ़ा है, उसमें से क्वेरी हैश हो जाती है और इसे डीबी में रखता है, टेक्स्ट को एफएस में सहेजता है। तो अगली चिंता अधिक अपेक्षित है फिर अतिभारित साझा स्मृति:
टेक्स्ट का हैश टेक्स्ट से इतना छोटा है, कि मुझे लगता है कि आपको लंबे प्रश्नों की तुलना में विस्तार मेमोरी खपत के बारे में चिंता नहीं करनी चाहिए। विशेष रूप से यह जानते हुए कि एक्सटेंशन क्वेरी एनालाइज़र का उपयोग करता है (जो हर के लिए काम करेगा क्वेरी वैसे भी ):
pg_stat_statements.max सेट करना मेरा मानना है कि 10 गुना बड़ी साझा मेमोरी को 10 गुना अधिक लेना चाहिए। वृद्धि रैखिक . होनी चाहिए . दस्तावेज़ीकरण में ऐसा नहीं कहा गया है , लेकिन तार्किक रूप से ऐसा होना चाहिए।
सेटिंग को अलग मान पर सेट करना सुरक्षित है या नहीं, इसका कोई जवाब नहीं है, क्योंकि आपके पास अन्य कॉन्फ़िगरेशन मानों और HW पर कोई डेटा नहीं है। लेकिन जैसा कि विकास रैखिक होना चाहिए, इस उत्तर पर विचार करें:"यदि आप इसे 5K पर सेट करते हैं, और क्वेरी रनटाइम लगभग कुछ भी नहीं बढ़ा है, तो इसे 50K पर सेट करने से यह लगभग दस गुना लंबा हो जाएगा"। BTW, मेरा प्रश्न - 50000 धीमे बयानों को खोदने वाला कौन है? :)
2.
यह एक्सटेंशन पहले से ही "अन-वैल्यूड" स्टेटमेंट के लिए प्री-एग्रीगेशन बनाता है। आप इसे सीधे डीबी पर चुन सकते हैं, इसलिए डेटा को अन्य डीबी में ले जाना और इसे वहां चुनना आपको केवल मूल डीबी को उतारने और दूसरे को लोड करने का लाभ देगा। दूसरे शब्दों में आप मूल पर एक प्रश्न के लिए 50 एमबी बचाते हैं, लेकिन दूसरे पर खर्च करते हैं। क्या इसका अर्थ बनता है? मेरे लिए हाँ। यही मैं खुद करता हूं। लेकिन मैं स्टेटमेंट के लिए निष्पादन योजनाओं को भी सहेजता हूं (जो कि pg_stat_statements एक्सटेंशन का हिस्सा नहीं है)। मेरा मानना है कि यह इस बात पर निर्भर करता है कि आपके पास क्या है और आपके पास क्या है। निश्चित रूप से कई प्रश्नों के कारण इसकी कोई आवश्यकता नहीं है। फिर से जब तक आपके पास इतनी बड़ी फ़ाइल न हो कि एक्सटेंशन