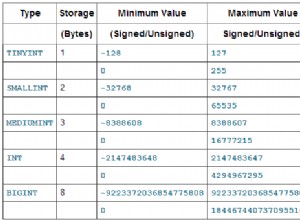
प्रदर्शन बदतर नहीं है, जरूरी है। जैसा कि लेख में बताया गया है, ऐसी विशिष्ट स्थितियां हैं जो आपके एप्लिकेशन डिज़ाइन और कार्यभार के आधार पर स्कीमा दृष्टिकोण को बेहतर या बदतर बनाती हैं। मुझे "किरायेदार-स्कीमा" बनाम "साझा-तालिका" दृष्टिकोण के ट्रेडऑफ़ की व्याख्या करने दें:
किरायेदार-स्कीमा सबसे अच्छा है जब आपके पास अपेक्षाकृत कम संख्या में काफी बड़े किरायेदार हों। इसका एक उदाहरण केवल सशुल्क सदस्यता वाले उपयोगकर्ताओं के साथ एक लेखा अनुप्रयोग होगा। जो चीजें इसे आपके लिए बेहतर प्रदर्शन करने वाला विकल्प बनाती हैं उनमें शामिल हैं:
- बहुत सारे डेटा वाले किरायेदारों की एक छोटी संख्या
- एक अपेक्षाकृत सरल स्कीमा जिसमें प्रति टैनेंट बहुत सारी टेबल नहीं है
- कुछ किरायेदारों के स्कीमा को अनुकूलित करने की आवश्यकता
- प्रति किरायेदार डेटाबेस भूमिकाओं का उपयोग करने की क्षमता
- एक टेनेंट के डेटा को एक सर्वर से दूसरे सर्वर पर माइग्रेट करने की आवश्यकता
- प्रत्येक टैनेंट के लिए आपके क्लाउड में एक समर्पित ऐपसर्वर को स्पिन करने की क्षमता
जो चीजें इसे खराब प्रदर्शन करने वाले विकल्प बनाती हैं उनमें शामिल हैं:
- बहुत कम डेटा वाले बहुत सारे किरायेदार
- कनेक्शन के लिए स्टेटलेस दृष्टिकोण जहां प्रत्येक अनुरोध कोई भी किरायेदार हो सकता है
- क्लाइंट लाइब्रेरी या ओआरएम जो सभी तालिकाओं के लिए मेटाडेटा को कैश करता है (जैसे ActiveRecord)
- कुशल, उच्च-प्रदर्शन कनेक्शन पूलिंग और/या कैशिंग के लिए एक आवश्यकता
- वैक्यूम और अन्य पोस्टग्रेएसक्यूएल प्रशासनिक कार्यों के साथ समस्याएं जो 1000 तालिकाओं में खराब पैमाने पर होती हैं।
क्या टेनेंट-स्कीमा माइग्रेशन/स्कीमा परिवर्तनों के लिए खराब है, यह वास्तव में इस बात पर निर्भर करता है कि आप उन्हें कैसे कर रहे हैं। सार्वभौमिक स्कीमा परिवर्तन को शीघ्रता से रोल आउट करना बुरा है, लेकिन स्कीमा परिवर्तनों को टैनेंट में क्रमिक रोलआउट के रूप में परिनियोजित करने के लिए अच्छा है।
साझा-तालिका उन स्थितियों के लिए बेहतर काम करता है जब आपके पास बहुत सारे किरायेदार होते हैं, और आपके बहुत से किरायेदारों के पास बहुत कम डेटा होता है। इसका एक उदाहरण सोशल मीडिया मोबाइल एप्लिकेशन होगा जो मुफ्त खातों की अनुमति देता है और इस प्रकार हजारों परित्यक्त खाते हैं। अन्य चीजें जो साझा तालिका मॉडल को लाभकारी बनाती हैं वे हैं:
- कनेक्शन पूलिंग के लिए बेहतर, क्योंकि सभी कनेक्शन एक ही पूल का उपयोग कर सकते हैं
- पोस्टग्रेएसक्यूएल व्यवस्थापन के लिए बेहतर, क्योंकि कुल टेबल कम हैं
- माइग्रेशन और स्कीमा परिवर्तन के लिए बेहतर है, क्योंकि तालिकाओं का केवल एक "सेट" होता है
साझा-तालिका का मुख्य दोष यह है कि आवेदन परत में प्रत्येक क्वेरी पर टैनेंट फ़िल्टर स्थिति को जोड़ने की आवश्यकता है। यह समस्याग्रस्त भी है क्योंकि:
- कई तालिकाओं में शामिल होने वाली क्वेरी खराब प्रदर्शन कर सकती हैं क्योंकि टैनेंट फ़िल्टर क्वेरी योजना को बंद कर देता है
- तालिकाएं जो 100 मिलियन पंक्तियों तक बढ़ती हैं, विशिष्ट प्रदर्शन और रखरखाव के मुद्दों का कारण बन सकती हैं
- टेनेंट-विशिष्ट एप्लिकेशन परिवर्तन या स्कीमा अपग्रेड करने का कोई तरीका नहीं
- टैनेंट को सर्वर के बीच माइग्रेट करना अधिक महंगा
तो कौन सा मॉडल "बेहतर प्रदर्शन करता है" वास्तव में इस बात पर निर्भर करता है कि कौन से ट्रेडऑफ़ आपको सबसे ज्यादा चोट पहुँचाते हैं।
एक हाइब्रिड मॉडल, "टेनेंट-व्यू" भी है, जहां वास्तविक डेटा साझा तालिकाओं में संग्रहीत किया जाता है, लेकिन प्रत्येक एप्लिकेशन कनेक्शन सुरक्षा बाधा दृश्य डेटा देखने के लिए। इसमें प्रत्येक मॉडल के कुछ ट्रेडऑफ़ हैं। मुख्य रूप से, इसमें टेनेंट-स्कीमा मॉडल के सुरक्षा लाभ हैं, जिसमें दोनों मॉडलों की कुछ प्रदर्शन कमियां हैं।