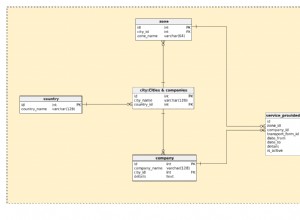
पहला चरण:सबक्वेरी में पूर्व-एकत्रीकरण करें:
EXPLAIN
SELECT cal.theday, act.action_name, SUM(sub.the_count)
FROM generate_series(current_date - interval '1 week', now(), interval '1
day') as cal(theday) -- calendar pseudo-table
CROSS JOIN (VALUES
('page_open')
, ('product_add') , ('product_buy') , ('product_event')
, ('product_favourite') , ('product_open') , ('product_share') , ('session_start')
) AS act(action_name)
LEFT JOIN (
SELECT es.action_name, date_trunc('day',es.date_update) as theday
, COUNT(DISTINCT es.id ) AS the_count
FROM event_statistics as es
WHERE es.client_id = (SELECT c.id FROM clients AS c
WHERE c.client_name = 'client name')
AND (es.date_update BETWEEN (current_date - interval '1 week') AND now())
GROUP BY 1,2
) sub ON cal.theday = sub.theday AND act.action_name = sub.action_name
GROUP BY act.action_name,cal.theday
ORDER BY act.action_name,cal.theday
;
अगला चरण:VALUES को CTE में डालें और इसे समग्र सबक्वेरी में भी देखें। (लाभ उन क्रिया नामों की संख्या पर निर्भर करता है जिन्हें छोड़ दिया जा सकता है)
EXPLAIN
WITH act(action_name) AS (VALUES
('page_open')
, ('product_add') , ('product_buy') , ('product_event')
, ('product_favourite') , ('product_open') , ('product_share') , ('session_start')
)
SELECT cal.theday, act.action_name, SUM(sub.the_count)
FROM generate_series(current_date - interval '1 week', now(), interval '1day') AS cal(theday)
CROSS JOIN act
LEFT JOIN (
SELECT es.action_name, date_trunc('day',es.date_update) AS theday
, COUNT(DISTINCT es.id ) AS the_count
FROM event_statistics AS es
WHERE es.date_update BETWEEN (current_date - interval '1 week') AND now()
AND EXISTS (SELECT * FROM clients cli WHERE cli.id= es.client_id AND cli.client_name = 'client name')
AND EXISTS (SELECT * FROM act WHERE act.action_name = es.action_name)
GROUP BY 1,2
) sub ON cal.theday = sub.theday AND act.action_name = sub.action_name
GROUP BY act.action_name,cal.theday
ORDER BY act.action_name,cal.theday
;
अद्यतन:भौतिक (अस्थायी) तालिका का उपयोग करने से बेहतर अनुमान प्राप्त होंगे।
-- Final attempt: materialize the carthesian product (timeseries*action_name)
-- into a temp table
CREATE TEMP TABLE grid AS
(SELECT act.action_name, cal.theday
FROM generate_series(current_date - interval '1 week', now(), interval '1 day')
AS cal(theday)
CROSS JOIN
(VALUES ('page_open')
, ('product_add') , ('product_buy') , ('product_event')
, ('product_favourite') , ('product_open') , ('product_share') , ('session_start')
) act(action_name)
);
CREATE UNIQUE INDEX ON grid(action_name, theday);
-- Index will force statistics to be collected
-- ,and will generate better estimates for the numbers of rows
CREATE INDEX iii ON event_statistics (action_name, date_update ) ;
VACUUM ANALYZE grid;
VACUUM ANALYZE event_statistics;
EXPLAIN
SELECT grid.action_name, grid.theday, SUM(sub.the_count) AS the_count
FROM grid
LEFT JOIN (
SELECT es.action_name, date_trunc('day',es.date_update) AS theday
, COUNT(*) AS the_count
FROM event_statistics AS es
WHERE es.date_update BETWEEN (current_date - interval '1 week') AND now()
AND EXISTS (SELECT * FROM clients cli WHERE cli.id= es.client_id AND cli.client_name = 'client name')
-- AND EXISTS (SELECT * FROM grid WHERE grid.action_name = es.action_name)
GROUP BY 1,2
ORDER BY 1,2 --nonsense!
) sub ON grid.theday = sub.theday AND grid.action_name = sub.action_name
GROUP BY grid.action_name,grid.theday
ORDER BY grid.action_name,grid.theday
;
अपडेट#3 (क्षमा करें, मैं यहां बेस टेबल पर इंडेक्स बनाता हूं, आपको संपादित करना होगा। मैंने टाइमस्टैम्प पर एक-कॉलम भी हटा दिया है)
-- attempt#4:
-- - materialize the carthesian product (timeseries*action_name)
-- - sanitize date interval -logic
CREATE TEMP TABLE grid AS
(SELECT act.action_name, cal.theday::date
FROM generate_series(current_date - interval '1 week', now(), interval '1 day')
AS cal(theday)
CROSS JOIN
(VALUES ('page_open')
, ('product_add') , ('product_buy') , ('product_event')
, ('product_favourite') , ('product_open') , ('product_share') , ('session_start')
) act(action_name)
);
-- Index will force statistics to be collected
-- ,and will generate better estimates for the numbers of rows
-- CREATE UNIQUE INDEX ON grid(action_name, theday);
-- CREATE INDEX iii ON event_statistics (action_name, date_update ) ;
CREATE UNIQUE INDEX ON grid(theday, action_name);
CREATE INDEX iii ON event_statistics (date_update, action_name) ;
VACUUM ANALYZE grid;
VACUUM ANALYZE event_statistics;
EXPLAIN
SELECT gr.action_name, gr.theday
, COUNT(*) AS the_count
FROM grid gr
LEFT JOIN event_statistics AS es
ON es.action_name = gr.action_name
AND date_trunc('day',es.date_update)::date = gr.theday
AND es.date_update BETWEEN (current_date - interval '1 week') AND current_date
JOIN clients cli ON cli.id= es.client_id AND cli.client_name = 'client name'
GROUP BY gr.action_name,gr.theday
ORDER BY 1,2
;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=8.33..8.35 rows=1 width=17)
Group Key: gr.action_name, gr.theday
-> Sort (cost=8.33..8.34 rows=1 width=17)
Sort Key: gr.action_name, gr.theday
-> Nested Loop (cost=1.40..8.33 rows=1 width=17)
-> Nested Loop (cost=1.31..7.78 rows=1 width=40)
Join Filter: (es.client_id = cli.id)
-> Index Scan using clients_client_name_key on clients cli (cost=0.09..2.30 rows=1 width=4)
Index Cond: (client_name = 'client name'::text)
-> Bitmap Heap Scan on event_statistics es (cost=1.22..5.45 rows=5 width=44)
Recheck Cond: ((date_update >= (('now'::cstring)::date - '7 days'::interval)) AND (date_update <= ('now'::cstring)::date))
-> Bitmap Index Scan on iii (cost=0.00..1.22 rows=5 width=0)
Index Cond: ((date_update >= (('now'::cstring)::date - '7 days'::interval)) AND (date_update <= ('now'::cstring)::date))
-> Index Only Scan using grid_theday_action_name_idx on grid gr (cost=0.09..0.54 rows=1 width=17)
Index Cond: ((theday = (date_trunc('day'::text, es.date_update))::date) AND (action_name = es.action_name))
(15 rows)