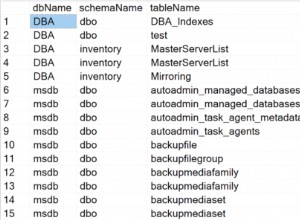
यह पूरी तरह से संतोषजनक समाधान के बिना एक समस्या है क्योंकि आप अनिवार्य रूप से असंगत आवश्यकताओं को संयोजित करने का प्रयास कर रहे हैं:
-
क्लाइंट को केवल आवश्यक मात्रा में डेटा ऑन-डिमांड भेजें, यानी आप संपूर्ण डेटासेट डाउनलोड नहीं कर सकते हैं, फिर इसे क्लाइंट-साइड पर पेजेट कर सकते हैं।
-
बड़ी संख्या में क्लाइंट के साथ स्केलेबिलिटी के लिए, प्रति-क्लाइंट स्थिति की मात्रा को कम करें जिसे सर्वर को ट्रैक करना चाहिए।
-
प्रत्येक ग्राहक के लिए अलग स्थिति बनाए रखें
यह एक "कोई दो चुनें" प्रकार की स्थिति है। आपको समझौता करना होगा; स्वीकार करें कि आप प्रत्येक क्लाइंट की पेजिनेशन स्थिति को बिल्कुल सही नहीं रख सकते हैं, स्वीकार करें कि आपको क्लाइंट के लिए एक बड़ा डेटा सेट डाउनलोड करना होगा, या स्वीकार करें कि क्लाइंट स्थिति को बनाए रखने के लिए आपको बड़ी मात्रा में सर्वर संसाधनों का उपयोग करना होगा।
उनमें भिन्नताएं हैं जो विभिन्न समझौतों को मिलाती हैं, लेकिन यही सब कुछ उबलता है।
उदाहरण के लिए, कुछ लोग क्लाइंट को कुछ भेजेंगे अतिरिक्त डेटा, अधिकांश ग्राहक आवश्यकताओं को पूरा करने के लिए पर्याप्त है। यदि क्लाइंट इससे अधिक हो जाता है, तो यह टूटा हुआ पृष्ठांकन हो जाता है।
कुछ सिस्टम क्लाइंट स्टेट को थोड़े समय के लिए कैश करेंगे (अल्पकालिक अनलॉग टेबल, टेम्पफाइल, या जो कुछ भी), लेकिन इसे जल्दी से समाप्त कर दें, इसलिए यदि क्लाइंट लगातार ताजा डेटा नहीं मांग रहा है तो यह टूटा हुआ पेजिनेशन हो जाता है।
आदि।
यह भी देखें:
- एक API क्लाइंट को 1,000,000 डेटाबेस परिणाम कैसे प्रदान करें?
- PostgreSQL में पेजिंग के लिए "Cursors" का उपयोग करना
- बड़े बाहरी पोस्टग्रेज डीबी पर पुनरावृति करें, पंक्तियों में हेरफेर करें, रेल पोस्टग्रेज डीबी को आउटपुट लिखें
- ऑफ़सेट/प्रदर्शन अनुकूलन सीमित करें
- अगर PostgreSQL गिनती(*) हमेशा धीमी है तो जटिल प्रश्नों को कैसे पृष्ठांकित करें?
- डेटाबेस से एक-एक करके नमूना पंक्ति कैसे वापस करें
मैं शायद किसी रूप का हाइब्रिड समाधान लागू करूंगा, जैसे:
-
कर्सर का उपयोग करते हुए, क्लाइंट को डेटा का पहला भाग पढ़ें और तुरंत भेजें।
-
ग्राहकों की 99% आवश्यकताओं को पूरा करने के लिए तुरंत कर्सर से पर्याप्त अतिरिक्त डेटा प्राप्त करें। इसे एक तेज़, असुरक्षित कैश जैसे मेमकैच्ड, रेडिस, बिगमेमरी, ईएचकैच में स्टोर करें, जो कुछ भी एक कुंजी के नीचे है जो मुझे उसी क्लाइंट द्वारा बाद के अनुरोधों के लिए इसे पुनर्प्राप्त करने देगा। फिर DB संसाधनों को मुक्त करने के लिए कर्सर को बंद करें।
-
कैश को कम से कम हाल ही में उपयोग किए गए आधार पर समाप्त करें, इसलिए यदि क्लाइंट पर्याप्त तेज़ी से पढ़ना जारी नहीं रखता है तो उन्हें डीबी से डेटा का एक नया सेट प्राप्त करना होगा, और पेजिनेशन बदल जाएगा।
-
यदि क्लाइंट अपने साथियों के विशाल बहुमत की तुलना में अधिक परिणाम चाहता है, तो कुछ बिंदु पर पेजिनेशन बदल जाएगा क्योंकि आप कैश के बजाय डीबी से सीधे पढ़ने के लिए स्विच करते हैं या एक नया बड़ा कैश्ड डेटासेट उत्पन्न करते हैं।
इस तरह अधिकांश क्लाइंट पेजिनेशन समस्याओं पर ध्यान नहीं देंगे और आपको अधिकांश क्लाइंट्स को बड़ी मात्रा में डेटा भेजने की आवश्यकता नहीं है, लेकिन आप अपने डीबी सर्वर को पिघला नहीं पाएंगे। हालाँकि, इससे दूर होने के लिए आपको एक बड़े बूफी कैश की आवश्यकता है। इसका व्यावहारिक इस बात पर निर्भर करता है कि क्या आपके ग्राहक पेजिनेशन ब्रेकिंग का सामना कर सकते हैं - यदि यह पेजिनेशन को तोड़ने के लिए स्वीकार्य नहीं है, तो आप इसे कर्सर, अस्थायी टेबल के साथ डीबी-साइड करने, पहले अनुरोध पर पूरे परिणाम सेट का मुकाबला करने आदि के साथ फंस गए हैं। यह डेटा सेट के आकार और प्रत्येक क्लाइंट को आमतौर पर कितने डेटा की आवश्यकता होती है, इस पर भी निर्भर करता है।