जब आपको किसी कंपनी के लिए एक एनालिटिक्स सिस्टम लागू करने की आवश्यकता होती है, तो अक्सर यह सवाल होता है कि डेटा कहाँ संग्रहीत किया जाना चाहिए। सभी आवश्यकताओं के लिए हमेशा एक सही विकल्प नहीं होता है और यह बजट, डेटा की मात्रा और कंपनी की जरूरतों पर निर्भर करता है।
PostgreSQL, सबसे उन्नत ओपन सोर्स डेटाबेस के रूप में, इतना लचीला है कि एक साधारण रिलेशनल डेटाबेस, एक समय-श्रृंखला डेटा डेटाबेस और यहां तक कि एक कुशल, कम लागत वाले, डेटा वेयरहाउसिंग समाधान के रूप में काम कर सकता है। आप इसे कई एनालिटिक्स टूल के साथ भी एकीकृत कर सकते हैं।
यदि आप व्यापक रूप से संगत, कम लागत और प्रदर्शनकारी डेटा वेयरहाउस की तलाश में हैं, तो सबसे अच्छा डेटाबेस विकल्प PostgreSQL हो सकता है, लेकिन क्यों? इस ब्लॉग में, हम देखेंगे कि डेटा वेयरहाउस क्या है, इसकी आवश्यकता क्यों है, और यहां PostgreSQL सबसे अच्छा विकल्प क्यों हो सकता है।
डेटा वेयरहाउस क्या है
डेटा वेयरहाउस मानकीकृत, सुसंगत और एकीकृत प्रणाली है जिसमें एक या अधिक स्रोतों से वर्तमान या ऐतिहासिक डेटा होता है जिसका उपयोग रिपोर्टिंग और डेटा विश्लेषण के लिए किया जाता है। इसे व्यावसायिक खुफिया का एक मुख्य घटक माना जाता है, जो कि एक कंपनी द्वारा अपने व्यावसायिक संदर्भ की बेहतर समझ के लिए उपयोग की जाने वाली रणनीति और तकनीक है।
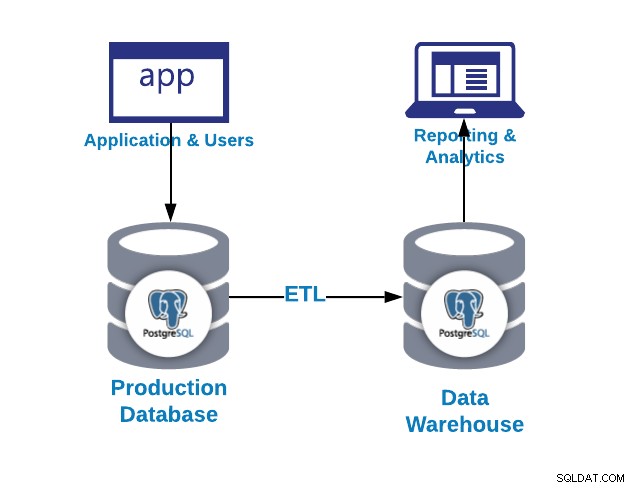
पहला सवाल जो आप पूछ सकते हैं वह यह है कि मुझे डेटा वेयरहाउस की आवश्यकता क्यों है?
- एकीकरण:एकाधिक सिस्टम/डेटाबेस से डेटा को एकीकृत/केंद्रीकृत करें
- मानकीकृत करें:सभी डेटा को एक ही प्रारूप में मानकीकृत करें
- Analytics:ऐतिहासिक संदर्भ में डेटा का विश्लेषण करें
डेटा वेयरहाउस के कुछ लाभ हो सकते हैं...
- एक से अधिक स्रोतों से डेटा को एक डेटाबेस में एकीकृत करें
- लंबे समय से चल रही क्वेरी के कारण प्रोडक्शन लॉकिंग या लोड से बचें
- ऐतिहासिक जानकारी संग्रहीत करें
- एनालिटिक्स की ज़रूरतों को पूरा करने के लिए डेटा का पुनर्गठन करें
जैसा कि हम पिछली छवि में देख सकते थे, हम OLAP और OLTP दोनों प्रस्तावों के लिए PostgreSQL का उपयोग कर सकते हैं। आइए देखें अंतर।
- OLTP:ऑनलाइन लेनदेन प्रसंस्करण। सामान्य तौर पर, इसमें उपयोगकर्ता गतिविधि द्वारा उत्पन्न बड़ी संख्या में लघु ऑनलाइन लेनदेन (INSERT, UPDATE, DELETE) होते हैं। ये सिस्टम बहु-पहुंच वातावरण में बहुत तेजी से क्वेरी प्रसंस्करण और डेटा अखंडता बनाए रखने पर जोर देते हैं। यहां, प्रभावशीलता को प्रति सेकंड लेनदेन की संख्या से मापा जाता है। OLTP डेटाबेस में विस्तृत और वर्तमान डेटा होता है।
- OLAP:ऑनलाइन विश्लेषणात्मक प्रसंस्करण। सामान्य तौर पर, इसमें बड़ी रिपोर्टों द्वारा उत्पन्न जटिल लेनदेन की मात्रा कम होती है। प्रतिक्रिया समय एक प्रभावशीलता उपाय है। ये डेटाबेस बहु-आयामी स्कीमा में एकत्रित, ऐतिहासिक डेटा संग्रहीत करते हैं। OLAP डेटाबेस का उपयोग कई स्रोतों और दृष्टिकोणों से बहुआयामी डेटा का विश्लेषण करने के लिए किया जाता है।
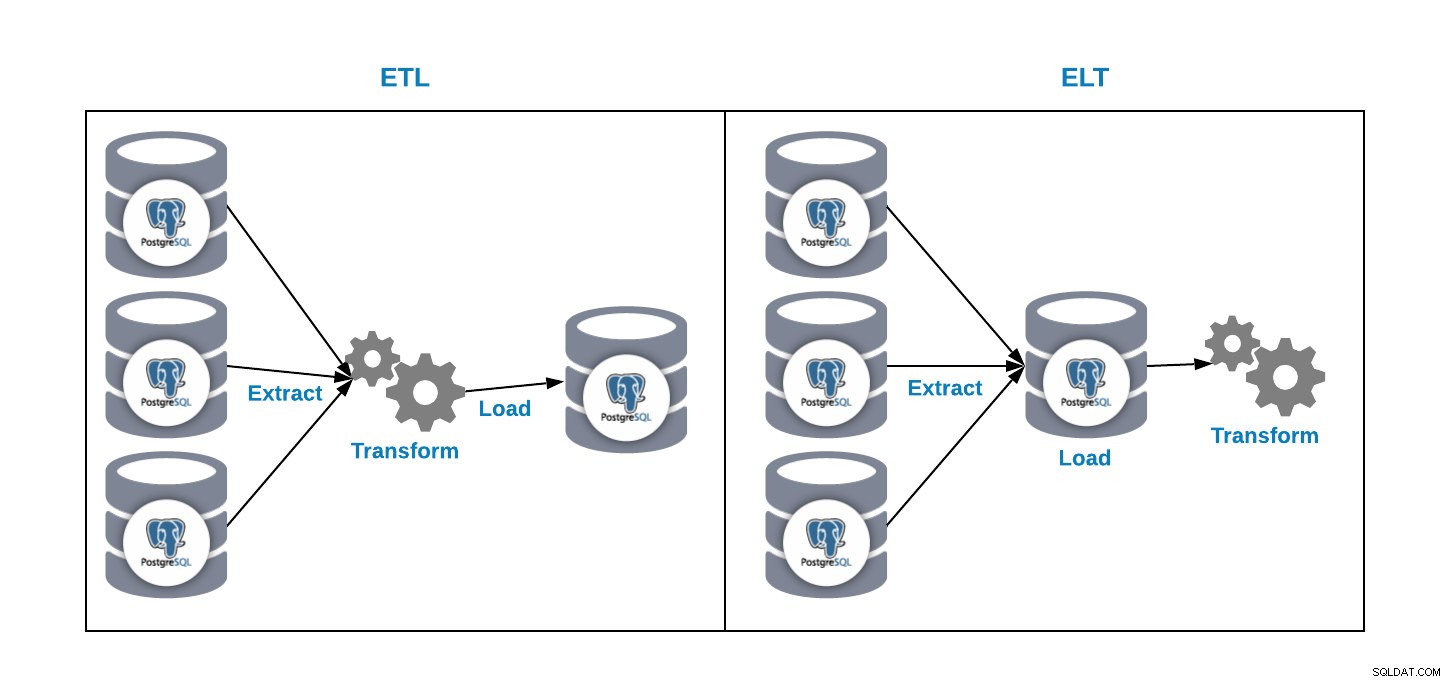
हमारे पास अपने एनालिटिक्स डेटाबेस में डेटा लोड करने के दो तरीके हैं:
- ETL:निकालें, रूपांतरित करें और लोड करें। यह हमारे डेटा वेयरहाउस को उत्पन्न करने का तरीका है। सबसे पहले, उत्पादन डेटाबेस से डेटा निकालें, डेटा को हमारी आवश्यकता के अनुसार रूपांतरित करें, और फिर डेटा को हमारे डेटा वेयरहाउस में लोड करें।
- ईएलटी:निकालें, लोड करें और रूपांतरित करें। सबसे पहले, उत्पादन डेटाबेस से डेटा निकालें, इसे डेटाबेस में लोड करें और फिर डेटा को रूपांतरित करें। इस तरह से डेटा लेक कहा जाता है और यह हमारे बड़े डेटा को प्रबंधित करने के लिए एक नई अवधारणा है।
और अब, दूसरा प्रश्न मैं, मुझे अपने डेटा वेयरहाउस के लिए PostgreSQL का उपयोग क्यों करना चाहिए?
डेटा वेयरहाउस के रूप में PostgreSQL के लाभ
आइए एक डेटा वेयरहाउस के रूप में PostgreSQL का उपयोग करने के कुछ लाभों को देखें...
- लागत:यदि आप ऑन-प्रिमाइसेस परिवेश का उपयोग कर रहे हैं, तो उत्पाद की लागत स्वयं $0 होगी, भले ही आप क्लाउड में किसी उत्पाद का उपयोग कर रहे हों, संभवतः पोस्टग्रेएसक्यूएल आधारित उत्पाद की लागत इससे कम होगी बाकी उत्पाद.
- पैमाना:आप जितने चाहें उतने प्रतिकृति नोड्स जोड़कर इसे सरल तरीके से पढ़ सकते हैं।
- प्रदर्शन:सही कॉन्फ़िगरेशन के साथ, PostgreSQL का विभिन्न परिदृश्यों पर वास्तव में अच्छा प्रदर्शन है।
- संगतता:आप डेटा माइनिंग, OLAP और रिपोर्टिंग के लिए बाहरी टूल या एप्लिकेशन के साथ PostgreSQL को एकीकृत कर सकते हैं।
- एक्सटेंसिबिलिटी:PostgreSQL में उपयोगकर्ता-परिभाषित डेटा प्रकार और कार्य हैं।
कुछ PostgreSQL सुविधाएं भी हैं जो हमारे डेटा वेयरहाउस जानकारी को प्रबंधित करने में हमारी सहायता कर सकती हैं...
- अस्थायी तालिकाएँ:यह एक अल्पकालिक तालिका है जो एक डेटाबेस सत्र की अवधि के लिए मौजूद है। PostgreSQL स्वचालित रूप से एक सत्र या लेनदेन के अंत में अस्थायी तालिकाओं को छोड़ देता है।
- संग्रहीत प्रक्रियाएं:आप इसका उपयोग कई भाषाओं (पीएल/पीजीएसक्यूएल, पीएल/पर्ल, पीएल/पायथन, आदि) पर प्रक्रियाएं या कार्य बनाने के लिए कर सकते हैं।
- विभाजन:यह वास्तव में डेटाबेस रखरखाव, विभाजन कुंजी का उपयोग करने वाली क्वेरी और INSERT प्रदर्शन के लिए उपयोगी है।
- भौतिक दृश्य:क्वेरी परिणाम एक तालिका के रूप में दिखाए जाते हैं।
- तालिका स्थान:आप डेटा स्थान को किसी भिन्न डिस्क में बदल सकते हैं। इस तरह, आपके पास समानांतर डिस्क एक्सेस होगी।
- PITR संगत:आप पॉइंट-इन-टाइम-रिकवरी संगत बैकअप बना सकते हैं, इसलिए विफलता के मामले में, आप एक विशिष्ट अवधि पर डेटाबेस स्थिति को पुनर्स्थापित कर सकते हैं।
- विशाल समुदाय:और अंतिम लेकिन कम से कम, PostgreSQL का एक विशाल समुदाय है जहां आप कई अलग-अलग मुद्दों पर समर्थन पा सकते हैं।
डेटा वेयरहाउस उपयोग के लिए PostgreSQL कॉन्फ़िगर करना
सभी मामलों में और सभी डेटाबेस तकनीकों में उपयोग करने के लिए कोई सर्वोत्तम कॉन्फ़िगरेशन नहीं है। यह हार्डवेयर, उपयोग और सिस्टम आवश्यकताओं जैसे कई कारकों पर निर्भर करता है। अपने PostgreSQL डेटाबेस को सही तरीके से डेटा वेयरहाउस के रूप में काम करने के लिए कॉन्फ़िगर करने के लिए नीचे कुछ सुझाव दिए गए हैं।
स्मृति आधारित
- max_connections:डेटा वेयरहाउस डेटाबेस के रूप में, आपको अधिक मात्रा में कनेक्शन की आवश्यकता नहीं है क्योंकि इसका उपयोग रिपोर्टिंग और विश्लेषण कार्य के लिए किया जाएगा, इसलिए आप इस पैरामीटर का उपयोग करके अधिकतम कनेक्शन संख्या को सीमित कर सकते हैं।
- shared_buffers:साझा मेमोरी बफ़र्स के लिए डेटाबेस सर्वर द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को सेट करता है। एक उचित मान RAM मेमोरी के 15% से 25% तक हो सकता है।
- प्रभावी_कैश_साइज:इस मान का उपयोग क्वेरी प्लानर द्वारा उन योजनाओं को ध्यान में रखने के लिए किया जाता है जो स्मृति में फिट हो भी सकती हैं और नहीं भी। इसे एक सूचकांक का उपयोग करने के लागत अनुमानों में ध्यान में रखा जाता है; एक उच्च मूल्य यह अधिक संभावना बनाता है कि सूचकांक स्कैन का उपयोग किया जाता है और कम मूल्य यह अधिक संभावना बनाता है कि अनुक्रमिक स्कैन का उपयोग किया जाएगा। एक उचित मूल्य RAM मेमोरी का लगभग 75% होगा।
- वर्क मेम:डिस्क पर अस्थायी फ़ाइलों को लिखने से पहले ORDER BY, DISTINCT, JOIN, और हैश टेबल के आंतरिक संचालन द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को निर्दिष्ट करता है। इस मान को कॉन्फ़िगर करते समय हमें यह ध्यान रखना चाहिए कि एक ही समय में कई सत्र इन कार्यों को निष्पादित कर रहे हैं और प्रत्येक ऑपरेशन को अस्थायी फ़ाइलों में डेटा लिखना शुरू करने से पहले इस मान द्वारा निर्दिष्ट मेमोरी का उपयोग करने की अनुमति दी जाएगी। एक उचित मूल्य RAM मेमोरी का लगभग 2% हो सकता है।
- maintenance_work_mem:रखरखाव कार्यों में उपयोग की जाने वाली मेमोरी की अधिकतम मात्रा को निर्दिष्ट करता है, जैसे VACUUM, CREATE INDEX, और ALTER TABLE ADD FOREIGN KEY। एक उचित मूल्य RAM मेमोरी का लगभग 15% हो सकता है।
CPU आधारित
- Max_worker_processes:सिस्टम द्वारा समर्थित अधिकतम पृष्ठभूमि प्रक्रियाओं को सेट करता है। एक उचित मूल्य CPU की संख्या हो सकता है।
- Max_parallel_workers_per_gather:उन श्रमिकों की अधिकतम संख्या सेट करता है, जिन्हें सिंगल गैदर या गैदर मर्ज नोड द्वारा शुरू किया जा सकता है। एक उचित मूल्य CPU की संख्या का 50% हो सकता है।
- Max_parallel_workers:श्रमिकों की अधिकतम संख्या सेट करता है जो सिस्टम समानांतर प्रश्नों के लिए समर्थन कर सकता है। एक उचित मूल्य CPU की संख्या हो सकता है।
चूंकि हमारे डेटा वेयरहाउस में लोड किया गया डेटा नहीं बदलना चाहिए, इसलिए हम आपके PostgreSQL डेटाबेस पर अतिरिक्त लोड से बचने के लिए ऑटोवैक्यूम को बंद भी कर सकते हैं। वैक्यूम और विश्लेषण प्रक्रियाएं बैच लोड प्रक्रिया का हिस्सा हो सकती हैं।
निष्कर्ष
यदि आप व्यापक रूप से संगत, कम लागत और उच्च-प्रदर्शन डेटा वेयरहाउस की तलाश कर रहे हैं, तो आपको निश्चित रूप से PostgreSQL को अपने डेटा वेयरहाउस डेटाबेस के विकल्प के रूप में विचार करना चाहिए। पोस्टग्रेएसक्यूएल के कई लाभ और विशेषताएं हैं जो हमारे डेटा वेयरहाउस को प्रबंधित करने के लिए उपयोगी हैं जैसे कि विभाजन, या संग्रहीत कार्यविधियाँ, और भी बहुत कुछ।